【编译和链接五】编译器后端——gcc到汇编
一. 栈回溯
1. frame pointers
在调试的时候经常需要进行堆栈回溯。最简单的方式是使用一个独立的寄存器(ebp)来保存每层函数调用的堆栈栈顶(frame pointer):
pushl%ebp
movl%esp,%ebp
...
popl%ebp
ret
- x86_64的frame point模式
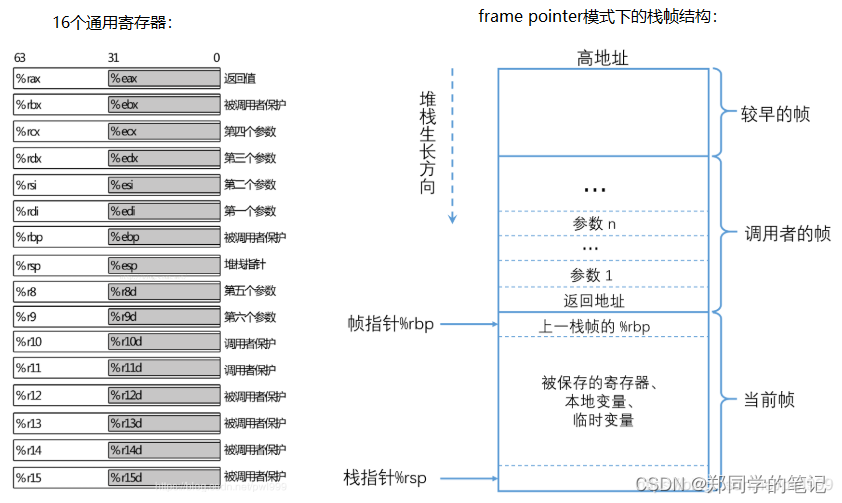
这种方式在堆栈回溯时非常方便快捷。但是这种方法也有自己的不足:
- 需要一个专门寄存器ebp来保存frame poniter。
- 保存ebp寄存器即保存回溯信息(unwind info)的动作会被编译成代码,有指令开销。
- 在回溯堆栈时,除了恢复sp,不知道怎么恢复其他的寄存器。(例如gdb中的 frame n, info reg)
- 没有源语言信息。
2 .debug_frame (DWARF)
调试信息标准DWARF(Debugging With Attributed Record Formats)定义了一个.debug_frame section用来解决上述的难题。
- 可以把ebp当成常规寄存器使用。
- 但是当保存esp时,它必须在.debug_frame节中产生一条注释,告知调试器它将其保存在什么位置以及存放在何处。
- 这种机制还有的好处是它不仅仅是用来恢复ebp,还可以用来恢复其他寄存器。
- 而且是带外的,不消耗任何指令周期,没有任何性能开销。
这种机制也有其不足:
- 没有源语言信息。
- 不支持在程序加载时同时加载调试信息。
DWARF4标准的section 6.4:DWARF4
The call frame is identified by an address on the stack. We refer to this address as the Canonical Frame Address orCFA. Typically, the CFA is defined to be the value of the stack pointer at the call site in the previous frame (which may be different from its value on entry to the current frame).
即CFA定义为执行call xxx时SP(stack pointer)所指向的地址。
3 .eh_frame (LSB)
现代Linux操作系统在LSB(Linux Standard Base)标准中定义了一个.eh_frame section来解决上述的难题。这个section和.debug_frame非常类似,但是它解决了上述难题:
- 拥有源语言信息。
- 编码紧凑,并随程序一起加载。
但是.debug_frame和.eh_frame同时面临一个难题:怎么样生成堆栈信息表?

