提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
作为高性能计算的典型应用,CESM运行时复杂性可谓首屈一指,由于其多模块、周期性的特点,使得相关的优化工作都很有针对性,博主特意测试了cesm的一些性能指标,作为观察现象,为一些优化工作提出一些参考
一、CESM程序概述
CESM程序特性表现为第一个模拟天的计算需要从读取小规模输入数据开始计算,然后进行多次迭代,每轮迭代过程均高度相似,每一轮迭代均由mpi_barrier函数进行同步启动与结束,这一点也表现在缓存命中与访寸上,主要使用内存进行计算,中间不生成任何中间数据,在最后一次性写入后端存储设备中。
二、缓存命中
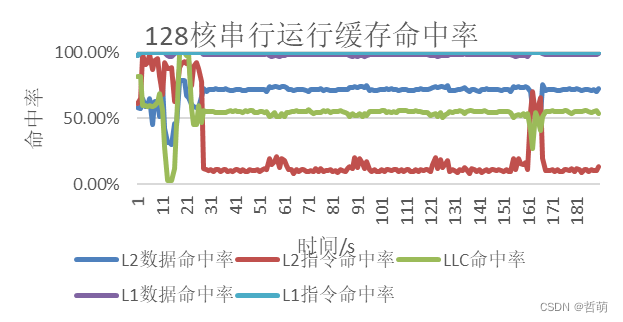
128核时各组件串行运行时的缓存命中情况如下:
L1的数据指令命中率都接近100%,而L2数据命中率在运行过程中稳定在70%左右, 指令命中率却很低并且呈现周期性,这与程序特性一致,并且说明CESM常用指令(libm数学库中的函数)较为固定,非常用指令(部分组件的独立函数,如海洋组件的傅里叶变换)一直更换频率很高,L3的命中率与L2数据命中率接近。
访寸体现了cesm程序的周期性,最大访存带宽230G/s,进入迭代后每一轮迭代的访寸行为基本一致,突出的部分为耦合器cpl接收各个组件的mpi_send消息,并完成网格转换计算后发送回各组件,需要用到访寸空间存储消息。迭代结束后输出总结结果,访寸有一个波动行为。
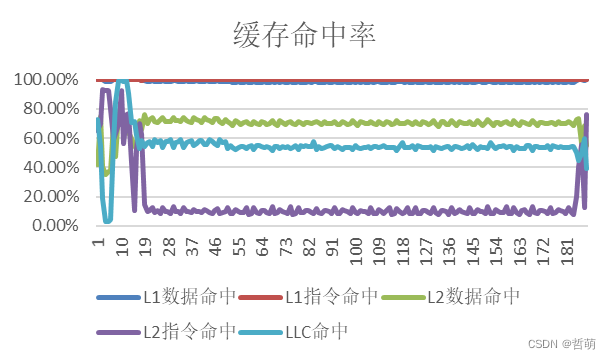
大规模并行后,缓存命中如下
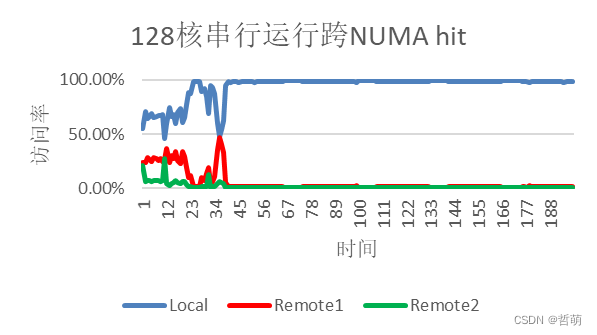
三、跨NUMA访问
跨NUMA hit统计的是所有核访问NUMA本地内存与跨NUMA访问内存的次数占总访问次数百分比的统计,从图中可见CESM程度整体基本上可以保持在NUMA本地内存的访问,这也是因为这个内存占用只有47.6G,对于每个NUMA来讲内存资源是非常充足的,因此可以保持很高的本地访寸率。
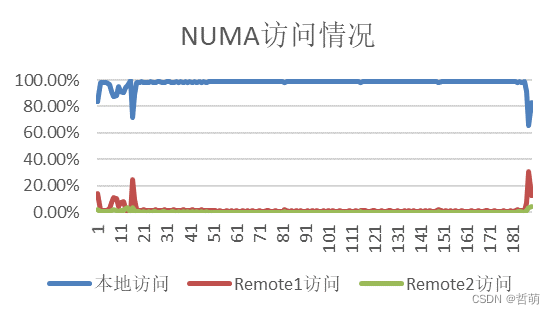
大规模并行后,单节点NUMA访问情况
四、IO
