目录
并行计算概述
所谓并行计算的概念定义
同时多个计算资源一起工作(逻辑以及物理上的并行而非并发),协同解决一个计算问题
- 涉及多个计算资源或者处理器;
- 问题被分解为多个离散的部分,可以同时处理;(数据并行)
- 每个部分可以由一系列指令完成;(指令并行)
(易混词:并发 反义词:串行)
如下图所示,问题的每个部分在不同的处理器上执行(这里的CPU指的是处理器;(ALU))

对比CPU和GPU处理方式,如下图直观可知何为并行。
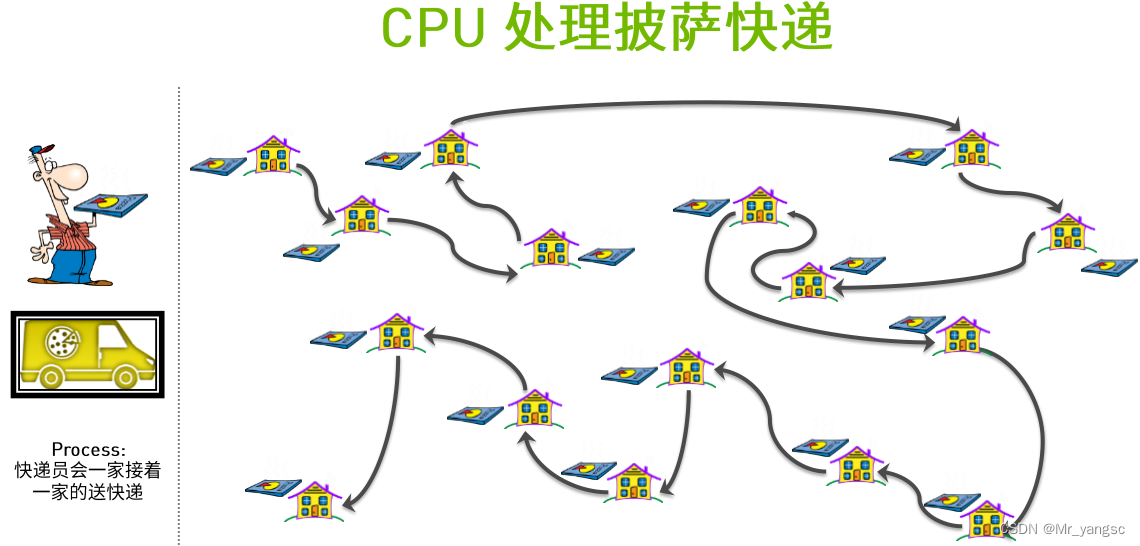

对于CPU单核的情况下意味着只有一个配送快递员(无论他的技艺水平有多高),于是为了完成配送任务,他需要一间房子一间房子的去完成配送。【串行】
而对于GPU(本身就是多核)来说,它可以同时派出多个配送员,一起去做配送工作。配送目的地之间独立,且无互相冲突【并行】
补:
显卡和GPU的区别:Much like a motherboard contains a CPU, a graphics card refers to an add-in board that incorporates the GPU. This board also includes the raft of components required to both allow the GPU to function and connect to the rest of the system.——Intel官网
查看GPU相关信息
方法一:命令行查看(硬件相关)
# 安装完CUDA之后,执行命令 nvidia-smi

方法二:代码查看(处理能力相关)
在cuda库中有专门关于存储显卡硬件的信息,信息存在了一个结构中,cudaDeviceProp数据结构:
cudaDeviceProp数据类型针对函式cudaGetDeviceProperties定义的,cudaGetDeviceProperties函数的功能是取得支持GPU计算装置的相关属性,比如支持CUDA版本号装置的名称、内存的大小、最大的thread数目、执行单元的频率等。如下所示:
// get the cuda device count cudaGetDeviceCount(&count);if (count == 0) { fprintf(stderr, "There is no device.\n"); return false; } // find the device >= 1.X int i; for (i = 0; i < count; ++i) { cudaDeviceProp prop; //接收设备相关信息参数 if (cudaGetDeviceProperties(&prop, i) == cudaSuccess) { if (prop.major >= 1) { printDeviceProp(prop); break; } } } // if can't find the device if (i == count) { fprintf(stderr, "There is no device supporting CUDA 1.x.\n"); return false; } // function printDeviceProp void printDeviceProp(const cudaDeviceProp &prop) { printf("Device Name : %s.\n", prop.name); printf("totalGlobalMem : %d.\n", prop.totalGlobalMem); printf("sharedMemPerBlock : %d.\n", prop.sharedMemPerBlock); printf("regsPerBlock : %d.\n", prop.regsPerBlock); printf("warpSize : %d.\n", prop.warpSize); printf("memPitch : %d.