历时3天,Hadoop集群终于搭建完成了,来记录一下,感兴趣的小伙伴也可以来一起学习,顺便分享下自己第一次测试成功的喜悦,如果有异常,也可以发上来一起讨论解决,下面我记录下整个过程以及中间产生的各种问题(仅限本次测试产生的一些问题,做记录)
启动集群
start-all.sh

启动完毕,检查下启动情况: master主机看到六个开启的进程,node1和node2看到三个开启的进程表示启动成功。(从节点必须3个)
主节点:

从节点node1:
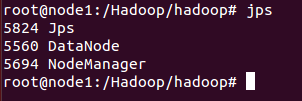
从节点node2:

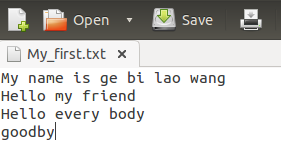
生成测试文件:

我生成了一个txt文档,并命名为我的第一次,具体内容如下:
将文件拷贝到HDFS中去,首先我们看看HDFS下目前都有什么
1、列出HDFS里的文件:ls命令
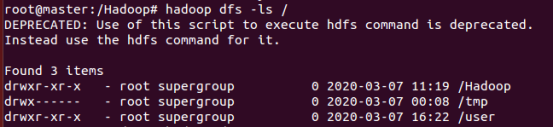
从两张图对比我们可以看出来,/目录下是有3个文件夹,而user什么也没有(user使我创建的一个文件夹)
在user下再创建一个文件夹
hadoop dfs -mkdir /user/input
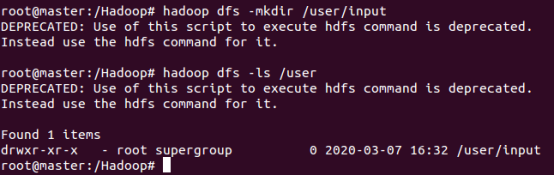
此时user下面多了一个input文件
将需要测试的文件上传到hdfs上面
hadoop dfs -put My_first.txt /user/input (注意,我这里本地路径下就存在这个txt文件,根据路径自己修改。反正这个语句的意思就是拷贝文件到位置)
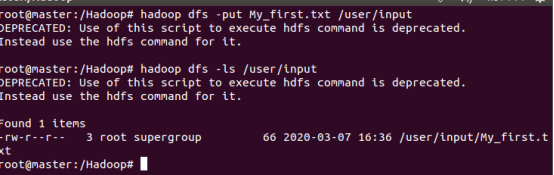 接着运行程序输入下面的命令
接着运行程序输入下面的命令
hadoop jar /Hadoop/hadoop/shar/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount /user/input/My_first.txt /user/output (这里输出输入他都会自动的,你只需要告诉他那个文件就行了)

 大致就是出来这么一堆东西
大致就是出来这么一堆东西
然后输入查看命令
首先我们查看文件下都有什么文件
hadoop dfs -ls /user/output
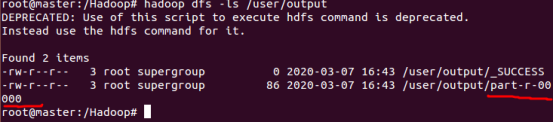
最后让我们打开看看这个文件吧!
hadoop dfs -cat /user/output/part-r-00000

大功告成!
建议--------在运行完成了之后养成清理垃圾文件的习惯。
附带几个常用的命令:
Hadoop 从HDFS中删除文件夹命令:
hadoop fs -rm -r -skipTrash /folder_name
例如:
hadoop fs -rm -r -skipTrash /user
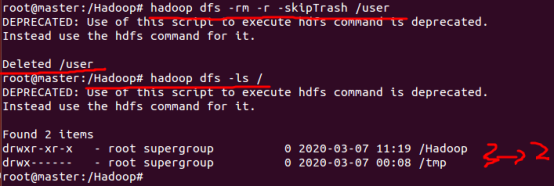
(下面会说我们在运行时产生的一些问题,小伙伴们可以了解下或者留下你的问题大家一起讨论)
1、首先在一开始运行的时候,只要不出现什么INFO之类的,肯定会出现WARN或者ERROR,像我这里就出现了WARN
WARN hdfs.DFSClient: Caught exception java.lang.InterruptedException
这个是Hadoop的一个bug,不用理会
2、Hadoop运行错误–输出重复
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://master:9000/output already exists
☆重点标记,你运行出结果的文件直接查是查不到的,一定要用hadoop命令下的指定输出位置去查,我刚开始就想,我输出那个位置怎么没有output文件夹,咋回事,后来用了hadoop命令去查看竟然有。
所以要想删除,必须用 hadoop命令指定删除,给个代码:
hadoop fs -rm -r /user/output
3、Hadoop运行错误–无输入文件
org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist
出现这个问题的原因是文件没有上传到HDFS上面去,所有的文件操作都是在HDFS上面的,所以需要将要处理的文件上传到HDFS
4、Hadoop在运行时一直卡住
集群卡在INFO mapreduce.Job: Running job: job_1457182697428_0001
出现这个问题是因为资源分配问题,默认值超出了机器配置或者不匹配,参考:
https://blog.csdn.net/SCGH_Fx/article/details/60783466
运行默认例子 【hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar pi 10 10】卡在ACCEPT,running 不显示map的解决办法: 因为我在mapred-site.xml中指定了yarn框架: 【 mapreduce.framework.name yarn 】而又没有配置yarn,所以导致无法调度任务,删去这里的框架指定,或者配置yarn即可解决; 路过特此记录。