最近学习NLP过程中学到了RNN,做了以下笔记
1.1RNN 是什么
我们知道CNN(卷积神经网络)能够处理特定的视觉任务,但它并没有记忆功能,也就意味着没有用到之前的任务来处理新的任务。RNN 相比较于CNN增加了一个时间的维度(当然不仅如此)。
我们可以考虑这样的情景,我要吃XXX,那么我们去预测XXX时,我们就得考虑前边的“我要吃”,不能随意的进行预测,要根据之前的信息进行预测,前一个输入与后一个输入是有关系的,CNN是无法解决此类问题的,那么RNN 也就应运而生。
1.2 RNN基本结构
话不多说先上图(图一)

抛开W这个循环之外的结构,和全连接神经网络就变成一样了
我们梳理一下这个结构:
- x 作为一个向量为输入
- s 作为一个向量,表示隐藏层的值(这里隐藏层面画了一个节点,你也可以想象这一层其实是多个节点,节点数与向量s的维度相同)
- o也是一个向量,它表示输出层的值
- U是输入层到隐藏层的权重矩阵;V是隐藏层到输出层的权重矩阵
- 循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
我们将图一展开,RNN多画几个也就变成了下图(图二)
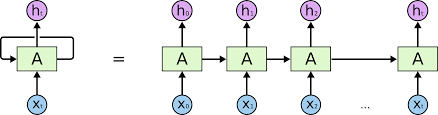
这个网络在 t 时刻接收到输入x(t)之后,隐藏层的值是 s(t-1),输出值是 O(t) 。关键一点是s(t) 的值不仅仅取决于 x(t) ,还取决于 x(t-1) 。
我们可以用下面的公式来表示循环神经网络的计算方法:
解释:式1是输出层的计算公式,输出层是一个全连接层,也就是它的每个节点都和隐藏层的每个节点相连。V是输出层的权重矩阵,g是激活函数。式2是隐藏层的计算公式,它是循环层。U是输入x的权重矩阵,W是上一次的值作为这一次的输入的权重矩阵,f是激活函数。从上面的公式我们可以看出,循环层和全连接层的区别就是循环层多了一个权重矩阵 W。
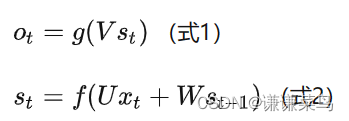
换一种思路重新讲解一下RNN结构:
将CNN加上时间序列这一维度,建立时序上的关联,注意我们不是去增加神经元的数量,而是表示隐层在不同时刻的状态,用权重Ws表示层级间的权重(也就是前一时间的隐藏层到这一隐藏层的权重,假定不同的层也就是不同的时刻去共享这个权重Ws,目的:有效的减少训练参数)
对于CNN 的矩阵形式:![]()
1.3循环神经网络遇到的问题
问题
RNN在训练过程中很容易发生梯度爆炸和梯度消失,导致训练时梯度不能在较长序列中一直传递下去,从而使得RNN无法捕捉到较长距离的影响。
时间跨度大,网络往往不能记忆这么长时间的信息,而且随着时间跨度越来越大,循环神经网络也越来越难以学习这些信息。因为记忆都会有遗忘性,我们总是更加清楚地记得最近发生的事情而遗忘很久之前发生的事情,循环神经网络也有同样的问题。
说了这么多根本原因还是由于梯度爆炸和梯度消失
解决方法
- 通常来说,梯度爆炸更容易处理一些。因为梯度爆炸的时候,我们的程序会受到Nan错误。我们也可以设置一个梯度阈值,当梯度超过这个阈值的时候可以直接截取。
- 梯度消失更难检测,而且也更难处理一些。总的来说,我们有三种方法应对梯度消失问题:
- 合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。
- 使用relu代替sigmoid和tanh作为激活函数。
- 使用其他结构的RNNs,比如长短时记忆网络(LTSM)和Gated Recurrent Unit(GRU),这是最流行的做法。
代码实现
pytorch 中的 RNN
我们分数据处理和模型搭建两部分来介绍。
数据处理
pytorch 的数据读取队列主要靠 torch.utils.data.Dataset 和 torch.utils.data.DataLoader
在一般的数据读取任务中,我们只需要在 Dataset 的 __getitem__ 方法中返回一个样本即可,pytorch 会自动帮我们把一个 batch 的样本组装起来,因此,在 RNN 相关的任务中,__getitem__ 通常返回的是一个维度为 [seq_len x input_size] 的数据。这时,我们会遇到第一个问题,那就是不同样本的 seq_len 是否相同。如果相同的话,那之后就省事太多了,但如果不同,这个地方就会成为初学者第一道坎。因此,下面就针对 seq_len 不同的情况介绍一下通用的处理方法。