4 CFI directives
为了解决上述难题,GAS(GCC Assembler)汇编编译器定义了一组伪指令来协助生成调用栈信息CFI(Call Frame Information)。
or CFI:Call Frame Instrctions, 即调用帧指令
CFI directives伪指令是一组生成CFI调试信息的高级语言,它的形式类似于:
.cfi_startproc
pushl%ebp
.cfi_def_cfa_offset 8
.cfi_offset ebp,-8
关于汇编器利用这些伪指令来生成.debug_frame还是.debug_frame,在.cfi_sections指令中定义。如果只是调试需求可以生成.debug_frame,如果需要在运行时调用需要生成.eh_frame。
5、关于.cfi结论
- CFI代表呼叫帧信息.这是编译器描述函数中发生的事情的方式.调试器可以使用它来呈现调用堆栈,链接器可以合成异常表,进行堆栈深度分析以及其他类似的事情.
实际上,它描述了存储处理器寄存器等资源的位置以及返回地址的位置.
CFA代表调用帧地址,它表示调用者函数的堆栈指针位置的地址.需要这样才能获取有关堆栈中下一帧的信息.
其他:至于.cfi每个指令什么意思,大家可以查看官网CFI directives
也可以查看其他解释
5.1、CFI 伪指令
gcc 使用CFI 伪指令来生成eh_frame信息,在使用c语言编写时,gcc会自动帮我们产生CFI伪指令。我们在深入了解eh_frame格式之前,先看下CFI 伪指令。
在GAS(GCC Assembler)汇编编译器CFI(Call Frame Information)/ARM CFI文档中,对所有CFI伪指令的含义有详细描述。这里挑选几个重要的伪指令分析。
- 1.cfi_startproc
用在每个函数的入口处。 - 2.cfi_endproc
.cfi_endproc用在函数的结束处,和.cfi_startproc对应。
- 3.cfi_def_cfa_offset [offset]
用来修改修改CFA计算规则,基址寄存器不变,offset变化:
CFA = register + offset(new) - 4.cfi_def_cfa_register register
用来修改修改CFA计算规则,基址寄存器从rsp转移到新的register。
register = new register - 5.cfi_offset register, offset
寄存器register上一次值保存在CFA偏移offset的堆栈中:
*(CFA + offset) = register(pre_value) - 6.cfi_def_cfa register, offset
用来定义CFA的计算规则:
CFA = register + offset
默认基址寄存器register = rsp。
x86_64的register编号从0-15对应下表。rbp的register编号为6,rsp的register编号为7。
%rax,%rbx,%rcx,%rdx,%esi,%edi,%rbp,%rsp,%r8,%r9,%r10,%r11,%r12,%r13,%r14,%r15,
参考
1、linux 栈回溯(x86_64 )
2、x86_64-abi-0.95
.cfi的介绍到此为止,后面不再介绍了。
二、寄存器
