来自巴西阿雷格里港大学的学者发表于ECCV2018的论文 http://url.cn/5tnTl9p
《License Plate Detection and Recognition in Unconstrained Scenarios》,给出了一整套完整的车牌识别系统设计,着眼于解决在非限定场景有挑战的车牌识别应用,其性能优于目前主流的商业系统,
1、车辆信息提供不充足,仅凭车辆号牌基础数据分析
2、仅牌照识别的检索准确率偏低,布控报警精度下降
3、数据追溯效率偏低,延误最佳破案时间
4、套牌车辆违法没有高效的应对手段
缺点难点:1、占用警力2、效率低下3、非智能化
结合国际领先的机器学习与深度学习技术,可以对车辆的身份进行识别,包括车牌号码,车身颜色,车辆品牌,车辆子型号,具体年款等。
一、车牌识别
支持识别车牌种类:普通民用蓝牌,单层黄牌,双层黄牌,新式武警车牌, 军牌,警用车牌,农用车牌,港牌等。
速度:200W 图片< 100ms
识别率:白天> 98%,夜晚> 95%
二、车身颜色识别
车身颜色识别模块首先获得车脸的位置信息,根据不同位置对颜色进行加权,最终可以输出车身的深浅颜色,红、绿、蓝、粉、棕、黄、白、黑、灰等9 种常见颜色(支持输出一个主颜色和一个辅颜色)。由于颜色受光照和夜晚补光的影响比较严重,故针对白天车身颜色识别准确率> 80%。
三、车型识别
1)采用算法:车型识别模块采用多种特征融合技术对车脸LBP 等纹理特征提取,利用SVM 分类器对车型进行识别。
2)支持种类:可以对标准卡口系统抓拍的车头图片和手机抓拍的车头图片进行识别,车尾识别正在完善中。
3)识别种类:目前可以识别常见的100 多种车辆品牌的1500 多种车辆子型号,车辆种类还在不断的增加之中,可以识别的部分车辆品牌名称如下:
4)识别率:
白天车型识别准确率> 90%
夜晚补光良好准确率> 80%
字符的识别眼下用于车牌字符识别(OCR)中的算法主要有基于模板匹配的OCR算法以及基于人工神经网络的OCR算法。基于模板匹配的OCR的基本过程是:首先对待识别字符进行二值化并将其尺寸大小缩放为字符数据库中模板的大小,然后与全部的模板进行匹配,最后选最佳匹配作为结果。用人工神经网络进行字符识别主要有两种方法:一种方法是先对待识别字符进行特征提取,然后用所获得的特征来训练神经网络分类器。识别效果与字符特征的提取有关,而字符特征提取往往比较耗时。因此,字符特征的提取就成为研究的关键。还有一种方法则充分利用神经网络的特点,直接把待处理图像输入网络,由网络自己主动实现特征提取直至识别。
模板匹配的主要特点是实现简单,当字符较规整时对字符图像的缺损、污迹干扰适应力强且识别率相当高。综合模板匹配的这些长处我们将其用为车牌字符识别的主要方法。
模板匹配是图象识别方法中最具代表性的基本方法之中的一个,它是将从待识别的图象或图象区域f(i,j)中提取的若干特征量与模板T(i,j)对应的特征量逐个进行比較,计算它们之间规格化的互相关量,当中互相关量最大的一个就表示期间相似程度最高,可将图象归于对应的类。也能够计算图象与模板特征量之间的距离,用最小距离法判定所属类。然而,通常情况下用于匹配的图象各自的成像条件存在差异,产生较大的噪声干扰,或图象经预处理和规格化处理后,使得图象的灰度或像素点的位置发生改变。在实际设计模板的时候,是依据各区域形状固有的特点,突出各类似区域之间的区别,并将easy由处理过程引起的噪声和位移等因素都考虑进去,依照一些基于图象不变特性所设计的特征量来构建模板,就能够避免上述问题。
此处采用相减的方法来求得字符与模板中哪一个字符最相似,然后找到相似度最大的输出。汽车牌照的字符一般有七个,大部分车牌第一位是汉字,通常代表车辆所属省份,或是军种、警别等有特定含义的字符简称;紧接其后的为字母与数字。车牌字符识别与一般文字识别在于它的字符数有限,汉字共约50多个,大写英文字母26个,数字10个。所以建立字符模板库也极为方便。为了实验方便,结合本次设计所选汽车牌照的特点,仅仅建立了4个数字26个字母与10个数字的模板。其它模板设计的方法与此同样。
首先取字符模板,接着依次取待识别字符与模板进行匹配,将其与模板字符相减,得到的0越多那么就越匹配。把每一幅相减后的图的0值个数保存,然后找数值最大的,即为识别出来的结果。
识别到以上信息后可采用多目标跟踪算法降低资源消耗,提高识别精度。
多目标跟踪中SORT算法的理解
在跟踪之前,对所有目标已经完成检测,实现了特征建模过程。
- 第一帧进来时,以检测到的目标初始化并创建新的跟踪器,标注id。
- 后面帧进来时,先到卡尔曼滤波器中得到由前面帧box产生的状态预测和协方差预测。求跟踪器所有目标状态预测与
U,通过匈牙利指派算法得到IOU最大的唯一匹配(数据关联部分),再去掉匹配值小于iou_threshold的匹配对。 - 用本帧中匹配到的目标检测box去更新卡尔曼跟踪器,计算卡尔曼增益、状态更新和协方差更新,并将状态更新值输出,作为本帧的跟踪box。对于本帧中没有匹配到的目标重新初始化跟踪器。
其中,卡尔曼跟踪器联合了历史跟踪记录,调节历史box与本帧box的残差,更好的匹配跟踪id。
四、车牌识别算法
具体车牌识别算法有以下几种:
1、CRNN
CRNN=CNN+RNN
优势:
(1) 可以端到端训练
(2) 不需要进行字符分割和水平缩放操作,只需要垂直方向缩放到固定长度既可,同时可以识别任意长度的序列
(3) 可以训练基于词典的模型和不基于词典的任意模型
