信号机制
在linux操作系统中,为了响应各种各样的事件,也定义了很多信号。我们可以通过kill -l命令,查看所有的信号
# kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
60多种。其中常见的信号有
1: HUP,终端退出进程终止,可以被捕获
2: INT,就是crtl+c ,终止前台进程;
8 : FPE,算术运算出错,溢出,除0等;
9:9 KILL,强行终止进程,不能被阻塞,捕获,忽略的。
15: TERM,进程正常终止,通常捕获它,处理善后比如释放资源再退出;kill默认就是15
19 SIGSTOP 该信号可以暂停前台进程,相当于输入 Ctrl+Z 快捷键
(9,15都是不能阻塞,捕获,忽略的)
20 SIGSTP 也是暂停进程,但是可以被阻塞,捕获,忽略的
14 ALARM时钟信号,用于alarm()函数设置多久收到信号,然后设置处理函数处理。
17 CHILD信号:防止产生僵尸进程。子进程退出给父进程发送CHILD信号,可以给这个信号设置处理函数异步waitpid,不用等待。其实默认是忽略,不用处理,直接释放资源就可以。
对于信号处理有三种方式
第一是默认的:如果是term,默认就是关闭,比如core默认就是关闭后写core文件方便事后分析原因。
捕捉信号:写一个信号处理函数处理 signal(ID,信号处理函数)
忽略信号:比如sigchild
(kill和stop是没有办法捕捉和忽略和阻塞的)
**

信号的处理流程
**
主要包括注册信号和发送信号。
如果我们不想让某个信号执行默认操作,一种方法是通过signal函数对特定的信号注册相应的信号处理函数。
sighandler_t signal(int signum, sighandler_t handler);
实际上,signal不是一个系统调用,而是一个gilbc函数。(和malloc和brk,mmap关系一样)
实际上系统调用是sigaction.其实它还是将信号和一个动作进行关联,只不过这个动作由一个结构struct sigaction表示了。
struct sigaction {
__sighandler_t sa_handler;
unsigned long sa_flags;
__sigrestore_t sa_restorer;
sigset_t sa_mask; /* mask last for extensibility */
};
其他成员变量可以让你更加细致地控制信号处理的行为。而 signal 函数没有给你机会设置这些。
比如sa_flags 进行了默认的设置
SA_ONESHOT是什么意思呢?意思就是,这里设置的信号处理函数,仅仅起作用一次。我们并不希望这么做,肯定希望它一直起作用,直到我显式地关闭它。
SA_NOMASK表示在这个信号处理函数执行过程中,如果再有其他信号,哪怕相同的信号到来的时候,这个信号处理函数会被中断。要操作某个数据结构,因为是相同的信号,很可能操作的是同一个实例,这样的话,死锁、同步这些都要想好。所以最好要屏蔽其他信号
SA_RESTART,系统调用时信号到来,这个时候系统调用会被自动重新启动,不需要调用方自己写代码。比如读字符时中断,然后再次读入一个字符的时候,如果用户不再输入,就停在那里了,需要用户再次输入同一个字符。
所以建议你使用 sigaction 函数,根据自己的需要定制参数。
在内核中,rt_sigaction 调用的是 do_sigaction 设置信号处理函数。在每一个进程的 task_struct 里面,都有一个 sighand 指向 struct sighand_struct,里面是一个数组,下标是信号,里面的内容是信号处理函数。(这里又联系到进程内存空间了,里面就有信号相关的处理函数,系统调用是在内核空间的)
