参考文档:
基本介绍
APScheduler(Advanced Python Scheduler)是一个python的任务调度器,他可以使任务定期执行,同时我们可以动态的添加或删除任务。如果我们希望任务在下次程序启动时继续执行,那么他还支持持久化任务。除此之外,他也是跨平台的。需要注意的是,APScheduler并不是一个守护进程或单独服务,他是依托于现有服务或程序运行。
安装
pip install apscheduler
或
poetry add apscheduler
快速开始
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
def job():
print(f"{datetime.now()}执行了")
if __name__ == '__main__':
scheduler = BlockingScheduler()
scheduler.add_job(func=job, trigger='interval', seconds=3)
scheduler.start()
这个栗子做了一件事:每三秒执行一次任务。
首先,初始化调度器,这里的BlockingScheduler是阻塞性的调度器,当调用start方法时,会阻塞当前进程;然后,向调度器中添加任务,这里的任务是job方法,每执行一次任务会打印文字;这里采用的是interval(间隔执行)的方式,每三秒执行一次
组件
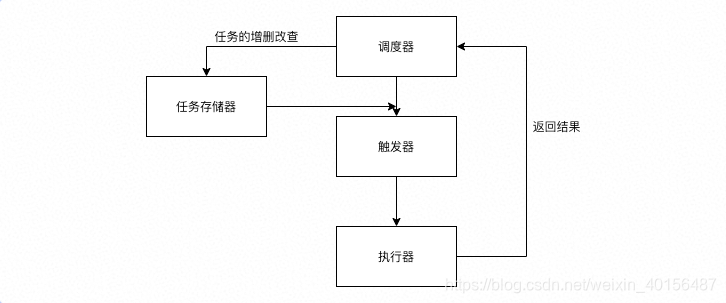
APScheduler具有四个基本组件:
- triggers(触发器):包含调度逻辑。每个作业都有自己的触发器,该触发器确定下一步应在何时运行该作业。除了其初始配置外,触发器完全是无状态的。
- job stores(任务存储器):任务存储器是可以存储任务的地方,默认情况下任务保存在内存,也可将任务保存在各种数据库中。任务存储进去后,会进行序列化,然后也可以反序列化提取出来,继续执行。
- executors(执行器):执行器会将任务放到进程或线程中执行,任务执行完成后,执行程序会通知调度器,然后触发一些事件
- schedulers(调度器):任务调度器是属于整个调度的总指挥官。他会合理安排作业存储器、执行器、触发器进行工作,并进行添加和删除任务等。调度器通常是只有一个的。
调度器
APScheduler有很多调度器,不同的调度器适合不同的环境:
- BlockingScheduler:适用于当前进程只有这一个调度器在工作
- BackgroundScheduler:适用于在程序后台运行
- AsyncIOScheduler:适用于使用了asyncio的模块
- GeventScheduler:适用于使用了gevent的模块
- TornadoScheduler:适用于用tornado构建的应用
- TwistedScheduler:适用于用twisted构建的应用
- QtScheduler:适用于构建QT应用
任务存储器
任务存储器的选择取决于是否需要任务持久化。如果每次任务启动的时候都重新创建任务,那么可以使用内存存储器(MemoryJobStore)。如果需要任务持久化,可以使用和项目匹配的数据库存储器,这样即使是程序崩溃,重启后任务依旧可以继续执行。存储器可以有以下几种:
- MemoryJobStore:任务保存在内存中
- SQLAlchemyJobStore:使用sqlalchemy作为存储框架,官方建议数据库使用PostgreSQL
- MongoDBJobStore:使用 mongodb作为存储器
- RedisJobStore:使用 redis作为存储器
执行器
执行器的选择取决于程序使用了什么框架,默认情况下使用ThreadPoolExecutor。如果任务涉及了计算密集型操作,可以考虑使用ProcessPoolExecutor。APScheduler针对不同的程序或架构,有以下几种执行器:
- ThreadPoolExecutor:线程池执行器;
- ProcessPoolExecutor:进程池执行器;
- GeventExecutor: Gevent程序执行器;
- TornadoExecutor: Tornado程序执行器;
- TwistedExecutor: Twisted程序执行器;
- AsyncIOExecutor: asyncio程序执行器;
触发器
APScheduler内置了三种触发器:
- date:特定时间仅运行一次
- interval:固定时间间隔运行
- cron:某个时间周期运行
构建调度程序
构建调度器
假设构建一个使用默认存储器和默认执行器的阻塞调度器:
from apscheduler.schedulers.blocking import BlockingScheduler
scheduler = BlockingScheduler()
通过查看源码可以发现,默认存储器使用的是MemoryJobStore,默认执行器使用的是ThreadPoolExecutor
除了默认的配置,APScheduler也提供了许多不同的方式来配置调度器。假设现在我们希望构造一个:
- 一个名为“ redis”的MemoryJobStore
- 一个名为“ default”的RedisJobStore
- 一个名为“ default”的ThreadPoolExecutor,其最大线程数为20
- 一个名为“ processpool”的ProcessPoolExecutor,其最大进程数为5
- UTC作为调度程序的时区
- 默认情况下,对新作业关闭合并
- 新作业的默认最大实例限制为3
方法一:
from pytz import utc
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.redis import RedisJobStore
from apscheduler.jobstores.memory import MemoryJobStore
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
jobstores = {
'redis': RedisJobStore(),
'default': MemoryJobStore()
}
executors = {
'default': ThreadPoolExecutor(20),
'processpool': ProcessPoolExecutor(5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BackgroundScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
方法二:
scheduler = BackgroundScheduler({
'apscheduler.jobstores.redis': {
'type': 'redis',
'url': ''
},
'apscheduler.jobstores.default': {
'type': 'memory'
},
'apscheduler.executors.default': {
'class': 'apscheduler.executors.pool:ThreadPoolExecutor',
