2015年7月1日上午,国家授时中心增加了7:59:60这个时间来处理闰秒问题。对于使用网络时间协议进行时钟同步的操作系统而言,实在是不应该有什么问题才对,因为即使没有这多出的一秒,系统时钟不准个几秒也是常有的事儿啊。但是部分Linux(比如RHEL 6.2 64bit)上的部分应用(比如Greenplum数据库,也包括java和mysql这些)需要读取硬件时钟和系统时钟,这二者不一致时,就跑不动,可恶的是,它还不挂,就只是慢。。。
故障现象
- Greenplum上的任务莫名其妙的变慢,平均执行时间加倍。
- 系统整体CPU利用率升高
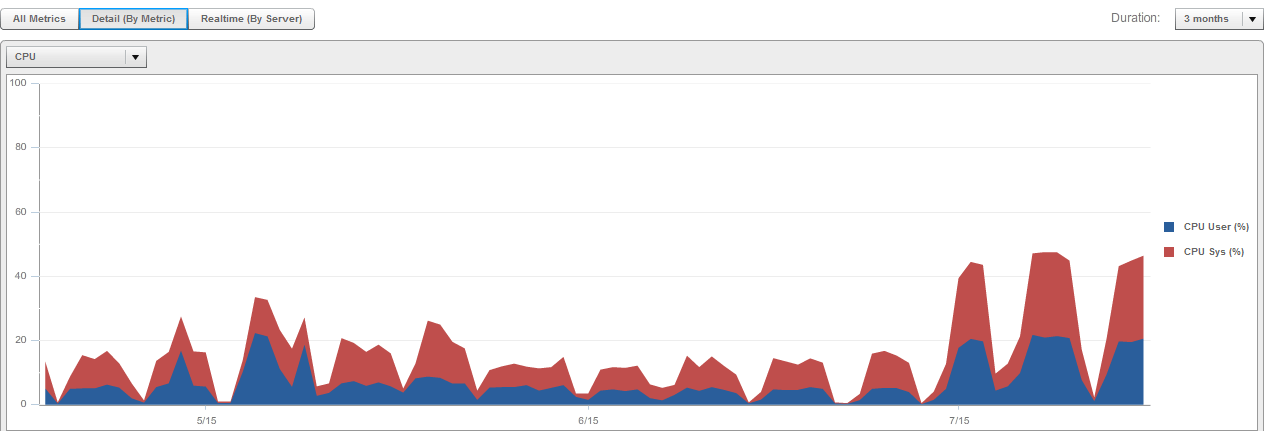
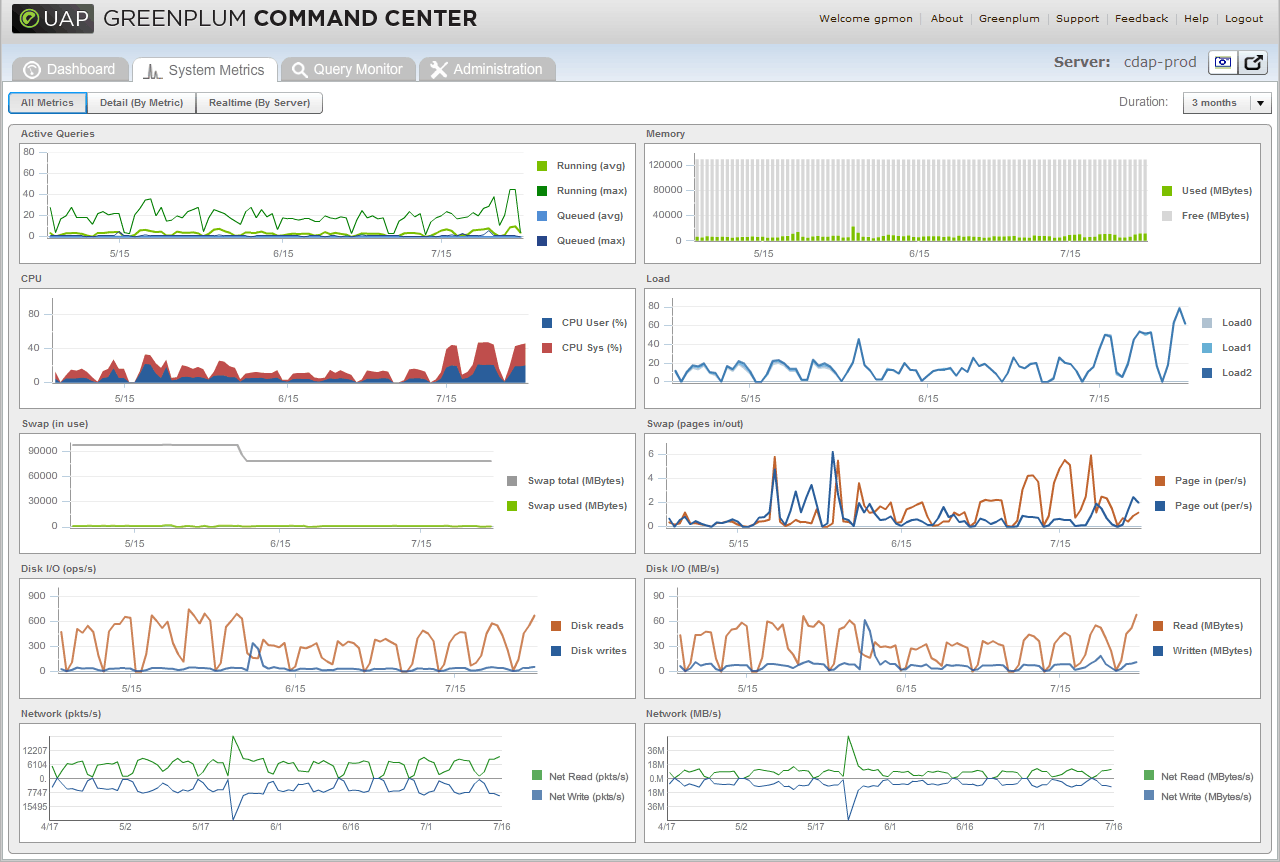
- 整个系统从7月1日开始CPU使用升高,IO使用降低,排队负载增多
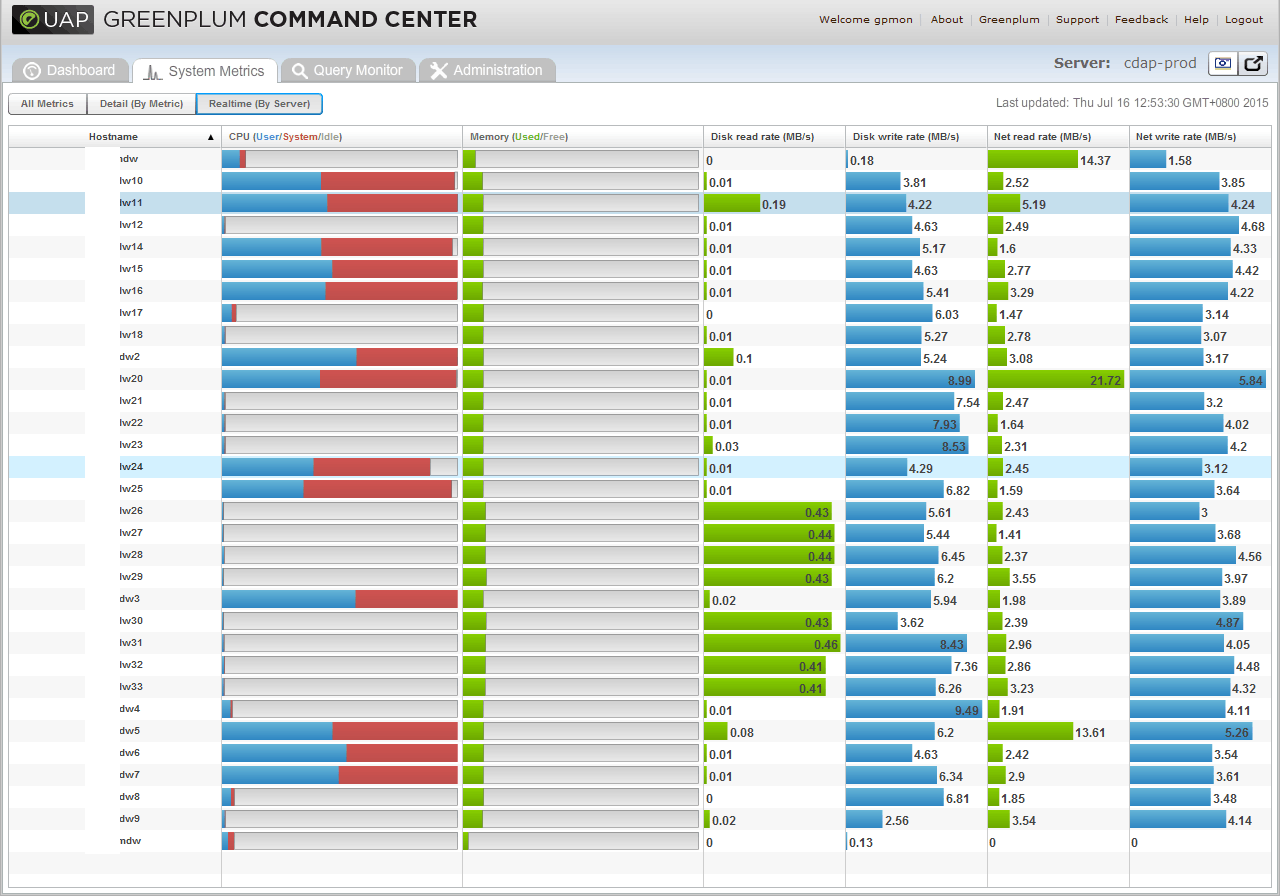
- 接近一半的服务器CPU利用率达到100%
