安全始终是重如泰山的事情,安全事件如果能够做到早发现早制止可能结果就会完全不一样了,本文的核心目的很简单,就是想基于目标检测模型来尝试构建枪支刀具等危险物品检测识别系统,希望基于人工智能手段来打击犯罪行为,简单看下效果图:
这种场景是比较敏感的,所以基本上很难去自己真实采集数据集去开发模型的,所以这里的数据大都是来源于互聊网,主要是实践分析使用,简单看下数据集如下所示:

VOC格式标注文件如下所示:
实例标注内容如下所示:
<annotation>
<folder>DATASET</folder>
<filename>images/0a53eb41-a382-4463-ad29-3e63bef6420d.jpg</filename>
<source>
<database>The DATASET Database</database>
<annotation>DATASET</annotation>
<image>DATASET</image>
</source>
<owner>
<name>YMGZS</name>
</owner>
<size>
<width>416</width>
<height>416</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>pistol</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>3</xmin>
<ymin>7</ymin>
<xmax>403</xmax>
<ymax>395</ymax>
</bndbox>
</object>
</annotation>YOLO格式标注文件如下所示:

实例标注内容如下所示:
1 0.546875 0.492788 0.122596 0.466346
核心训练配置如下所示:
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='weights/yolov5n.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5n.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/self.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=416, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=0, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--name', default='yolov5n', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
可以看到:我这里使用的是n系列的模型,图像尺寸使用的是416x416的,默认执行100次epoch的迭代计算。
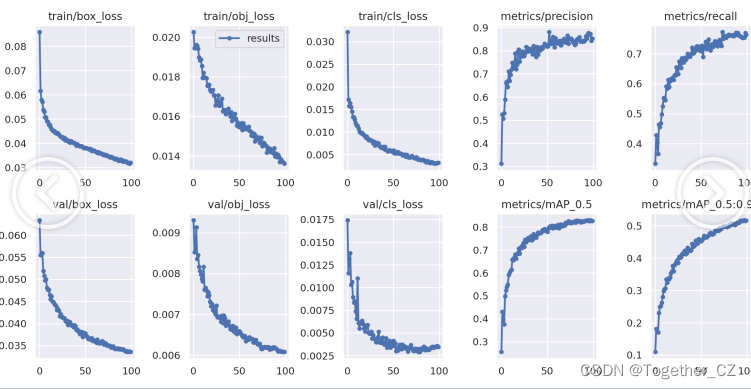
结果详情如下所示:
F1值和PR曲线如下:
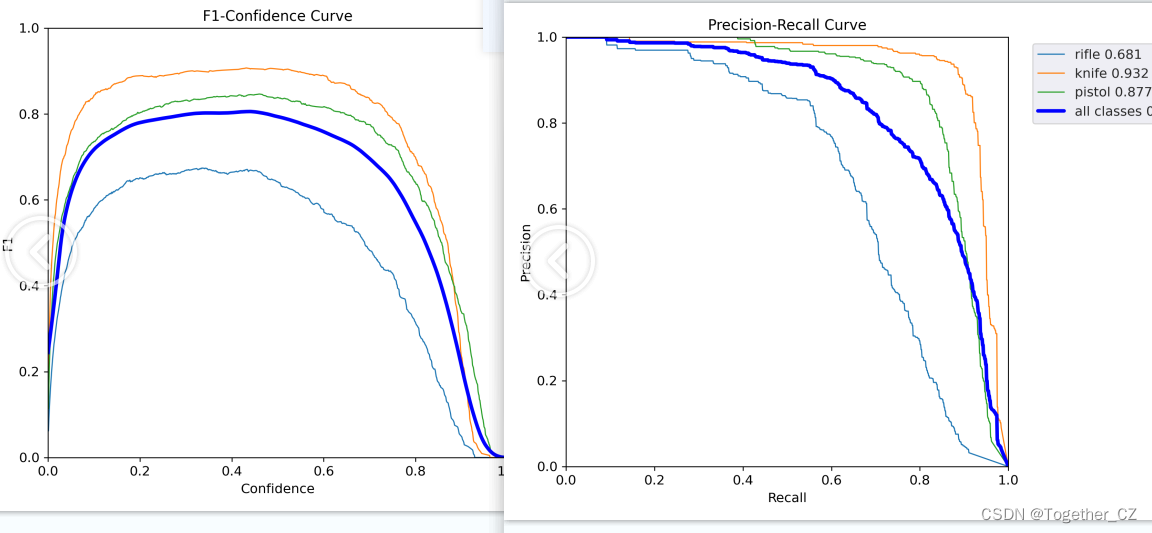
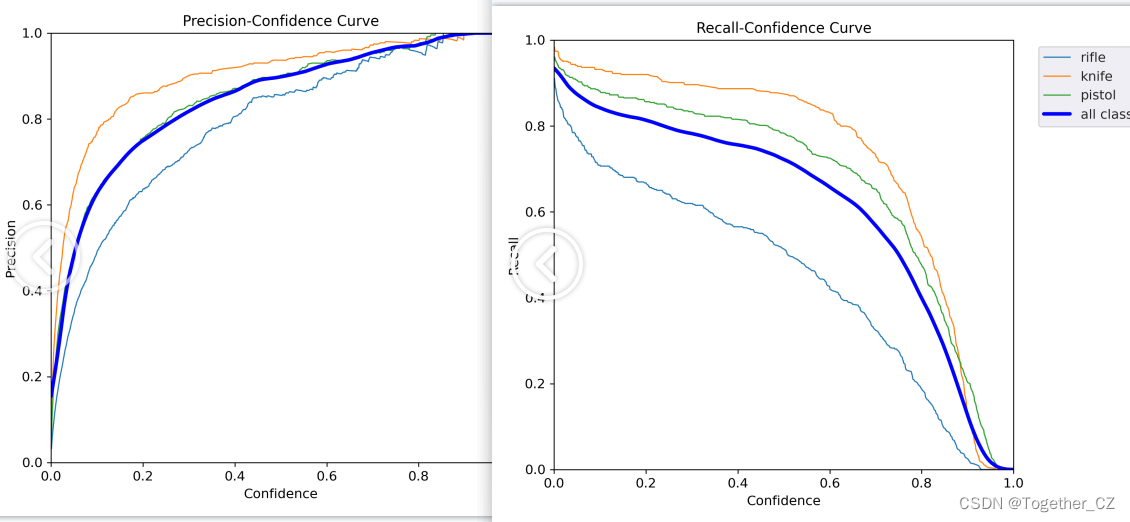
精确率和召回率曲线如下:
整体训练可视化如下:
batch计算实例如下:

感兴趣的话也都是可以尝试一下的
混淆矩阵如下:

数据可视化如下:
