本文来自社区分享,仅限交流探讨。原文作者:李婵玲,某智能车企DBA。欢迎访问 OceanBase 官网获取更多信息:https://www.oceanbase.com/

最近一年,我们完成了从MySQL到OceanBase的替代过程,既降低了架构复杂度和存储成本,又提高了扩展性和吞吐量,而且再也不用担心数据不一致问题了。故而将我们遇到的痛点问题、解决方案、技术选型过程总结成此文,供大家参考。
一、业务增长凸显MySQL八大支撑瓶颈
相信很多企业都会因为业务快速发展,数据成指数级增长带来一些新的需求或系统瓶颈。我所在的国内某知名智能车企也面临这样的问题,特别是我们的业务监控数据和信号数据在近几年爆发式增长,我们过去使用的MySQL数据库越来越难以应对,主要体现为以下八个方面。
-
性能瓶颈:单台服务器难以承受大规模数据和请求访问,导致数据库性能下降,只能通过部署多套集群解决。
-
水平扩展困难:单集群容量达到瓶颈时,无法实现无缝扩展,需要停机维护,影响业务运行。
-
数据一致性难以保证:多集群数据合并的时候,数据更新同步难度大,易出现数据不一致的情况。
-
多活实现困难:多活场景下,无法保证业务双写。
-
实效性差:多集群的跨节点join操作需要内存运算,或者大数据整合后提供,时效性无法保证。
-
容易造成集群数据或流量倾斜。
-
各集群之间数据调度麻烦。
-
运维压力大:需要定期备份归档数据,排查数据问题。
为了解决上述八个问题,我们需要制定高效的数据库解决方案,于是开始了数据库的调研、选型、替换之旅。
二、分布式数据库选型十要素
根据业务需求分析,我们决定拥抱分布式数据库,并以十个方面为考虑因素对市面上的分布式数据库产品展开调研。
-
数据模型:支持的数据模型是否丰富?能否满足各种应用场景?
-
性能:性能是否足够优秀?理论读写性能、事务能达到多少?并发能力和水平扩展能力如何?
-
可用性和容错性:RPO、RTO能达到多少?容错机制怎么样?备份与恢复能力如何?通过什么样的机制保证数据的高可用和可靠性?集群管理和运维能力如何?
-
安全性:安全策略有哪些?能否对数据进行加密?身份验证如何和?访问控制如何?
-
生态环境:生态如何?基本工具如何?社区与商业支持如何?
-
成本效益:开发对接成本如何?同样需求的部署成本如何?同等数据量的存储成本如何?以及后续扩容的成本和运维成本如何?采购成本如何?
-
可扩展性:节点数量有无限制?使用什么分布式架构?集群是如何管理的?
-
应用场景:需要了解数据库的适用场景和行业应用,是否有成功案例?
-
是否自研:全自研?还是部分自研?
-
是否支持单元化场景?
(一)TiDB与OceanBase多方面对比
通过筛选,最终选定两个分布式数据库产品:TiDB、OceanBase,并从分库分表、兼容性、多活容灾、性能、安全性、成本、生态等环境进行对比。
首先,两种数据库类型应用设计方面,都对业务透明,对外表现为一个整体数据库,不需要业务进行分库分表。
其中TiDB是自动分区,底层自动使用region(默认96M)打散;不支持多租户功能,资源无法隔离,同集群的业务相互影响;提供TiDB节点配合负载均衡使用。
OceanBase可以根据业务规则设计最优数据模型,支持一级分区和二级分区,支持分区裁剪;支持多租户,可做到租户间资源隔离;提供OBProxy无状态代理,支持部署在OB服务器,对于延时要求较高的服务,可以以SIdeCar模式部署在应用Pod中,应用本地回环地址访问。
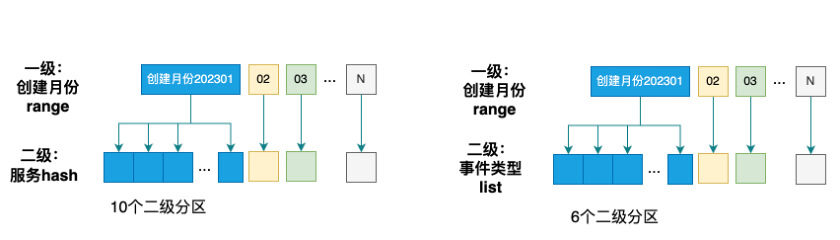
其次,应⽤和数据库解耦方面,Oceanbase与TiDB都高度兼容MySQL,方便业务平滑迁移。OceanBase3.x不支持的少许alter类型变更在4.1已支持(如:int到varchar)。