(总结一下,系统调用的代码是在内核空间的具体是前1MB地方,中断时根找到该代码,信号中断时处理函数是在进程的内核态空间,具体是task_struct的信号结构部分。共同的是都会陷入内核态)
(软中断有信号(异常),系统调用,这些都在内核初始化trap_init()注册好了,中断处理过程是保护现场(保存在内核态的ptg结构)—执行系统调用或者中断处理函数–恢复
硬中断就是IO产生的中断,复杂一点,中间有中断信号–中断向量–全局中断向量—找到中断处理程序(驱动的))
信号的发送
有时候,我们在终端输入某些组合键的时候,会给进程发送信号,例如,Ctrl+C 产生 SIGINT 信号,Ctrl+Z 产生 SIGSTOP 信号。
有的时候,硬件异常也会产生信号。比如,执行了除以0的指令,CPU就会产生异常,然后把SIGFPE发送给进程。比如,进程访问了非法内存,内存管理模块就会产生异常,然后把SIGSEGV发送给进程。
最直接的发送信号的方法就是,通过命令 kill 来发送信号了。例如,我们都知道的 kill -9 pid 可以发送信号给一个进程,杀死它。也可以通过 tkill 或者 发送信号给某个线程,最终都是调用了 do_send_sig_info 函数。这个函数重要的是sigpending结构
struct sigpending 里面有两个成员,一个是一个集合sigset_t,表示都收到了哪些信号,还有一个链表,也表示收到了哪些信号。它的结构如下:
struct sigpending {
struct list_head list;
sigset_t signal;
};
小于32的信号,都会放在集合里,这是不可靠的。比如总共 5 个 SIGUSR1,分别是 A、B、C、D、E。
如果这五个信号来得太密。A 来了,但是信号处理函数还没来得及处理,B、C、D、E 就都来了。根据上面的逻辑,因为 A 已经将 SIGUSR1 放在 sigset_t 集合中了,因而后面四个都要丢失。 如果是另一种情况,A 来了已经被信号处理函数处理了,内核在调用信号处理函数之前,我们会将集合中的标志位清除,这个时候 B 再来,B 还是会进入集合,还是会被处理,也就不会丢。
大于32的信号会挂载链表上,这是可靠信号。
信号处理的时机
当kill发送的信号挂到了task_struct结构之后,最后我们需要调用complete_signal。我们要调用signal_wake_up,来企图唤醒它。
signal_wake_up_state里面主要做了两件事情。第一,就是给这个线程设置TIF_SIGPENDING,这就说明其实信号的处理和进程的调度是采用一种类型的机制。
当一个进程应该被调用的时候,我们并不直接把它赶下来,而是设置一个标识位TIF_NEED_RESCHED,表示等待调度,然后等待系统调用结束或者中断处理结束,从内核态返回用户态的时候,调用schedule函数进行调度。
信号也是类似的,当信号来的时候,我们并不直接处理这个信号,而是设置一个标识位TIF_SIGPENDING,来表示已经有信号在等待处理。同样,等系统调用结束,或者中断处理结束,从内核态返回用户态的时候,再进行信号的处理。
总结一下:
用sianal,siaaction注册信号信号,会放在进程的task_struct的信号数组中;
当用kill或者其他方式发送信号时,实际上调用send_sig_info。 这里面有很重要的结构体sigpending。发送信号实际上就是把信号挂到进程task_struct的sigpending结构体上,并且对于小于32挂载集合,不可靠会丢失,大于32挂载链表可靠。
然后处理信号的时机。如果进程正在运行,就直接执行信号处理函数。
