线程大章节第一篇文章
前言
什么是线程呢?
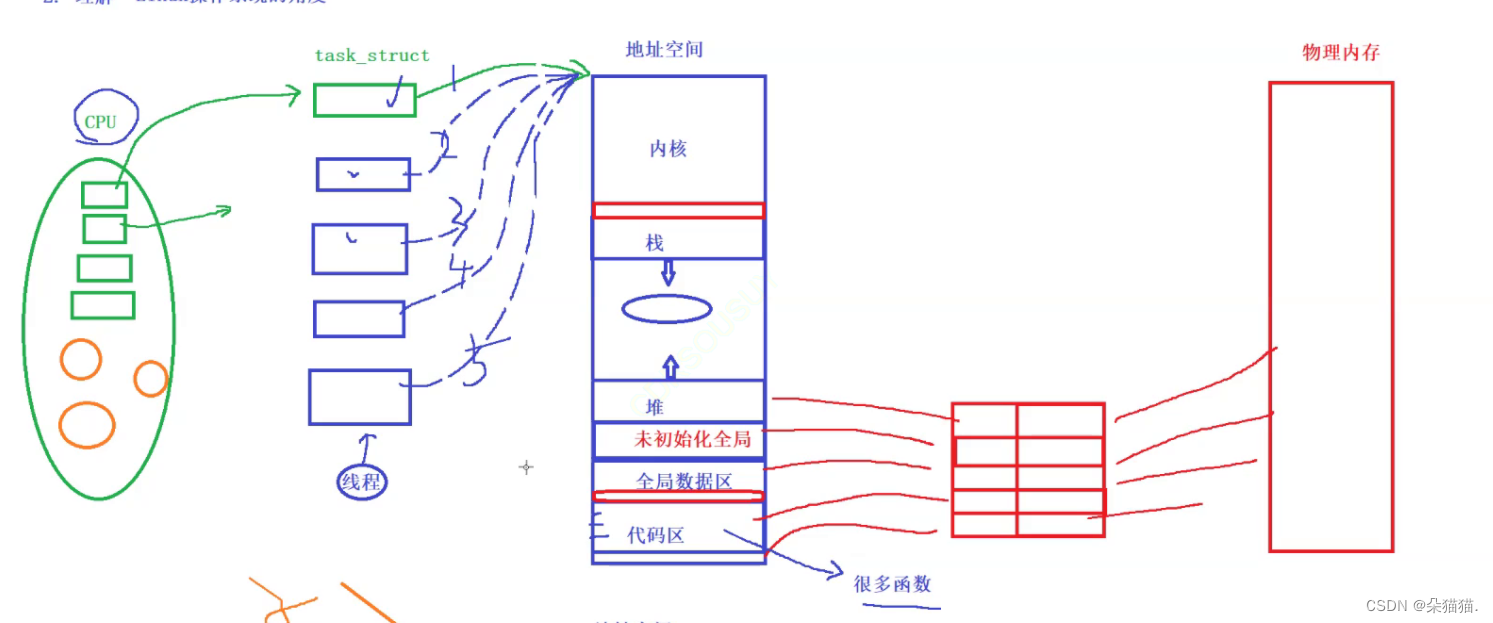
首先我们的地址空间有内核区等,然后进程地址空间通过页表映射到物理内存,而在CPU这边创建一个进程需要相应的pcb也就是task_struct,task_struct里面有个指针指向进程地址空间,而CPU中的寄存器有的指向进程pcb,有的指向内核级页表,而如果是创建一个进程的话那么如上图一样的策略如下图:
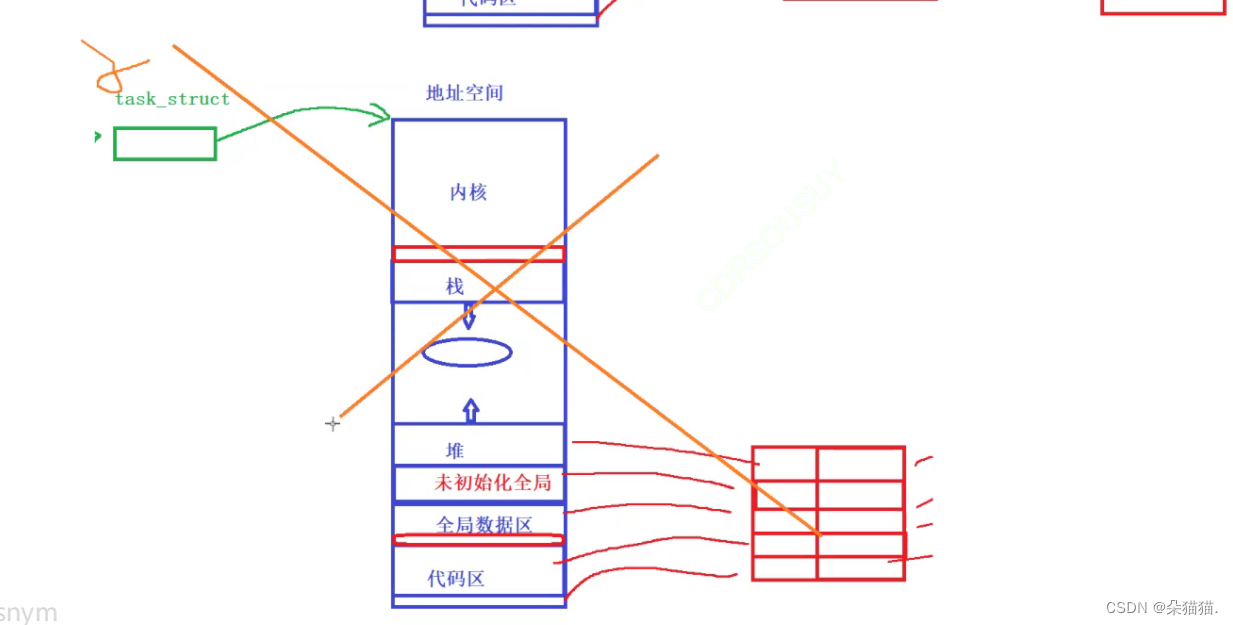
那么如果是线程是什么样呢?线程同样需要创建一个进程,但是与传统进程不同的是,线程所创建的进程只会创建PCB,也就是如第一张图所示task_struct下面的蓝色小方块,这些都是PCB,这些PCB不会重新创建进程地址空间和页表等重新映射,而是继续执行父进程的地址空间,也就是第一张图中父进程是绿色小方块,下面几个蓝色的都是线程pcb,这些线程可以执行不同的代码来达到不同工作的目的。以上就是线程的创建过程,实际上很好理解吧,那么线程是进程内部的一个执行分支这句话该怎么理解呢?实际上就是线程在进程的地址空间内运行,而这个线程属于该进程。
