一、服务端Hadoop2.8.2的配置修改
首先,你需要对Linux下的Hadoop2.8.2进行一些小修改,让虚拟机IP下的hdfs协议的9000与9001端口顺利发布出去。
如果是虚拟机,连通虚拟机与主机。
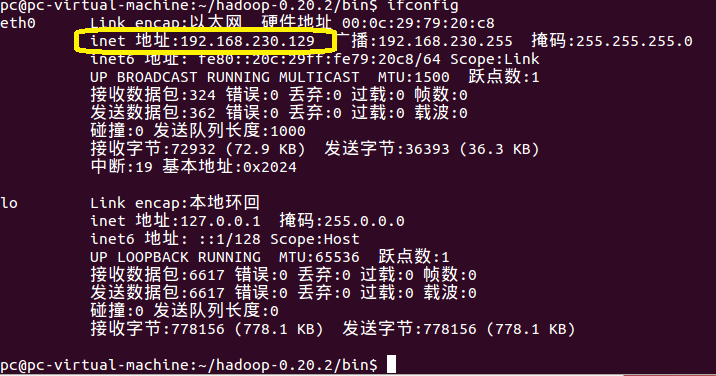
之后,在虚拟机或者远程服务器中通过如下的命令,查出当前虚拟机或服务器所在的内网IP,
- -ifconfig
比如此处,我的Linux所在的内网IP是:192.168.230.129
之后在hadoop的关闭状态,对如下图的一些有关hadoop配置的文件进行修改:
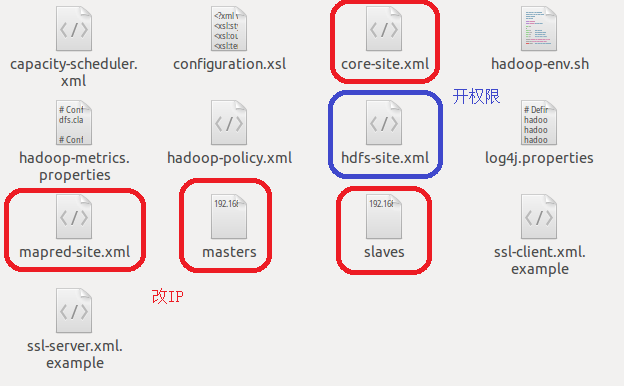
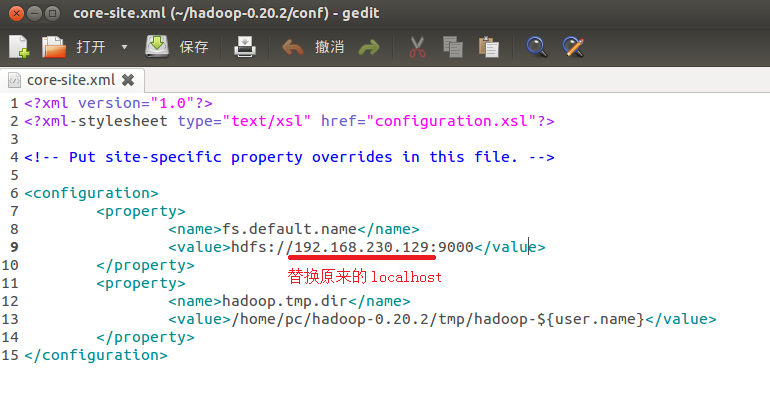
一是core-site.xml、mapred-site.xml、masters与slaves这些文件中的localhost通通替换成刚才用ifconfig命令查询出来的IP地址。比如我这里是192.168.230.129。我们不玩单机了,这次真的需要将整个Hadoop发布出去。
二是对hdfs-site.xml这个文件进行修改,为里面加一条关于关闭权限认证dfs.permissions的值为false属性。不然一会儿在Windows下的Eclipse,也就是客户端的东西,无法对服务器的东西进行读取,造成org.apache.hadoop.security.AccessControlException: Permission denied的问题。
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!-- Put site-specific property overrides in this file. -->
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.permissions</name>
- <value>false</value>
- </property>
- </configuration>
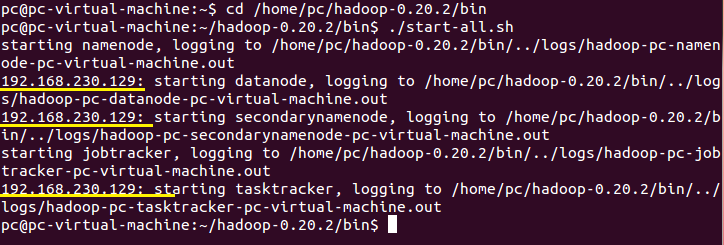
- ./start-all.sh
开启Hadoop服务器,这似乎与Hadoop是单机模式、伪分布模式、完全模式没有半点关系,也就是与hdfs-site.xml中dfs.replication设置为哪个值没有关系。
在开始Hadoop服务器的过程中,你很明显地发现,原本localhost的地方,变更为192.168.230.129。
当然在Windows下打开一个IE,输入http://192.168.230.129:50070,还是能够访问关于Hadoop与Mapreduce情况的网页的。
二、Cgywin的安装、配置
可能来到这一步有人会与我当初一样疑惑,我们不是有VMWare作为虚拟机,在上面的Ubuntu配置Hadoop0.20.2了吗?还需要另一个在Windows下虚拟Linux环境干嘛?