首先需要明确的是,如果 seq_len 不同,那么 pytorch 在组装 batch 的时候会首先报错,因为一个 batch 必须是一个 n-dimensional 的 tensor, seq_len 不同的话,证明有一个维度的长度是不固定的,那就没法组装成一个方方正正的 tensor 了。因此,在数据预处理时,需要记录下每个样本的seq_len,然后统计出一个均值或者最大值,之后,每次取数据的时候,都必须把数据的seq_len 填充 (补0) 或者裁剪到这个固定的长度,而且要记得把该样本真实的 seq_len 也一起取出来 (后面有大用)。例如下面的代码:
def __getitem__(self, idx):
# data: seq_len * input_size
data, label, seq_len = self.train_data[idx]
# pad_data: max_seq_len * input_size
pad_data = np.zeros(shape=(self.max_seq_len, data.shape[1]))
pad_data[0:data.shape[0]] = data
sample = {'data': pad_data, 'label': label, 'seq_len': seq_len}
return sample这样,你从外部拿到的 batch 数据就是一个 [batch_size x max_seq_len x input_size] 的 tensor
搭建网络
在PyTorch中可以使用下面两种方式去调用,分别是torch.nn.RNNCell()和torch.nn.RNN(),这两种方式的区别在于RNNCell()只能接受序列中单步的输入,且必须传入隐藏状态,而RNN()可以接受一个序列的输入,默认会传入全0的隐藏状态,也可以自己申明隐藏状态传入。
torch.nn.RNN()
import torch
from torch.autograd import Variable
from torch import nn
# 首先建立一个简单的循环神经网络:输入维度为20, 输出维度是50, 两层的单向网络
basic_rnn = nn.RNN(input_size=20, hidden_size=50, num_layers=2)
"""
通过 weight_ih_l0 来访问第一层中的 w_{ih},因为输入 x_{t}是20维,输出是50维,所以w_{ih}是一个50*20维的向量,另外要访问第
二层网络可以使用 weight_ih_l1.对于 w_{hh},可以用 weight_hh_l0来访问,而 b_{ih}则可以通过 bias_ih_l0来访问。当然可以对它
进行自定义的初始化,只需要记得它们是 Variable,取出它们的data,对它进行自定的初始化即可。
"""
print(basic_rnn.weight_ih_l0.size(), basic_rnn.weight_ih_l1.size(), basic_rnn.weight_hh_l0.size())
# 随机初始化输入和隐藏状态
toy_input = Variable(torch.randn(3, 1, 20))
h_0 = Variable(torch.randn(2*1, 1, 50))
print(toy_input[0].size())
# 将输入和隐藏状态传入网络,得到输出和更新之后的隐藏状态,输出维度是(100, 32, 20)。
toy_output, h_n = basic_rnn(toy_input, h_0)
print(toy_output[-1])
print(h_n)
print(h_n[1])torch.nn.RNN()
RNNCell()只能接受序列中单步的输入,且必须传入隐藏状态
# 定义一个单步的rnn
rnn_single = nn.RNNCell(input_size=100, hidden_size=200)
# 访问其中的参数
print(rnn_single.weight_hh.size())
# 构造一个序列,长为6,batch是5,特征是100
x = Variable(torch.randn(6, 5, 100))
# 定义初始的记忆状态
h_t = Variable(torch.zeros(5, 200))
# 传入 rnn
out = []
for i in range(6): # 通过循环6次作用在整个序列上
h_t = rnn_single(x[i], h_t)
out.append(h_t)