在CPU中有这些东西:运算器,控制器,寄存器,MMU(页表),硬件cache L1,L2,L3。而我们在切换进程的时候是需要重新加载缓存的也就是cache,而我们如果切换线程的话是不需要加载cache的。对于线程来说我们也可以用执行流来表示线程,所以我们在后面如果提到了执行流那么代表的就是线程。进程包括一大堆执行流以及进程地址空间以及页表以及代码和数据,所以一定要记得线程是在进程内的。以下是一张进程中画的很好的图:
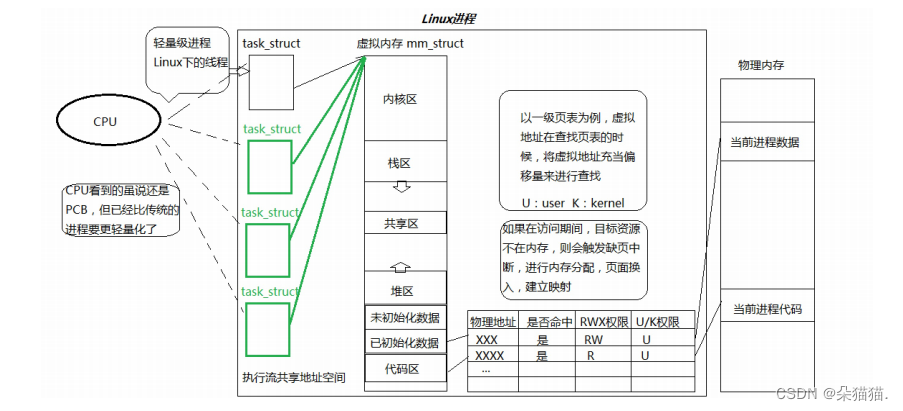
以上管理线程的知识知识linux系统下,不是每个系统的线程管理都是一样的,比如在windows下的内核是有真的线程的,所以windows系统需要同时管理TCB(线程控制块,属于进程PCB)和PCB,这样就会比较复杂,所以linux下管理线程用语言描述就是:复用你的PCB的结构体,用PCB模拟线程的TCB,很好地复用了进程的设计方案,也就是说linux没有真正意义上的线程,而是用进程方案模拟的线程。如果明白了以上的案例,我们就可以明白为什么windows操作系统长时间不关机就会变得非常卡顿,而linux操作系统可以不间断的运行(比如我们的安卓手机哦~),因为linux系统的这种维护进程线程的动作有好维护,效率更高也更安全的优点。下面我们先使用一下线程让大家看看linux线程。

