随着大数据越来越火热,薪资越来越高,开始吸引着越来越多的人开始想要投身这个行业。其中有许多朋友的都是大数据零基础,以前并没有接触过大数据相关知识。零基础参加大数据培训难吗?这主要取决于你所学习大数据培训机构的硬性实力,如:大数据师资、大数据课程、大数据项目等等,下面我们一起来看一下吧。
大数据学习QQ群:716581014 共同努力进步
从学习难易度来看,作为一个为“优雅”而生的语言,Python语法简捷而清晰,对底层做了很好的封装,是一种很容易上手的高级语言。在一些习惯于底层程序开发的“硬核”程序员眼里,Python简直就是一种“伪代码”。

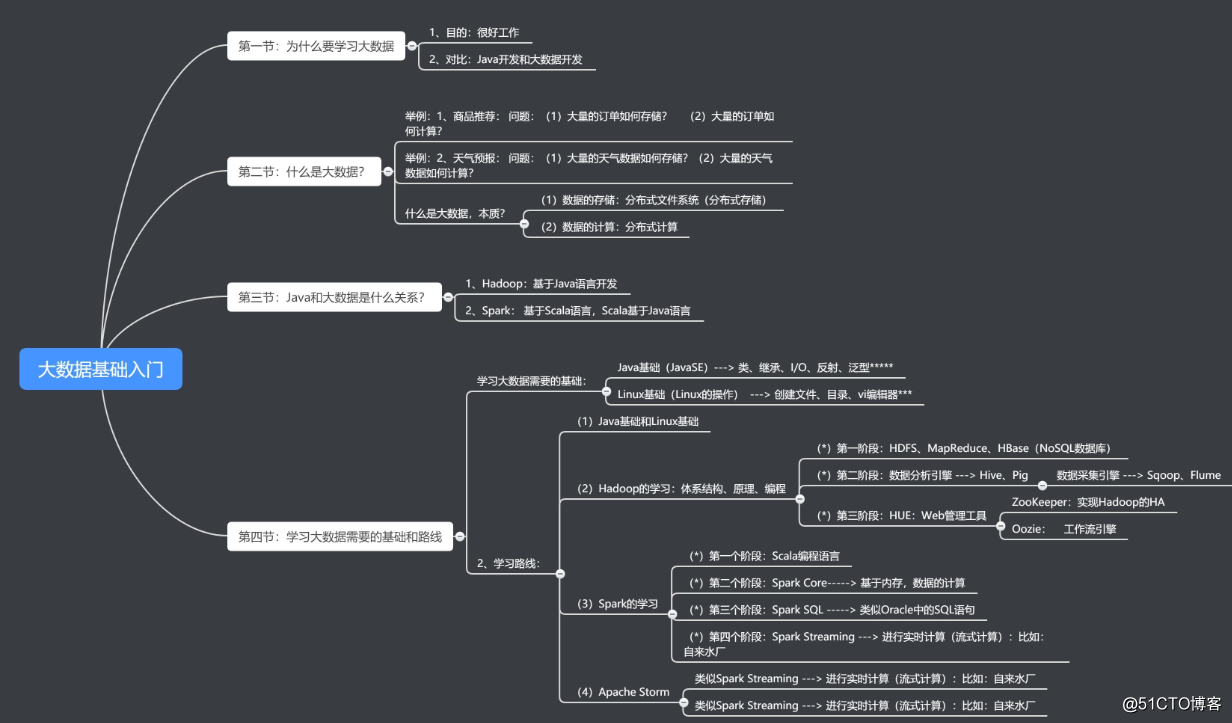
2018年零基础学习大数据路线图
在大数据和数据科学领域,Python几乎是万能的,任何集群架构软件都支持Python,Python也有很丰富的数据科学库,所以Python不得不学。
Linux:因为大数据相关软件都是在Linux上运行的,所以Linux要学习的扎实一些,学好Linux对你快速掌握大数据相关技术会有很大的帮助,能让你更好的理解hadoop、hive、hbase、spark等大数据软件的运行环境和网络环境配置,能少踩很多坑,学会 shell就能看懂脚本这样能更容易理解和配置大数据集群。还能让你对以后新出的大数据技术学习起来更快。
Hadoop:这是现在流行的大数据处理平台几乎已经成为大数据的代名词,所以这个是必学的。Hadoop里面包括几个组件HDFS、MapReduce和YARN,HDFS是存储数据的地方就像我们电脑的硬盘一样文件都存储在这个上面,MapReduce是对数据进行处理计算的,它有个特点就是不管多大的数据只要给它时间它就能把数据跑完,但是时间可能不是很快所以它叫数据的批处理。
YARN是体现Hadoop平台概念的重要组件有了它大数据生态体系的其它软件就能在hadoop上运行了,这样就能更好的利用HDFS大存储的优势和节省更多的资源比如我们就不用再单独建一个spark的集群了,让它直接跑在现有的hadoop yarn上面就可以了。其实把Hadoop的这些组件学明白你就能做大数据的处理了,只不过你现在还可能对”大数据”到底有多大还没有个太清楚的概念,听我的别纠结这个。
等以后你工作了就会有很多场景遇到几十T/几百T大规模的数据,到时候你就不会觉得数据大真好,越大越有你头疼的。当然别怕处理这么大规模的数据,因为这是你的价值所在,让那些个搞Javaee的php的html5的和DBA的羡慕去吧。
Zookeeper:这是个万金油,安装Hadoop的HA的时候就会用到它,以后的Hbase也会用到它。它一般用来存放一些相互协作的信息,这些信息比较小一般不会超过1M,都是使用它的软件对它有依赖,对于我们个人来讲只需要把它安装正确,让它正常的run起来就可以了。

