目录
一、awk介绍
1)awk概述
AWK 是一种用于处理文本的编程语言工具。AWK 在很多方面类似于 shell 编程语言,尽管 AWK 具有完全属于其本身的语法。它的设计思想来源于 SNOBOL4 、sed 、Marc Rochkind设计的有效性语言、语言工具 yacc 和 lex ,当然还从 C 语言中获取了一些优秀的思想。在最初创造 AWK 时,其目的是用于文本处理,并且这种语言的基础是,只要在输入数据中有模式匹配,就执行一系列指令。该实用工具扫描文件中的每一行,查找与命令行中所给定内容相匹配的模式。如果发现匹配内容,则进行下一个编程步骤。如果找不到匹配内容,则继续处理下一行
2)awk的工作原理
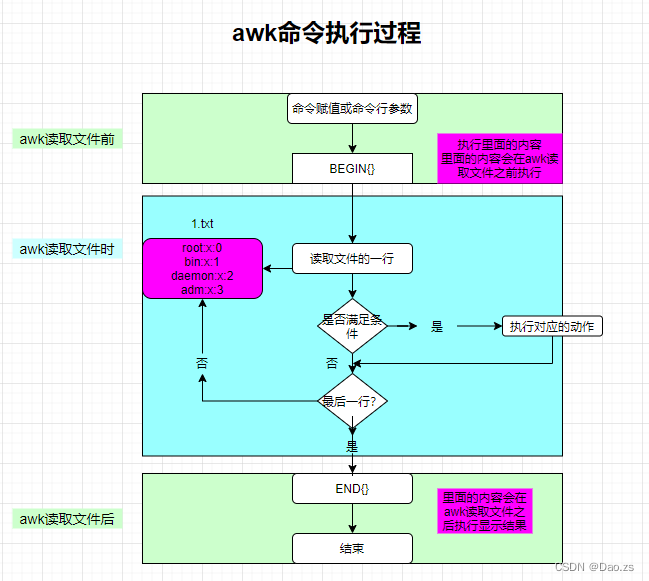
- 逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令;
- sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个“字段”再进行处理;
- awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示;
- 在使用awk命令的过程中,可以使用逻辑操作符“&&”表示与、“||”表示或、“!”表示非,还可以进行简单的数学运算如+-*/%^,分别表示加减乘除取余和乘方
3)awk的数学计算(浮点运算)
#bash不支持浮点运算,如果需要进行浮点运算,需要借助bc,awk处理
#!/bin/bash
#加
f=$(echo "4.3+2.5"|bc)
echo "4.3+2.5=$f"
#减
f=$(echo "4.3-2.5"|bc)
echo "4.3-2.5=$f"
#乘
f=$(echo "4.30*2.50"|bc)
echo "4.3*2.5=$f"
#除
f=$(echo "scale=2;4.3/2.5"|bc)
echo "4.3/2.5=$f"
#混合运算
f=$(echo "2.2/(2.2-1.1)*2+1.1"|bc)
echo "2.2/(2.2-1.1)*2+1.1=$f"
#加
f=$(awk 'BEGIN{print 4.5+3.4 }')
echo "4.5+3.4=$f"
#减
f=$(awk 'BEGIN{print 4.5-3.4 }')
echo "4.5-3.4=$f"
#乘
f=$(awk 'BEGIN{print 4.5*3.4 }')
echo "4.5*3.4=$f"
#除
f=$(awk 'BEGIN{print 4.5/3.4 }')
echo "4.5/3.4=$f"
#混合
f=$(awk 'BEGIN{print (4.5-3.4)*2+3 }')
echo "(4.5-3.4)*2+3=$f"二、awk的基础用法和选项
1)awk的基本格式及其内置变量
awk 选项 '模式或条件 {操作}' 文件1 文件2...
awk -f 脚本文件 文件1 文件2-
注意一定是单引号:'模式或条件 {操作}'
-
{ }外指定条件,{ }内指定操作。
-
用逗号指定连续的行,用 || 指定不连续的行。&&表示”且“。
-
内建变量,不能用双引号括起来,不然系统会把它当成字符串
| 内置变量 | 作用 |
| $0 | 当前处理的行的整行内容 |
| $n | 当前处理行的第n个字段(第n列) |
| NR | 当前处理的行的行号(序数) |
| NF | 当前处理的行的字段个数。$NF代表最后一个字段 |
| FS | 列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同 |
| OFS | 输出内容的列分隔符 |
| FILENAME | 被处理的文件名 |
| RS | 行分隔符。awk从文件中读取资料时,将根据RS的定义把资料切割成许多条记录, 而awk一次仅读入一条记录进行处理。预设值是"\n" |
2)基本打印用法
①打印文章所有内容
[root@localhost awk]#awk '{print}' english.txt
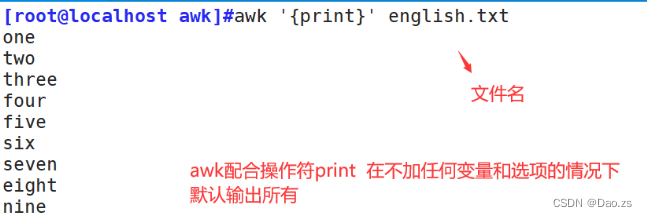
另外:0和1放置{ }前,能够起到限制答应的作用(默认为"1")

