编写高效的代码有两个条件:选择好的算法和数据结构,编写编译器能够优化以转换成高效可执行的代码。前者是基础和前提,即使后者做的足够好,但是选用了错误的算法和数据结构,优化也不起作用,这个一点要搞清楚。本文的内容的侧重于后者。
1 计算机系统架构
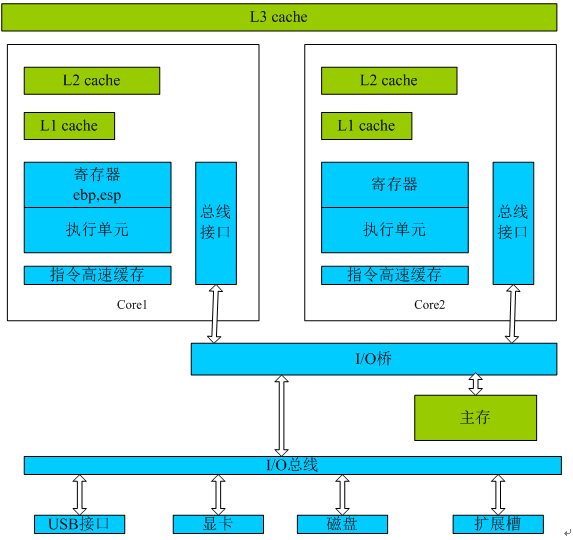
L1和L2位于CPU芯片上,L3被各个CPU共享。由于成本的考虑,L3,L2,L1的大小依次递减。以INTEL XEON E7-8891V2为例,L3 :37.5 MB,L2 :2.5 MB,L1 :640 KB。
2 各种存储的速度比
寄存器 |
|
L1 |
10-13 |
L2 |
10-12 |
L3 |
10-11 |
内存 |
10-10 |
磁盘 |
10-3 |
从上表中可以看出,内存比磁盘快1000万倍。
3 进程的内存分布
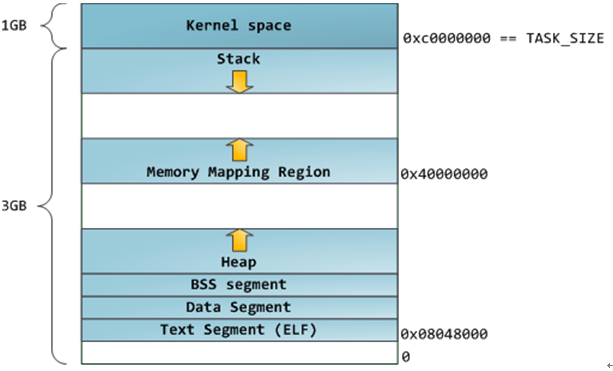
共享映射库的起始地址是0x40000000(1G),BSS: 未初始化的全局变量。
4 函数调用的开销
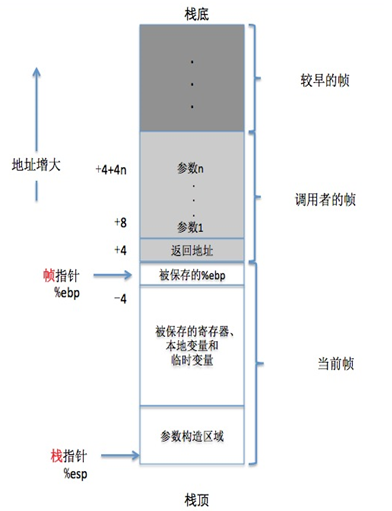
ebp寄存器指向当前帧的栈底,esp寄存器指向当前帧的栈顶。函数被调用时,都会生成一个新的帧。返回地址:函数调用返回调用者后,待执行的代码的地址。在调用函数之前,调用者在自己的栈内构造参数。缓冲区溢出攻击的原理:覆盖被保存的ebp和返回地址,执行攻击者指定的函数。
5 代码优化
编写高效的代码有两个步骤:选择好的算法和数据结构,编写编译器能够优化以转换成高效可执行的代码。第一个步骤是前提。即使第二部做的足够好,但是选用了错误的算法和数据结构,优化也不起作用。本小节后续的优化措施指的是后者。
5.1 函数调用和系统调用
(1) 从第四小节可以看出,函数调用的开销不菲。所以在调用次数非常高的函数内,尽量少的使用函数,特别是小函数。
(2) 尽量把循环内部的函数调用移到循环外部。
带来的副作用损害了代码的可读性,可维护性。
系统调用的的开销:
1,段的切换。
2,当前数据、指令预取队列的刷新和重建。
3,数据复制。5.2 利用内存局部性原理
时间局部性:如果数据被访问,则不久之后该数据可能被再次访问。
空间局部性:如果某个存储单元被访问,则不久之后附近的存储单元也会被访问。
例:没有利用空间局部性的代码
for(i=0;i<M;i++)
for(j=0;j<N;j++)
sum += a[j][i];
例:利用空间局部性的代码
for(i=0;i<M;i++)
for(j=0;j<N;j++)
sum += a[i][j];
重复利用同一变量有良好的时间局部性。
5.3 适应CPU的指令流水线
执行指令的基本流程:
1 从内存读取指令到L1
2 对L1中的指令译码
3 执行单元执行指令
现代的CPU进行分支预测,在指令高速缓存区形成一个指令流水线,如果预测失败,需要重新从内存读取指令,译码形成一个新的指令流水线,对CPU而言,操作内存的开销非常大(2个数量级的差别),所以代价非常高。
优化措施:
(1) 尽量减少分支
尽量不用if/else switch。用switch代替if/else,因为跳转指令更少。
经过测试if 和?:的汇编代码是一样的,所以性能也一样。
(2 )减少小循环,因为循环里面有跳转指令
(3)减少函数调用