ARMv8 架构中引入的最重要的变化之一是增加了 64 位指令集。该指令集补充了现有的 32 位指令集架构。这种增加提供了对 64 位宽整数寄存器和数据操作的访问,以及使用 64 位长度的内存指针的能力。新指令被称为 A64,以 AArch64 执行状态执行。ARMv8 还包括原始的 ARM 指令集,现在称为 A32,以及 Thumb(T32)指令集。A32 和 T32 都以 AArch32 状态执行,并向后兼容 ARMv7。
尽管 ARMv8-A 提供了与 32 位 ARM 体系结构的向后兼容,但 A64 指令集与旧的 ISA 是独立的,而且编码方式也不同。A64 添加了一些额外的功能,同时也删除了其他可能限制高性能实现的速度或能源效率的特性。ARMv8 架构还包括对 32 位指令集(A32 和 T32)的一些增强。但是,利用这些特性的代码与旧的 ARMv7 实现不兼容。然而,A64 指令集中的指令操作码仍然是 32 位,而不是 64 位。
一、ARMv8 指令集
新的 A64 指令集与现有的 A32 指令集类似。指令宽度为 32 位,语法类似。指令集在 ARMv8 架构中使用了通用的命名约定,因此原来的 32 位指令集状态现在被称为:
A32:在 AArch32 状态下,指令集基本上与 ARMv7 兼容,但也有差异。可以参考 ARMv8-A 架构参考手册。它还提供了一些新指令,以符合 A64 指令集引入的一些特性。
T32:Thumb 指令集(Thumb 是 ARM 体系结构中一种 16 位的指令集。Thumb 指令集可以看作是 ARM 指令压缩形式的子集,它是为减小代码量而提出,具有 16bit 的代码密度。Thumb 指令体系并不完整,只支持通用功能,必要时仍需要使用 ARM 指令,如进入异常时)最初包含在 ARM7TDMI 处理器中,最初只包含 16 位指令。16 位指令可以提供小得多的程序,但会牺牲一些性能。ARMv7 处理器,包括那些在 Cortex-A 系列中的处理器,支持 Thumb-2 技术,它扩展了 Thumb 指令集,以提供 16 位和 32 位指令的混合。这提供了与 ARM 类似的性能,同时保留了较短的代码长度。由于 Thumb-2 的体积和性能优势,编译或汇编所有 32 位代码以利用 Thumb-2 技术变得越来越普遍。
内核在处于 AArch64 状态时可以使用一个新的指令集。为了保持命名约定,并反映 64 位操作,该指令集称为:A64。
A64:A64 提供了类似于 AArch32 或 ARMv7 中的 A32 和 T32 指令集的功能。ARMv8 架构在 AArch64 运行状态下使用 A64 指令集,在 AArch32 运行状态下使用 A32 指令集。A64 指令集和 A32 指令集是不兼容的,它们是两套完全不一样的指令集,它们的指令编码是不一样的。
新的 A64 指令集的设计允许以下几个改进:
- 一致编码方案:A32 中一些指令的添加导致了编码方案的不一致。例如,LDR 和 STR 支持半字的编码方式与主流的字节和字传输指令略有不同。这样做的结果是寻址模式略有不同。
- 宽范围常数:A64 指令为常量提供了一系列选项,每一个都是根据特定指令类型的要求定制的。
- 算术指令通常接受 12 位立即数常量。
- 逻辑指令通常接受 32 位或 64 位常量,这在其编码中有一些限制。
- MOV 指令接受 16 位立即数,可将其移位到任何 16 位边界。
- 地址生成指令适用于与 4KB 页面大小对齐的地址。
- 对于位操作指令中使用的常量,有稍微复杂一些的规则。然而,位字段操作指令可以寻址源操作数或目标操作数中的任何连续位序列。
A64 提供了灵活的常量,但对它们进行编码,甚至确定特定常量是否可以在特定上下文中合法编码,都是非常重要的。
-
数据类型更容易:A64 自然地处理 64 位有符号和无符号数据类型,因为它提供了更简洁和有效的方式来处理 64 位整数。这对于所有提供 64 位整数的语言(如 C 或 Java)都是有利的。
-
长偏移量:A64 指令通常为 PC 相关分支和偏移寻址提供更长的偏移。增加的分支范围使管理节(inter-section)间跳转变得更容易。动态生成的代码通常放在堆上,因此实际上可以放在任何地方。运行时系统发现,通过增加分支范围可以更容易地管理这一点,并且需要更少的修复。对文本池(嵌入代码流中的文本数据块)的需求一直是 ARM 指令集的一个特点。这在 A64 中仍然存在。然而,更大的 PC 相对负载偏移量大大有助于文字池的管理,使得每个编译单元都可以使用一个。这消除了在长代码序列中为多个池制造位置的需要。