[root@localhost awk]#awk '{print $0 }' english.txt

②打印行内容及其行号
[root@localhost awk]#awk '{print NR}' english.txt

[root@localhost awk]#awk '{print NR,$0}' english.txt
③指定行和指定行范围打印
[root@localhost awk]#awk 'NR==3{print}' english.txt
[root@localhost awk]#awk 'NR==3,NR==5{print}' english.txt
[root@localhost awk]#awk '(NR>=3)&&(NR<=5){print}' english.txt 
④奇偶行打印
[root@localhost awk]#awk 'NR%2==0{print}' english.txt
[root@localhost awk]#awk 'NR%2==1{print}' english.txt 
⑤奇偶打印特殊方式的引入——getline
getline的工作过程:
1)当getline左右无重定向符号(“<”)或者管道符号(“|”)时,awk首先读取的是第一行,而getline获取的是是光标跳转至下一行的内容(也就是第二行)
原因:getline运行之后awk会改变NF,NR,$0,FNR等内部变量,所以此时读取$0的行号不再为1,而是2
拓展:
FNR:awk当前读取的记录数,其变量值小于等于NR,(比如说当读取完第一个文件后,读取第二个文件,FNR是会从0开始进行,而NR不会)
因此读取两个或两个以上的文件,NR==FNR,可以 判断是不是在读取第一个文件
2)当getline左右有管道符号或重定向符时,getline则作用定向输入文件,由于文件是刚打开,并没有被awk读入一行,而只是getline读入,所以getline返回的是文件的第一行,而不是跳转至一行输入
getline 打印偶数行:
[root@localhost awk]#awk '{getline;print $0}' english.txt
[root@localhost awk]#seq 10|awk '{getline;print $0}' 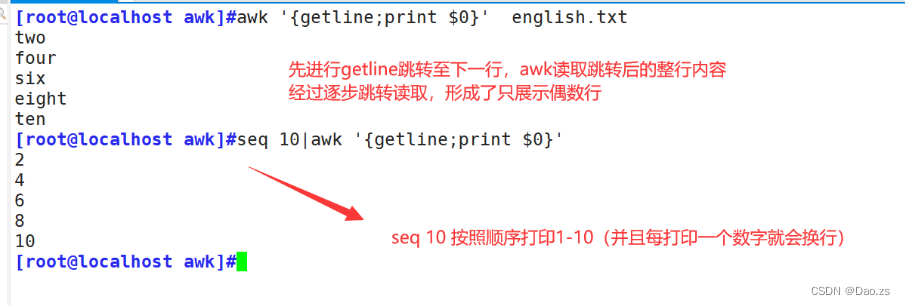
getline 打印奇数行 :
[root@localhost awk]#awk '{print $0;getline}' english.txt
[root@localhost awk]#seq 10|awk '{print $0;getline}' 
⑥文本内容匹配过滤打印
[root@localhost awk]#awk '/^root/{print}' /etc/passwd
[root@localhost awk]#awk '/bash$/{print}' /etc/passwd
3)BEGIN打印模式
格式:awk 'BEGIN{...};{...};END{...}' 文件处理过程:
- 在awk处理指定的文本之前,需要先执行BEGIN{...}模式里的命令操作
- 中间的{...} 是真正用于处理文件的命令操作
- 在awk处理完文件后才会执行END{...}模式里的命令操作。END{ }语句块中,往往会放入打印结果等语句
示例:
[root@localhost awk]#awk 'BEGIN{x=1};{x++};END{print x}' english.txt
拓展:
awk是从c语言中继承到Linux,所以在BEGIN模式中变量x,可以直接运用,无需"$"声明获取变量值