(4) 模型速度快,并且很小,本人原始ckpt模型100M,固化后40M,量化后只有10M。
对于类序列对象,CRNN与传统神经网络模型相比具有一些独特的优点:1)可以直接从序列标签(例如单词)学习,不需要详细的标注(例如字符);2)直接从图像数据学习信息表示时具有与DCNN相同的性质,既不需要手工特征也不需要预处理步骤,包括二值化/分割,组件定位等;3)具有与RNN相同的性质,能够产生一系列标签;4)对类序列对象的长度无约束,只需要在训练阶段和测试阶段对高度进行归一化;5)与现有技术相比,它在场景文本(字识别)上获得更好或更具竞争力的表现[23,8]。6)它比标准DCNN模型包含的参数要少得多,占用更少的存储空间。
我国交通法规规定车牌编号中不包含字母I和O
系统自动识别黑、白、蓝、黄、绿五种车牌颜色
检测模块可以用darknet
darknet 的主要特点:
darknet 完全由C语言实现,没有任何依赖项。为了更好的可视化,可以使用 OpenCV 来显示图片;
2)darknet 支持 CPU 和 GPU(CUDA/cuDNN);
3)因为较为轻型,没有像TensorFlow那般强大的API,有另一种味道的灵活性,更为方便的从底层对其进行改进与扩展;
4)darknet 的实现与 caffe 的实现存在相似的地方,熟悉了darknet,相信对上手caffe有帮助;
在开源界也有许多优秀的算法,目前github上比较优秀的开源方案包括OpenALPR,easyPR,HyperLPR等。其中OpenALPR针对国外车牌,如果需要利用其识别国内车牌,需要重新训练以及代码的修改,可以作为一种车牌识别的思路进行参考。是车牌识别爱好者开发的中文车牌识别框架,作者目前在南京大学读博,代码具有一定参考价值。编译运行代码,但是速度跟准确率都不能达到商用。HyperLPR是智云视图开源的一个车牌识别代码,作者提到该算法采用了神经网络,端到端的进行识别。改代码提供了多个平台的代码方案,包括linux、win、ios、android等。我们运行了该代码,速度跟准确率算是开源代码中很不错的了。但是与其提供的demo还有一点差距,需要使用者自己完善。
链接:https://www.jianshu.com/p/82174681e89f
2、Halcon车牌识别
灰度化:实际就是对原始车牌图片进行预处理,把彩色图片转化为黑白图片,然后对不符合指定阙值范围的灰度值进行过滤。
车牌定位:这是技术难点之一。很多车牌识别的产品都对车牌的定位预留了很多配置参数,例如截取原始图片的位置参数、车牌的长宽比例、大小等等,这些都是为了提高车牌定位的准确率。
字符分割:对定位的车牌位置进行降噪处理、边界模糊、从右向左找出前6个封闭的图形、剩余的封闭图形综合为一个图形进行汉字的识别。
字符识别:就是根据字符模板进行模板匹配,因此需预先建立相应的字符模板。基于图像进行字符识别也可配置很多参数来大大提高字符的识别率。例如限定车牌头的字符,车牌各位字符的识别优先级等等。
3、Deep-anpr基于tensorflow的车牌号自动识别系统:
https://github.com/matthewearl/deep-anpr
该系统的缺点:
只适用于特定车牌号。尤其是,网络结构明确假定了输出只有7个字符。
只适用于特定字体。
速度太慢。该系统运行一张适当尺寸的图片要花费几秒钟。
为了解决第1个问题,谷歌团队将他们的网络结构的高层拆分成了多个子网络,每一个子网络用于假定输出号码中的不同号码位。还有一个并行的子网络来决定存在多少号码。我觉得这种方法可以应用到这儿,但是我没有在这个项目中实现。
关于第2点我在上面举过例子,由于字体的稍微不同而导致字符R的误检。如果尝试着检测US车牌号的话,误检将会更加严重,因为US车牌号字体类型更多。一个可能的解决方案就是使得训练数据有更多不同的字体类型可选择,尽管还不清楚需要多少字体类型才能成功。
第3点提到的速度慢的问题是扼杀许多应用的cancer:在一个相当强大的GPU上处理一张适当尺寸的输入图片就要花费几秒钟。我认为不引进一种级联式结构的检测网络就想避开这个问题是不太可能的,比如Haar级联,HOG检测器,或者一个更简单的神经网络。
4、Tensorflow车牌识别完整版
https://blog.csdn.net/ShadowN1ght/article/details/78571187
车牌数据集下载地址(约4000张图片):https://pan.baidu.com/s/1RyoMbHtLUlsMDsvLBCLZ2w(tf_car_license_dataset.rar)
省份简称训练+识别代码(保存文件名为train-license-province.py)
城市代号训练+识别代码(保存文件名为train-license-letters.py):
车牌编号训练+识别代码(保存文件名为train-license-digits.py):
首先进行省份简称训练python train-license-province.py train
然后进行省份简称识别python train-license-province.py predict
执行城市代号训练相当于训练26个字母python train-license-letters.py train
识别城市代号:python train-license-letters.py predict
执行车牌编号训练(相当于训练24个字母+10个数字,我国交通法规规定车牌编号中不包含字母I和O):python train-license-digits.py train
