1. 部署方式选择
基于Kafka3.X后的集群搭建方式主要分为两种,一种是基于Zookeeper管理方式,一种是基于KRaft模式,本文主要介绍Kafka-KRaft集群模式搭建
纠正文章1.Kafka系列之K8S部署单节点中基于Zookeeper方式的部署方式错误,其实是基于KRaft启动的,所以不部署Zookeeper也可以,可以通过把连接ZK的环境去掉看是否可以启动成功验证

2.KRaft模式介绍
Apache Kafka 不依赖 Apache Zookeeper的版本,被社区称之为 Kafka Raft 元数据模式,简称KRaft模式。
KRaft运行模式的Kafka集群,不会将元数据存储在 Apache ZooKeeper中。即部署新集群的时候,无需部署ZooKeeper集群,因为Kafka将元数据存储在 Controller 节点的 KRaft Quorum中。KRaft可以带来很多好处,比如可以支持更多的分区,更快速的切换Controller,也可以避免Controller缓存的元数据和Zookeeper存储的数据不一致带来的一系列问题
3. 编写install.sh
我们基于Helm进行安装,在此不在讲解Helm安装方式
helm repo add bitnami https://charts.bitnami.com/bitnami
# 指定命名空间为middleware,如果卸载后再次安装,install改为upgrade
helm install kafka bitnami/kafka --namespace middleware
--set kafkaVersion=3.4.0
--set replicaCount=3
--set kafka.persistence.enabled=false
--set kafka.kafkaConfigOverrides=transaction.state.log.replication.factor=3
--set kafka.kafkaConfigOverrides=transaction.state.log.min.isr=2
--set kafka.kafkaConfigOverrides=default.replication.factor=3
--set kafka.kafkaConfigOverrides=num.io.threads=8
--set kafka.kafkaConfigOverrides=num.network.threads=3
--set kafka.kafkaConfigOverrides=log.message.format.version=3.4
--set kafka.kafkaConfigOverrides=inter.broker.protocol.version=3.4
--set kafka.kafkaConfigOverrides=offsets.topic.replication.factor=3
--set kafka.kafkaConfigOverrides=transaction.state.log.num.partitions=50
--set-string labels.app.kubernetes.io/managed-by=Helm
--set-string labels.meta.helm.sh/release-name=kafka
--set-string labels.meta.helm.sh/release-namespace=middleware
打印日志
space=middleware
NAME: kafka
LAST DEPLOYED: Sun May 21 13:56:26 2023
NAMESPACE: middleware
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: kafka
CHART VERSION: 22.1.2
APP VERSION: 3.4.0
** Please be patient while the chart is being deployed **
Kafka can be accessed by consumers via port 9092 on the following DNS name from within your cluster:
kafka.middleware.svc.cluster.local
Each Kafka broker can be accessed by producers via port 9092 on the following DNS name(s) from within your cluster:
kafka-0.kafka-headless.middleware.svc.cluster.local:9092
kafka-1.kafka-headless.middleware.svc.cluster.local:9092
kafka-2.kafka-headless.middleware.svc.cluster.local:9092
To create a pod that you can use as a Kafka client run the following commands:
kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:3.4.0-debian-11-r28 --namespace middleware --command -- sleep infinity
kubectl exec --tty -i kafka-client --namespace middleware -- bash
PRODUCER:
kafka-console-producer.sh \
--broker-list kafka-0.kafka-headless.middleware.svc.cluster.local:9092,kafka-1.kafka-headless.middleware.svc.cluster.local:9092,kafka-2.kafka-headless.middleware.svc.cluster.local:9092 \
--topic test
CONSUMER:
kafka-console-consumer.sh \
--bootstrap-server kafka.middleware.svc.cluster.local:9092 \
--topic test \
--from-beginning

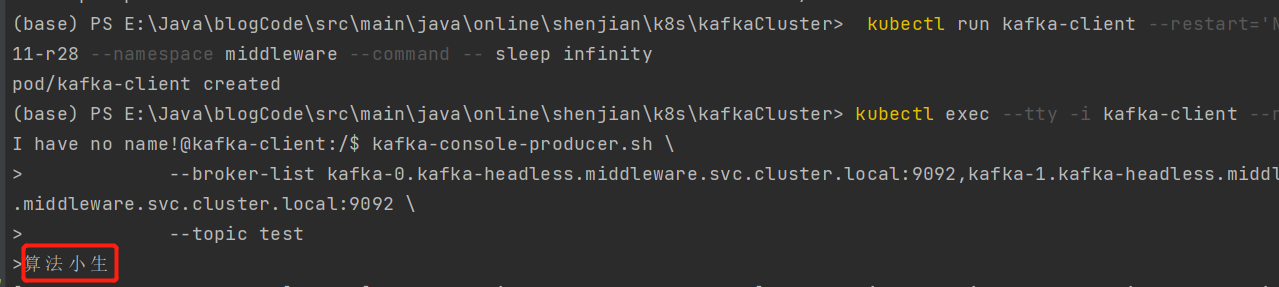
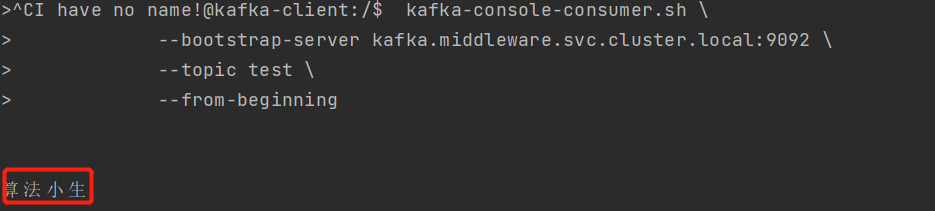
4. 验证生产者与消费者
安装打印日志的提示,我们发送 算法小生 消息至test主题,并进行消费,OK
5. 节点部分失败模拟
我们手工删除kafka01,由于是Statefulsets部署方式:和 Deployment 类似, StatefulSet 管理基于相同容器规约的一组 Pod。但和 Deployment 不同的是, StatefulSet 为它们的每个 Pod 维护了一个有粘性的 ID。这些 Pod 是基于相同的规约来创建的, 但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID

所在再次进行消费的时候,还可以看到 算法小生 仍然正常消费
6. 安装卸载uninstall.sh
#!/bin/bash
set -e
# 定义变量
NAMESPACE="middleware"
RELEASE_NAME="kafka"
# 删除Kafka实例
helm delete "$RELEASE_NAME" --namespace "$NAMESPACE"
# 等待Kafka实例完全删除
echo "等待Kafka实例删除..."
while kubectl get statefulsets -n "$NAMESPACE" | grep "$RELEASE_NAME"; do
echo "等待Kafka实例删除..."
sleep 5
done
echo "卸载完成"
注意:当我们执行install.sh后,再次执行消费test主题,也可以看到 算法小生 输出,这个证明了Statefulsets在删除后,不会删除持久卷,即数据不会被删除
欢迎关注公众号算法小生