4)对字段进行处理打印
①指定分隔符打印字段
普通指定方式:
[root@localhost awk]#head -n5 /etc/passwd |awk -F':' '{print$3}'
[root@localhost awk]#head -n5 /etc/passwd |awk -F':' '{print$5}' 
BEIGIN模式指定:
[root@localhost awk]#head -n5 /etc/passwd|awk 'BEGIN{FS=":"};{print $5}'
[root@localhost awk]#head -n5 /etc/passwd|awk 'BEGIN{FS=":"};{print $3}'
②条件判断打印
正向判断打印:
[root@localhost awk]#awk -F: '$3>500{print $0}' /etc/passwd

判断取反打印:
[root@localhost awk]#awk -F: '!($3>10){print $0}' /etc/passwd
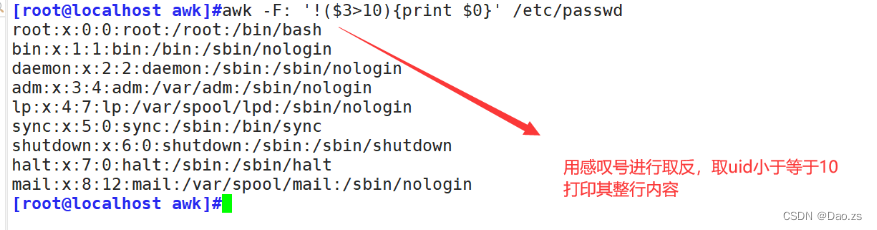
除此之外,甚至可以直接进行if语句判断打印:
[root@localhost awk]#awk -F: '{if($3>500){print $0}}' /etc/passwd
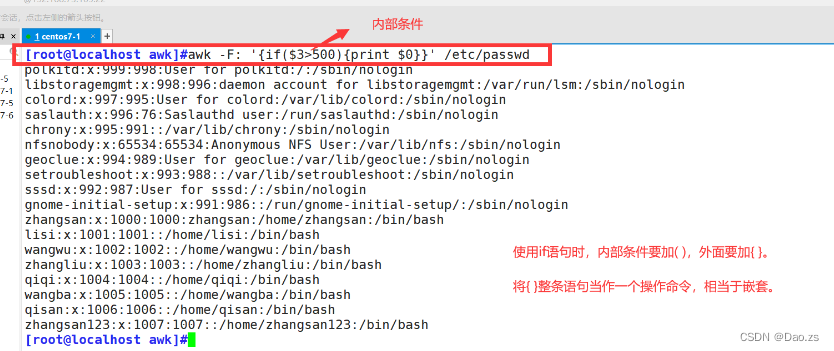
三、awk的三元表达式与精准筛选用法
1)awk的三元表达式
①shell的三元表达式
Shell中: [ 条件表达式 ] && A || B
- 条件表达式成立(为真)时,会取||前面的值A。 - 条件表达式不成立(为假)时,会取||后面的值B
②awk的三元表达式运用
格式:awk '(条件表达式)?(A表达式或者值):(B表达式或者值)'[root@localhost awk]# awk -F: '{max=($3>=$4)?$3:$4;{print max,$0}}' /etc/passwd|sed -n '1,6p'
同时:通过管道符sed命令只打印其中的前六行内容