\n", prop.memPitch); printf("maxThreadsPerBlock : %d.\n", prop.maxThreadsPerBlock); printf("maxThreadsDim[0 - 2] : %d %d %d.\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]); printf("maxGridSize[0 - 2] : %d %d %d.\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]); printf("totalConstMem : %d.\n", prop.totalConstMem); printf("major.minor : %d.%d.\n", prop.major, prop.minor); printf("clockRate : %d.\n", prop.clockRate); printf("textureAlignment : %d.\n", prop.textureAlignment); printf("deviceOverlap : %d.\n", prop.deviceOverlap); printf("multiProcessorCount : %d.\n", prop.multiProcessorCount); }struct cudaDeviceProp { char name[256]; // 识别设备的ASCII字符串(比如,"GeForce GTX 940M") size_t totalGlobalMem; // 全局内存大小 size_t sharedMemPerBlock; // 每个block内共享内存的大小 int regsPerBlock; // 每个block 32位寄存器的个数 int warpSize; // warp大小 size_t memPitch; // 内存中允许的最大间距字节数 int maxThreadsPerBlock; // 每个Block中最大的线程数是多少 int maxThreadsDim[3]; // 一个块中每个维度的最大线程数 int maxGridSize[3]; // 一个网格的每个维度的块数量 size_t totalConstMem; // 可用恒定内存量 int major; // 该设备计算能力的主要修订版号 int minor; // 设备计算能力的小修订版本号 int clockRate; // 时钟速率 size_t textureAlignment; // 该设备对纹理对齐的要求 int deviceOverlap; // 一个布尔值,表示该装置是否能够同时进行cudamemcpy()和内核执行 int multiProcessorCount; // 设备上的处理器的数量 int kernelExecTimeoutEnabled; // 一个布尔值,该值表示在该设备上执行的内核是否有运行时的限制 int integrated; // 返回一个布尔值,表示设备是否是一个集成的GPU(即部分的芯片组、没有独立显卡等) int canMapHostMemory; // 表示设备是否可以映射到CUDA设备主机内存地址空间的布尔值 int computeMode; // 一个值,该值表示该设备的计算模式:默认值,专有的,或禁止的 int maxTexture1D; // 一维纹理内存最大值 int maxTexture2D[2]; // 二维纹理内存最大值 int maxTexture3D[3]; // 三维纹理内存最大值 int maxTexture2DArray[3]; // 二维纹理阵列支持的最大尺寸 int concurrentKernels; // 一个布尔值,该值表示该设备是否支持在同一上下文中同时执行多个内核 }

软硬件架构基础
GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此当我们在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device),如下图所示。