-
指针:指针在 AArch64 中是 64 位的,它允许寻址更多的虚拟内存,并为地址映射提供了更多的自由。然而,使用 64 位指针确实会产生一些成本。当使用 64 指针运行时,同一段代码通常比使用 32 位指针时使用更多的内存。每个指针都存储在内存中,需要八个字节而不是四个字节。这听起来可能微不足道,但可能会导致严重的后果。此外,与移动到 64 位相关联的内存空间的使用增加会导致缓存中命中的访问次数减少。缓存命中率的下降会降低性能。一些语言可以使用压缩指针(如 Java)来实现,以避免性能问题。
-
使用条件构造代替 IT 块:IT 块是 T32 的一个有用特性,它可以实现高效的序列,避免在未执行的指令周围进行短的前向分支。然而,硬件有时很难有效地处理这些问题。A64 删除这些块并用条件指令(如 CSEL、条件选择和 CINC 或条件增量)替换它们。这些条件构造更直接,更容易处理,无需特殊情况。
IT,这条指令用于根据指定的条件来执行后面相继的四条指令。IT 指令的描述为:IT{<x>{<y>{<z>}}} <firstcond>。
其中,<x> 表示第二条指令的条件;<y> 表示第三条指令的条件;<z> 表示第四条指令的条件。<firstcond> 是条件操作数,表示第一条指令的条件。
<x>、<y>、<z> 的标识其实就两种符号 —— T 或 E。T 表示 Then,表示相应的指令所满足的条件与 <firstcond> 一致;E 表示 else,表示相应的指令所满足的条件与 <firstcond> 完全相反。因此,对于第一条指令而言,总是为 T 的,因此不需要在 IT 中显示给出,它直接对应于 <firstcond> 的条件。
另外,在 IT 块中不能再使用 IT 指令。即,相继的四条指令中不允许出现 IT 指令。例如:
ITETT EQ
MOVEQ R0, #1 ;//指令1
MOVNE R0, #0 ;//指令2
MOVEQ R1, #0 ;//指令3
MOVEQ R2, #0 ;//指令4
这个例子意思是,当条件“EQ”符合时,执行指令 1、3、4 的 mov 操作,否则执行指令 2 的 mov 操作。
- 移动和循环行为更直观:A32 或 T32 的移位循环行为并不总是容易映射到高级语言所期望的行为。ARMv7 提供了一个桶形移位器,可以用作数据处理指令的一部分。然而,指定移位类型和移位量需要一定数量的操作码位,这可以在其他地方使用。A64 指令因此删除了很少使用的选项,而是添加了新的显式指令来执行更复杂的移位操作。
- 代码生成:在为常见的算术函数静态和动态生成代码时,A32 和 T32 通常需要不同的指令或指令序列。这是为了处理不同的数据类型。A64 中的这些操作更加一致,因此在不同大小的数据类型上生成简单操作的通用序列要容易得多。例如,在 T32 中,根据使用的寄存器(低寄存器或高寄存器),同一指令可以具有不同的编码。A64 指令集编码更加规则和合理。因此,A64 的汇编程序通常需要比 T32 的汇编程序更少的代码行。
- 固定长度指令:所有 A64 指令的长度相同,而 T32 是可变长度指令集。这使得生成的代码序列的管理和跟踪更容易,特别是影响动态代码生成器。
- 三个操作数映射更好:A32 通常为数据处理操作保留真正的三操作数结构。另一方面,T32 包含大量的双操作数指令格式,这使得它在生成代码时稍微不那么灵活。A64 坚持一致的三操作数语法,这进一步有助于提高指令集的规则性和同质性,以利于编译器。
二、区分 32 位和 64 位 A64 指令
A64 指令集中的大多数整数指令有两种形式,它们对 64 位通用寄存器文件中的 32 位或 64 位值进行操作。
查看指令使用的寄存器名时:
- 如果寄存器名以
X开头,则为 64 位值。 - 如果寄存器名以
W开头,则为 32 位值。
如果选择 32 位指令形式,则以下事实成立:
- 循环右移在 31 位注入,而不是 63 位。
- 由指令设置的条件标志从低 32 位计算。
- 写入
W寄存器,将X寄存器的位 [63:32] 设置为零。
AArch64 执行状态提供了 31 × 64 位通用寄存器,在任何时候和所有异常级别都可以访问。每个寄存器是 64 位宽的,它们通常被称为寄存器 X0~X30。

每个 AArch64 64 位通用寄存器(X~X30)也有 32 位(W0~W30)形式。