其实,这里的Cgywin的安装主要是因为在Windows下的Eclipse进行Hadoop编程同样需要在命令行,执行一些关于操作系统操作的命令。Hadoop0.20.2是在Linux环境下写出来的,有关上传、下载、创建文件夹等之类操作,Hadoop0.20.2是用Linux的shell命令行去写的。
你要清楚我们的Java程序是在Windows下的Eclipse跑的,如果在Windows下的命令行执行一些Linux命令自然是不行的。会报
WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
Exception in thread "main" java.io.IOException: Cannot run program "chmod": CreateProcess error=2,
这样的错误!
因此,这里的Cgywin是让Windows命令行能够执行一些Linux,如下图所示:
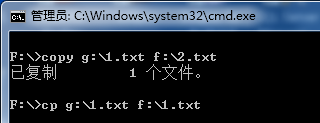
装了Cgywin之后,能够在命令行中,同时是有windows原有的copy与Linux的cp复制文件。
同时引一段Cgywin中文官网(点击打开链接)上的说明:
当然于我们来说,主要是让Hadoop0.20.2程序能够在Windows下的Eclipse跑起来。有些资料十分坑爹,个人认为此乃Hadoop0.20.2能够在Windows下跑起来关键的一步,只字不提。这也说明Hadoop0.20.2并不跨平台!Hadoop希望我们直接在Linux下编译、调试程序,简直晕死。
好,回到正题,Cgywin的安装其实非常脑残的,上其官网https://www.cygwin.com/选择适合自己系统位数的版本下载:
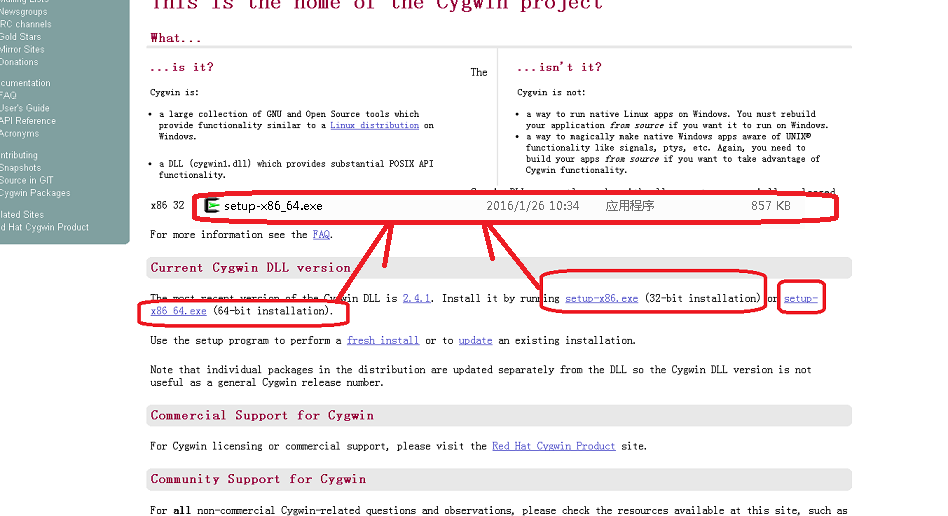
下载之后打开这个安装文件,Cygwin也是非常坑定的货,只提供一下在线安装的下载器,整得像某些垃圾软件一样。
然后直接下一步就可以了。唯一需要注意的是,安装路径不能有空格,中文没测试过,最好也没有的。关键是没有空格。安装的过程中,问你要装什么组件,不用想直接点确定就可以了。
安装好Cgywin之后,将其安装路径里面的bin文件夹中添加的系统环境变量的path中。
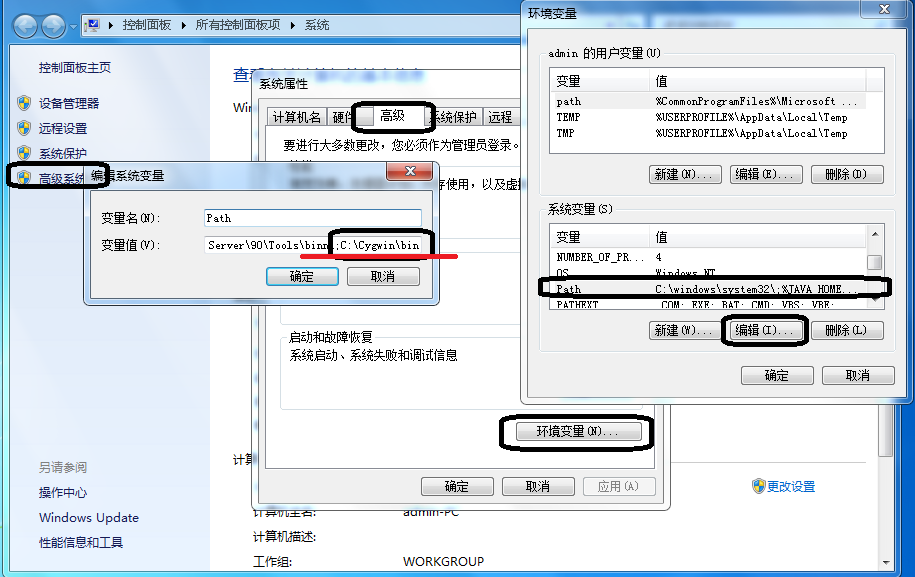
然后你可以在命令行,测试一样能够用linux下的cp文件复制文件吧。
三、Eclipse的准备,Hadoop组件的安装
1、将hadoop-2.8.2.tar.gz解压到一个无空格的目录,这也是hadoop在Windows的安装文件夹,是全路径没有空格的。