首先我们从宏观到微观的来直观看下CPU和GPU的物理构造:

从CPU和GPU的芯片结构上来看,可知,CPU的架构的计算单元(core较少,但是单核的计算能力较强),而GPU的架构计算单元非常多(其中一个深绿色的块就是一个计算单元,也即一个线程),但作为数量代价的是单核的计算能力相较cpu的单核肯定是有所下降;
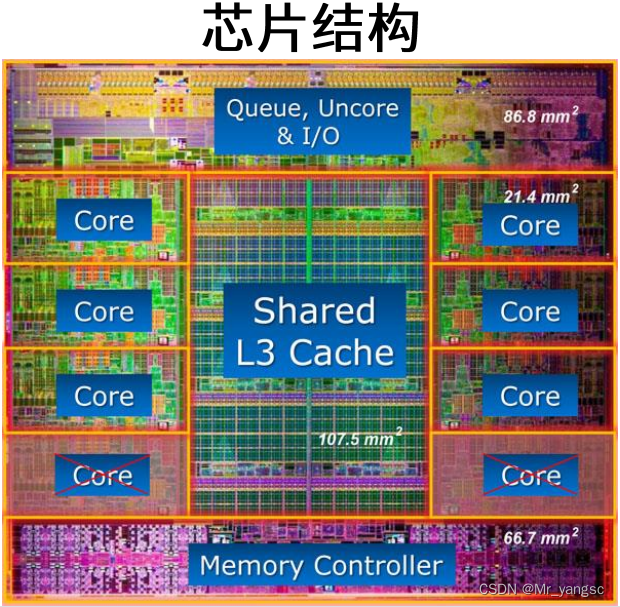

物理层(物理结构)
深入细节对GPU的硬件实现有一个基本的认识。后面会讲到kernel(核函数概念)的线程组织层次,那么一个kernel实际上会启动很多线程,这些线程是逻辑上并行的,但是在物理层却并不一定。这其实和CPU的多线程有类似之处,多线程如果没有多核支持,在物理层也是无法实现并行的。但是好在GPU存在很多CUDA核心,充分利用CUDA核心可以充分发挥GPU的并行计算能力。
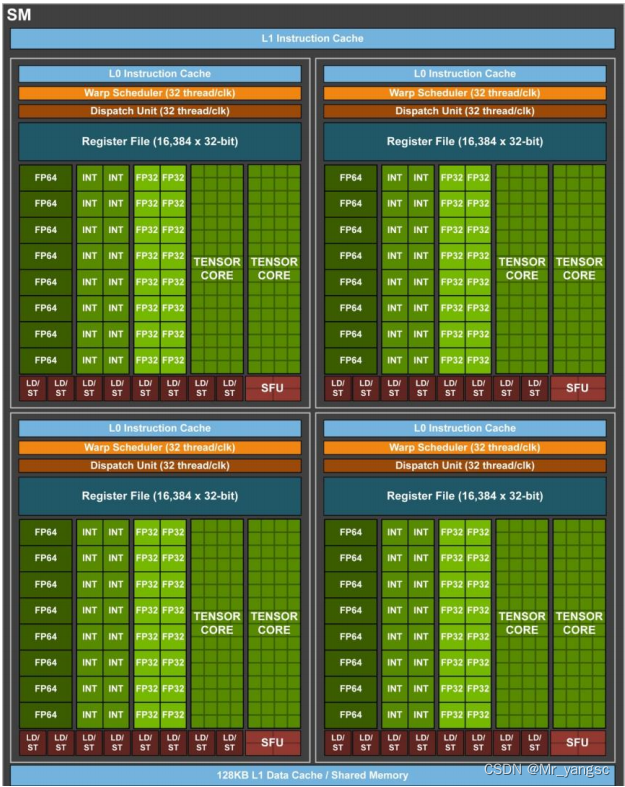
物理层级为:Device—>SM(Streaming Multiprocessor,采用的是SIMT (Single-Instruction, Multiple-Thread,单指令多线程)架构)——>warps(线程束,32个线程)(GPU的核心处理器,可以单独申请资源的最小单位)——>单线程核(每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径。)
SM(Streaming Multiprocessor):GPU硬件的一个核心组件是SM,前面已经说过,SM是英文名是 Streaming Multiprocessor,翻译过来就是流式多处理器。SM的核心组件包括CUDA核心,共享内存,寄存器等,SM可以并发地执行数百个线程,并发能力就取决于SM所拥有的资源数。当一个kernel被执行时,它的gird中的线程块被分配到SM上,一个线程块只能在一个SM上被调度。SM一般可以调度多个线程块,这要看SM本身的能力。那么有可能一个kernel的各个线程块被分配多个SM,所以grid只是逻辑层,而SM才是执行的物理层。
Warps:SM采用的是SIMT (Single-Instruction, Multiple-Thread,单指令多线程)架构,基本的执行单元是线程束(warps),线程束包含32个线程,这些线程同时执行相同的指令,
线程:每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径。所以尽管线程束中的线程同时从同一程序地址执行,但是可能具有不同的行为,比如遇到了分支结构,一些线程可能进入这个分支,但是另外一些有可能不执行,它们只能死等,因为GPU规定线程束中所有线程在同一周期执行相同的指令,线程束分化会导致性能下降。
当线程块被划分到某个SM上时,它将进一步划分为多个线程束,因为这才是SM的基本执行单元,但是一个SM同时并发的线程束数是有限的。这是因为资源限制,SM要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器。所以SM的配置会影响其所支持的线程块和线程束并发数量。
总之,就是网格和线程块只是逻辑划分,一个kernel的所有线程其实在物理层是不一定同时并发的。所以kernel的grid和block的配置不同,性能会出现差异,这点是要特别注意的。还有,由于SM的基本执行单元是包含32个线程的线程束,所以block大小一般要设置为32的倍数。
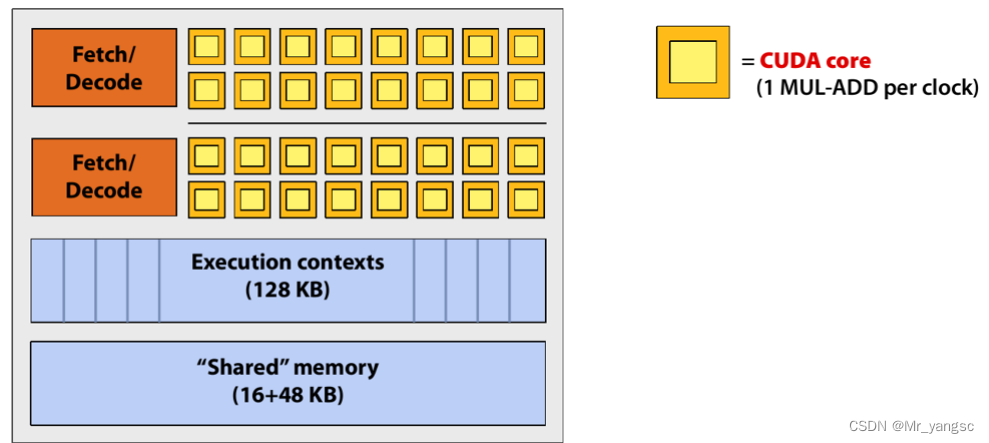
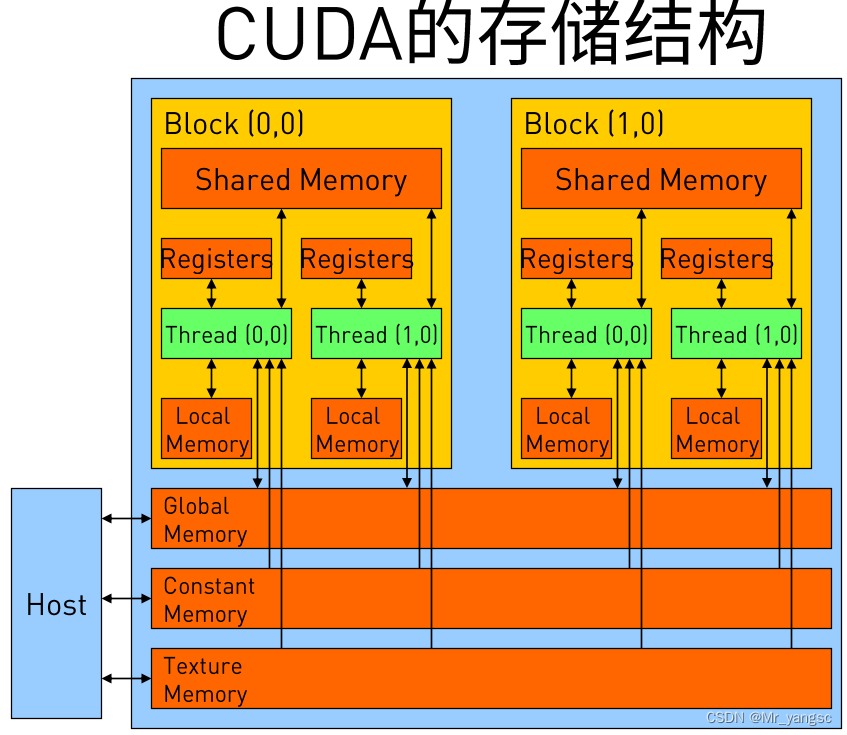