但是进程可能在执行系统调用或者硬件中断(并且在可中断的睡眠状态比如等待IO),这种情况的话,信号处理和进程调度是一种机制。会先给一个抢占标识或者是信号处理标识,然后尝试唤醒进程,进程发现信号,就会中断返回,也就是系统调用被信号打断了。返回的时候就是处理信号的时机,进入用户态把信号处理函数复制到用户态执行。执行完返回到原来的位置。
(当然,系统调用或者硬件中断被信号打断后,要执行的操作可以是用户自定义的,可以不采取操作,或者重新系统调用都可以)
并且,如果是不可中断的睡眠状态,那么在系统调用睡眠时,信号是不能唤醒的。没办法终止了,kill -9也不行。它主要用于一些内核不可中断的过程,保证原子性?类似,就比如读字符设备时如果发生中断,就会造成设备不可控的状态,所以要设置为不可中断。
匿名管道的原理
管道的创建,需要通过下面这个函数
int pipe(int fd[2])
在这里,我们创建了一个管道pipe,返回了两个文件描述符,这表示管道的两端,一个是管道的读取描述符fd[0],另一个是管道的写入描述符fd[1]
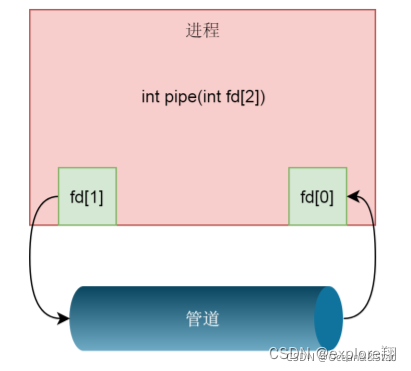
这个函数其实是调用了系统调用pipe2 。这个函数主要原理,先创建管道文件。也是创建在文件系统上的,只不过是一种特殊的文件系统,创建一个特殊的文件,对应一个特殊的inode,文件有自己的struct(包含inode,实际的数据,对应的文件操作),里面包含了特殊的inode,指向的不是磁盘,而是内存的内核缓冲区。再调用fd_install,将两个fd和两个struct file关联起来。
这里的文件其实就是一个管道文件,也就是fd1以读的方式打开文件fd2以写的方式打开文件。
这个时候还是一个进程,所以需要fork子进程,这样子进程会复制父进程的struct file_struct,这里面fd的数组会复制一份,但是fd指向的struct file对于同一个文件还是只有一份(因为是一个管道文件)。然后父进程关闭读取的 fd,只保留写入的 fd,而子进程关闭写入的 fd,只保留读取的 fd,如果需要双向通行,则应该创建两个管道。
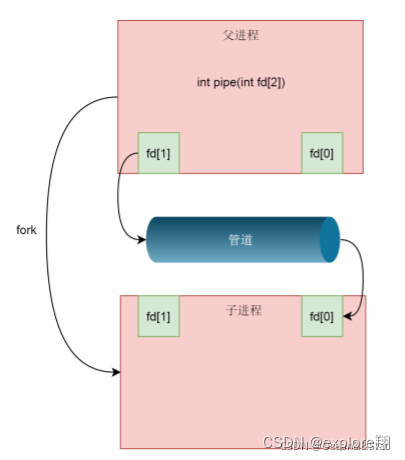
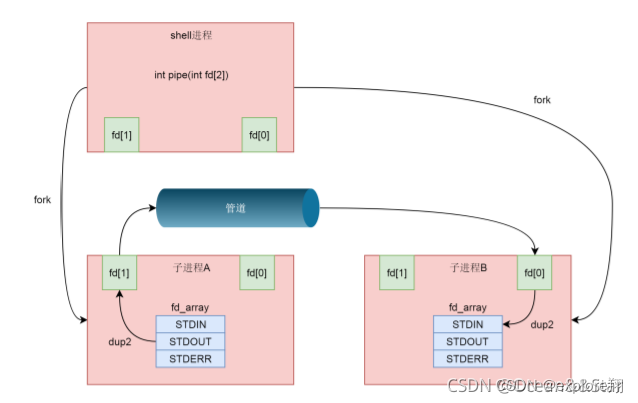
但是我们在 shell 里面的不是这样的。在 shell 里面运行 A|B 的时候,A 进程和 B 进程都是 shell 创建出来的子进程,A 和 B 之间不存在父子关系。
所以还用到了dup2(int oldfd, int newfd);将老的文件描述符赋值给新的文件描述符,让newfd的值和oldfd一样。
fd数组中,前三项是定下来的,其中第零项 STDIN_FILENO 表示标准输入,第一项 STDOUT_FILENO 表示标准输出,第三项 STDERR_FILENO 表示错误输出。dup2(fd[1], STDOUT_FILENO),将STDOUT_FILENO(就是第一项)不再指向标准输出,而是执行场景的管道文件,那么以后往标准输出里面写入的任何东西,都会写入管道文件。读取端亦然。
命名管道
主要解决没有亲缘关系的两个进程想要通信的问题。
Glibc 的 mkfifo 函数会调用 mknodat 系统调用(命名管道也是一个设备,因此也用mknod)
会在 ext4 文件系统上真的创建一个文件,但是会调用 init_special_inode,创建一个内存中特殊的 inode,有一个管道的文件结构,存储inode,实体(内核的缓冲区)、对应操作。
总结:
匿名和命名其实都是内核的内存缓冲区空间。管道,设备都是文件,在用户来看访问接口是一致的,区别是他inode是特殊的,根据这个不同,就可以对应到不同的文件结构(包含对应操作,inode,文件实体),实现不同的操作,比如读文件就是文件的read,
读设备就要从设备read其实读的是驱动程序,读管道就是从内核缓冲区read。我们不关心。
为什么要有管道?