并下载hadoop-common-2.7.1-bin-master.jar包,将压缩包里面的东西复制到本机hadoop的安装路径bin目录下,
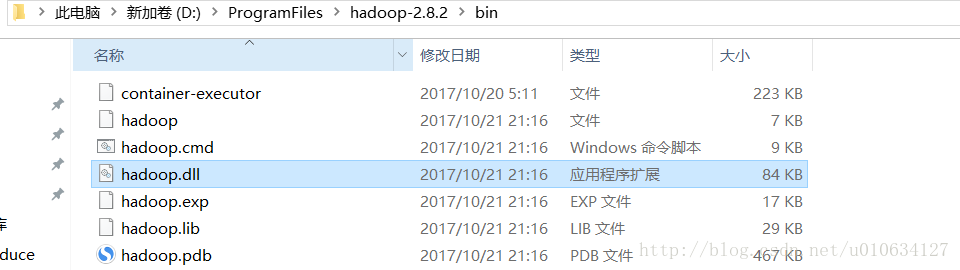
并将hadoop.dll文件放到C:\Windows\System32路径下。
3、所有Eclipse都是绿色的,直接解压之后,将刚刚hadoop-2.8.2.tar.gz解压之后的文件夹下的contrib下的eclipse-plugin下的hadoop-0.20.2-eclipse-plugin.jar,扔到Eclipse中的plugins文件夹,再打开Eclipse。
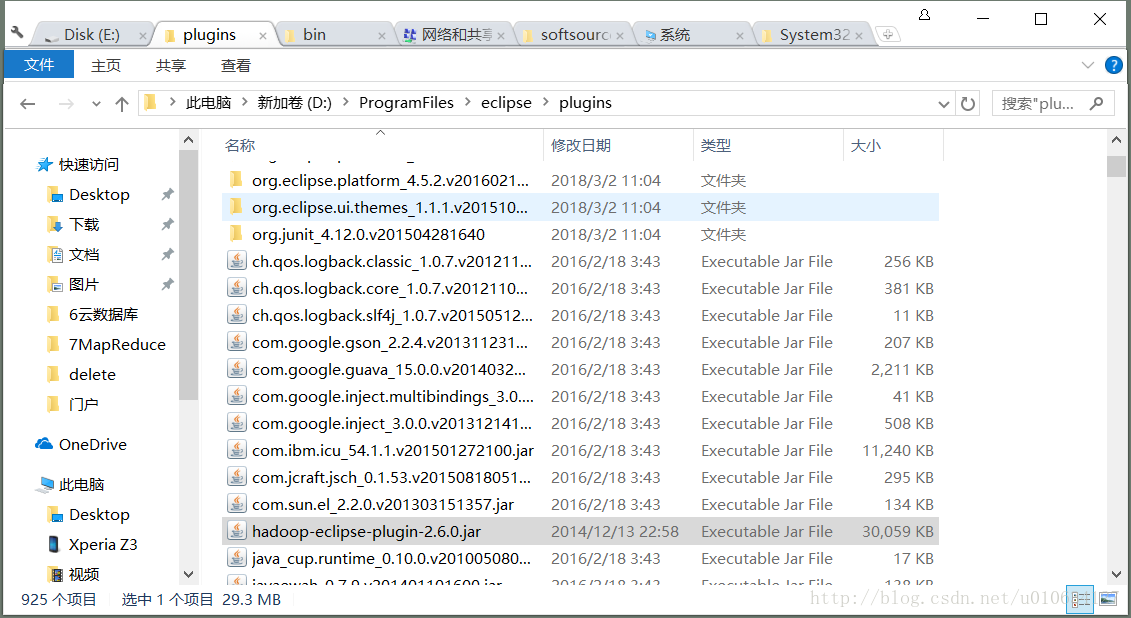
4.打开之后,先将Hadoop的安装目录配置进来,打开Eclipse的属性窗口,找到刚刚hadoop-2.8.2.tar.gz的解压路径,这里面包含一些必须的包,
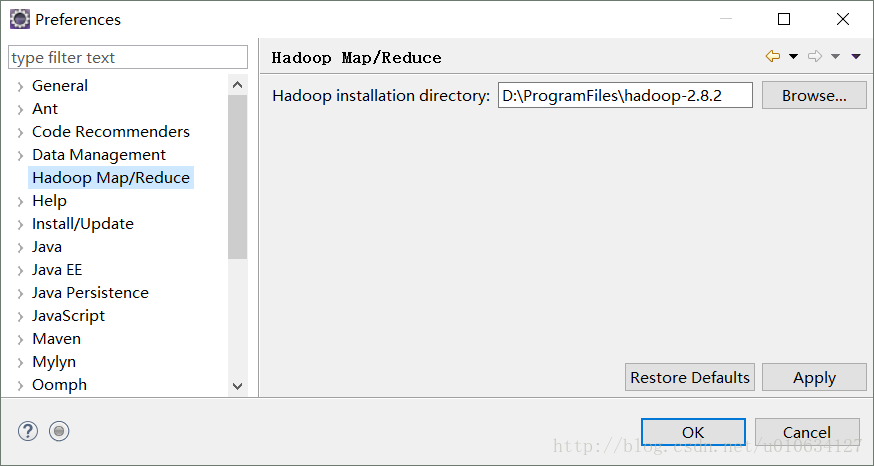
设置好Eclipse的默认编码为UTF-8,同时检查一下此时Eclipse所用的JDK是否大于1.6。
5、点击右上角的Map/Reduce视图。没有的话,在菜单栏中Window->Open Perspective->Other中打开这个Map/Reduce视图。
