呐,作为后台程序猿,必不可少的要与数据库打交道,所以今天记录下平时工作中遇到的一些sql问题。
数据库操作,大家用的最多的应该就是select了,使用select我们要记住一个原则:尽量使每次查询的结果集够小!
比如一个嵌套查询A(1000)B(100)C(10),括号中为每个查询结果的行数,如果我们按ABC来执行,那么显然比按CBA执行耗时更长。
为了执行效率的提高,正常都会给某些关键字段加上索引,但需要注意的是,一旦查询结果数超过了整张表的2%~5%(通常情况),查询就不走索引了,所以还是那句话:要减小每次查询结果集。
一个很重要的点:
很多表中都会存在日期字段,很多同学根据日期来查询的时候通常会这样写:
select * from tableA where fieldDate>’20170101’
很显然,这样是能查出结果的,但是这样是不走日期上的索引的,因为数据库会默认把fieldDate转成varchar然后再与’20170101’比较。
还有同学这样写:
select * from tableA where DATE_FORMAT(fieldDate, ‘%Y-%m-%d’) >DATE_FORMAT(20170101, ‘%Y-%m-%d’)
这样也是不对的,我们要避免在字段上加处理函数。
正确的写法应该是这样:
select * from tableA where fieldDate>STR_TO_DATE(20170101, ‘%Y-%m-%d’)
几个sql:
IF函数是一个很常用也很重要的函数,
select if(isnull(query_times), 1, query_times+1) as m1
select if(query_times>0, true, false) as m2
与之相对应的还有case when,适合多种分支的情况。
一个表中根据字段guid有重复记录,怎么把这些记录找出来?
select * from tableB where guid in (select guid from tableB where status=1 group by guid having count(*) > 1)
mysql中,根据某个字段倒序排序,如果存在行数该字段为null,那么这些行数是显示在最后的:
SELECT * FROM app_feedback ORDER BY reply_time DESC
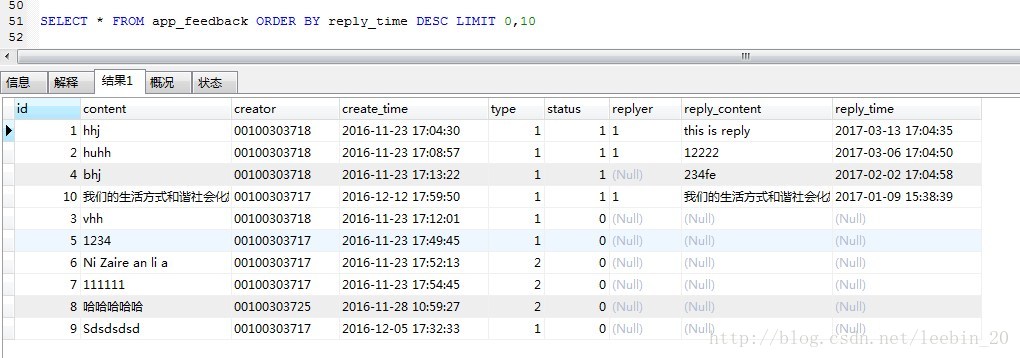
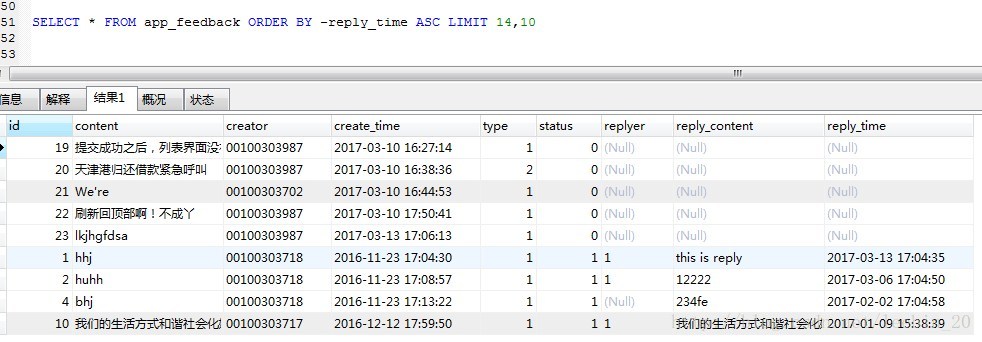
当我们在页面展示时,我们既希望保持倒序排序,又希望把有null值的显示在最前面,方便操作人员优先操作这些为null的记录,此时可以这样:
SELECT * FROM app_feedback ORDER BY -reply_time ASC
多表合并,union和union all,前者自动去掉重复记录,后者保留。
feedback_user表中存在type字段,type有1和2两种值的可能。
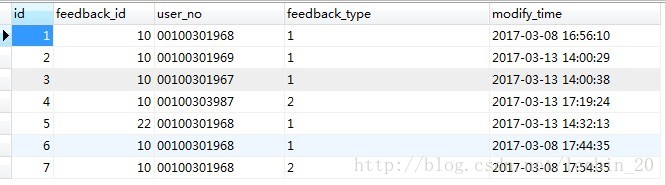
现在需要统计出每个feedback_id对应的type等于1和2的记录数:
SELECT feedback_id,SUM(oppo),SUM(supp) from (
SELECT feedback_type,feedback_id,COUNT(*) as oppo,0 as supp from app_feedback_user where feedback_type=’2’ GROUP BY feedback_id,feedback_type union
SELECT feedback_type,feedback_id,0 as oppo,COUNT(*) as supp from app_feedback_user where feedback_type=’1’ GROUP BY feedback_id,feedback_type) as ta
GROUP BY feedback_id