为什么不直接用磁盘上的普通文件作为通信的地方?
缺点:1:没有访问控制。父进程写入很慢或者关闭,子进程不会终止,会返回0,导致子进程无法回收,内存泄漏;
2、明显,磁盘文件访问慢一点;
而管道是内存文件,有访问控制,速度太慢太快都会阻塞。一方关闭就会另一方停止。
总和一下:操作系统怎么通过统一的open操作各种类型的文件的(普通文件,目录,设备,管道)?
进程会有fd数组,其中有文件名字,创建文件时操作系统会创建dentry,里面是名字和inode结构体的映射,只不过不同类型的文件inode不一样(inode里面有文件类型,属主,修改时间等等信息以及存放位置)。当open时,根据inode不同。会创建不同各类型文件的结构体file_struct,里面记录了不同文件的相关操作(比如open操作,read,write)
(fd-inode-file_struct)
IPC共享内存
有了共享内存机制之后,两个进程就可以像访问自己内存中的变量一样,访问共享内存的变量。但是同时问题也来了,当两个进程共享内存了,就会存在同时读写问题,这就需要对共享内存进行保护,这需要信号量这样的同步机制
int shmget(key_t key, size_t size, int shmflag);
key就是前面生成的那个key
shmflag如果为IPC_CREAT,就表示新创建,还可以指定读写权限0777。
对于共享内存,需要指定一个大小size,这个一般要申请多大呢?一个最佳实践是,我们将多个进程需要共享的数据放在一个struct里面,然后这里的size就应该是这个struct的大小。这样每一个进程得到这块内存后,只要强制将类型转换为这个struct类型,就能够访问里面的共享数据了
生成了共享内存之后,接下来就是将这个共享内存映射到进程的虚拟地址空间中:
void *shmat(int shm_id, const void *addr, int shmflg);
这里面的shm_id,就是上面创建的共享内存的id,addr就是指定映射在某个地方。如果不指定,则内核会自动选择一个地址,作为返回值返回。得到了返回地址以后,我们需要将指针强制类型转换为struct shm_data结构,就可以使用这个指针设置的data和datalength了。
当共享内存使用完毕,我们可以通弄过shmdt解除它到虚拟内存的映射
int shmdt(const void *shmaddr);
信号量
我们需要创建一个信号量集合,同样也是使用 xxxget 来创建:信号量需要通过semctl初始化为某个值
int semget(key_t key, int nsems, int semflg);
信号量往往代表某种资源的数量,如果用信号量做互斥,那往往将信号量设置为1。对于信号量,往往要定义两种操作,P 操作和 V 操作。我们可以用这个信号量,来保护共享内存中的struct shm_data,使得同时只有一个进程可以操作这个结构。
具体内核机制就不说了。
网络系统socket
前面的通信都是一台机器上的不同进程通信,不同机器的进程通信就要用到socket.