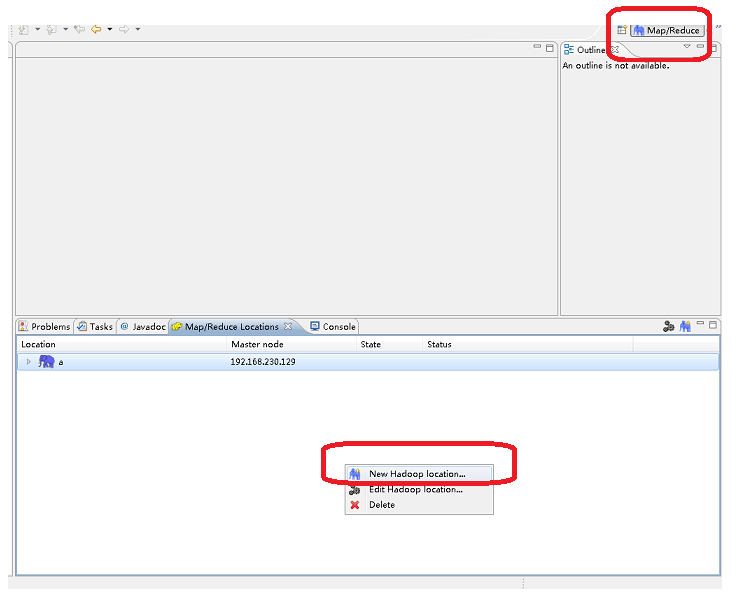
在旗下的Map/Reduce Location的空白地方新建一个Hadoop服务器,就像你搞JSP新建一个Tomcat服务器一样。
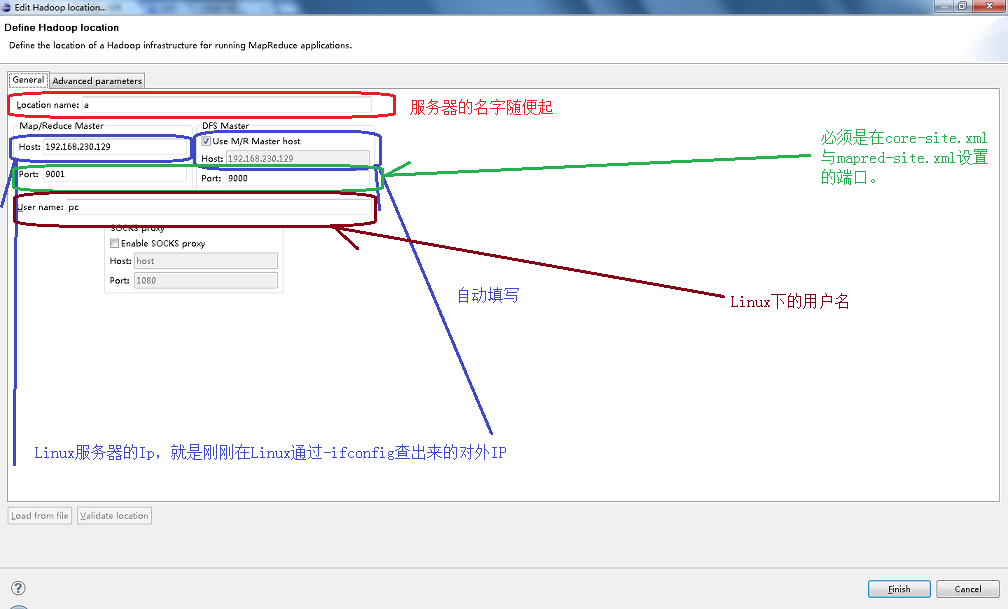
对Hadoop服务器进行设置,在General标签页进行如下图设置,主要是一些IP与端口的填写,不要写错了,写错就会报如下的错误:java.io.IOException: 您的主机中的软件中止了一个已建立的连接。
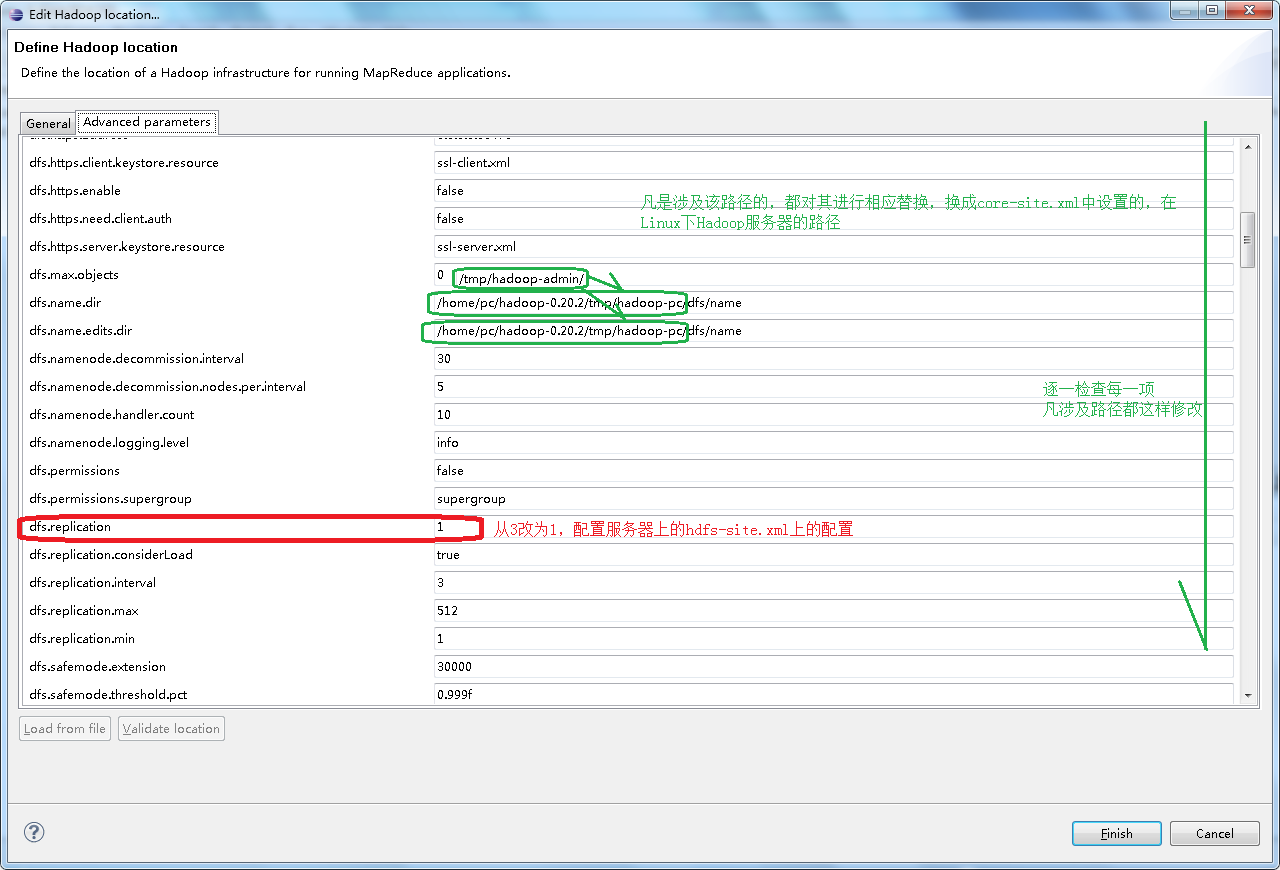
点击“完成之后”,再对这个服务器在Advanced parameters标签页进行修改,主要是一些路径的修改,凡是涉及到临时文件夹的路径,将其修改为Linux服务器上Hadoop的临时文件夹,也就是在core-site.xml下hadoop.tmp.dir的值,如下图所示:
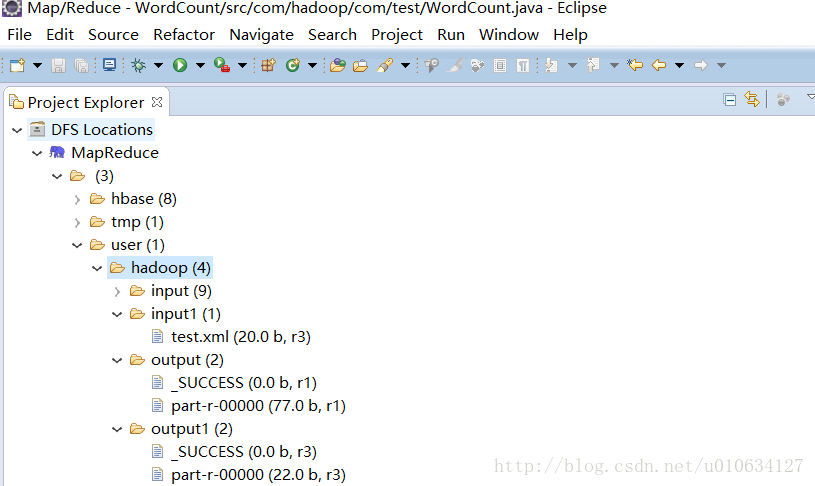
配置之后,点击左方的DFS Locations下配置好的a服务器,可以看到能够成功读取到Hadoop的文件夹,至此,终于可以编写Hadoop程序,看看Hadoop到底能够干什么呢?