此外这里简单介绍一下CUDA的内存模型,如下图所示。可以看到,每个线程有自己的私有本地内存(Local Memory),而每个线程块有包含共享内存(Shared Memory),可以被线程块中所有线程共享,其生命周期与线程块一致。此外,所有的线程都可以访问全局内存(Global Memory)。还可以访问一些只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)。内存结构涉及到程序优化,这里不深入探讨它们。
逻辑层(kernel组织)
在编程中,那么多的线程(成千上万个)是否有一种方式来对它们进行一种结构化管理呢?当然是有的!这就是CUDA编程中的逻辑层,暗中其实也与物理层相合;
概念词:kernel,grid/block/thread
注:单个核函数的运行配置只涉及到block和thread的配置。更高层面的任务流的分配控制,才涉及到grid的安排。(前期学习的我自己比较困惑的地方)
Kernel
首先来了解何为GPU编程中的kernel,是CUDA中一个重要的概念,数据并行处理函数(核函数), 在GPU上执行的程序,一个Kernel对应一个Grid。
kernel是在device上线程中并行执行的函数,核函数用
__global__符号声明,在调用时需要用<<<grid, block>>>来指定kernel要执行的线程数量,在CUDA中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。由于GPU实际上是异构模型,所以需要区分host和device上的代码,在CUDA中是通过函数类型限定词开区别host和device上的函数,主要的三个函数类型限定词如下:
__global__:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。__device__:在device上执行,单仅可以从device中调用,不可以和__global__同时用。__host__:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。/* kernel函数的样例 1.在函数调用时,要通过<<< >>>来确定线程的数量。 2..调用kernel函数时各个参数的含义: Dg:int型或者dim3类型(x,y,z),用于定义一个Grid中Block是如何组织的,如果是int型,则表示一维组织结构 Db:int型或者dim3类型(x,y,z),用于定义一个Block中Thread是如何组织的,如果是int型,则表示一维组织结构 Ns:size_t类型,可缺省,默认为0; 用于设置每个block除了静态分配的共享内存外,最多能动态分配的共享内存大小,单位为byte。 0表示不需要动态分配。 S:cudaStream_t类型,可缺省,默认为0。 表示该核函数位于哪个流。 */ // CUDA核函数的定义 __global__ void addKernel(int *c, const int *a, const int *b) { int i = threadIdx.x; c[i] = a[i] + b[i]; } // CUDA核函数调用 addKernel<<<Dg,Db, Ns, S>>>(c, a, b);
Grid/Block/Thread
CUDA的软件架构由网格(Grid)、线程块(Block)和线程(Thread)组成,相当于把GPU上的计算单元分为若干(2~3)个网格,每个网格内包含若干(65535)个线程块,每个线程块包含若干(512)个线程,三者的关系如下图:
Thread,block,grid是CUDA编程上的概念,为了方便程序员软件设计,组织线程。
- thread:一个CUDA的并行程序会被以许多个threads来执行。
- block:数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
- grid:多个blocks则会再构成grid
补:关于grid,block,thread之间的计算,以及全局和局部位置之间的对应关系计算;