识别车牌编号:
python train-license-digits.py predict
5、Easypr 能够识别车牌颜色
https://blog.csdn.net/vs2008ASPNET/article/details/79422678
http://www.cnblogs.com/subconscious/p/3979988.html
https://gitee.com/tonegod/EasyPR
https://github.com/liuruoze/EasyPR
EasyPR 当前版本基于OpenCV 3.1开发。
地址: https://github.com/dreamxgn/EasyPR
环境搭建 VS2017+OpenCV 3.1
EasyPR是一个开源的中文车牌识别系统,其目标是成为一个简单、高效、准确的非限制场景(unconstrained situation)下的车牌识别库。
相比于其他的车牌识别系统,EasyPR有如下特点:
它基于openCV这个开源库。这意味着你可以获取全部源代码,并且移植到opencv支持的所有平台。
它能够识别中文。例如车牌为苏EUK722的图片,它可以准确地输出std:string类型的"苏EUK722"的结果。
它的识别率较高。图片清晰情况下,车牌检测与字符识别可以达到80%以上的精度。
针对特定场景号称98%。
Easypr 后面有字符切分
6、OpenALPR 2013
车牌检测及识别 开源代码 OpenALPR配置及使用
OpenALPR(自动车牌识别)的开源软件库当摄像头在影像内容中拍摄到车牌的时候,就能够快速地扫描车牌的每一帧(不过似乎只支持美国和欧洲格式)(训练中文格式的车牌号码)
openALPR后端调用tesseract,需要自己训练,识别中文效果不怎么样。
https://blog.csdn.net/lanbing510/article/details/42215507
http://lanbing510.info/2014/12/18/License-Plate-Detection-Recognition.html
https://blog.csdn.net/hongbin_xu/article/details/76377238
http://doc.openalpr.com/index.htmlOpenALPR在线文档
http://doc.openalpr.com/accuracy_improvements.html如何提高精度(虽然讲的是提高检测精度,但提到了很多关键的实现细节,对工程实现很有帮助)
https://github.com/openalpr/train-ocr如何训练 OCR(训练Tesseract 字符识别的详细步骤。提供了很多有用的工具。起步时,不用再专门看 Tesseract 的文档了)
检测的基本方法
1 用边缘检测+轮廓提取+车牌特征进行车牌的检测;
2 用Harr-like特征或者LBP特征+Adaboost来训练模板用于车牌的检测;还有用神经网络训练的;
3 两者结合。
识别的基本方法
1 用Tesseract.来进行训练;
2 用车牌上的字符直接训练识别器。
Openalpr https://github.com/openalpr/openalpr
测试单幅图:处理时间58ms 准确率88%
简介:
OpenALPR是一种使用C ++编写的开源自动车牌识别库,还能支持:
C#,Java,Node.js,Go和Python。
该库可以分析图像和视频流以识别车牌。
输出的结果是车牌上的字符。
环境配置
OpenALPR需要这些依赖的库:
Tesseract OCR v3.0.4 (https://github.com/tesseract-ocr/tesseract)
OpenCV v2.4.8+ (http://opencv.org/)
7、Paddle
1 车牌数据不多可以用代码批量生成车牌
2 可以采用Paddlepaddle进行车牌识别,车牌识别其实属于比较常见的图像识别的项目了,目前也属于比较成熟的应用,大多数老牌厂家能做到准确率99%+。传统的方法需要对图像进行多次预处理再用机器学习的分类算法进行分类识别,然而深度学习发展起来以后,我们可以通过用CNN来进行端对端的车牌识别。任何模型的训练都离不开数据,在车牌识别中,除了网上能下载到的一些包含车牌的数据是不够的,本篇文章的主要目的是教大家如何批量生成车牌。
3 paddlepaddle是百度提出来的深度学习的框架
8、Hyperlpr
无需进行字符分割
HyperLPR是北京智云视图科技有限公司(www.zeusee.com)开源的一个使用深度学习针对对中文车牌识别的实现,与较为流行的开源的 EasyPR 相比,它的检测速度和鲁棒性和多场景的适应性都要好于目前开源的。
HyperLPR是一个使用深度学习针对对中文车牌识别的实现,与较为流行的开源的其他框架相比,它的检测速度和鲁棒性和多场景的适应性都要好于目前开源的框架,HyperLPR可以识别多种中文车牌包括白牌,新能源车牌,使馆车牌,教练车牌,武警车牌等。
特性
基于端到端sequence模型,无需进行字符分割,识别速度更快。
速度快 720p ,单核 Intel 2.2G CPU (macbook Pro 2015)平均识别时间<=90ms
识别率高,仅仅针对车牌ROI在EasyPR数据集上,0-error达到 95.2%, 1-error识别率达到 97.4% (指在定位成功后的车牌识别率)