下表展示的是16bit寄存器 , 32bit寄存器的前缀是 e, 64bit的寄存器前缀是 r。例如 bp/ebp/rbp

三、hello world 汇编
- demo
#include<stdio.h>
int main()
{
printf("hello world\n");
return -1;
}
- 汇编
gcc -S hello.c -o hello.s
- 生成的汇编代码
.file "hello.c"
.section .rodata
.LC0:
.string "hello world"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $.LC0, %edi
call puts
movl $-1, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-44)"
.section .note.GNU-stack,"",@progbits
1、指令解释
1.1 .cfi伪指令
.cfi_startproc ——表示每个函数的开头标志。它初始化一些内部数据结构。对应的用.cfi. endproc 来表示关闭函数的标志。
.cfi_def_cfa_offset 16 ——距离栈帧的距离16,在此偏移后的地址用CFA的基址寄存器保存,程序刚开始的默认基址寄存器是 5号SP寄存器
.cfi_offset [6,-16] ——把6号寄存器BP 的值保存在CFA - 16 处
.cfi_def_cfa_register 6 ——CFA的基址寄存器改用6号寄存器保存,同时原先寄存器的值也挪到6号,
Linux C :C的汇编码生成
X86汇编调用框架浅析与CFI简介
1.2 汇编指令
pushq %rbp
movq %rsp, %rbp
movl $.LC0, %edi
call puts
movl $-1, %eax
popq %rbp
ret
- 第一行代码:
pushq %rbp
通过前面的讲解,我们已经知道,这一行是将%rbp的值压入栈中。为什么要这样做?因为寄存器有“调用者保存”和“被调用者”保存的规则。待我细细道来。
16个寄存器,除了%rsp要存储栈顶指针外,一般来说剩下的15个都可以用作存储变量。但是当涉及函数调用时,部分寄存器的功能就用限制了:%rax将被用作存储返回值;%rdi, %rsi, % rdx, %rcx, %r8, %r9这六个寄存器将被用来保存参数;剩下8个仍然可以保存任何数值。但问题是,寄存器只有一套, 现在要两个函数(父函数和子函数)来使用,势必产生冲突,那怎么办呢?答案是在子函数使用之前将这些寄存器的值保存在栈中,待子函数使用完成后,再将栈中保存的值还给寄存器。根据谁负责保存这些寄存器,可以把它们分为两类:“调用者保存”和“被调用者保存”。“调用者保存”(caller-saved):即在调用子函数之前,将父函数用过的寄存器压栈;“被调用者保存”:即在子函数内,对即将使用的寄存器压栈。下面总结了哪些是调用者保存寄存器,和被调用者保存寄存器。
| 调用者保存寄存器 | 被调用者保存寄存器 |
|---|---|
| %r10,%r11 | %rbx, %rbp, %r12-15 |
回到这行代码,显而易见,我们将%rbp压栈是因为第二行代码改变了%rbp的值,而%rbp是被调用者保存寄存器。
-
- 第2行代码
movq %rsp, %rbp