2018年零基础学习大数据路线图
Mysql:我们学习完大数据的处理了,接下来学习学习小数据的处理工具mysql数据库,因为一会装hive的时候要用到,mysql需要掌握到什么层度那?你能在Linux上把它安装好,运行起来,会配置简单的权限,修改root的密码,创建数据库。这里主要的是学习SQL的语法,因为hive的语法和这个非常相似。
Sqoop:这个是用于把Mysql里的数据导入到Hadoop里的。当然你也可以不用这个,直接把Mysql数据表导出成文件再放到HDFS上也是一样的,当然生产环境中使用要注意Mysql的压力。
Hive:这个东西对于会SQL语法的来说就是神器,它能让你处理大数据变的很简单,不会再费劲的编写MapReduce程序。有的人说Pig那?它和Pig差不多掌握一个就可以了。
Oozie:既然学会Hive了,我相信你一定需要这个东西,它可以帮你管理你的Hive或者MapReduce、Spark脚本,还能检查你的程序是否执行正确,出错了给你发报警并能帮你重试程序,最重要的是还能帮你配置任务的依赖关系。我相信你一定会喜欢上它的,不然你看着那一大堆脚本,和密密麻麻的crond是不是有种想屎的感觉。
Hbase:这是Hadoop生态体系中的NOSQL数据库,他的数据是按照key和value的形式存储的并且key是唯一的,所以它能用来做数据的排重,它与MYSQL相比能存储的数据量大很多。所以他常被用于大数据处理完成之后的存储目的地。
Kafka:这是个比较好用的队列工具,队列是干吗的?排队买票你知道不?数据多了同样也需要排队处理,这样与你协作的其它同学不会叫起来,你干吗给我这么多的数据(比如好几百G的文件)我怎么处理得过来,你别怪他因为他不是搞大数据的,你可以跟他讲我把数据放在队列里你使用的时候一个个拿,这样他就不在抱怨了马上灰流流的去优化他的程序去了,因为处理不过来就是他的事情。而不是你给的问题。
当然我们也可以利用这个工具来做线上实时数据的入库或入HDFS,这时你可以与一个叫Flume的工具配合使用,它是专门用来提供对数据进行简单处理,并写到各种数据接受方(比如Kafka)的。

2018年零基础学习大数据路线图
Spark:它是用来弥补基于MapReduce处理数据速度上的缺点,它的特点是把数据装载到内存中计算而不是去读慢的要死进化还特别慢的硬盘。特别适合做迭代运算,所以算法流们特别稀饭它。它是用scala编写的。Java语言或者Scala都可以操作它,因为它们都是用JVM的。
后续提高:大数据结合人工智能达到真正的数据科学家,打通了数据科学的任督二脉,在公司是技术专家级别,这时候月薪再次翻倍且成为公司核心骨干。
机器学习(Machine Learning, ML):是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。机器学习的算法基本比较固定了,学习起来相对容易。
你的大数据学习路线
腾讯云一站式解决方案在移动开发生命周期中提供各种服务,帮助您快速构建移动应用程序并推动业务增长。立即了解细