四、Hadoop的Helloworld——WordCount词频统计程序
Hadoop是用于大数据应用与分析的,说白了,就是用来统计用的。
下面,利用配置好的Hadoop环境,进行Hadoop程序的开发。
1、在左侧工程视图下新建一个Map/Reduce Project。

2、然后在这个工程下新建一个WordCount.java,这个文件的代码是什么暂且不管,主要是保证其能够顺利运行即可,能够统计词频即可,接下来我们再慢慢研究。
- import java.io.IOException;
- import java.util.StringTokenizer;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- public class WordCount {
- public static class TokenizerMapper extends
- Mapper<Object, Text, Text, IntWritable> {
- private final static IntWritable one = new IntWritable(1);
- private Text word = new Text();
- public void map(Object key, Text value, Context context)
- throws IOException, InterruptedException {
- StringTokenizer itr = new StringTokenizer(value.toString());
- while (itr.hasMoreTokens()) {
- word.set(itr.nextToken());
- context.write(word, one);
- }
- }
- }
- public static class IntSumReducer extends
- Reducer<Text, IntWritable, Text, IntWritable> {
- private IntWritable result = new IntWritable();
- public void reduce(Text key, Iterable<IntWritable> values,
- Context context) throws IOException, InterruptedException {
- int sum = 0;
- for (IntWritable val : values) {
- sum += val.get();
- }
- result.set(sum);
- context.write(key, result);
- }
- }
- public static void main(String[] args) throws Exception {
- Configuration conf = new Configuration();
- String[] otherArgs = new GenericOptionsParser(conf, args)
- .getRemainingArgs();
- if (otherArgs.length != 2) {
- System.err.println("Usage: wordcount <in> <out>");
- System.exit(2);
- }
- Job job = new Job(conf, "word count");
- job.setJarByClass(WordCount.class);
- job.setMapperClass(TokenizerMapper.class);
- job.setCombinerClass(IntSumReducer.class);