轻量总代码量不超1k行。
带有Android实现,其Android Demo可解决一些在一些普通业务场景(如执法记录仪)下的车牌识别任务。
支持多种车牌的识别
注意事项:
Win工程中若需要使用静态库,需单独编译
本项目的C++实现和Python实现无任何关联,都为单独实现
在编译C++工程的时候必须要使用OpenCV 3.3(DNN 库),否则无法编译
Python 依赖
Keras (>2.0.0)
Theano(>0.9) or Tensorflow(>1.1.x)
Numpy (>1.10)
Scipy (0.19.1)
OpenCV(>3.0)
Scikit-image (0.13.0)
PIL
CPP 依赖
Opencv 3.3(必须是OpenCV 3.3)
设计流程
step1. 使用opencv 的 HAAR Cascade 检测车牌大致位置
step2. Extend 检测到的大致位置的矩形区域
step3. 使用类似于MSER的方式的 多级二值化 + RANSAC 拟合车牌的上下边界
step4. 使用CNN Regression回归车牌左右边界
step5. 使用基于纹理场的算法进行车牌校正倾斜
step6. 使用CNN滑动窗切割字符
step7. 使用CNN识别字符
HyperLPR车牌识别技术算法之车牌粗定位与训练
使用了OpenALPR的Train - Detector,来进行训练Opencv的Haar级联分类目标检测器。 https://github.com/zeusees/train-detector
正样本可以通过手动crop或者使用easypr或者hyperlpr的模块进行crop裁剪。
HyperLPR车牌识别
(1) opencv2的imread函数导入图片, 返回的是Mat类型。
(2) HyperLPRLiite.py中的LPR类构造函数导入model, 参数就是训练好的三个模型文件,名字分别是:
- model/cascade.xml 参数model_detection就是文件model/cascade.xml 用到了 opencv2的CascadeClassifier()函数 参数输入.xml或者.yaml文件,表示加载模型 一种基于Haar特征的级联分类器用于物体检测的模型
- model/model12.h5
- model/ocr_plate_all_gru.h5
参考:
https://blog.csdn.net/relocy/article/details/78705662
https://blog.csdn.net/YubaoLouisLiu/article/details/80767942
https://github.com/zeusees/HyperLPR
https://gitee.com/zeusees/HyperLPR
https://gitcode.net/mirrors/zeusees/hyperlpr?utm_source=csdn_github_accelerator
https://blog.csdn.net/qq_37423198/article/details/81266401
https://github.com/icepoint666/HyperLPR
9、LPRNet
无需对字符提前进行切割
YOLOv5与LPRNet训练车牌识别
https://zhuanlan.zhihu.com/p/442836317
LPRNet没有对字符进行预分割,可以说是一个端到端的车牌识别算法。
论文: LPRNet: License Plate Recognition via Deep Neural Networks (2018)
GitHub:https://github.com/sirius-ai/LPRNet_Pytorch
来自 https://blog.csdn.net/qq_14845119/article/details/120783704
五、车牌识别研究点
1、概念
车牌定位: 车牌定位是以灰度图像为基础的,然后结合视觉角度和字符特点,提取对应的特征。车牌定位是整个系统的关键和难点。
倾斜校正: 以为在获取车辆牌照的时候不能保证拍照是水平的,难免出现倾斜的情况,这时候就要对车辆牌照进行倾斜校正。为后来的车牌字符分割和车牌字符识别提供方便。
字符分割: 将车牌号中的字符分割出来,在于模板中的字符 相互比较,看是狗一致。
字符识别: 字符识别是对分割后的字符进行归一化处理,然后进行模板匹配以显示出车牌号码。
2、问题和方案
1、预处理
问题:
对摄像机获得的车牌进行二值化等方法预处理,为后面的操作做铺垫。
(1)对车身颜色的检测由于反光、光照不均、光照强度不稳定造成的车身颜色检测不准确,对车牌底色的检测同样也需要预处理。
(2)对异常光照敏感。夜间补光灯会打在车体上,不管什么颜色的车,都会产生亮白的光斑,车牌周围的区域极易与车牌融合在一起,可能会产生很大的区域。
(3)图像模糊,尤其是运动模糊造成的图像不清晰的处理,或者通过摄像机采集到的模糊不清的原始图像。
(4)北方冬天的雨雪及大雾天气时有发生,在这种情况下,道路监控摄像机的清晰度就会存在很大的问题,要针对有雾画面进行独特的处理,实时调整图像的的那个大范围曲线,强化色彩,提供更为真实的监控画面。
(5)在外界环境噪声以及电子器件自身产生的噪声干扰下,车牌图像质量会有所下降,因此需要对原图像进行去噪处理.