再次,对于异地多活架构,二者均可实现两地三中⼼多活部署,以及同城的两中⼼双活。不过OceanBase采用的Paxos协议对于复杂⽹络环境的容忍性比TiDB采用的 Raft更强。
最后,在运维管理方面,OceanBase和TiDB都具备查询慢SQL、执行计划、终止异常session等。OceanBase提供OCP平台进行管理集群,OBD黑屏命令辅助,TiDB提供dashboard平台和Tiup黑屏命令进行集群管理。
此外,我们针对产品调研时关注的十个方面也进行了详细对比,数据如下表。
| 对比项 | OceanBase | TiDB |
|---|---|---|
| 数据模型 | 关系型、半结构化、非关系型、图、时序 | 非关系型、半结构化、关系型 |
| 数据库性能 | 以优异的成绩经过TPC-C 测试,经过阿里系双十一的验证 | 未经过互联网高并发核心业务的验证 |
| 可用性与容错性 | 4.0支持6级容灾标准(RPO=0,RTO<8s),支持三地五中心 | RPO=0,RTO<30s,支持两地三中⼼ |
| 安全性 | 租户资源隔离,租户内的操作只会影响租户、租户管理 | 无资源隔离,使用时集群内会相互影响 |
| 生态环境 | 生态稍微差些,但是企业配套极为丰富,且经历了多少核心场景验证 | 开源社区活跃,生态较为健全 |
| 成本效益 | 兼容MySQL与Oracle,改动极小,租户按需配置资源,最小需要3obproxy,3observer,存储成本降低70%~90% | 兼容MySQL5.7,整个集群一套,无资源隔离,部署成本相对较高(需要3pd-server,2tidb-server,tikv-server) |
| 可扩展性 | 存算一体,支持数千个节点,单集群数据量超3PB,最大单表行达万亿级,使用Multi-Paxos,数据可以动态漂移; | 存算分离,使用Multi-Raft, |
| 应用场景 | 支付宝、网商银行 | 大多都是OLAP场景 |
| 是否自研 | 全自研 | Tikv基于RocksDB进行数据存储 |
经过综合对比,我们倾向于使用OceanBase,那么,OceanBase真能解决MySQL的痛点吗?我们接下来看下OceanBase和MySQL有哪些实际区别。
MySQL 与 OceanBase压测对比
我们尽可能使用同样的配置进行测试对比,数据如下。
硬件配置与软件版本
硬件配置
| 服务类型 | 实例数 | 机器配置 | 租户配置 |
|---|---|---|---|
| OceanBase 数据库 | 3 | 56C238G,35T本地SSD | 20C90G |
| Sysbench | 1 | 16C32G | |
| ODP | 1 | 46C258G | |
| MySQL | 1 | 32C128G,SSD800G |
补充说明一下,MySQL的机器配置虽然是32C128G,实际上我们通过参数配置最后和Oceanbase的20C90G保持一致;
软件版本
| 服务类型 | 软件类型 |
|---|---|
| OceanBase 数据库 | OceanBase V3.2.3.1 |
| ODP | obproxy V3.8 |
| MySQL | MySQL5.7.31 |
| Sysbench | sysbench 1.0.17 |
| OS | CentOS Linux release 7.5.1804 (Core) |
压测结果对比
TPS/QPS对比如下:

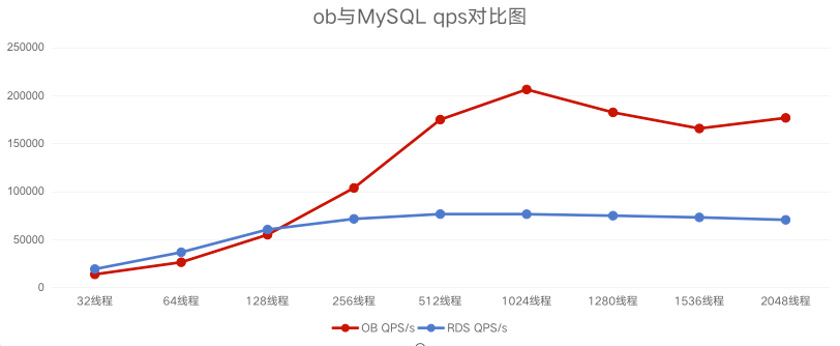
压测结论
• 线程数 < 200时,MySQL在TPS、OPS方面表现更好;
• 线程数 > 200时,OceanBase在TPS、OPS方面表现更好;
• OceanBase的3个节点的集群能达到20w的qps;