2)awk的精准筛选
精准筛选方法:
| $n(> < ==) | 用于对比数值 |
| $n~"字符串" | 代表第n个字段 包含 某个字符串的作用 |
| $n!~"字符串" | 代表第n个字段 不包含 某个字符串的作用 |
| $n=="字符串" | 代表第n个字段 为 某个字符串的作用 |
| $n!="字符串" | 代表第n个字段 不为 某个字符串的作用 |
| $NF | 代表最后一个字段 |
运用1:输出第七个字段包含“bash”所在行的第一个字段和最后一个字段
[root@localhost awk]#awk -F: '$7~"bash" {print $1,$NF}' /etc/passwd

运用2:输出第七个字段不包含“nologin”所在行的第一个字段和最后一个字段
[root@localhost awk]#awk -F: '$7!~"nologin" {print $1,$NF}' /etc/passwd
运用3:指定第六个字段为/home/lisi ,第七个字段为/bin/bash,输出满足这些条件所在行的第一个和最后一个字段
[root@localhost awk]#awk -F: '($6=="/home/lisi")&&($7==/bin/bash)"nologin" {print $1,$NF}' /etc/passwd

四、awk的分隔符用法
1 )RS 指定行分隔符
awk从文件中读取资料时,将根据RS的定义把资料切割成许多条记录, 而awk一次仅读入一条记录进行处理。内置变量RS的预设值是"\n"。
但是也可以在使用BEGIN模式在操作前进行行分隔符的改变
[root@localhost awk]#echo $PATH|awk 'BEGIN{RS=":"};{print NR,$0}'
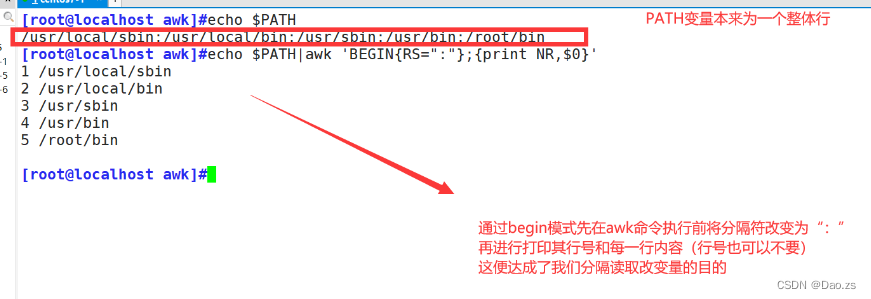
2)指定输出的分隔符
FS 输入时的列分隔符
OFS 输出内容的列分隔符。($n=$n用于激活,否则不生效,n且必须存在)
对于输出时改变分隔符,我们常用到tr,awk,它们都可以实现在输出内容改变原本的分隔符
①tr改变分隔符输出
[root@localhost awk]#echo a b c d
[root@localhost awk]#echo a b c d|tr " " ":"②awk改变输出分隔符
直接修改输出分隔符 :
[root@localhost awk]#echo a b c d|awk '{OFS=":" ; $1=$1;print $0}'
BEGIN模式中修改输出分隔符:
[root@localhost awk]#echo a b c d|awk 'BEGIN{OFS=":"};{$2=$2;print $0}'
[root@localhost awk]#echo a b c d|awk 'BEGIN{OFS=":"};{$3=$3;print $0}'
[root@localhost awk]#echo a b c d|awk 'BEGIN{OFS=":"};{$4=$4;print $0}'
[root@localhost awk]#echo a b c d|awk 'BEGIN{OFS=":"};{$5=$5;print $0}'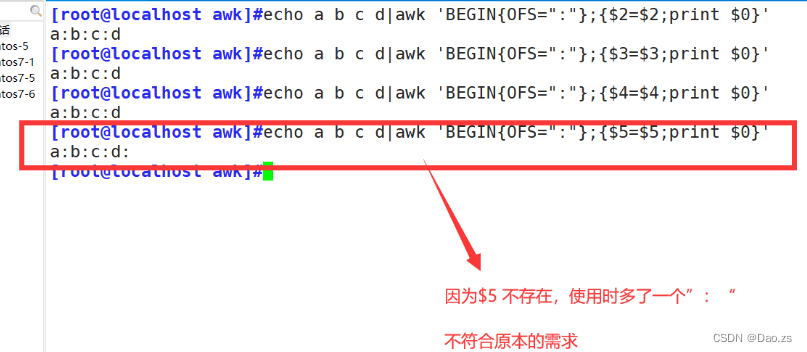
五、awk结合数组运用
1)awk中定义数组打印
[root@localhost awk]#awk 'BEGIN{a[0]=10 ; a[1]=20 ; a[2]=30;print a[1]} '
[root@localhost awk]#awk 'BEGIN{a[0]=10 ; a[1]=20 ; a[2]=30;print a[0]} '
[root@localhost awk]#awk 'BEGIN{a[0]=10 ; a[1]=20 ; a[2]=30;print a[2]} '
此外:awk中的数组还能形成遍历
2)awk打印文件内容去重统计
①去重打印数组
[root@localhost awk]#echo ${arry[@]}|awk -v RS=' ' '!a[$1]++'
[root@localhost awk]#awk -v RS=' ' '!a[$1]++' <<< ${arry[@]}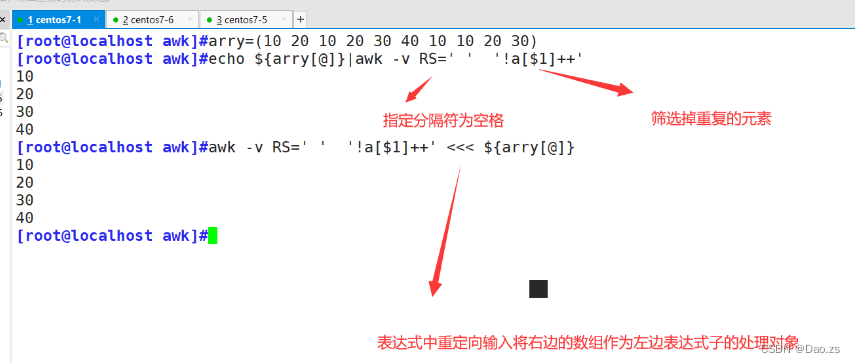
②处理文件去重统计
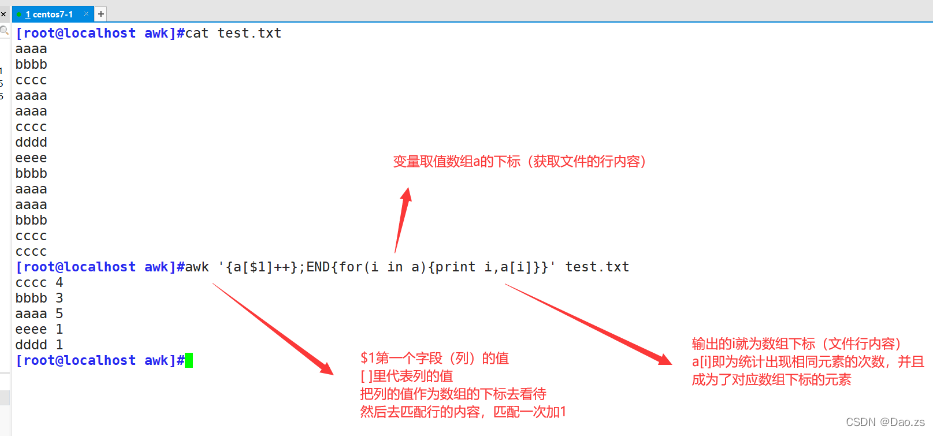
原理:将文件的字段内容变为定义的数组下标,对其进行匹配读取累加(只有遇到完全一致的才会累加),此时重复的次数在for循环的作用下成为了数组对应下标的元素
所以输出该下标和元素(就等同于输出重复的字段内容 以及 统计的重复次数)
[root@localhost awk]#awk '{a[$1]++};END{for(i in a){print i,a[i]}}' test.txt
需求:
统计ssh登录失败的用户及其登录失败(日志:/var/log/secure中有记录)的次数(通常我们会认为失败三次,存在着暴力破解登录的可能,意味该主机存在隐患)解决方案:将其筛选出来就把IP加入到黑名单中 /etc/hosts.deny。
纯awk筛选统计:
[root@localhost awk]# awk '/Failed password/{a[$11]++};END{for(i in a){print i,a[i]}}' /var/log/secure

其他awk组合方式:
[root@localhost awk]#awk '/Failed password/{print $11}' /var/log/secure |sort -n
[root@localhost awk]#awk '/Failed password/{print $11}' /var/log/secure |sort -n |uniq -c
六、常用awk筛选数据实例
下面有很多的awk获取数据都可以配合脚本加计划性任务编写为一个全自动化运维的检测脚本
1 )获取本机上一次开机时间
[root@localhost awk]#date -d "$(awk -F. '{print $1}' /proc/uptime) second ago" +"%Y%m%d %H:%M:%S"

2)获取本机IP地址
[root@localhost awk]#ifconfig ens33|awk '/inet /{print $2}'

3)检测本机cpu 15分钟内的平均负载
一般超过百七十,就要注意了!!
[root@localhost awk]#uptime|awk '{print $NF}'
4)检测入站网卡流量和出站网卡的流量
#入站网卡
[root@localhost awk]#ifconfig ens33|awk '/RX p/{print $5}'
#出站网卡
[root@localhost awk]#ifconfig ens33|awk '/TX p/{print $5}'
5)内存剩余量
[root@localhost awk]#free -m |awk '/^Mem/{print $4}'

6)根分区剩余量
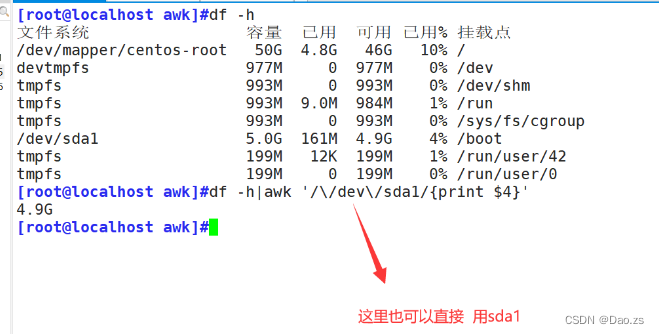
[root@localhost awk]#df -h|awk '/\/dev\/sda1/{print $4}'
其他有用数据的提取(非awk)
user=`cat /etc/passwd |wc -l`
echo "本地账户数量为:"$user
login=`who | wc -l`
echo "当前登陆计算机的账户数量为:"$login
process=`ps aux | wc -l`
echo "当前计算机启动的进程数量为:"$process
soft=`rpm -qa | wc -l`
echo "当前计算机已安装的软件数量为:"$soft