'max_workers': '20'
},
'apscheduler.executors.processpool': {
'type': 'processpool',
'max_workers': '5'
},
'apscheduler.job_defaults.coalesce': 'false',
'apscheduler.job_defaults.max_instances': '3',
'apscheduler.timezone': 'UTC',
})
方法三:
from pytz import utc
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.redis import RedisJobStore
from apscheduler.executors.pool import ProcessPoolExecutor
jobstores = {
'redis': RedisJobStore(),
'default': {
'type': 'memory'}
}
executors = {
'default': {
'type': 'threadpool', 'max_workers': 20},
'processpool': ProcessPoolExecutor(max_workers=5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BackgroundScheduler()
scheduler.configure(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
启动调度器
除了BlockingScheduler,其他调度器启动后会立即返回,继续执行程序其他操作
scheduler.start()
添加任务
APScheduler支持两种添加任务的方式:
- 调用
add_job()
调用add_job方法之后,会返回apscheduler.job.Job对象,这个对象可以用来更新或删除
scheduler.add_job(func=job, trigger='interval', seconds=3)
- 使用
scheduled_job()装饰器
@scheduler.scheduled_job(trigger='interval', seconds=3)
def job():
print(f"{datetime.now()}执行了")
我们可以在任何时候安排工作给调度器,如果添加工作的时候调度器还木有启动,那么工作会暂停,并在调度器开始工作后才开始
删除任务
- 调用
remove()
job = scheduler.add_job(job, 'interval', minutes=2)
job.remove()
- 调用
remove_job()
scheduler.add_job(job, 'interval', minutes=2, id='my_job_id')
scheduler.remove_job('my_job_id')
暂停和恢复任务
暂停:
apscheduler.job.Job.pause()apscheduler.schedulers.base.BaseScheduler.pause_job()
恢复:
apscheduler.job.Job.resume()apscheduler.schedulers.base.BaseScheduler.resume_job()
更新任务
modify_job()apscheduler.job.Job.modify()reschedule_job()apscheduler.job.Job.reschedule()
关闭调度程序
scheduler.shutdown()
默认情况下,调度程序关闭其作业存储和执行程序,并等待直到所有当前正在执行的作业完成。如果不想等待,可以执行以下操作:
scheduler.shutdown(wait=False)
APScheduler和fastapi实战
import datetime
import uvicorn
from fastapi import FastAPI, Body
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.redis import RedisJobStore
from apscheduler.executors.pool import ThreadPoolExecutor
app = FastAPI(title='fast-api')
scheduler = None
def job(job_id=None):
print(f"{datetime.datetime.now()}执行了{job_id}")
@app.on_event('startup')
def init_scheduler():
"""初始化"""
redis_job_store = RedisJobStore(host='127.0.0.1', port='6379')
executor = ThreadPoolExecutor()
jobstores = {
'default': redis_job_store
}
executors = {
'default': executor,
}
job_defaults = {
'coalesce': True,
'max_instance': 1
}
global scheduler
scheduler = BackgroundScheduler()
scheduler.configure(jobstores=jobstores, executors=executors, job_defaults=job_defaults)
scheduler.add_job(job, 'interval', seconds=3)
print("启动调度器...")
scheduler.start()
@app.post('/add-job')
async def add_job(job_id: str = Body(...)):
"""添加job"""
scheduler.add_job(id=job_id, func=job, args=(job_id,), trigger='interval', seconds=2)
return {
"msg": "success!"}
@app.post('/remove-job')
async def remove_job(job_id: str = Body(..., embed=True)):
"""移除job"""
scheduler.remove_job(job_id)
return {
"msg": "success!"}
if __name__ == '__main__':
uvicorn.run(app, host='127.0.0.1', port=5566)
项目启动后,可以看到调度器开始工作,并开始执行任务

这时添加一个job_id=1的任务,可以看到两个任务在执行
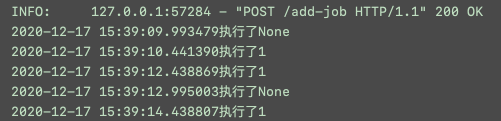
删除job_id=1的任务,可以看到只剩下一个任务在执行
