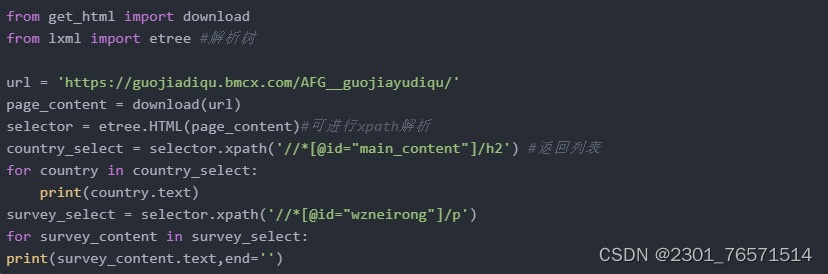
步骤/方式一
正则表达式(re库)
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。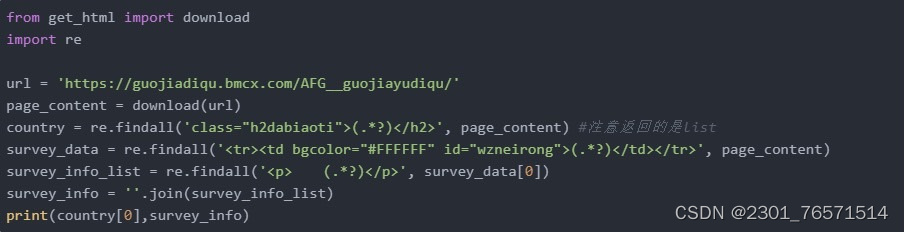
步骤/方式二
BeautifulSoup(bs4)
beautifulSoup是用python语言编写的一个HTML/XML的解析器,它可以很好地处理不规范标记并将其生成剖析树(parse tree)。它提供简单而又常见的导航(navigating),搜索及修改剖析树,此可以大大节省编程时间。
步骤/方式三
lxml
lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的数据;lxml和正则一样,也是用C语言实现的,是一款高性能的python HTML、XML解析器,也可以利用XPath语法,来定位特定的元素及节点信息。