分析原因
Greenplum的性能问题基本从两个方面着手,一是硬件和OS问题,RAID和网络这类影响IO的硬件条件一般最容易出问题,之前就遇过一台seg host的一块万兆网卡出问题,导致整个cluster的性能急剧下降,gpcheckperf可以发现这类问题,但是需要停机检测;二是应用程序问题,也就是sql语句写的质量,主要就是锁,可以通过以下的sql查询:
SELECT locktype, database, c.relname, l.relation, l.transactionid, l.transaction, l.pid, l.mode, l.granted, a.current_query
FROM pg_locks l, pg_class c, pg_stat_activity a
WHERE l.relation=c.oid AND l.pid=a.procpid
ORDER BY c.relname;可是闰秒造成的问题跟上述情况都不一样,这些办法都没用,本次实际问题的分析情况如下:
- 所有发生闰秒问题的机器都是linux,现象是CPU使用率较高(不一定是100%)
- GP Master是从7月1日8:05开始有CPU使用过高的告警,闰秒是7月1日7:59开始实施的,重启后CPU使用率恢复正常
- GP变慢就是7月初开始的,7月1日,GP本身及所有应用未做任何更改,未上线新应用
- 从系统平均CPU利用率看,7月1日开始,系统平均CPU利用率比之前高出了1倍
- 有一半的机器(全是RHEL 6.2 64bit)CPU一直是100%
解决方案
知道原因,解决起来就很容易了,其实就是在集群的每台机器上都将系统时钟同步到硬件时钟就行了,执行过程需要注意执行结果,有时候同步一次可能不生效:
gpssh -f ./allhosts
=> service ntpd stop
=> ntpdate ntp.mydomain.com
=> service ntpd start
=> clock --systohc
=> exit