计算机科学硕士毕业于北京航空公司。现在他为一家互联网金融公司和一名开源技术爱好者工作。曾在IBM、Sogou、微博等公司任职。我们对卡夫卡和其他开源的流处理技术和框架有很深的理解,也是中国的高级卡夫卡代码贡献者。深入研究了卡夫卡的工作原理、应用机理及应用进展。
本文的目的是为所有大数据初学者制定一个清晰的学习路线,帮助他们打开大数据的学习之旅。鉴于大数据领域的辉煌和复杂的技术,每个大数据初学者应该根据自己的实际情况制定自己的学习路径。
大数据,即大数据,对它有很多定义。最权威的是IBM的定义,它可以被读者阅读。由于本文关注的是如何学习大数据,首先要在大数据域中定义不同的角色,以便读者能够根据自己的实际情况找到自己的位置,从而打开学习过程。

你的大数据学习路线
角色
在我看来,大数据产业有以下两种类型的角色。
大数据工程
大数据分析
为什么这两种角色相互依赖,独立运作?没有大数据工程,大数据分析是不可能的,但没有大数据分析,就没有理由进行大数据工程。这与婚姻和爱情相似——爱情的目的是结婚,而不是为了爱情而结婚,是玩流氓。
特别是大数据工程需要解决数据的定义、收集、计算和保存等工作。因此,大型数据工程师首先考虑数据的高可用性问题,设计和部署这样的系统,即大数据工程系统需要为下游业务系统或分析系统实时提供数据服务。而大型数据分析的角色定位在如何使用数据从大型数据工程系统接收数据,如何为企业或组织提供生产性数据分析,并且它确实帮助公司改进或提高服务水平,因此对于大数据分析者来说,它们是F。解决这个问题。问题是发现和利用数据的价值,包括趋势分析、模型建立和预测分析。
总而言之,大数据工程角色需要考虑数据收集、计算(或处理)和保存;大数据分析角色是用于执行数据的高级计算。

你的大数据学习路线
我们属于什么样的角色?
既然我们理解了在大数据领域中的角色分类,我们自然需要“就座”来确定他们自己的位置,这样我们就可以开始在一个明确的方向上学习大数据。在考虑这个问题时,我们需要参考以下两个因素。
专业知识背景
行业经验
这里的专业知识背景不是学历和机构的背景,而是你对一些IT技术的理解。即使你不是计算机专业的,只要你在C语言中有一个热血,即使C Dennis Ritchie的父亲也不敢贬低你。因此,这里只有两个专业知识。
计算机专业知识,如操作系统、程序设计语言、计算机操作原理等。
数学知识,指高等数学,如微积分,概率统计,线性代数和离散数学,不是x*x+y x y=1。
而行业经验指的是你在相关领域的工作经验,具体可以分为以下3个文件。
绿色的手。
你的大数据学习路线
有一定经验的工程师
资深专家——现在在大数据领域,有一个更酷的名字,数据科学家,比如百度前首席数据科学家Wu Enda博士。
好的,现在我们可以根据上面的分类来定义我们的角色。例如,作者是:“我是一个计算机专业的工程师,有一定的数学基础(尤其是微积分和线性代数),但数理统计和概率论不是我的强项。”此外,最好不要炸掉面子。脂肪。如果你以前没有任何经验,承认你是新手。没关系。关键是要明确你的立场。
在确定我们的位置之后,我们需要对应于特定的大数据角色。下面是一些基本规则。
如果你有良好的编程基础和深刻的理解
深度学习(Deep Learning, DL):深度学习的概念源于人工神经网络的研究,最近几年发展迅猛。深度学习应用的实例有AlphaGo、人脸识别、图像检测等。是国内外稀缺人才,但是深度学习相对比较难,算法更新也比较快,需要跟随有经验的老师学习。
**大数据学习QQ群:716581014 一起学习
大数据基础入门图