要深刻理解kernel,必须要对kernel的线程层次结构有一个清晰的认识。首先GPU上很多并行化的轻量级线程。kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次,而网格又可以分为很多线程块(block),一个线程块里面包含很多线程,这是第二个层次。线程两层组织结构如下图所示,这是一个gird和block均为2-dim的线程组织。grid和block都是定义为
dim3类型的变量,dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,缺省值初始化为1。因此grid和block可以灵活地定义为1-dim,2-dim以及3-dim结构,对于图中结构(主要水平方向为x轴),定义的grid和block如下所示,kernel在调用时也必须通过执行配置<<<grid, block>>>来指定kernel所使用的线程数及结构。dim3 grid(3, 2); dim3 block(5, 3); kernel_fun<<< grid, block >>>(prams...);举个例子:
所以,一个线程需要两个内置的坐标变量(blockIdx,threadIdx)来唯一标识),它们都是
dim3类型变量,其中blockIdx指明线程所在grid中的位置,而threaIdx指明线程所在block中的位置,如图中的Thread (1,1)满足://threadIdx指的是在当前block中的相对位置 //而非全局线性排序后的位置 threadIdx.x = 1 threadIdx.y = 1 //当前grid中的相对位置 blockIdx.x = 1 blockIdx.y = 1一个线程块上的线程是放在同一个流式多处理器(SM)上的,但是单个SM的资源有限,这导致线程块中的线程数是有限制的,现代GPUs的线程块可支持的线程数可达1024个。有时候,我们要知道一个线程在blcok中的全局ID,此时就必须还要知道block的组织结构,这是通过线程的内置变量blockDim来获得。它获取线程块各个维度的大小。对于一个2-dim的block (Dx,Dy) ,线程 (x,y) 的ID值为 (x+y∗Dx) ,如果是3-dim的block (Dx,Dy,Dz) ,线程 (x,y,z) 的ID值为 (x+y∗Dx+z∗Dx∗Dy) 。另外线程还有内置变量gridDim,用于获得网格块各个维度的大小。
Grid/Block/Thread都是软件的组织结构,并不是硬件的,因此理论上我们可以以任意的维度(一维、二维、三维)去排列Thread;在硬件上就是一个个的SP,并没有维度这一说,只是软件上抽象成了具有维度的概念。(其实这些组织更是把所有的线程按照一定的方式进行排列,为了使用者更好的去对每个线程进行指派任务。)
####################################################################
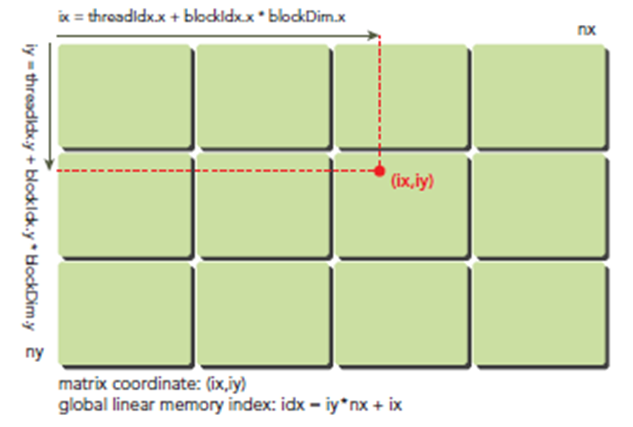
举例计算:关于threadIdx的局部坐标和全局线性位置对应
首先可以将thread和block索引映射到矩阵坐标:
ix = threadIdx.x + blockIdx.x * blockDim.x
iy = threadIdx.y + blockIdx.y * blockDim.y
之后可以利用上述变量计算线性地址:
idx = iy * nx + ix
全部公式 & 相关信息的获取:
gridDim.x-线程网络X维度上线程块的数量
gridDim.y-线程网络Y维度上线程块的数量
blockDim.x-一个线程块X维度上的线程数量
blockDim.y-一个线程块Y维度上的线程数量
blockIdx.x-线程网络X维度上的线程块索引
blockIdx.y-线程网络Y维度上的线程块索引
threadIdx.x-线程块X维度上的线程索引
threadIdx.y-线程块Y维度上的线程索引