经过压测,OceanBase的高可用、高并发能力完全能满足我们的业务需求,同时,我们在压测的时候进行故障模拟,能达到官方所说的RPO=0,RTO<30s(我们压测的3.x的版本,4.x的RTO可以达到8s以下)。另外,动态扩容基本上也无感知,通过租户管理让业务数据隔离;我们用OMS将业务压测的测试数据同步到OceanBase上,能够实现业务在测试环境无缝切换到Oceanbase上。所以我们决定部署OceanBase。
三、业务迁移过程及注意事项
经过压测,我们发现OceanBase在高并发的情况下,除了QPS的性能不错外,还使用了LSM-Tree的存储结构(主要分为两方面:MemTable代表内存、 SSTable代表磁盘)。理论上只要服务的内存足够大,基本上都是内存写(转储的时候,性能会有一定的下降),这比较适合我们的业务监控数据和信号数据。同时,OceanBase支持单张万亿级数据的表,完全能满足我们的需求,还不需要做数据的归档。
我们的业务监控数据和信号数据,以接收为主,主要是写,前端应用会有一些场景通过id去查基线数据。在平台端,根据监控数据做指标计算,以流的方式处理。我们的信号数据也差不多类似的场景,OceanBase的压测情况,完全能满足我们的需求。
第一步,分区表设计
首次设计分区表的表结构如下:
-- 分区字段是create_time,类型TIMESTAMP
CREATE TABLE biz_monitor (
id bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
biz_name varchar(50) NOT NULL COMMENT '业务名称',
event_type varchar(50) NOT NULL COMMENT '事件类型',
....,
create_time TIMESTAMP NOT NULL COMMENT '创建时间',
PRIMARY KEY (id,create_time)
)AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COMMENT = '业务监控数据表'
PARTITION BY RANGE(UNIX_TIMESTAMP(create_time))
(
PARTITION M202301 VALUES LESS THAN(UNIX_TIMESTAMP('2023-02-01')),
PARTITION M202302 VALUES LESS THAN(UNIX_TIMESTAMP('2023-03-01')),
PARTITION M202303 VALUES LESS THAN(UNIX_TIMESTAMP('2023-04-01'))
);
为了保证业务上线OceanBase后的稳定性,我们根据业务场景对OceanBase进行了压测。 期间遇到了问题:压测期间机器的CPU大约50%左右,说明未达到瓶颈,但QPS一直压测不上去,TopSQL也没有特别慢,大约30ms左右。
最后的租户配置是12C40G*4unit
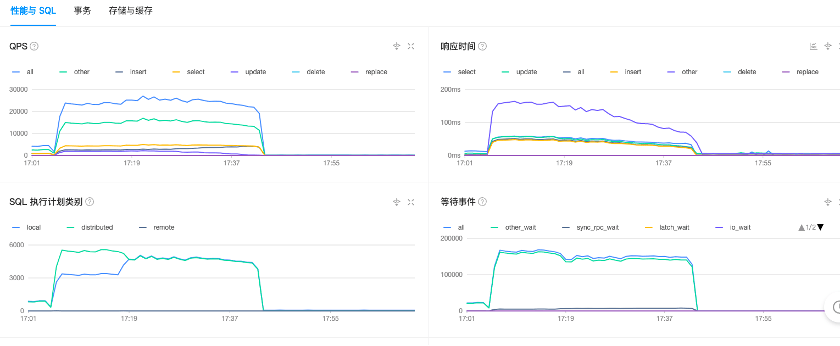
从监控数据可知:
- 压测期间机器的CPU大约50%左右,未达到瓶颈。
- 响应时间较慢,对于other类型需要100ms以上。
- 等待事件也较多,其中other_wait最多。
而且配置由6C20G * 4(primary zone)改为 12C40G * 4(zone1,zone2,zone3)未见QPS由提升,最多的QPS只有2.5w左右。
经过分析,发现业务存在单独使用表id进行查询的情况,查询耗时30ms以上,执行次数较多,导致CPU总耗时较长,具体信息如下图TopSQL所示。