32 位 W 寄存器对应的 64 位 X 寄存器的下半部分。即 W0 映射到 X0 的下半部分,W1 映射到 X1 的下半部分。
从 W 寄存器读取时,忽略对应的 X 寄存器中较高的 32 位,并保持不变。写入 W 寄存器将 X 寄存器的高 32 位设置为零。也就是说,将 0xFFFFFFFF 写入 W0 会将 X0 设置为 0x00000000FFFFFFFF。
三、寻址
当处理器可以在单个寄存器中存储 64 位值时,在程序中访问大量内存就变得简单得多。在 32 位内核上执行的单个线程被限制访问 4GB 的地址空间。可寻址空间的很大一部分被保留给操作系统内核、库代码、外围设备等使用。因此,空间不足意味着程序在执行时可能需要将一些数据映射到内存中或映射出内存。使用更大的地址空间和 64 位指针可以避免这个问题。它还使内存映射文件等技术更有吸引力,使用起来更方便。
寻址的其他改进包括:
- 独占访问
一个字节、半字、字和双字的独占加载存储(load-store)。对一对双字的独占访问允许对一对指针进行原子更新,例如循环列表插入。所有排他性访问必须自然对齐,排他性对访问必须对齐到数据大小的两倍,即对 64 位值对齐为 128 位。
- 增加 PC 相对偏移寻址
PC 相对文字负载的偏移范围为 ±1MB。与 A32 的 PC 相对负载相比,这减少了文本池的数量,并增加了函数之间的文本数据共享。反过来,这又减少了 I-cache 和 TLB 污染。
大多数条件分支的范围为 ±1MB,预计足以满足在单个函数中发生的大多数条件分支。
无条件分支(包括分支和链接)的范围为 ±128MB,预计足以跨越大多数可执行加载模块和共享对象的静态代码段,而无需插入链接器 Veneers——贴面(贴面是一小段代码,例如,当链接器检测到分支目标超出范围时,它会自动插入这些代码。贴面成为原始分支的中间目标,然后贴面本身成为目标地址的分支)。
范围为 ±4GB 的 PC 相对加载、存储和地址生成可以只用两条指令内联执行,也就是说,不需要从字面量池加载偏移量。
- 未对齐的地址支持
除了独占和有序访问外,所有加载和存储都支持在访问正常内存时使用未对齐的地址。这简化了将代码移植到 A64 的过程。
- 批量传输
LDM、STM、PUSH 和 POP 指令在 A64 中不存在。可以使用 LDP 和 STP 指令构建批量传输。这些指令从连续的存储器位置加载并存储一对独立的寄存器。LDNP 和 STNP 指令提供了流式或非时间性提示,即数据不需要保留在缓存中。PRFM 或预取内存指令允许将预取定向到特定的高速缓存级别。
- 加载/存储
所有加载/存储指令现在都支持一致的寻址模式。例如,在从内存中加载和存储元素时,这使得以相同的方式处理 char、short、int 和 long long 变得容易得多。浮点寄存器和 NEON 寄存器现在支持与核心寄存器相同的寻址模式,这使得可以更容易地互换使用这两个寄存器组。
- 对齐检查
在 AArch64 中执行时,使用堆栈指针对指令获取和加载或存储执行额外的对齐检查,从而启用 PC 或当前 SP 的对齐检查。这种方法比强制 PC 或 SP 正确对齐更可取,因为 PC 或 SP 的未对齐通常表示软件错误,例如软件中的地址损坏。
四、C/C++ 内联汇编
asm 关键字可以将内联 GCC 语法汇编代码合并到函数中。例如:
#include <stdio.h>
int add(int i, int j)
{
int res = 0;
asm (
"ADD %w[result], %w[input_i], %w[input_j]" // 使用“%w[名称]”对 w 寄存器进行操作。
// 也可以对 x 寄存器使用“%x[name]”,这是默认值。
: [result] "=r" (res)
: [input_i] "r" (i), [input_j] "r" (j)
);
return res;
}
int main(void)
{
int a = 1;
int b = 2;
int c = 0;
c = add(a,b)
printf(“Result of %d + %d = %d\n, a, b, c);
}
asm 内联汇编语句的一般形式如下:
asm(code [: output_operand_list [: input_operand_list [: clobber_list]]]);