(6)车牌使用多年后会有污染和磨损等现象,因此在实际环境中,面对破损污旧的车牌,如何提高车牌识别系统的识别能力也是实际需要解决的问题。
(7)高清数据量过大,会出现处理速度过慢的问题,还会因为资源占用需求过大难以是实现高清视频流识别,这是车牌识别系统在高清系统中面临的新问题。
方案:
(1)传统的图像处理方法
(2)GAN方法处理
(3)去雨算法:RESCAN本文来自于ECCV2018接收的论文《Recurrent Squeeze-and-Excitation Context Aggregation Net for Single Image Deraining》。
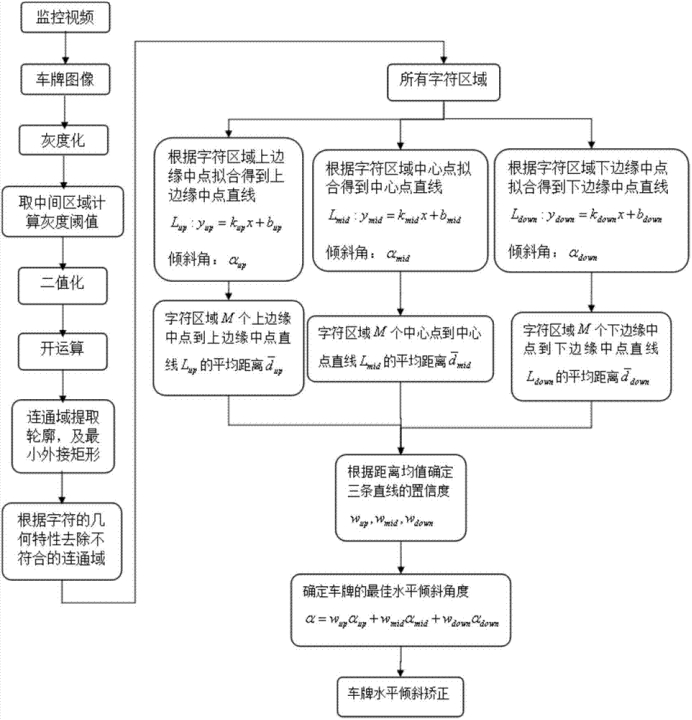
2、车牌倾斜的校正
问题:
当摄像头摆放位置与车辆牌照悬挂位置存在一定角度,或者在摄像头进行拍摄的过程中,由于车辆发动机的震动导致摄像头抖动或者车的位置/摄像头安置的角度等因素导致获取到的车身是倾斜的,进而定位到的车牌的位置是倾斜的,对车牌号的识别有很大影响。
字符分割阶段对倾斜车牌校正:车牌畸变校准。
方案:倾斜度/最小二乘法/Randon变换/Hough变换
hyperlpr之基于方向纹理场进行快速车牌(文字)校正 https://blog.csdn.net/Relocy/article/details/77771495
空间变换预处理LocNet这是对检测到的车牌形状上的校正,使用 Spatial Transformer Layer[1],这一步是可选的,但用上可以使得图像更好得被识别。
3、车牌定位
问题
车牌定位是以灰度图像为基础的,然后结合视觉角度和字符特点,提取对应的特征。车牌定位是整个系统的关键和难点。
目前业内开源的较好的车牌识别,其传统的定位算法有很多且存在一定的问题:
传统的边缘检测算法检测到的边缘信息存在大量的干扰信息,当光照条件不同时,传统的边缘检测算法很多情况下不能实现车牌定位;纹理特征法对于牌照倾斜以及光照不匀的情况,定位效果较好,但对于噪声大、背景复杂 的图像则不能实现较好的定位; 小波变换法能很好地解决含有噪声的车牌图像的定位问题,缺点是速度比较慢,并且在噪声比较大时误判率较高;遗传算法在图像质量较差时对目标区域有很好的增强效果,但是在实时系统中,遗传算法中的迭代次数会对车牌定位的速度造成很大的影响,导致运算速度慢,效率不高。
由于灰度图像信息较少,计算量相对彩色图像较小,处理 时间较短,因此文中使用基于灰度图的目标检测方法 来定位车牌。
目前我们所实现的车牌识别中采用的定位方法是基于opencv中传统的cascade方法,后期与车身颜色、车标检测结合实现时,可以将车牌的定位也用相同的检测方法即目标检测yolov3算法。
4、车牌识别
现有开源框架模型虽然较准率很高,但不是100%,仍然存在很多问题如‘o0DQ’‘B8’‘2Z’‘5S’‘4Z’‘1I’‘汉字’等的识别中误识别率较高,针对这个问题可以重新优化训练网络。
六、车牌校正调研
车牌校正是车牌定位和字符分割的一个重要处理过程。经过车牌定位后所获取的车牌图像不可避免地存在某种程度上的倾斜,这种倾斜不仅会给字符分割带来困难,最终对车牌识别的正确率造成影响。
现有对车牌倾斜进行校正的算法主要有四类:直线检测法、投影最值法、角点检测法和主方向分析法。http://www.doc88.com/p-1915679548419.html
直线检测法是最常用的,该类方法是利用Hough变换或Radon变换来检测车牌边框的两条最长平行线,然后计算该平行线与水平线的夹角,最后根据该夹角度数对车牌进行倾斜校正,比如贾晓丹等提出的基于Radon变换的车牌倾斜校正算法,王少伟等提出的基于RGB色彩空间和Hough变换的车牌校正定位算法 。该类方法对车牌的边缘依赖较大,当检测出的边缘宽度不一致或者不平滑时,该类方法检测得到的倾斜角并不是真实的倾斜角度,并且该类方法仅仅在水平方向实现对车牌的倾斜校正。吴丽丽和刘威分别提出了利用Radon变换来检测车牌在水平和垂直两个方向的倾斜角度,最后在不同方向上分别对车牌进行倾斜校正,该方法仍然对车牌的边缘依赖性很强,对噪声也比较敏感。