这行代码是将%rsp的值赋值给%rbp。这行代码在这里显得比较多余(但在后面的例子中将看到它的作用),它的作用是让%rbp成为基指针,后续函数(多于6个)的参数,中间变量等等保存的地址就是以%rbp所指向的地址的偏移。
-
- 第3行代码
movl $.LC0, %edi
把hello world 放入寄存器edi
-
- 第4行代码
call puts
调用puts函数,输出到shell窗口
-
- 第5行代码
movl $-1, %eax
把-1赋值给寄存器eax
-
- 第6行代码
popq %rbp
将栈顶的数据弹出,并赋给%rbp。这与pushq %rbp相对应,旨在恢复%rbp以前的值。
-
- 第7行代码
ret
被调用者执行完毕,返回调用者。
参考:快速入门汇编语言
四、printf和puts
两个函数的最大区别在于 puts() 函数只接受一个参数(指向要显示的字符串的指针)而 printf () 函数将采用一个参数(指向格式字符串的指针),然后是堆栈中任意数量的参数(printf() 是一个可变参数函数)。
所以,基本上,区别在于 puts() 只有一个参数,而 printf() 是一个可变参数函数。
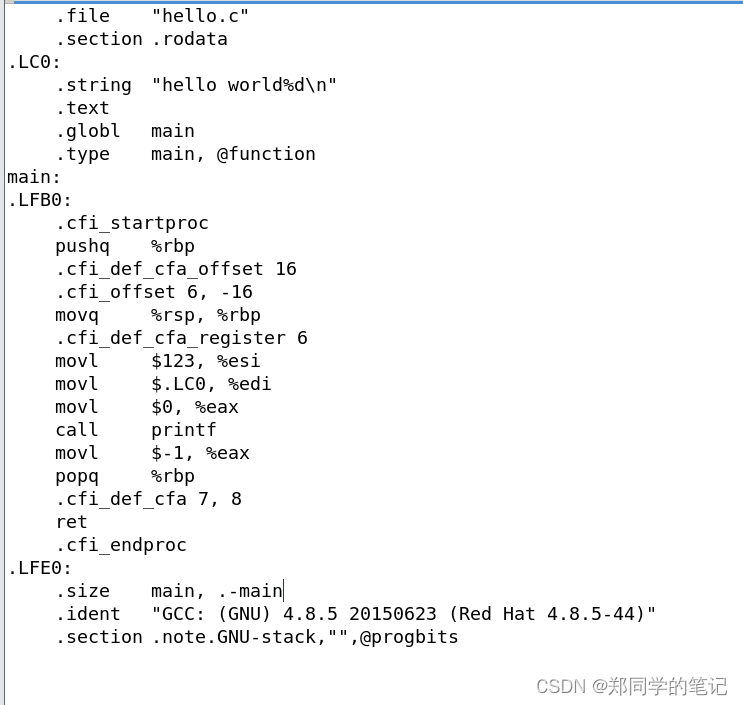
#include<stdio.h>
int main()
{
printf("hello world%d\n",123);
return -1;
}
.file "hello.c"
.section .rodata
.LC0:
.string "hello world%d\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $123, %esi
movl $.LC0, %edi
movl $0, %eax
call printf
movl $-1, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-44)"
.section .note.GNU-stack,"",@progbits
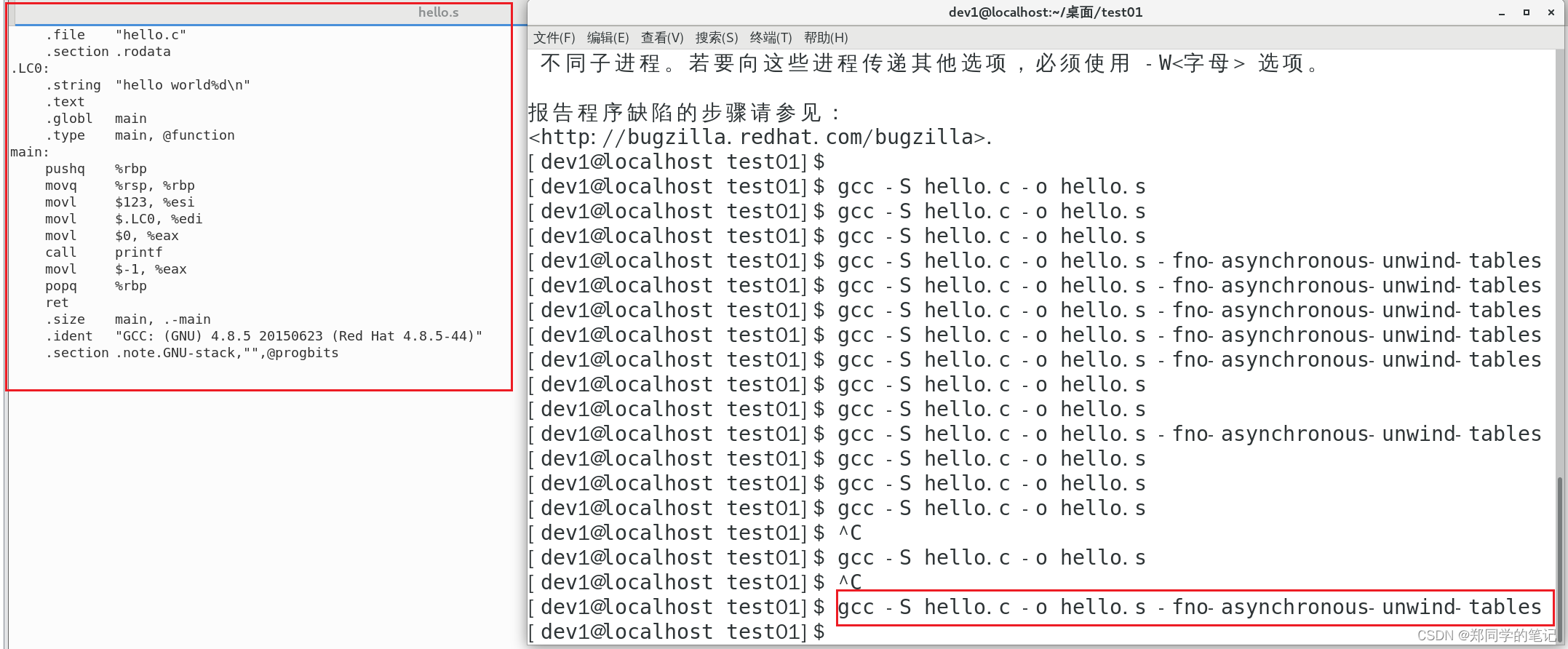
四、如何编译不带:调试用的调用堆栈的
gcc -S hello.c -o hello.s -fno-asynchronous-unwind-tables
.file "hello.c"
.section .rodata
.LC0:
.string "hello world%d\n"
.text
.globl main
.type main, @function
main:
pushq %rbp
movq %rsp, %rbp
movl $123, %esi
movl $.LC0, %edi
movl $0, %eax
call printf
movl $-1, %eax
popq %rbp
ret
.size main, .-main
.ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-44)"
.section .note.GNU-stack,"",@progbits
五、汇编语法
- .ident
.ident
gcc版本信息
- .file
.file filename
.file伪操作用指示汇编器该汇编程序的逻辑文件名。
- .global
.global symbol_name或者.globl symbol_name