针对分区表直接使用id查询的情况,我们调整了分区表的结构(如下所示),将主键调整为分区字段在前,id在后的形式,再加入一个单独的id全局唯一索引。表结构调整后,该sql的性能得到了极大提升,从30ms降低至5ms左右。
-- 分区字段是create_time,类型TIMESTAMP,将主键调整为分区字段在前,id在后的形式,然后再加入一个单独的id全局唯一索引
CREATE TABLE biz_monitor (
id bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
biz_name varchar(50) NOT NULL COMMENT '业务名称',
event_type varchar(50) NOT NULL COMMENT '事件类型',
....,
create_time TIMESTAMP NOT NULL COMMENT '创建时间',
PRIMARY KEY (create_time,id),
UNIQUE KEY `uniq_id` (`id`) global
)AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COMMENT = '业务监控数据表'
PARTITION BY RANGE(UNIX_TIMESTAMP(create_time))
(
PARTITION M202301 VALU,ES LESS THAN(UNIX_TIMESTAMP('2023-02-01')),
PARTITION M202302 VALUES LESS THAN(UNIX_TIMESTAMP('2023-03-01')),
PARTITION M202303 VALUES LESS THAN(UNIX_TIMESTAMP('2023-04-01'))
);
第二步,使用OMS进行数据迁移
将数据从MySQL迁移到OceanBase的时候,我们选择了OceanBase 数据库一站式数据传输和同步的产品OMS(如下图),它支持多种关系型数据库、消息队列与 OceanBase 数据库之间的数据复制,是集数据迁移、实时数据同步和增量数据订阅于一体的数据传输服务。使用OMS进行数据迁移,极大地简化了DBA的工作。
使用OMS数据迁移的流程如下。

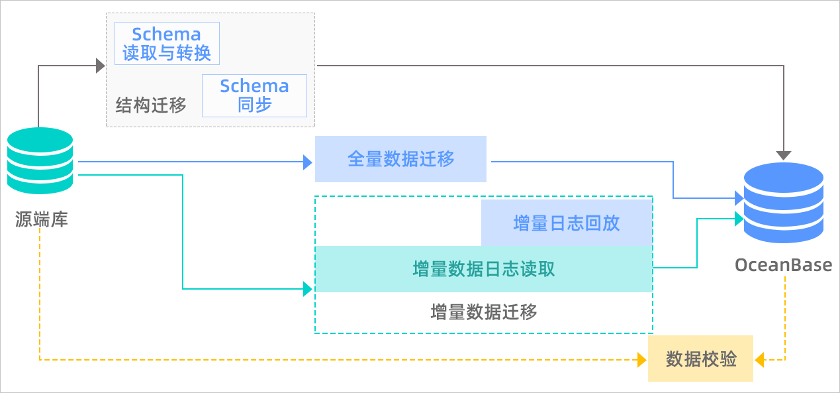
值得一提的是, 使用 OMS 需要注意两点 :一是迁移和全量校验对原业务有一定的影响,建议迁移时选择业务低峰期或者从库进行;二是迁移时建议调大租户的内存,避免Over tenant memory limits问题。
四、总结
以上就是我们解决MySQL痛点的过程,那么替换为OceanBase以后真的有效吗?
就目前的使用效果来看,OceanBase给我们 的业务带来了七方面的明显提升。
-
降低了业务系统的复杂度,集群从有状态变成了无状态,服务的稳定性提高,开发运维成本降低。
-
在流量倾斜时,我们可以动态的切换主从副本,从而快速的实现流量转移。
-
当有突发流量的时候,我们可以快速的扩展,提升整体的吞吐量。
-
集群内join操作,通过表组优化后,能实时提供。
-
我们一套OceanBase集群写吞吐量是之前MySQL集群5套的总和。
-
使用OceanBase的压缩功能后,我们的存储由16TB降到了4-5TB,整体成本降低了70%。
-
再也不用帮业务排查数据不一致的问题了。
OceanBase为我们分区分表提供了非常好的一个开端,避免了使用分布式中间件 sql的不兼容、维护繁琐问题。目前,我们还有业务单元化的需求,也已经经过了测试和验证,后续会逐渐应用到生产环境中。
此外,在使用OceanBase过程中也遇到了几个小问题,希望官方在后续版本中支持OCP平台自动检测分区表并添加分区,以及集群磁盘占用百分比可以调大也可以调小。