这一部分的基础知识要很好掌握,网络通信很重要。
基础知识:

socket 编程需要基于一个文件描述符,即 socket 文件描述符。socket(2) 系统调用就是用来创建 socket 文件描述符。
int socket(int domain, int type, int protocol);
第一个参数主要是什么协议UNIX,IPV4,IPV6,第二个是套接字的类型(字节流和数据包,对于TCP,UDP),protocol: 一般设置为0。 发生错误返回-1,否则返回socket文件描述符。
bind
通过 socket 系统调用创建的文件描述符并不能直接使用,TCP/UDP协议中所涉及的协议、IP、端口等基本要素并未体现,而 bind(2) 系统调用就是将这些要素与文件描述符关联起来。
函数如下:
#include <sys/socket.h>
int bind(int socket, const struct sockaddr *address, socklen_t address_len);第二个参数为协议、IP、端口等要素分别定义了字段。address_len: 协议地址结构体长度。
如果绑定的地址错误,或者端口已被占用,bind 函数一定会报错,否则一般不会返回错误。
listen
这个函数会稍微复杂一点。
使用 socket 系统调用创建一个套接字时,它被假设是一个主动套接字(客户端套接字),而调用 listen(2) 系统调用就是将这个主动套接字转换成被动套接字,指示内核应接受指向该套接字的连接请求。
listen 还有项重要使命,就是创建未完成连接队列(半连接队列)和已完成连接队列(全连接队列)。内核为每一个监听套接字都维护着这两个队列,未完成三次握手的连接暂时存放在未完成队列,已完成三次握手并且服务端还未调用 accept 系统调用处理的连接均存放在已完成连接队列。
函数原型如下:
#include <sys/socket.h>
int listen(int socket, int backlog);
对于存在高并发场景的服务端程序,应该将 backlog 适当调大(Nginx和Redis的默认backlog值为511)。 backlog 实际就是全连接队列的大小,代表完成三次握手但是还没有被accept,一旦超过阈值,就会丢弃客户端的syn请求。实际上全连接大小由min(backlog, somaxconn)决定。
内核解析:
1、在 listen 中,我们还是通过 sockfd_lookup_light,根据 fd 文件描述符,找到 struct socket 结构。接着,我们调用 struct socket 结构里面 ops 的 listen 函数。(这里其实体现了万物皆文件的操作,也是通过fd找到相应的inode,只不过它在内核的内存中不在磁盘上,通过inode找到文件的相关信息以及位置,打开fd会有相应的文件结构记录相应操作)
/2、如果这个socket还不在TCP_LISTEN状态,会调用inet_csk_listen_start进入监听状态。
3、主动套接字转换成被动套接字其实就对应 struct inet_connection_sock *icsk = inet_csk(sk); 其实做了一次强制类型转换。struct inet_connection_sock结构比较复杂。如果打开它,你能看到处于各种状态的队列,各种超时时间、拥塞控制等字眼。我们说TCP是面向连接的,就是客户端和服务端都是有一个结构维护连接的状态,就是指这个结构。
4、 reqsk_queue_alloc(&icsk->icsk_accept_queue);也就是分配全连接队列。
accept
accept(2) 系统调用将尝试从已完成连接队列的队头中取出一个连接进行服务,因此产生的队列空缺将从未完成连接队列中取出一个进行补充。若此时已完成连接队列为空,且 socket 文件描述符为默认的阻塞模式,那么进程将被挂起。