- job.setReducerClass(IntSumReducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
- FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
3、这段代码还不能直接运行的。我们要先设置其输入文件夹,与输出文件夹。如下图,先在Hadoop服务器a下的根目录,也就是那个(1)文件夹,新建一个input文件夹,当然你叫其它就可以。新建完是没有反应的,必须刷新一下才能看到这个文件夹的建立。
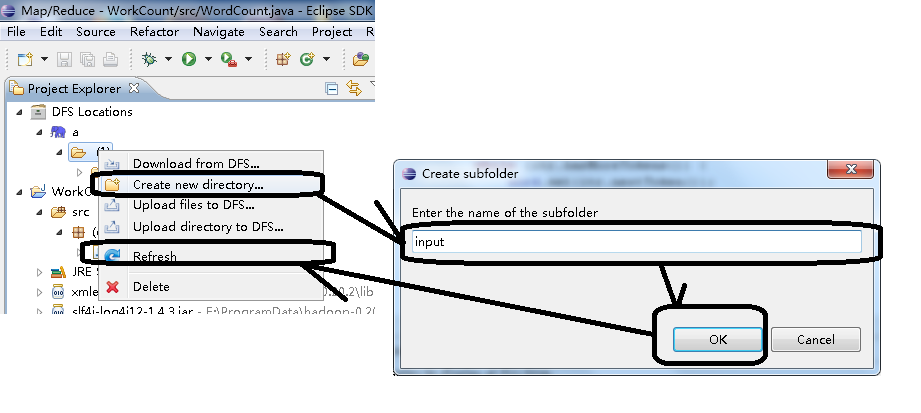
之后,通过这里的Upload files to DFS...上传一个纯英文的文本文件,比如如下的1.txt
- One World One Dream
扔上Hadoop服务器,也就是要刷新才能看到,而且这个文件夹走的是hdfs协议,你在Linux的服务器是找不到其所在的。
4、之后,对这个WordCount.java的运行方式进行运行参数的设置。
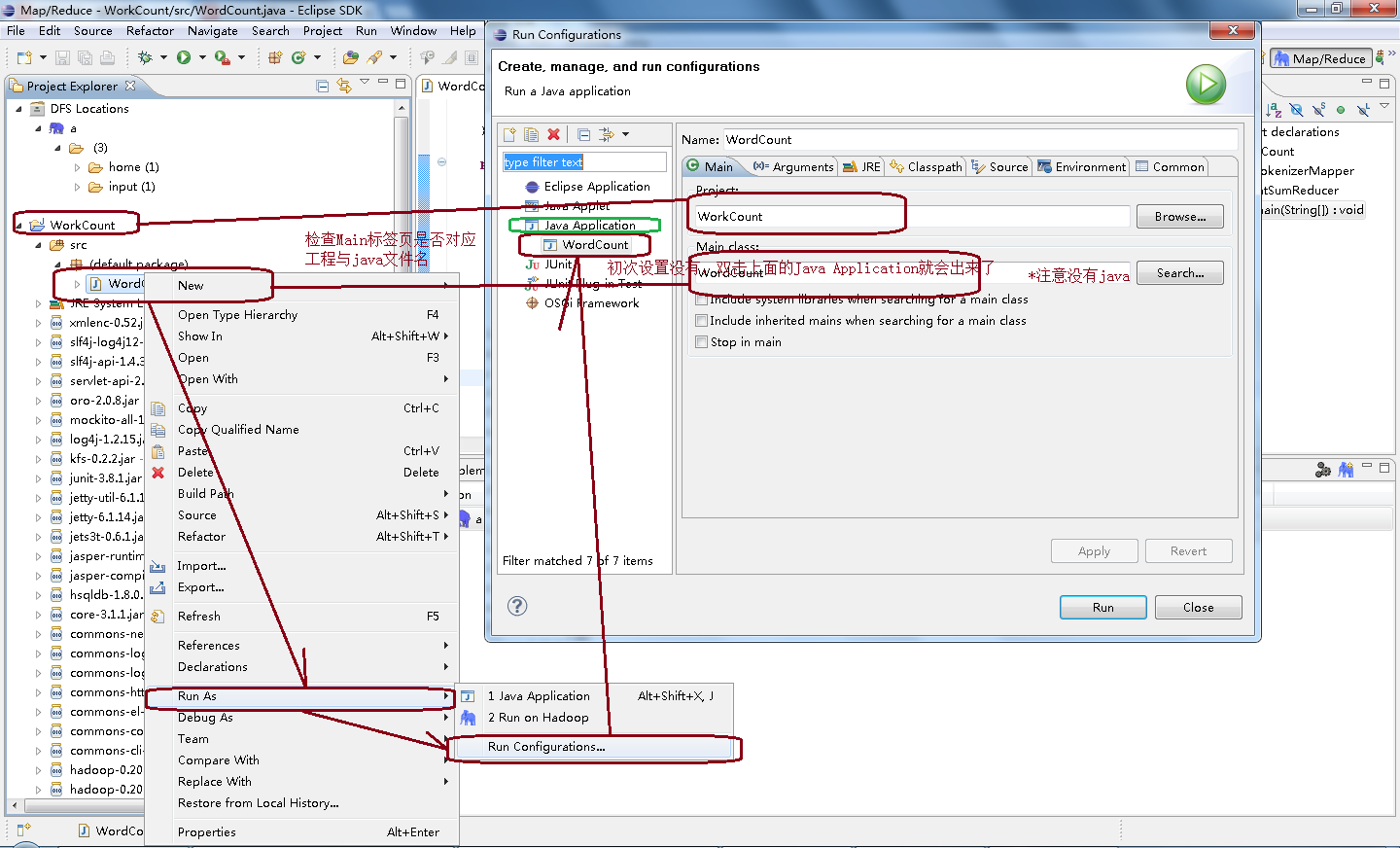
最关键还是在Arguments标签页进行如下运行参数的填写,指明其输入输出的位置:
- hdfs://192.168.230.129:9000/input/1.txt
- hdfs://192.168.230.129:9000/output
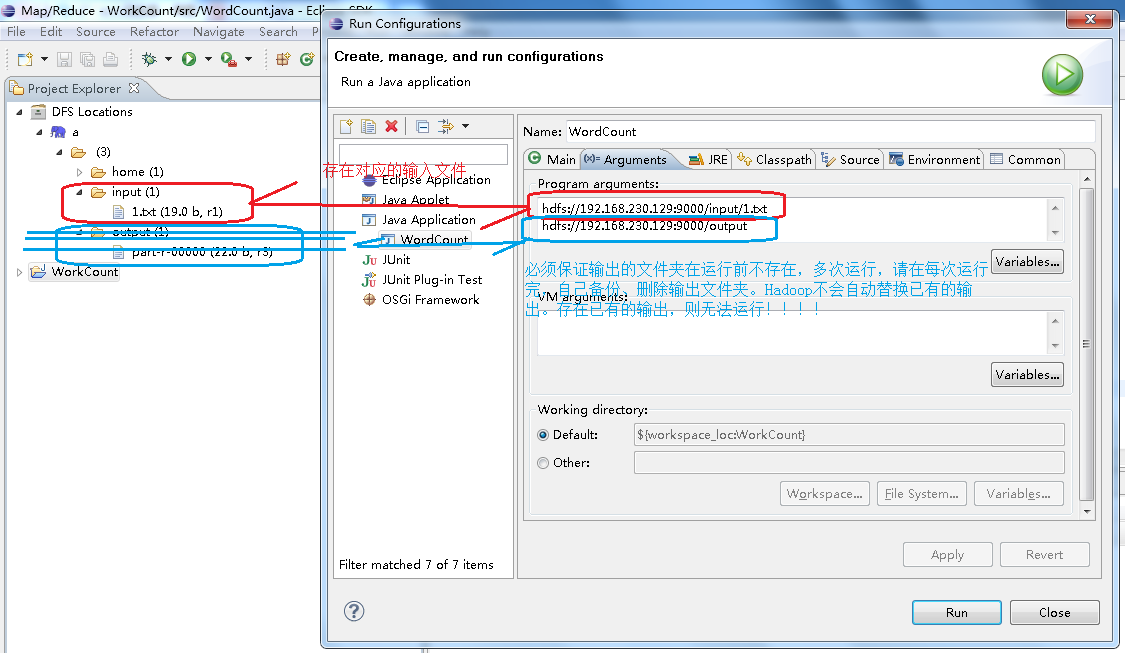
搞完之后,点击Run,或者点Close再点菜单栏上的运行图标,刷新一下名为a这个Hadoop服务器,发现output已经被创建,同时得到WordCount.java对1.txt的运行结果:
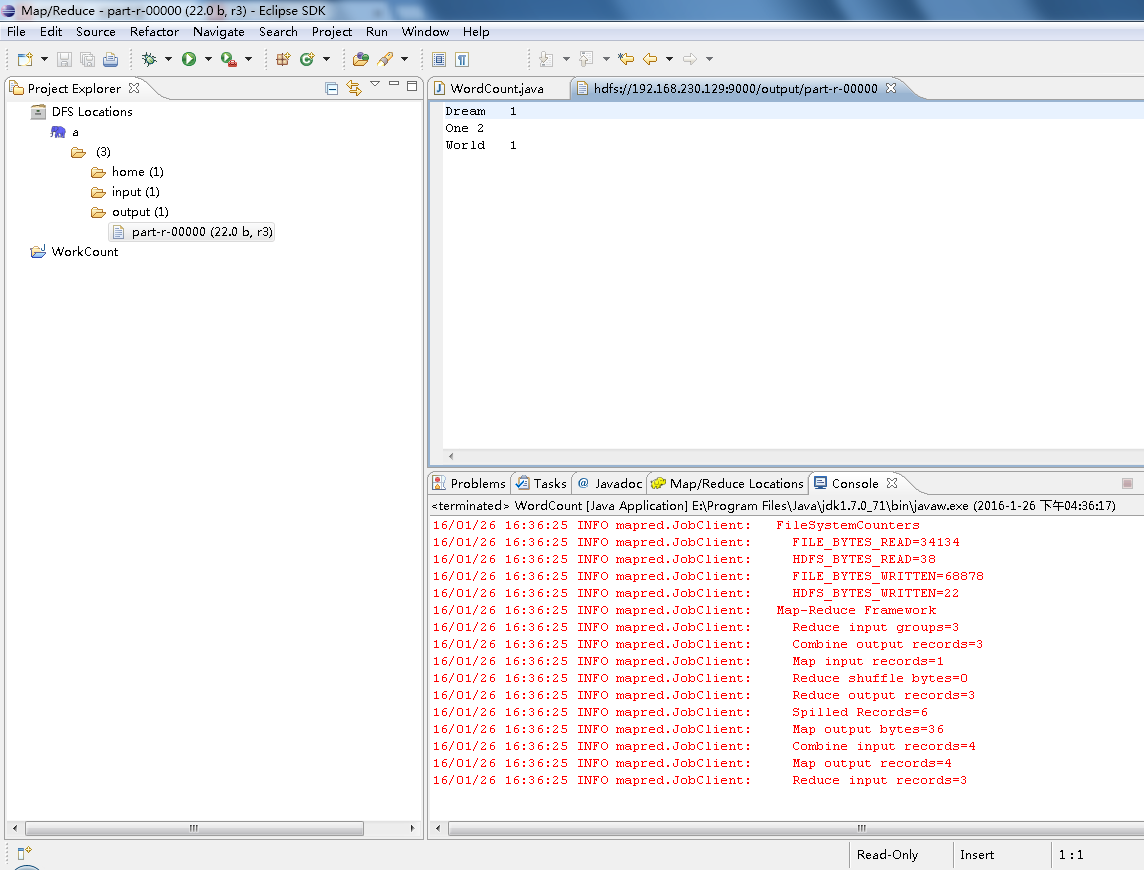
这恰好与One World One Dream的词频匹配!证明Windows下的Eclipse远程连接Linux下的Hadoop2.8.2成功。