.global和.globl伪操作用于定义一个全局的符号,使得链接器能够全局识别它,即一个程序文件中定义的符号能够被所有其他程序文件可见。
通过标签创建或者通过.set和.equ创建的符号会作为本地符号被保存到符号表内。通过.globl指令则可以将这些符号转为全局符号。例如下面的代码,_start和max_temp被转换成了全局符号。
- .local
.local symbol_name
.local伪操作用于定义局部符号,使得此符号不能够被其他程序文件可见
- .type
.type name , type description
.type伪操作用于定义符号的类型。譬如“.type symbol,@function”即将名为symbol的符号定义为一个函数(function)。
.word伪操作将从当前PC地址处开始分配若干个字(word)的空间,每个字填充的值由分号分隔开的expression指定。空间分配的地址一定与字对齐(word aligned)。
- .string
.string “string”
.string伪操作将从当前PC地址处开始分配若干个字节空间用于存放“string”字符串。字节的个数取决于字符串的长度。
- .section
.section name [, subsection]
.section伪操作指明将接下来的代码汇编链接到名为name的段(Section)当中,还可以指定可选的子段(Subsection)。常见的段如.text、.data、.rodata、.bss:
“.section .text”伪操作将接下来的代码汇编链接到.text段。
“.section .data”伪操作将接下来的代码汇编链接到.data段。
“.section .rodata”伪操作将接下来的代码汇编链接到.rodata段。
“.section .bss”伪操作将接下来的代码汇编链接到.bss段。
- .text
.text
伪操作基本等效于“.section .text”。
- .data
.data
.data伪操作基本等效于“.section .data”。
- .rodata
.rodata
.rodata伪操作基本等效于“.section .rodata”。
- .bss
.bss
.bss伪操作基本等效于“.section .bss”。
- .size
.size symbol,symbol
size伪操作用于指定符号的大小。.表示当前位置,减去main符号的地址即为整个main函数的大小。相当于将将main函数的大小赋值给符号main_size。
其他、
位置无关代码(PIC)
position independent code :位置无关代码
call __x86.get_pc_thunk.ax
获取调用时eip的值,cpu指令寄存器 extend instruction pointer
mov eax ,eip;错误的指令
得到‘GLOBAL_OFFSET_TABLE’,里面存储了符号的地址信息。
不需要位置无关代码,可以使用指令
-fno-pic
不需要gcc内置函数
-fno-builtin
不需要标准头文件
-fnostdinc
不需要位置无关的可执行程序 position independent executable
-fno-pie
不需要标准库
-nostdlib
不需要栈保护
-fno-stack-protector