//1、 grid划分成1维,block划分为1维 int threadId = blockIdx.x *blockDim.x + threadIdx.x; //2、 grid划分成1维,block划分为2维 int threadId = blockIdx.x * blockDim.x * blockDim.y+ threadIdx.y * blockDim.x + threadIdx.x; //3、 grid划分成1维,block划分为3维 int threadId = blockIdx.x * blockDim.x * blockDim.y * blockDim.z + threadIdx.z * blockDim.y * blockDim.x + threadIdx.y * blockDim.x + threadIdx.x; //4、 grid划分成2维,block划分为1维 int blockId = blockIdx.y * gridDim.x + blockIdx.x; int threadId = blockId * blockDim.x + threadIdx.x; //5、 grid划分成2维,block划分为2维 int blockId = blockIdx.x + blockIdx.y * gridDim.x; int threadId = blockId * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x; //6、 grid划分成2维,block划分为3维 int blockId = blockIdx.x + blockIdx.y * gridDim.x; int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z) + (threadIdx.z * (blockDim.x * blockDim.y)) + (threadIdx.y * blockDim.x) + threadIdx.x; //7、 grid划分成3维,block划分为1维 int blockId = blockIdx.x + blockIdx.y * gridDim.x + gridDim.x * gridDim.y * blockIdx.z; int threadId = blockId * blockDim.x + threadIdx.x; //8、 grid划分成3维,block划分为2维 int blockId = blockIdx.x + blockIdx.y * gridDim.x + gridDim.x * gridDim.y * blockIdx.z; int threadId = blockId * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x; //9、 grid划分成3维,block划分为3维 int blockId = blockIdx.x + blockIdx.y * gridDim.x + gridDim.x * gridDim.y * blockIdx.z; int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z) + (threadIdx.z * (blockDim.x * blockDim.y)) + (threadIdx.y * blockDim.x) + threadIdx.x;


物理层和逻辑层的总结
Stream(流)
流是一系列顺序执行的命令,流之间相对无序或并发的执行他们的命令。Streaming Multiprocessor(SM)
多个SP加上其他的一些资源组成一个SM。其他资源包括存储资源,共享内存,寄储器等。一个SM中的所有SP是先分成warp,共享同一个memory和instruction unit。
每个SM通过使用两个特殊函数(Special Function Unit,SFU)单元进行超越函数和属性插值函数(根据顶点属性来对像素进行插值)计算。SFU用来执行超越函数、插值以及其他特殊运算。Warp
