一、heapq库简介
heapq 库是Python标准库之一,提供了构建小顶堆的方法和一些对小顶堆的基本操作方法(如入堆,出堆等),可以用于实现堆排序算法。
堆是一种基本的数据结构,堆的结构是一棵完全二叉树,并且满足堆积的性质:每个节点(叶节点除外)的值都大于等于(或都小于等于)它的子节点。
堆结构分为大顶堆和小顶堆,在heapq中使用的是小顶堆:
1. 大顶堆:每个节点(叶节点除外)的值都大于等于其子节点的值,根节点的值是所有节点中最大的。
2. 小顶堆:每个节点(叶节点除外)的值都小于等于其子节点的值,根节点的值是所有节点中最小的。
在heapq库中,heapq使用的数据类型是Python的基本数据类型 list ,要满足堆积的性质,则在这个列表中,索引 k 的值要小于等于索引 2*k+1 的值和索引 2*k+2 的值(在完全二叉树中,将数据按广度优先插入,索引为k的节点的子节点索引分别为2*k+1和2*k+2)。在heapq库的源码中也有介绍,可以读一下heapq的源码,代码不多。
使用Python实现堆排序可以参考:https://blog.csdn.net/weixin_43790276/article/details/104033696
完全二叉树的特性可以参考:https://blog.csdn.net/weixin_43790276/article/details/104737870
# heapq_showtree.py
import math
from io import StringIO
def show_tree(tree, total_width=36, fill=' '):
"""Pretty-print a tree."""
output = StringIO()
last_row = -1
for i, n in enumerate(tree):
if i:
row = int(math.floor(math.log(i + 1, 2)))
else:
row = 0
if row != last_row:
output.write('\n')
columns = 2 ** row
col_width = int(math.floor(total_width / columns))
output.write(str(n).center(col_width, fill))
last_row = row
print(output.getvalue())
print('-' * total_width)
print()
二、使用heapq创建堆
array = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]
heap = []
for num in array:
heapq.heappush(heap, num)
print("array:", array)
print("heap: ", heap)
show_tree(heap)
heapq.heapify(array)
print("array:", array)
show_tree(array)运行结果:

heapq中创建堆的方法有两种。
heappush(heap, num),先创建一个空堆,然后将数据一个一个地添加到堆中。每添加一个数据后,heap都满足小顶堆的特性。当使用heappush()时,当新元素添加时,堆得顺序被保持了。
heapify(array),直接将数据列表调整成一个小顶堆(调整的原理参考上面堆排序的文章,heapq库已经实现了)。
如果数据已经在内存中,则使用 heapify() 来更有效地重新排列列表中的元素。
两种方法实现的结果会有差异,上面的代码中,使用heappush(heap, num)得到的堆结构如下
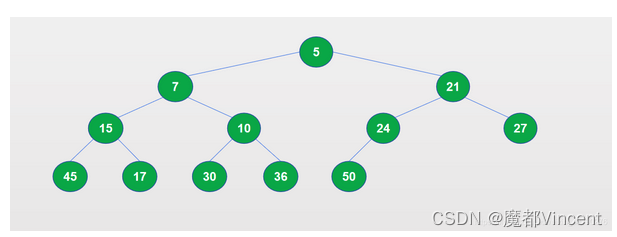
使用heapify(array)得到的堆结构如下:

不过,这两个结果都满足小顶堆的特性,不影响堆的使用(堆只会从堆顶开始取数据,取出数据后会重新调整结构)。
三、使用heapq实现堆排序
array = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]
heap = []
for num in array:
heapq.heappush(heap, num)
print(heap)
for i in range(2):
smallest = heapq.heappop(heap)
print('pop {:>3}:'.format(smallest))
show_tree(data)运行结果:

先将待排序列表中的数据添加到堆中,构造一个小顶堆,打印第一个数据,可以确认它是最小值。然后依次将堆顶的值取出,添加到一个新的列表中,直到堆中的数据取完,新列表就是排序后的列表。
四、获取堆中的最小值或最大值
array = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]
heapq.heapify(array)
print(heapq.nlargest(2, array))
print(heapq.nsmallest(3, array))运行结果:
[50, 45]
[5, 7, 10]nlargest(num, heap),从堆中取出num个数据,从最大的数据开始取,返回结果是一个列表(即使只取一个数据)。如果num大于等于堆中的数据数量,则从大到小取出堆中的所有数据,不会报错,相当于实现了降序排序。
nsmallest(num, heap),从堆中取出num个数据,从最小的数据开始取,返回结果是一个列表。
这两个方法除了可以用于堆,也可以直接用于列表,功能一样。
五、使用heapq合并两个有序列表
将几个排序的序列组合成一个新序列对于小数据集来说很容易。
list(sorted(itertools.chain(*data)))array_a = [10, 7, 15, 8]
array_b = [17, 3, 8, 20, 13]
array_merge = heapq.merge(sorted(array_a), sorted(array_b))
print("merge result:", list(array_merge))运行结果:
merge result: [3, 7, 8, 8, 10, 13, 15, 17, 20]merge(list1, list2),将两个有序的列表合并成一个新的有序列表,返回结果是一个迭代器。这个方法可以用于归并排序。
对于较大的数据集,将会占用大量内存。不是对整个组合序列进行排序,而是使用 merge() 一次生成一个新序列。
import heapq
import random
random.seed(2022)
data = []
for i in range(4):
new_data = list(random.sample(range(1, 101), 5))
new_data.sort()
data.append(new_data)
for i, d in enumerate(data):
print('{}: {}'.format(i, d))
print('\nMerged:')
for i in heapq.merge(*data):
print(i, end=' ')
print()
因为merge()使用堆的实现,它根据被合并的序列元素个数消耗内存,而不是所有序列中的元素个数。
heapq.merge()在迭代操作中,对所提供的序列并不会做一次性操作,可以处理非常长的序列,开销小。heapq.merge()方法使用的前提是要求所有的输入序列是有序的。heapq.merge()方法不会预先做排序操作。heapq.merge()方法不会验证输入序列是否满足要求。heapq.merge()方法会检查每个序列的第一个元素,进行比较,将最小的那个放入新的序列中,然后再从之前的每个序列中选择下一个相比较小的元素。重复此操作,直至生成一个完整的新序列。
六、heapq替换数据的方法
array_c = [10, 7, 15, 8]
heapq.heapify(array_c)
print("before:", array_c)
# 先push再pop
item = heapq.heappushpop(array_c, 5)
print("after: ", array_c)
print(item)
array_d = [10, 7, 15, 8]
heapq.heapify(array_d)
print("before:", array_d)
# 先pop再push
item = heapq.heapreplace(array_d, 5)
print("after: ", array_d)
print(item)before: [7, 8, 15, 10]
after: [7, 8, 15, 10]
5
before: [7, 8, 15, 10]
after: [5, 8, 15, 10]
7heappushpop(heap, num),先将num添加到堆中,然后将堆顶的数据出堆。
heapreplace(heap, num),先将堆顶的数据出堆,然后将num添加到堆中。
两个方法都是即入堆又出堆,只是顺序不一样,可以用于替换堆中的数据。具体的区别可以看代码中的例子。
array = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]
heap = []
for num in array:
heapq.heappush(heap, num)
show_tree(heap)
for n in [0, 13]:
smallest = heapq.heapreplace(heap, n)
print('replace {:>2} with {:>2}:'.format(smallest, n))
show_tree(heap)
替换元素可以维护固定大小的堆,例如按优先级排序的 jobs 队列。