一、linux线程基本概念
首先创建两个文件,一个是makefile,一个是.c文件:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
void* thread1_run(void *args)
{
while (1)
{
printf("我是线程1,我正在运行\n");
sleep(1);
}
}
void* thread2_run(void *args)
{
while (1)
{
printf("我是线程2,我正在运行\n");
sleep(1);
}
}
void* thread3_run(void *args)
{
while (1)
{
printf("我是线程3,我正在运行\n");
sleep(1);
}
}
int main()
{
pthread_t t1,t2,t3;
pthread_create(&t1,NULL,thread1_run,NULL);
pthread_create(&t2,NULL,thread2_run,NULL);
pthread_create(&t3,NULL,thread3_run,NULL);
while (1)
{
printf("我是主线程,我正在运行\n");
sleep(1);
}
return 0;
}大家一定要注意,在linux下用线程需要引入pthread库:

下面我们将程序运行起来:
指令 ps -aL是查询线程的:

右边的属性中pid我们已经很熟悉了,而LWP是线程的pid,我们可以看到第一个线程的pid和LWP是一样的,这是因为第一个是主线程。演示完了我们在继续讲讲理论知识:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
using namespace std;
#include <iostream>
void* thread1_run(void *args)
{
while (true)
{
sleep(1);
//printf("我是线程1,我正在运行\n");
cout<<"t1 thread..."<<getpid()<<endl;
}
}
void* thread2_run(void *args)
{
char* s = "hello world";
while (true)
{
sleep(5);
//printf("我是线程2,我正在运行\n");
cout<<"t2 thread..."<<getpid()<<endl;
*s = 'H'; //让这一个线程崩溃
}
}
void* thread3_run(void *args)
{
while (1)
{
printf("我是线程3,我正在运行\n");
sleep(1);
}
}
int main()
{
pthread_t t1,t2,t3;
pthread_create(&t1,NULL,thread1_run,NULL);
pthread_create(&t2,NULL,thread2_run,NULL);
//pthread_create(&t3,NULL,thread3_run,NULL);
while (1)
{
printf("我是主线程,我正在运行\n");
sleep(1);
}
return 0;
}我们的代码目的是让线程2因为修改常量区数据而崩溃,然后看看其他线程的状态,下面我们将代码运行起来:
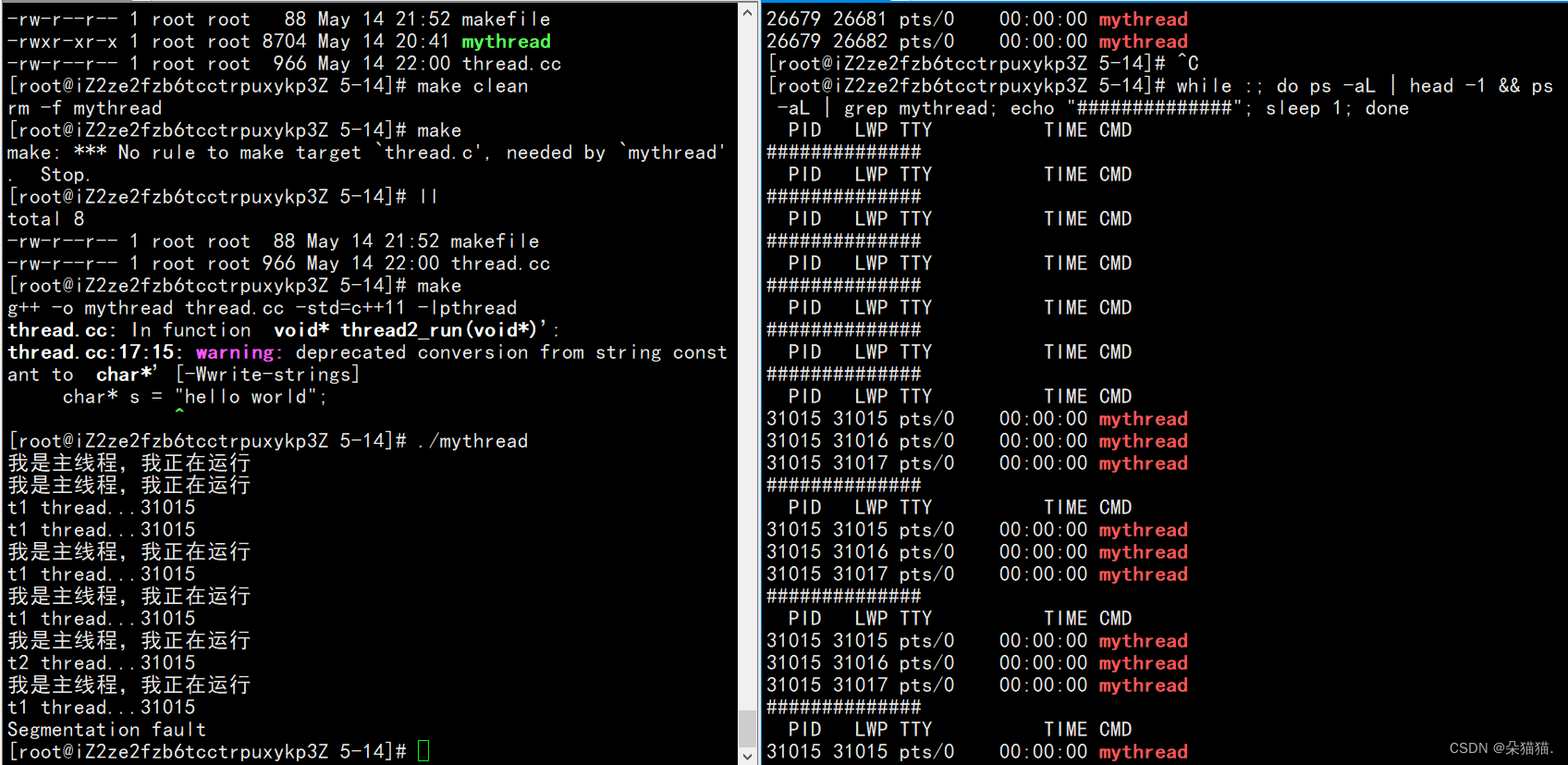