投影最值法是利用车牌在倾斜方向上的投影具有特殊最值得特征,通过一定步长旋转图像来找到对应特征得旋转角度,该角度即车牌得倾斜角度。
角点检测法是通过寻找车牌区域的四个角点来定位车牌,进而对车牌进行倾斜校正。
主方向分析法则是利用主成分分析等工具寻找边缘点在最小均方误差意义下的特征直线来计算车牌的倾斜角度,进而对车牌进行倾斜校正。
基于低秩纹理特征的车牌倾斜校正方法—论文结合低秩纹理和低秩先验的概念,提出一种基于低秩纹理特征的车牌倾斜校正算法,这样进一步提高倾斜校正的准确性和鲁棒性。该算法首先假定原始未倾斜的车牌图像是一个低秩纹理,在该假定条件下首先在旋转意义上对车牌图像进行旋转变换,并计算变换后的图像的秩,然后找出秩最小的图像对应的透射变换参数,并利用该参数来对车牌进行倾斜校正。在旋转变换完成后,采用同样的方法在错切变换意义上对车牌进行倾斜校正,这样就得到了最后的倾斜校正结果。
目前常用的校正算法如下:
首先对图像进行边缘检测,找出图像与背景的交线,然后通过一定的算法确定图像的倾斜角度。 这里采用Sobel水平方向算子对图像中的水平边缘直线进行检测。
以下四种方法:https://wenku.baidu.com/view/09fb0808f12d2af90242e609.html
1、基于Hough变换的车牌图像倾斜校正
利用Hough变换法提取直线是一种变换域提取直线的方法,它把直线上的坐标变换到过点的直线的系数域,巧妙的利用了共线和直线相交的关系。
利用Hough变换检测车牌的边框,确定边框直线的倾斜角度,根据倾斜角度选装,获得校正后的图像。 具体步骤如下:
1)图像预处理。读取图像,转换为灰度图像,去除离散噪声点。
2)利用边缘检测,对图像中的水平线进行强化处理。 可选用Sobel算子来检测图像中水平方向的直线。
3)基于Hough变换检测车牌图像的边框,获取倾斜角度。
4)根据倾斜角度,对车牌图像进行倾斜校正。
Hough变换原理: 采用极坐标(ρ,θ)作为变换空间,其极坐标方程如下:
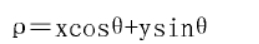
其中ρ为原点到这条直线的距离,θ为发现与x轴的夹角;
落在直线上的每一个样本点对应极坐标一条曲线。θ 的范围取到(-20,20)度, ρ的范围取到(-D, D), D为图像对角线的长度。 落在(ρ0, θ 0)所对应的直线上的样本点最多,则θ 0为水平倾斜角度。
直线的Hough变换在极坐标系(亦称为Hough参数空间)中是一个点,而一点的Hough变换是一正弦曲线。 检测流程如下:
对于每一个(X0,Y0)点代入θ 的量化值(该量化值要合适,不能过粗或过细),计算出各个ρ,所得到的量化置落在某个小格内,使得该小格的计数累加器加1,当全部(X,Y)点变换完毕后,对小格进行检验,有大的计数值的各个小格对应于共线点,其(ρ,θ )可用作直线拟合参数,有小的计数值的各个小格一般反映非共线点,丢弃不用。
基于Hough变换倾斜校正方法的主要缺点是:计算量大(有大量的正弦,余弦运算),倾斜角范围一般局限于-15~15度。
2、基于Radon变换的车牌图像倾斜校正
将车牌图像朝各个方向投影,进而通过分析各方向的投影特性确定车牌的倾斜角度。具体的实现步骤如下:
1)图像预处理。读取图像,转换为灰度图,去除离散噪声点。
2)利用边缘检测,对图像中的水平线进行强化处理。
3)计算图像Radon变换,获取倾斜角度。
4)根据倾斜角度,对车牌图像进行倾斜校正。
3、最小二乘法 (线性回归法)
将汽车牌照图像进行二值化,就可以得到与背景的明显交线,对于汽车牌照图像二值化的阈值可以取的高一点。
最小二乘法原理图如下所示:
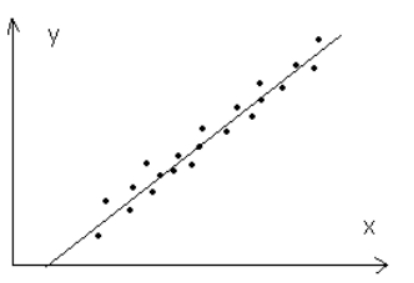
图1 最小二乘法原理图
倾角矫正前的车牌图像如下所示:

图2 倾角矫正前图像
matlab中执行bw=im2bw(pic, 0.3)就可以得到二值化的图像,如下:

从上图可以看出如果我们能够检测到图像上边缘的一系列的边界点,我们就可以通过最小二乘法拟合这条边界直线,从而确定图像的倾角。
具体方法如下:
1)找出边界直线上的点(每列第一次由黑变白的点,且这一列的下两个点还是白的话就可以判为边界点), 将其行坐标存入数组a中,列坐标存入数组b中。
2)通过最小二乘法拟合这条边界直线,计算出其斜率L。
3)通过rot=atan(L), 计算 直线的倾斜角度,然后对其校正。 atan函数返回数字的反正切值。
执行结果如下所示:

图3 用最小二乘法校正后图像
4、两点法
原理非常简单,就是:如果知道直线上不同两点的坐标,我们就可以求得这条直线的斜率,进而确定直线倾角。 在使用最小二乘法时,已经检测到图像与背景交线的一系列坐标点,这些点近似分布在一条直线上。其原理如下图:
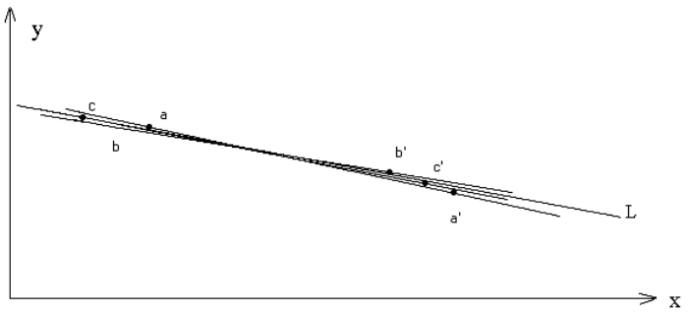
图1 两点发原理图
如图1所示:a,b,c,a’,b’,c’点近似分布在一条直线L上,直线L的斜率与直线aa’, bb’, cc‘的斜率近似,我们求出aa’,bb‘,cc’的斜率,再求平均值,平均值就可以近似认为是直线L的斜率。这样就可以确定L的倾角。
这里选取汽车牌照图像上边缘的两百个坐标点做出一百条直线(做出直线的两点的距离尽量大),然后计算这一百条直线的斜率,而后确定一百个倾斜角度并求出其平均值作为直线L的斜率。
5、总结
上述四种方法对倾斜角度矫正都非常有效。Hough变换和Radon变换相似,其对抗干扰能力比较强,但是运算量大,程序执行慢,其改进方法为:可以不对整幅图像进行操作,在图像中选取一块(必须含有一条与倾角有关的直线)进行操作,从而减小运算量。Hough变换和Radon变换进行倾角检测的最大精度为1度,他们的优点是可以计算有断点的直线的倾角。 最小二乘法的优点是运算量小,但是其抗干扰能力比较差,容易受到噪声的影响。 两点法虽然理论简单,但由于采样点比较多而且这些点服从随机分布,计算均值后能有效抑制干扰,实验表明其矫正效果很好,最大精度可以明显小于1度,而且计算量也很小。最小二乘法和两点法的缺点是不能计算有断点的直线倾角。
下图是利用matlab的GUI功能设计的车牌图像倾斜角度矫正系统:
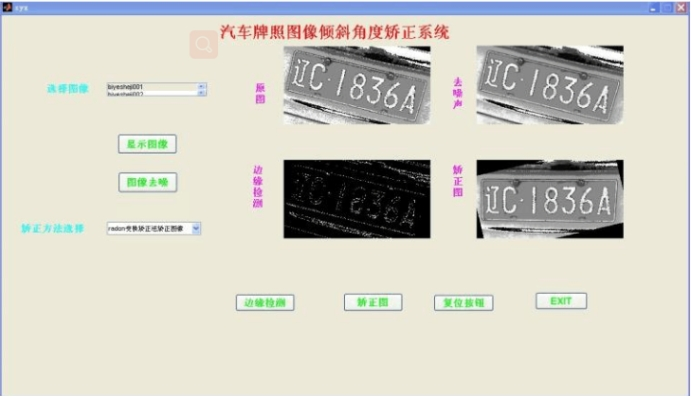
车牌图像识别系统
七、车牌识别数据集
CCPD数据集
用于车牌识别的大型国内的数据集,由中科大的科研人员构建出来的。发表在ECCV2018论文Towords End-to-End License Plate Detection and Recognition:A Large Dataset and Baseline
https://github.com/detectRecog/CCPD
该数据集在合肥市的停车场采集得来的,采集时间早上7.30到晚上10.00。涉及多种复杂环境。
一共包含超多25万张图片,每张图片大小72011603。一共包含9项。
参考:来自 https://blog.csdn.net/baidu_38634017/article/details/105805855
八、算法复现
1、HyperLPR实现
无需进行字符分割
GitHub: https://gitcode.net/mirrors/icepoint666/HyperLPR?utm_source=csdn_github_accelerator
运行:
246服务器 Dir:/home/xxx/PLR/HyperLPR-simple/HyperLPR-master
python demo.py --detect_path ./dataset/4.jpg --save_path ./result/
python multi_demo.py --detect_parent_path ./dataset/ --save_path ./result/
2、LPRNet实现
无需对字符进行提前切割
运行:
服务器 dir: /home/xxx/PLR/plate-main