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
socket: socket 监听文件描述符。
addr: 已连接的对端进程的协议地址。若不关注对端信息,可设置为NULL。
addrlen: 地址结构体长度的指针。addr 参数设置为 NULL 时,可设置为 NULL 。
返回值:出错返回-1,否则返回已连接套接字文件描述符。
内核分析:
1、都是一样的,通过 sockfd_lookup_light,根据 fd 文件描述符,找到 struct socket 结构。
2、newsock = sock_alloc();并基于它去创建一个新的newsock。这才是连接socket
3、如果 icsk_accept_queue 为空,则调用 inet_csk_wait_for_connect 进行等待;等待的时候,调用 schedule_timeout,让出 CPU,并且将进程状态设置为 TASK_INTERRUPTIBLE。可中断的睡眠状态,可以被信号唤醒
如果再次 CPU 醒来,我们会接着判断 icsk_accept_queue 是否为空,同时也会调用 signal_pending 看有没有信号可以处理。一旦 icsk_accept_queue 不为空,就从 inet_csk_wait_for_connect 中返回,在队列中取出一个 struct sock 对象赋值给 newsk。
connect(实现三次握手)
创建主动套接字的一方(客户端)调用 connect(2) 系统调用,可建立与被动套接字的一方(服务端)的连接。
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
其中,第一个参数就是accept建立的连接fd,addr是服务器的ip+port
三次握手一般是由客户端调用connect发起: 完成会就会进入全连接队列了
1、步骤都一样,根据fd,找到struct socket 结构,找到对应的conncet操作。
2、如果发现socket处于SS_UNCONNECTED 状态,就会tcp_v4_connect 函数。主要是做一个路由的选择。(因为客户端没有Bind,所以会自动选一个网卡和端口。)发送SYN之前,我们先将客户端socket的状态设置为TCP_SYN_SENT,然后初始化TCP的ISN初始化序列号,然后调用tcp_connect进行发送;
在 tcp_connect 中,有一个新的结构 struct tcp_sock,如果打开他,你会发现他是 struct inet_connection_sock 的一个扩展,struct inet_connection_sock 在 struct tcp_sock 开头的位置**,通过强制类型转换访问,故伎重演又一次**。struct tcp_sock 里面维护了更多的 TCP 的状态
3、inet_wait_for_connect 会一直等待客户端收到服务端的ACK。而我们知道,服务端再accept之后,也是在等待中。服务端收到syn,通过tcp_v4_send_synack。具体发送的过程我们不去管它,看注释我们能知道,这是收到了SYN后,回复一个SYN-ACK,回复完毕之后,服务端处于TCP_SYN_RECV
4、会调用 tcp_send_ack,发送一个ACK-ACK,发送后客户端处于 TCP_ESTABLISHED 状态。服务端收到后也会处于ESTABLISHED
Socket 系统调用会有三级参数 family、type、protocal,通过这三级参数,分别在 net_proto_family 表中找到 type 链表,在 type 链表中找到 protocal 对应的操作。这个操作分为两层,对于 TCP 协议来讲,第一层是 inet_stream_ops 层,第二层是 tcp_prot 层。