warp是SM调度和执行的基础概念,同时warp实际上是一个和硬件相关的概念,通常一个SM中的SP(thread)会分成几个warp(SP在SM中是进行物理上的分组),每一个wrap中在Tegra中是32个thread。这个wrap中的32个thread(SP)是一起工作的,执行相同的指令,如果没有这么多thread需要工作,那么这个wrap中的一些thread(SP)是不工作的。
P.S. 每一个线程都有自己的寄存器内存和local memory,一个warp中的线程是同时执行的,也就是当进行并行计算时,线程数尽量为32的倍数,如果线程数不上32的倍数的话;假如是1,则warp会生成一个掩码,当一个指令控制器对一个warp单位的线程发送指令时,32个线程中只有一个线程在真正执行,其他31个 进程会进入静默状态。Streaming Processor(SP)
最基本的处理单元, 具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。现在SP的术语已经有点弱化了,而是直接使用thread来代替。一个SP对应一个thread。Grid、Block与Thread
在利用CUDA进行编程时,一个grid分为多个block,而一个block分为多个thread。划分的依据是任务特性和GPU本身的硬件特性。grid、block和thread是软件概念,而非硬件的概念。从硬件角度讲,一个GPU由多个SM组成(当然还有其他部分),一个SM包含有多个SP(以及还有寄存器资源,shared memory资源,一级缓存(L1 cache),scheduler(调度器),SPU,LD/ST单元(读取单元)等等),1.x硬件,一个SM包含8个SP,2.0是32个,2.1是48个,3.0和3.5是192个。以及SP目前也称为CUDA CORE,而SM目前也称为MP,在KEPLER架构(SM3.0和3.5)下也称为SMX。
从软件角度讲,CUDA因为是SIMT的形式,grid和block是thread的组织形式。thread是最小的逻辑单位,wrap是最小的硬件执行单位,若干个thread(典型值是128~512个)组成一个block,block被加载到SM上运行,多个block组成整体的grid。
P.S. SIMT: SIMT中文译为单指令多线程,英文全称为Single Instruction Multiple Threads。GPU中的SIMT体系结构相对于CPU的SIMD中的概念。为了有效地管理和执行多个单线程,多处理器采用了SIMT架构。此架构在第一个unified computing GPU中由NVIDIA公司生产的GPU引入。不同于CPU中通过SIMD(单指令多数据)来处理矢量数据;GPU则使用SIMT,SIMT的好处是无需开发者费力把数据凑成合适的矢量长度,并且SIMT允许每个线程有不同的分支。 纯粹使用SIMD不能并行的执行有条件跳转的函数,很显然条件跳转会根据输入数据不同在不同的线程中有不同表现,这个只有利用SIMT才能做到。
总的来说,在GPU中最小的硬件单元是SP(这个术语通常使用thread来代替),而硬件上一个SM中的所有SP在物理上是分成了几个wrap,每一个warp包含一些thread,warp中的SP是可以同时工作的,但是执行相同的指令,也就是说取指令单元取一条指令同时发射给WARP中的所有的SP(假设SP都需要工作,否则有些是空闲的)。可见,在硬件上一个SM > WARPS > SP(thread)。从软件thread组织方面来看,因为一个SM中是分WARP的,而一个WARP包含一定数目(比如Tegra的32个)的SP(thread),因此最好按照这个数目来组织thread,否则硬件该warp上有些SP是不工作的。

参考
(3条消息) GPU概念:Thread, Block, Grid, Warp, SP, SM_Kevyn7的博客-CSDN博客_gpu warp
CUDA学习3-Grid&Block_AplusX的博客-CSDN博客_cuda grid
(3条消息) CUDA软件架构—网格(Grid)、线程块(Block)和线程(Thread)的组织关系以及线程索引的计算公式_-牧野-的博客-CSDN博客_线程块