IO方面,使用nmon抓取的IO特征信息
各组件串行运行,128并行度抓取IO信息
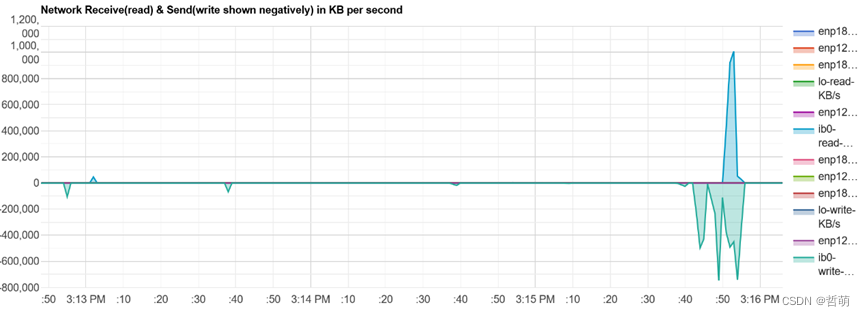
CESM对并行IO的支持并不好,因此采用串行IO。
这里程序从3:14开始程序运行,到3:16程序结束,整个过程前期IO量非常微小,到快结束的时候有一个瞬间的高达1GB的读取量,以及在800MB左右的写入量,整体IO总带宽峰值为读取1GB/s,写入813MB/s,因此CESM是一个主要依赖访寸,只在最后输出的时候需要存储设备IO的程序。
五、热点函数
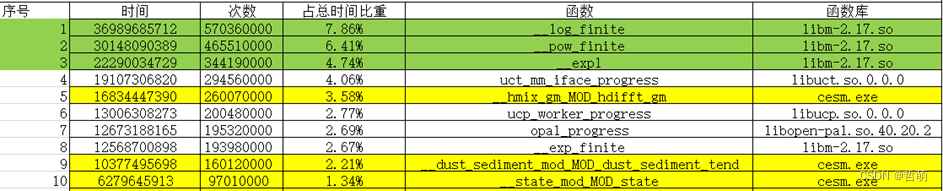
函数名 函数用途/特点
__hmix_gm_MOD_hdifft_gm 海洋斜压部分计算,求解三维流体方程,使用显式的蛙跳积分方法求解---傅里叶变换,暴力乘法
__dust_sediment_mod_MOD_dust_sediment_tend 气溶胶计算,使用有限差分(Finite Volumn,FV)动力框架,使用希尔伯特填充曲线方法
__rrtmg_lw_rtrnmc_MOD_rtrnmc 大气辐射计算,对网格垂柱(降雨、云、长短波辐射等)的进行近似计算
耗时前三名热点函数-使用perf抓取的耗时较长的cesm自身函数(计算耗时由长到短排列)
上述三个函数为使用perf统计时无法用数学库抽象出算符的耗时最高的三个计算函数,其他的不使用数学库的cesm计算代码占整体运行时间的比例都很少,不超过0.5%,而这三个函数无论在哪个并行度下都能占比1%以上,并且不依赖数学库,是自己独立的乘法运算。而其他使用数学库的函数在使用华为数学库后都能有很好的优化效果。
六、CPU绑定与性能关系
在CESM单机的分配上,我提出了将任务尽可能地分配到同一个NUMA中,并且在有空间的情况下各个任务尽可能的错开放在不同的CCL中避免缓存争抢的宏观策略。
我们用
mpirun --rankfile /path/to/myrank
同时创建文件myrank,内容格式为rank x=机器名 slot= y
表示x号进程绑定在y号core上
-
考虑一个最极端的情况,24核顺序绑定任务,也就是说分配给CPUID 0-23上:
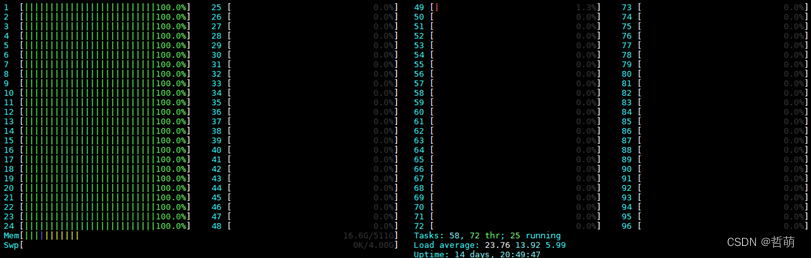 这种情况下每个占据的CCL都是四core全部占满。这种情况下,运行时长
这种情况下每个占据的CCL都是四core全部占满。这种情况下,运行时长420.238s。 -
一般情况下,直接mpirun不附加任何选项
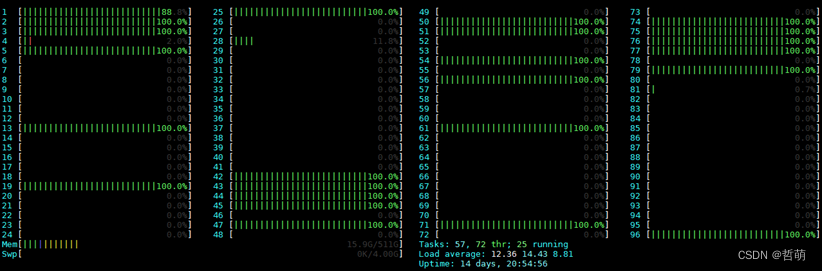
openmpi自带负载均衡设计,我们看到程序自动在每个Socket上平均分配进程,奇数并行度除了单核以外几乎都不行(这一点在cesm说明书中也被提及过)。但是我们发现依然有好几个进程是在一个CCL中运行的,此时运行时间为359.068s。也就是说情况1会导致性能下降16.9%。 -
最优方案
当每个CCL只有一个任务分配。此时运行时间仅有347.804s。
提升了3.3%。在避免紧密分配到一个CCL中时,性能已经有了肉眼可见的提升。
显然某个资源的争抢问题是个瓶颈,我们尝试通过抓取缓存命中以及NUMA内存通道的方法寻找问题的根源。
解决这个问题的方法有两个思路—1)将缓存争夺小的任务分配在同一个CCL中,2)在资源充足的前提下,尽可能将任务分配到不同CCL中,3)将计算资源缓存需求小的任务放在一个CCL中,空出一些空CCL给缓存要求大的任务。然而对于mpi来讲,除了root任务以外,其他task运行的代码是相同的,因而具体几号进程会有更大的存储需求并不好判断。因此避免该资源的争抢十分必要,同时我们注意到同一个CCL中有2-3个任务时,也会发生争抢问题,相对占满要轻一些。
七、通信拓扑
针对CESM的通信方式,我们使用IPM进行分析:
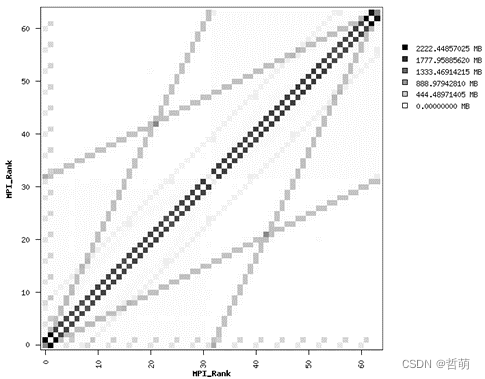
图中横坐标代表消息发送任务,纵坐标代表 黑点代表依次通信,颜色越深说明通信数据越大或通信越频繁。
我们发现通信特点是,邻近任务通信量大且频繁,并且总体分为两段,两段之间通信较少。因此将每段邻近任务分配到同一个socket中的相邻位置,两段任务可以正好分配到一个节点的两个socket上,因此CESM与920平台比较契合,直接将任务分两大段分到两片socket上并尽量错开到不同CCL中即可。
目前的策略是:尽可能分散地将任务分配到各个CCL中去,绑定CPUID时优先绑定4n,再是4n+2,然后是4n+3,最后是4n+1(n=0,1,…)。