发送数据包write
ssize_t write(int fd, const void*buf,size_t nbytes);
write函数将buf中的nbytes字节内容写入文件描述符fd.成功时返回写的字节数.失败时返回-1. 并设置errno变量
涉及到从VFS层到IP层再到MAC层是如何发送网络包的 解析socket的write操作
1.第一步是统一的。通过fd找到对应的struct file结构,write系统调用会最终调用struct file结构指向的file_operations操作:sock_write_iter;这里根据两个层级分别是ip协议层级以及TCP/UDP层级,最终调用的是 tcp_sendmsg
VFS-Socket
2、tcp_sendmsg 的实现还是很复杂的,这里面做了这样几件事情。第一就是把数据从用户态拷贝到内核的缓冲区中;第二就是发送这些数据。
拷贝到内核就是一个循环,声明一个copid,在循环的最后有copied += copy,将每次拷贝的数量都加起来。一次循环中做的事有:
计算MSS(MTU-TCP头部-IP头部),如果copy小于0,说明最后一个struct sk_buff已经没地方可以存放了,需要调用sk_stream_alloc_skb,重新分配struct sk_buff,然后调用skb_entail,将新分配的sk_buff放到队列尾部(其中还有一些优化的数据结构)
3、要发送网络包。无论 __tcp_push_pending_frames 还是 tcp_push_one,都会调用 tcp_write_xmit 发送网络包。这里面主要的逻辑是一个循环,用来处理发送队列,只要队列不空,就会发送。
在一个循环中,涉及 TCP 层的很多传输算法(包括分段,拥塞控制,流量控制等),在一个循环的最后,是调用tcp_transmit_skb,真正去发送一个网络包。要做了两件事情,第一件事情就填充TCP头,全部设置完毕之后,就会调用 ip_queue_xmit 函数发送。
4、从IP层到MAC层
ip_queue_xmit有三部分逻辑。
第一部分,选取路由,也就是我要发送的这个包应该从哪个网卡出去。fib_table_lookup函数在这个表里面进行查找。按照前缀进行查询,希望找到最长匹配的那一个,比如192.168.2.0/24 和 192.168.0.0/16 都能匹配 192.168.2.100/24。但是,我们应该使用 192.168.2.0/24 的这一条。为了更加方便的做这个事情,我们使用了trie树这种结构.将IP地址转成二进制放入trie树
2 第二部分,就是准备IP层的头,往里面填充内容。
3 第三部分,就是调用ip_local_out 发送IP包,其中有nf_hook。在 IP 层还要做的一件事情就是通过 iptables 规则
(nf_hook。这是什么呢?nf的意思是Netfilter,这是Linux内核的一个机制,用于在网络发送和转发的关键节点加上hook函数,这些函数可以截获数据包,对数据包进行干预。一个著名的实现,就是内核模块ip_tables。在用户态,还有一个客户端程序iptables,用命令行来干预内核的规则。
iptable主要有两个表,每个表有几条链。总结来说就是如果iptable有某些规则,就会进行过滤或者说改变ip地址
filter 表处理过滤功能,主要包含以下三个链。INPUT 链:过滤所有目标地址是本机的数据包;FORWARD 链:过滤所有路过本机的数据包;OUTPUT 链:过滤所有由本机产生的数据包