asm 关键字允许你在 C/C++ 代码中嵌入汇编指令。GCC 提供了两种形式的内联 asm 语句。基本 asm 语句是没有操作数的语句,而扩展 asm 语句包含一个或多个操作数。扩展形式是在函数中混合 C/C++ 和汇编语言的首选。
code 是汇编代码。在我们的例子中,这是“ADD %[result], %[input_i], %[input_j]”。
output_operand_list 是一个可选的输出操作数列表,用逗号分隔。每个操作数由方括号中的符号名称、约束字符串和括号中的 C 表达式组成。在这个例子中,只有一个输出操作数:[result] “=r” (res)。
input_operand_list 是一个可选的输入操作数列表,由逗号分隔。输入操作数的语法与输出操作数相同。在这个例子中,有两个输入操作数:[input_i] “r” (i)和[input_j] “r” (j)。
clobber_list 是一个可选的寄存器或其他值的列表。在这个例子中,这个参数被省略了。
扩展 asm —— 汇编指令与 C 表达式操作数
使用扩展 asm,可以从汇编程序读写 C 变量,并执行从汇编代码到 C 标签的跳转。扩展 asm 语法使用冒号(‘:’)在汇编程序模板之后分隔操作数参数:
asm asm-qualifiers ( AssemblerTemplate
: OutputOperands
[ : InputOperands
[ : Clobbers ] ])
asm asm-qualifiers ( AssemblerTemplate
: OutputOperands
: InputOperands
: Clobbers
: GotoLabels)
在最后一种形式中,asm-限定符(asm-qualifiers)包含 goto(在第一种形式中,不包含)。
限定符
volatile —— 扩展 asm 语句的典型用法是操作输入值以产生输出值。然而,asm 语句也可能产生副作用。如果是这样,可能需要使用 volatile 限定符来禁用某些优化(GCC 的优化器有时会在确定不需要输出变量时丢弃 asm 语句。此外,如果优化器认为代码将始终返回相同的结果(即,在调用之间没有任何输入值改变),则优化器可以将代码移出循环)。
inline —— 如果使用 inline 限定符,那么出于内联目的,asm 语句的大小将尽可能小。
goto —— 这个限定符通知编译器,asm 语句可以执行跳转到 GotoLabels 中列出的标签之一。
参数
AssemblerTemplate —— 这是一个文本字符串,它是汇编程序代码的模板(汇编程序模板是包含汇编程序指令的文本字符串)。它是指输入、输出和 goto 参数的固定文本和标记的组合。
OutputOperands —— 由 AssemblerTemplate 中的指令修改的 C 变量列表,以逗号分隔。允许使用空列表。
InputOperands —— 由 AssemblerTemplate 中的指令读取的以逗号分隔的 C 表达式列表。允许使用空列表。
Clobbers —— 逗号分隔的寄存器列表或由 AssemblerTemplate 更改的其他值,不包括作为输出列出的那些值。允许使用空列表。
GotoLabels —— 当使用 asm 的 goto 形式时,此部分包含汇编模板中的代码可能跳转到的所有 C 标签的列表。asm 语句不能执行跳转到其他 asm 语句,只能跳转到列出的 GotoLabels。GCC 的优化器不知道其他跳跃。因此,他们在决定如何优化时无法考虑这些因素。
input + output + goto 操作数的总数限制为 30。
五、在指令集之间切换
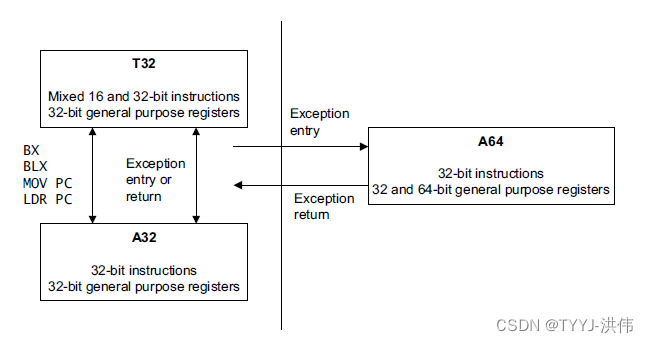
不可能在单个应用程序中使用来自两种执行状态的代码。在 ARMv8 中,A64 和 A32 或 T32 指令集之间没有相互作用,而 A32 和 T32 指令集之间有相互作用。用 A64 编写的 ARMv8 处理器的代码不能在 ARMv7 Cortex-A 系列处理器上运行。但是,为 ARMv7-A 处理器编写的代码可以在 AArch32 执行状态下在 ARMv8 处理器上运行。这一点做安卓的不陌生,在 ARMv8 处理器上运行只包含 ARMv7-A 的 so 库是可以正常运行的。
参考资料:
- 《ARMv8-A-Programmer-Guide》
- https://gcc.gnu.org/onlinedocs/gcc/Extended-Asm.html#Extended-Asm