通过运行结果我们发现一个线程崩溃了以后导致进程崩溃了,这是因为从linux系统角度来看,线程是进程的执行分支,线程崩溃了就是进程崩溃了。如果从linux信号角度来看:页表转换的时候,MMU识别是否有写入权限,由于没有写入权限所以验证没有通过导致MMU异常->操作系统识别->给进程发信号->linux进程信号,而信号又是以进程为主的,所以当信号发给进程后整个进程就被杀掉了。
下面我们再验证一下如果有一个全局变量被修改了在其他线程是否会被看到:(也就是健壮性降低的缺点)
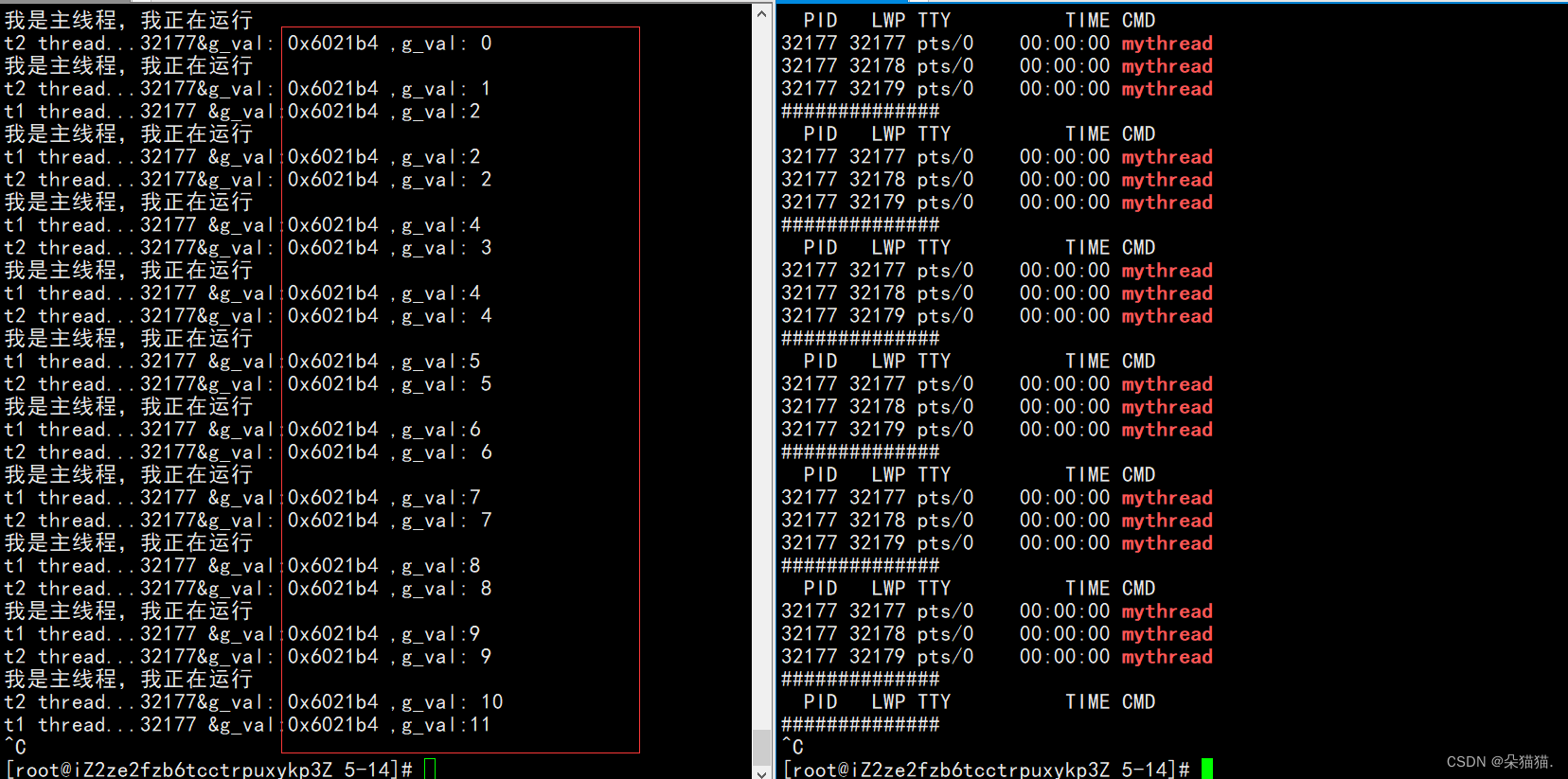 运行后我们发现全局变量在两个线程中的地址一模一样,其实这里为什么一样我们已经给出答案了,因为线程是共享父进程的进程地址空间的,所以他们所看到的代码和变量当然是一样的了。
运行后我们发现全局变量在两个线程中的地址一模一样,其实这里为什么一样我们已经给出答案了,因为线程是共享父进程的进程地址空间的,所以他们所看到的代码和变量当然是一样的了。
线程异常
线程异常这个概念其实我们已经演示过了,概念如下:
我们那会演示的修改常量区代码就是线程异常。
二、线程与进程的对比
进程是资源分配的基本单位,线程是调度的基本单位。
线程是在进程的内部运行的,多线程会共享进程的地址空间。
下面是进程自己的一部分数据:
1.线程ID 也就是我们所看到的LWP
2.一组寄存器。也就是当前线程执行的上下文数据
3.栈。没错,线程是有自己独立的栈的
4.errno
5.信号屏蔽字
6.调度优先级
线程自己私有的数据中最重要的两个是:寄存器和栈(也叫私有栈)
1.文件描述符表
2.每种信号的处理方式(SIG_IGN,SIG_DFL或者自定义的信号处理函数)
3.当前工作目录
4.用户id和组id
进程与线程的关系如下图:

第一种是一个进程中就一个线程,第二种是一个进程中有多个线程,这也叫多线程。
第三种是多个第一种情况,第四种是多个第二种情况。
下面讲解一下线程控制接口:
由于linux下没有真正意义的线程,而是用进程模拟的线程(LWP),所以linux不会提供直接创建线程的系统调用,他会给我们最多提供创建轻量级进程的接口。而为了让用户使用这些接口,任何系统都会提供pthread库,也叫原生线程库。
首先是pthread_create接口:

第一个参数类型是pthread_t类型,与线程ID有关。第二个参数是线程的属性,属性包括优先级,状态,私有栈等,但是我们一般不会设值属性所以nullptr即可。第三个参数是一个函数指针,作用是让该线程回调主线程执行的函数。第四个参数是配合回调函数使用的,当调用回调函数时这个参数会传入回调函数。下面我们编写代码演示一下pthread_create接口:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
void* thread_run(void* args)
{
while (true)
{
cout<<"new thread running"<<endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t t;
//第一个参数是一个输出型参数,当我们成功创建新线程后会将新线程的地址返回到参数中。
pthread_create(&t,nullptr,thread_run,nullptr);
while (true)
{
cout<<"main thread running,new thread id:"<<t<<endl;
sleep(1);
}
return 0;
}程序很简单,就是让主线程和新线程一起运行:

运行起来后我们发现为什么新线程的id会这么大呢?这个问题我们稍后一起讲解,现在我们还有一个问题,新线程创建后谁先运行呢?是主线程先运行还是新线程呢?我们在学进程的时候说过,父子进程谁先调度是要看调度器的,一般都是调度器随机选择,既然线程是由进程所复用的所以线程也同样遵守这个规则,由调度器决定。
下面我们创建一批线程去调用同一个函数:
void* thread_run(void* args)
{
char* name = (char*)args;
while (true)
{
cout<<"new thread running,my thread name is:"<<name<<endl;
sleep(1);
}
return nullptr;
}
int main()
{
//pthread_t t;
pthread_t tids[NUM];
for (int i = 0;i<NUM;i++)
{
char tname[64];
snprintf(tname,sizeof(tname),"thread-%d",i+1);
pthread_create(tids+i,nullptr,thread_run,tname);
}
//第一个参数是一个输出型参数,当我们成功创建新线程后会将新线程的地址返回到参数中。
//pthread_create(&t,nullptr,thread_run,nullptr);
while (true)
{
cout<<"main thread running,new thread id:"<<endl;
sleep(1);
}
return 0;
}首先我们在创建多个进程的时候开了一个字符数组用来打印每个线程的名称,然后看creat函数的第四个参数,我们让线程执行thread_run回调函数,把tname这个参数传到回调函数中,这样run函数的args就接收到了name参数,然后在run函数中把name打印出来以上就是代码所表达的意思,下面我们将程序运行起来:

运行后我们发现线程的编号有问题。为什么都是10而不是从1到10呢?因为我们传的第四个参数是缓冲区的首元素地址,所以每次传的都是相同的,这也就解释了为什么都是一样的,要解决这个问题很简单,我们只需要给每个线程都单独开一个缓冲区:
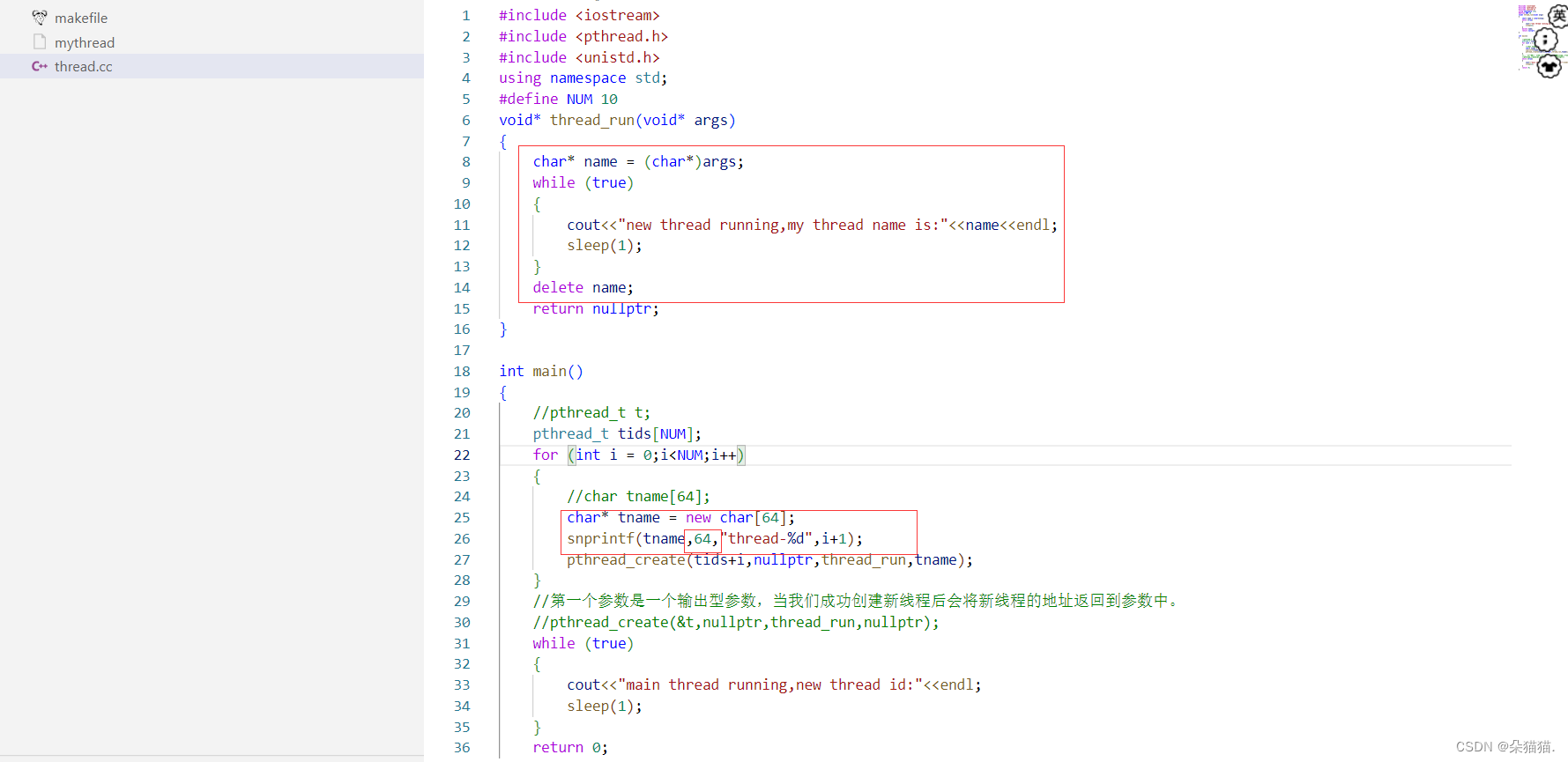
下面我们运行起来:
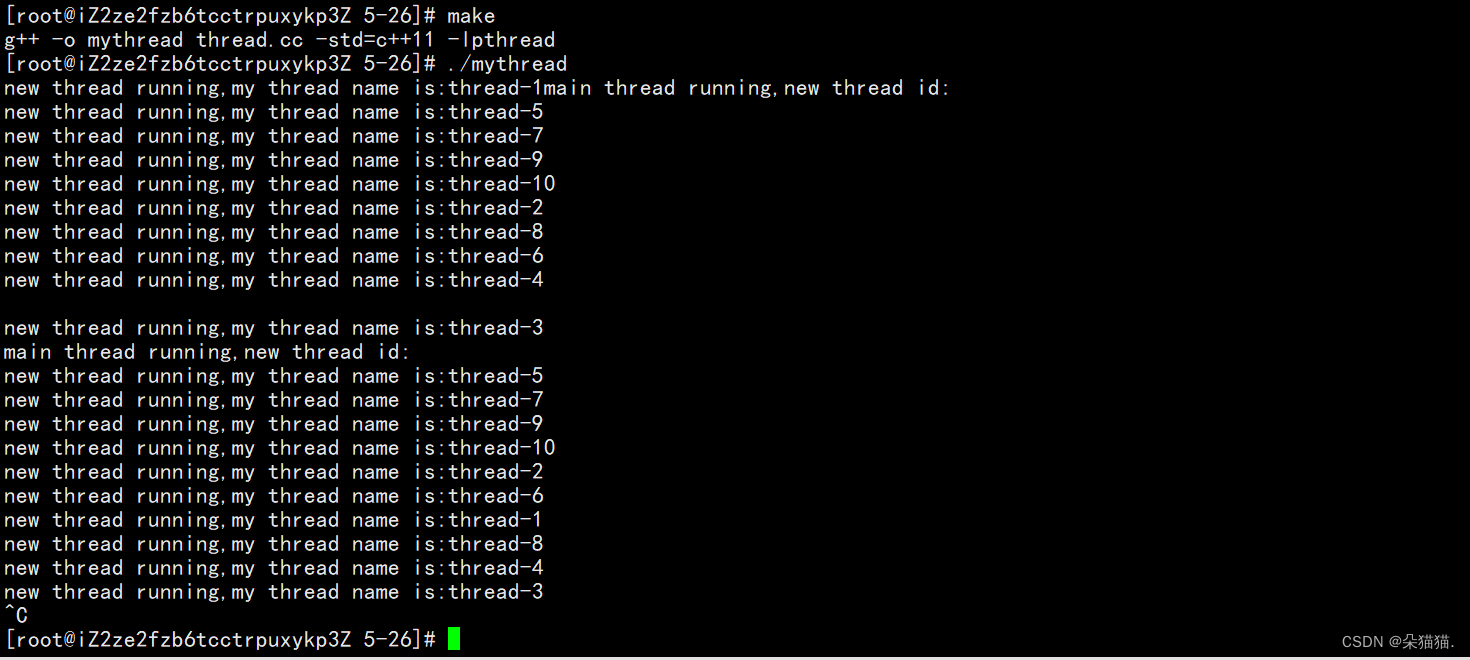
我们可以看到这次运行没问题了都成功打印出自己是几号线程。如果我们刚把10个线程创建出来然后就把主线程退了会有什么结果呢?


我们可以看到运行后连线程运行都没看到就直接退出了,下面我们让主线程sleep3秒看看结果:
 可以看到正好10个线程运行了3秒后自动退出了,也就是说主线程退出就是进程退出,进程退出所有的代码等都释放了所以线程也退出了。而新线程也会有僵尸进程的问题,所以需要让主线程去等待要退出的线程。下面我们学习线程等待接口:
可以看到正好10个线程运行了3秒后自动退出了,也就是说主线程退出就是进程退出,进程退出所有的代码等都释放了所以线程也退出了。而新线程也会有僵尸进程的问题,所以需要让主线程去等待要退出的线程。下面我们学习线程等待接口:
pthread_join:

第一个参数是线程id,第二个参数是二级指针我们先不考虑。
int main()
{
pthread_t tids[NUM];
for (int i = 0;i<NUM;i++)
{
//char tname[64];
char* tname = new char[64];
snprintf(tname,64,"thread-%d",i+1);
pthread_create(tids+i,nullptr,thread_run,tname);
}
for (int i = 0;i<NUM;i++)
{
pthread_join(tids[i],nullptr);
}
return 0;
}
这一次我们可以看到主线程不会退出了,因为主线程在等子线程退出。
下面我们修改一下代码让其子线程自己退出让主线程接收:



等待线程的返回值和之前一样,如果等待成功则返回0,否则返回错误码。下面我们运行起来:

运行结果与我们所预料的一样,等待成功后主进程退出。不知道大家对刚刚10个线程重复调用run函数熟不熟悉呢?这其实就是我们之前讲到的可重入函数。
如果我们在run函数里直接exit会发生什么呢?

什么都没有就结束了,这是因为exit直接终止的是进程,进程都被终止了那么后面的线程当然不可能继续使用了。那么如何只终止一个线程呢?接口pthread_exit
pthread_exit:
参数我们先不关心,直接设为空也就是不做任何操作给我把线程退出了就行:

下面我们将一下刚刚线程等待接口的第二个参数:
 这个参数是一个输出型参数,会拿出来等待到新线程的退出结果。下面我们演示一下:
这个参数是一个输出型参数,会拿出来等待到新线程的退出结果。下面我们演示一下:
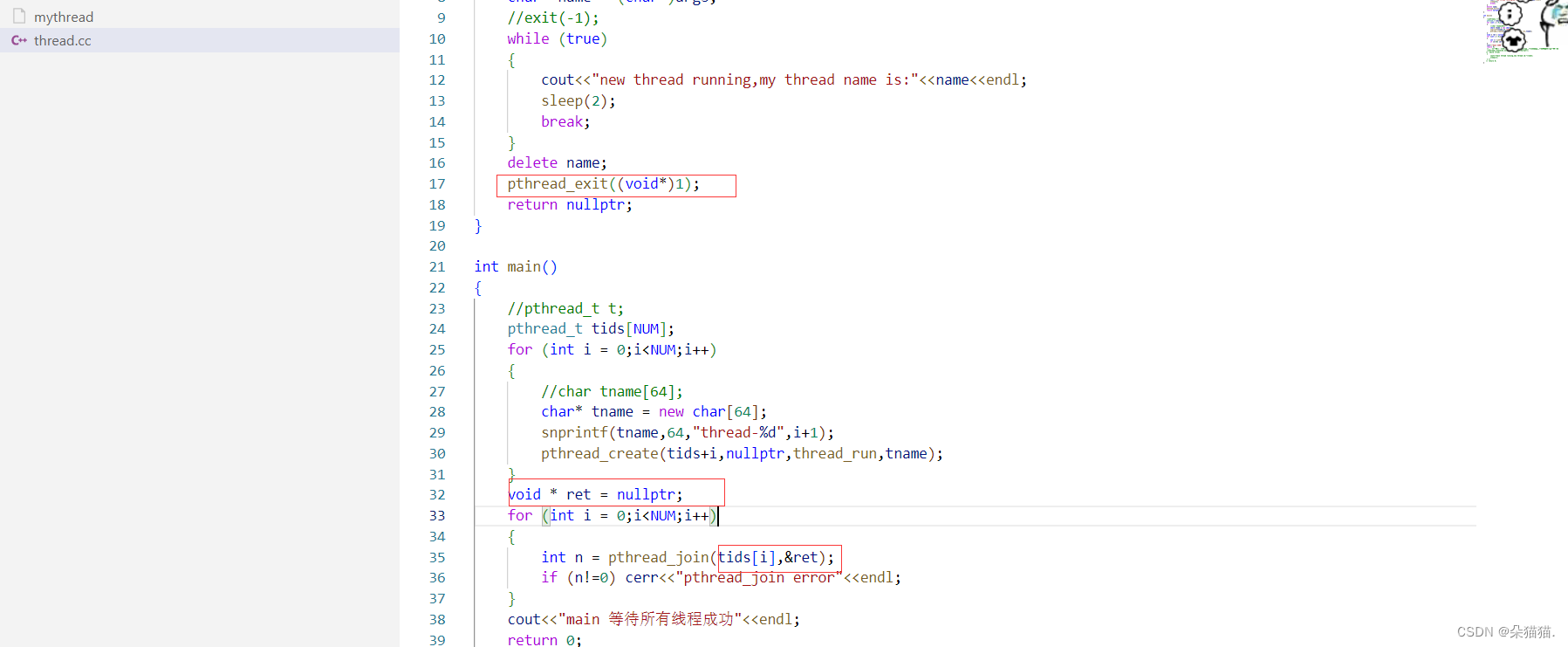
首先pthread_exit接口的参数是void*,我们搞一个1的信息,然后怎么被join的时候接收呢?很简单,只需要创建一个void*的变量,由于我们的第二个参数是二级指针,所以我们传的是void*的地址,这样等会等待成功就会拿到退出信息:
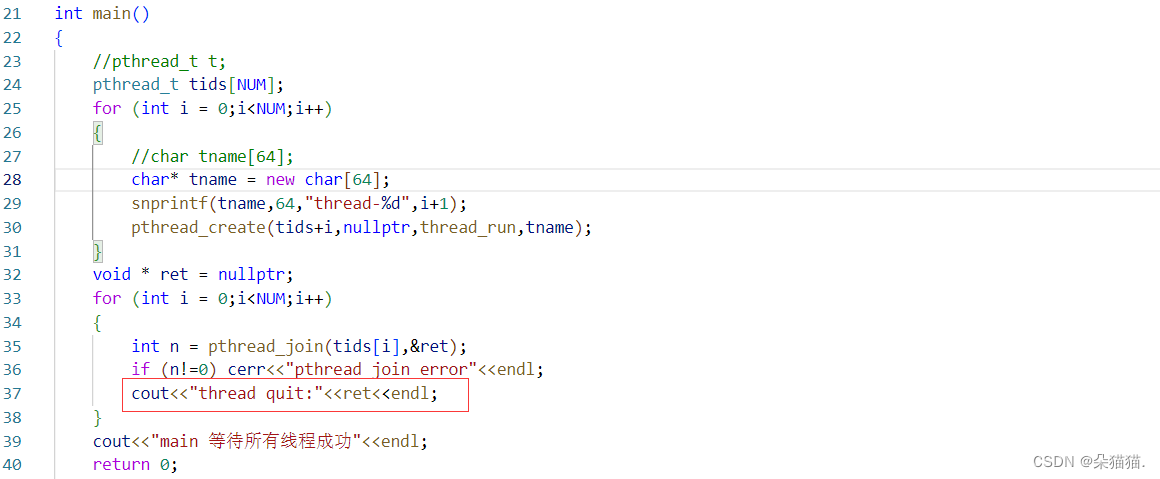
拿到信息后我们再打印一下:

我们确实拿到了退出信息,当然这是以地址的方式呈现的,如果想要整形只需要打印的时候强转一下即可。当然我们的线程退出的时候不仅仅可以传地址传整形,还可以传其他任意属性,下面我们用一个类举例:
class ThreadData
{
public:
ThreadData(const string& name,int id,time_t creatTime)
:_name(name)
,_id(id)
,_createTime((uint64_t)creatTime)
{
}
~ThreadData()
{
}
public:
string _name;
int _id;
uint64_t _createTime;
};我们直接创建一个类,这个线程数据类中有名字,id,创建时间的数据,下面我们修改一下原来的代码:


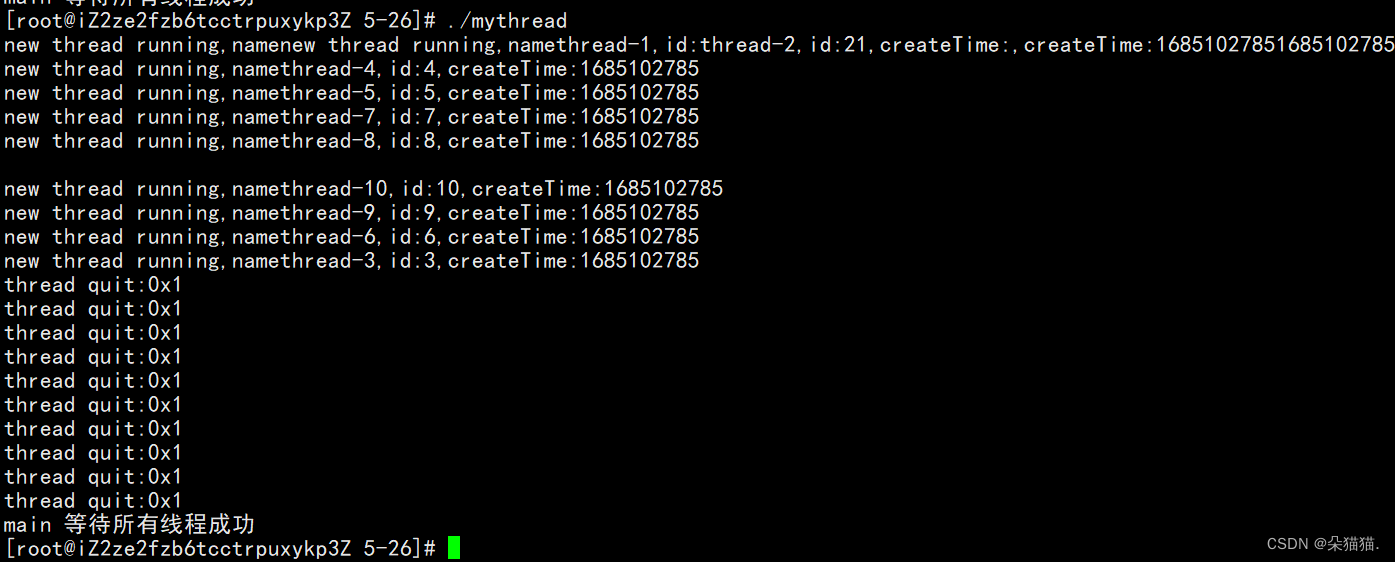
static_cast是安全转换,与强制类型转换差不多。下面我们运行起来:
下面我们把这个类补充完整,然后让pthread_exit返回这个类:
enum
{
OK = 0,
ERROR
};
class ThreadData
{
public:
ThreadData(const string& name,int id,time_t creatTime,int top)
:_name(name)
,_id(id)
,_createTime((uint64_t)creatTime)
,_status(OK)
,_top(top)
,_result(0)
{
}
~ThreadData()
{
}
public:
string _name;
int _id;
uint64_t _createTime;
//返回状态
int _status;
int _top = 0;
int _result;
};我们在类中加入了表示状态的status和top result,top和result是让线程帮我们计算所用到的两个变量,我们将原来的回调函数改为1-top的加和,每个线程算出来的都不一样,原先我们用ret接收的返回信息现在也可以用类的指针接收了

下面我们运行起来:

结果如上图所示,每个线程都完成了自己的任务,并且最后都成功被主线程回收。
下面我们再讲一个接口:pthread_cancel
这个接口的作用是取消一个线程,注意:必须是这个线程已经在运行了才能取消。

下面是测试代码:
void *threadRun(void* args)
{
const char* name = static_cast<const char*>(args);
int cnt = 5;
while (cnt)
{
cout<<name<<" is running: "<<cnt--<<endl;
sleep(1);
}
pthread_exit((void*)11);
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,threadRun,(void*)"thread 1");
sleep(1);
pthread_cancel(tid);
void *ret = nullptr;
pthread_join(tid,&ret);
cout<<"new thread exit : "<<(uint64_t)ret<<endl;
return 0;
}代码的作用是当线程创建好开始运行后我们直接取消线程。

我们可以看到,本来线程进入run函数需要打印5次running,但是由于我们取消了所以打印了一次就直接退出了,这就是pthread_cancel接口。