nat 表主要处理网络地址转换,可以进行 SNAT(改变源地址)、DNAT(改变目标地址),包含以下三个链。PREROUTING 链:可以在数据包到达时改变目标地址;OUTPUT 链:可以改变本地产生的数据包的目标地址;POSTROUTING 链:在数据包离开时改变数据包的源地址
write来说,会经过output和POSTROUTING 链。然后调用 ip_finish_output。进入MAC层。
4.MAC层要做的事就是ARP协议。MAC 层需要 ARP 获得 MAC 地址,因而要调用 ___neigh_lookup_noref 查找属于同一个网段的邻居,他会调用 neigh_probe 发送 ARP。有了 MAC 地址,就可以调用 dev_queue_xmit 发送二层网络包了,它会调用 __dev_xmit_skb 会将请求放入队列。网络包的发送会触发一个软中断 ,从队列拿到数据放到硬件网卡的发送队列中。
总结一下一共几个层
VFS-SOCKET层:就是通过fd找到对应的文件结构,调用相应的write操作tcp_sendmsg。其中包含了两个层次;
到了TCP层之后,要做的第一就是把数据从用户态拷贝到内核的缓冲区中;第二就是发送这些数据。这一层涉及到了TCP连接的一些特性,比如MSS,拥塞控制,流量控制,TCP头部填充等。调用ip_queue_xmit函数发送进入ip层
到了IP层之后,主要做三件事,第一就是选取路由,从哪个网卡发出去,使用了trie树这种结构.将IP地址转成二进制放入trie树更快匹配; 第二就是准备IP层的头部信息;第三就是通过 iptables 规则;然后调用 ip_finish_output。进入MAC层。
到了MAC,主要做的就是ARP找到MAC地址,找到后放入请求队列, 会触发一个软中断,网卡会来取这些数据发送。
read函数解析(其实是一个相反的过程)
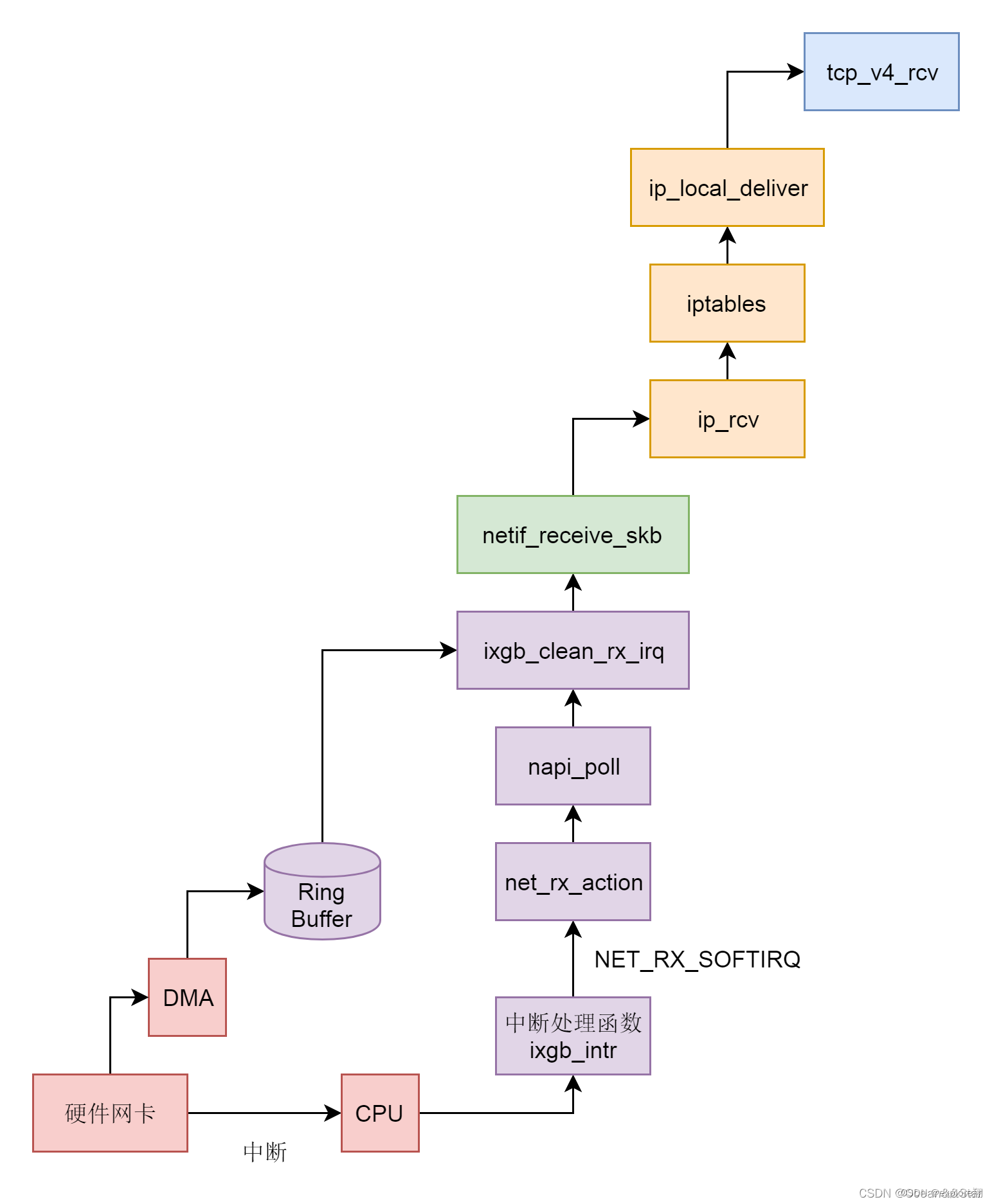
过程大致是:
1、硬件网卡接收到网络包之后。DMA技术放到环形缓冲区,再通过NAPI的方式(因为数据到达时间不定,如果普通中断处理,可能刚处理完回去又来低效。所以NAPI就是有中断,就poll一直到没有数据了,再回去)数据放到缓冲区,再通知CPU,从Ring Buffer中读取数据到内核struct sk_buff。
2、调用 netif_receive_skb 进入内核网络协议栈,进行一些关于 VLAN 的二层逻辑处理后,调用 ip_rcv 进入三层 IP 层。
3、在 IP 层,会处理 iptables 规则,然后调用 ip_local_deliver,交给更上层 TCP 层。在 TCP 层调用 tcp_v4_rcv。
4、TCP层主要处理几个队列。如果当前的 Socket 不是正在被读;取,则放入 backlog 队列,如果正在被读取,不需要很实时的话,则放入 prequeue 队列,其他情况调用 tcp_v4_do_rcv;如果序列号能够接的上,则放入 sk_receive_queue 队列;如果序列号接不上,则暂时放入 out_of_order_queue 队列,等序列号能够接上的时候,再放入 sk_receive_queue 队列。(这也是为什么http2还是有队头阻塞的问题,只不过在TCP层了,必须序号接得上,才会进入接收队列)
至此内核接收网络包的过程到此结束,接下来就是用户态读取网络包的过程,这个过程分成几个层次。
VFS 层:read 系统调用找到 struct file,根据里面的 file_operations 的定义,调用 sock_read_iter 函数。sock_read_iter 函数调用 sock_recvmsg 函数。然后经过两个层级inet和TCP,调用真正的读取函数 tcp_recvmsg 函数。tcp_recvmsg 函数会依次读取 receive_queue 队列、prequeue 队列和 backlog 队列。