python detect.py
YOLOv5与LPRNet训练车牌识别
https://zhuanlan.zhihu.com/p/442836317
LPRNet没有对字符进行预分割,可以说是一个端到端的车牌识别算法。
论文: LPRNet: License Plate Recognition via Deep Neural Networks (2018)
GitHub:https://github.com/sirius-ai/LPRNet_Pytorch
来自 https://blog.csdn.net/qq_14845119/article/details/120783704
3、评估结果
hyperlpr : 25张testimg,4张FALSE
LPRNet :25张testing,5张FALSE
4、LPRNet
实时目标检测网络(Yolov5Net)用于从车辆图像中提取特征并且通过训练对车辆进行实时目标检测;
车牌识别神经网络(LPRnet)用于从车牌提取特征并且通过训练对车牌进行实时识别。
LPRNet特性:
- 实时、高精度、支持车牌字符边长、无需字符分割、对不同国家支持从零开始end-to-end的训练;
- 第一个不需要使用RNN的足够轻量级的网络,可以运行在各种平台,包括嵌入式设备;
- 鲁棒,LPRNet已经应用于真实的交通监控场景,事实证明它可以鲁棒的应对各种困难情况,包括透视变换、镜头畸变带来的成像失真、强光、视点变换等。
车牌识别的挑战:
图像模糊、很差的光线条件、车牌数字的变化(比如中国和日本的车牌有一些特殊字符)、车牌变形、天气影响(比如雨雪天气)、车牌上的字符个数有变化。
空间变换预处理LocNet
这是对检测到的车牌形状上的校正,使用Spatial Transformer Layer ,这一步是可选的,但用上可以使得图像更好地被识别。
LPRNet的基础构建模块
LPRNet的基础网络构建模块收启发于SqueezeNet Fire Blocks 和Inception Blocks
骨干网络将原始的RGB图像作为输入,计算得到空间分布的丰富特征。为了利用局部字符的上下文信息,该论文使用了宽卷积(1*13kernel)而没有使用LSTM-based RNN。骨干网络最终的输出,可以被认为是一系列字符的概率,其长度对应于输入图像像素宽度。
由于解码器的输出与目标字符序列长度不同,训练的时候使用了CTC Loss,它可以很好地应对不需要字符分割和对齐的end-to-end训练。
为了进一步提高性能,使用了global context 嵌入。
推理阶段对上述一系列字符的概率进行解码,使用beam search ,它可以最大化输出序列的总概率。
后过滤post-filtering阶段,使用面向任务的语言模型实现作为目标国家车牌模板的一组集合,后过滤阶段是和beam search结合一起用的,获得通过beam search 找到的前N个最可能序列,返回与预定义模板集合最匹配的第一个序列,该模板取决于特定国家的车牌规则。
识别实验结果
训练时,使用一个来自监控场景的中国车牌的似有库,总共有11696幅经过LBP级联检测器检测出来的车牌,并进行了数据增广(data augmentation)即随机旋转、平移、缩放。
最大的识别精度增益来自于global context(36%),其次是data augmentation(28.6%),STN-based alignment即预处理也带来了显著提高(2.8-5.2%),beam search联合post-filtering进一步提高了0.4-0.6%。
识别速度
Intel将LPRNet在CPU/GPU/FPGA上都进行了实现,这里GPU用的是NVIDIAGeForce 1080,CPU是Core i7 -6700K SkyLake,FPGA是Intel Arria 10,推断引擎IE来自Intel OpenVINO。
Intel已经商用,虽然该论文本身没有什么新的发明。但有它的价值和优势。
每个车牌的识别时间: