前面博客已经更新了初阶的指针,接下来我们来详细地学习进阶指针的内容。
目录
1. 字符指针
在指针的类型中我们知道有一种指针类型为字符指针 char* ;
int main()
{
char ch = 'w';
char *pc = &ch;
*pc = 'w';
return 0;
}#include <stdio.h>
int main()
{
char str1[] = "hello bit.";
char str2[] = "hello bit.";
const char* str3 = "hello bit.";
const char* str4 = "hello bit.";
if (str1 == str2)
printf("str1 and str2 are same\n");
else
printf("str1 and str2 are not same\n");
if (str3 == str4)
printf("str3 and str4 are same\n");
else
printf("str3 and str4 are not same\n");
return 0;
}
str1,str2两个指针变量指向的字符串常量长的一样,所以内存中就没有必要保存两份字符串,只需要保存一份即可。故str1,str2两个指针变量指向的是同一个字符串常量。而指针指向字符串,实际上是将字符串首字符的地址放到了指针变量中。
而数组则不一样了,数组在内存中创建是不同空间的。所以最后的结果是
str1 and str2 are not same
str3 and str4 are same arr2
2. 指针数组
首先来类比学习
整型数组
int arr[10];//存放整型的数组字符数组
char arr2[5];//存放字符的数组指针数组
就是存放指针的数组,数组里的元素都是指针。int* arr[10];
char* ch[5];
举个例子,但是一般不这样写。
int main()
{
int a = 10;
int b = 20;
int c = 30;
int* p1 = &a;
int* p2 = &b;
int* p3 = &c;
//int* arr[3] = { &a,&b,&c };
int* arr[3] = { p1,p2,p3 };
int i = 0;
for (i = 0; i < 3; i++)
{
printf("%d ", *(arr[i]));
}
return 0;
}int main()
{
int arr1[5] = { 1,2,3,4,5 };
int arr2[5] = { 2,3,4,5,6 };
int arr3[5] = { 3,4,5,6,7 };
int* parr[3] = { arr1,arr2,arr3 };
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 5; j++)
{
//printf("%d ", parr[i][j]);
printf("%d ", *(parr[i]+j)); //这两种写法等价
}
printf("\n");
}
return 0;
}
总结:指针数组就是存放指针的数组,数组里的元素都是指针。
3. 数组指针
3.1 数组指针的定义
依旧是采用类比的方法
int main()
{
int a = 10;
int *p = &a;//整型指针 - 指向整型的指针, 存放整型变量地址的
char ch = 'w';
char* pc= &ch;//字符指针 - 指向字符的指针,存放的是字符变量的地址//数组指针 - 指向数组的指针
int* p1[10]; // 指针数组
int(*p2)[10]; // 数组指针
return 0;
}
数组指针是指针?还是数组?
答案是:指针
int main()
{
int a = 10;
int *p = &a;//整型指针 - 指向整型的指针, 存放整型变量地址的
char ch = 'w';
char* pc= &ch;//字符指针 - 指向字符的指针,存放的是字符变量的地址
//数组指针 - 指向数组的指针
int* p1[10];
int(*p2)[10];
return 0;
}3.2 &数组名VS数组名
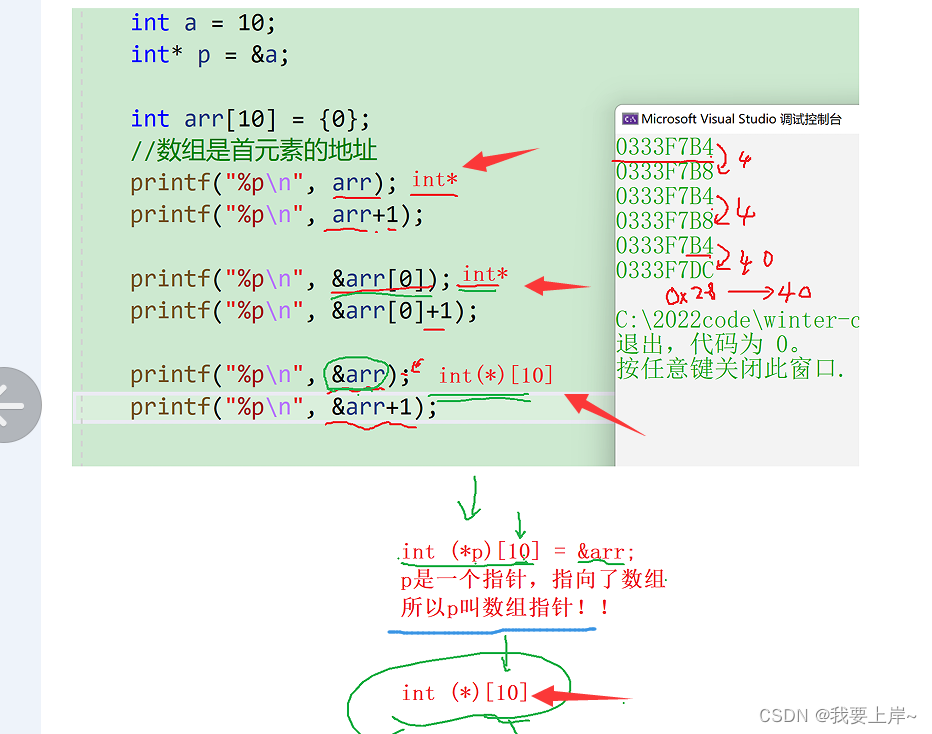
int main()
{
int a = 10;
int* p = &a;
int arr[10] = {0};
//数组是首元素的地址
printf("%p\n", arr);
printf("%p\n", arr+1);
printf("%p\n", &arr[0]);
printf("%p\n", &arr[0]+1);
printf("%p\n", &arr);
printf("%p\n", &arr+1);
return 0;
}
数组名该怎么理解呢?
通常情况下,我们说的数组名都是数组首元素的地址
但是有2个例外:
1. sizeof(数组名),这里的数组名表示整个数组,sizeof(数组名)计算的是整个数组的大小
2. &数组名,这里的数组名表示整个数组,&数组名,取出的是整个数组的地址
这里前面文章已经讲解过,不再赘述。
3.3 数组指针的使用
那么数组指针应该如何使用呢?
写一个打印数组的函数
//形参写成数组
void print(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
//写一个函数来打印arr数组
int sz = sizeof(arr) / sizeof(arr[0]);
print(arr,sz);
return 0;
}//形参写成指针
void print(int* arr, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", *(arr + i));
}
printf("\n");
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
//写一个函数来打印arr数组
int sz = sizeof(arr) / sizeof(arr[0]);
print(arr, sz);
return 0;
}//不推荐这样的写法
void print(int(*p)[10], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", *(*p+i));
}
printf("\n");
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
//写一个函数来打印arr数组
int sz = sizeof(arr) / sizeof(arr[0]);
print(&arr, sz);
return 0;
}第三张图我将数组的地址传给了打印函数,我们一般是不这样写的,但是为了讲解不得已这样。
我们来类比一下学习
而我们已知p是指向数组的,*p是不是就得到了整个数组,而数组名(数组首元素地址)就相当于是整个数组,也就是说*p就等于数组名。而*(*p+i),相比于上面用指针当参数的(*p+i)写法是不是脱裤子放屁,多此一举? 所以,我们在一维数组中,基本不会传地址过去。
真正用到的是二维数组
void print2(int arr[3][5], int c, int r)
{
int i = 0;
for (i = 0; i < c; i++)
{
int j = 0;
for (j = 0; j < r; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7} };
//int (*ptr)[3][5] = &arr;
//写一个函数,打印arr数组
print2(arr, 3, 5);
return 0;
}void print2(int(*p)[5], int c, int r)
{
int i = 0;
for (i = 0; i < c; i++)
{
int j = 0;
for (j = 0; j < r; j++)
{
//printf("%d ", p[i][j]);
printf("%d ", *(*(p+i)+j));
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7} };
//int (*ptr)[3][5] = &arr;
//写一个函数,打印arr数组
print2(arr, 3, 5);
return 0;
}对于二维数组而言,数组首元素地址就相当于它的第一行的地址,所以我们用数组指针来做参数。
p+i是指向第i行的,*(p+i)相当于拿到了第i行的地址,也就相当于第i行的数组名
数组名表示首元素的地址,*(p+i) 就是第i行第一个元素的地址
练习 理解下述代码的意思
int arr[5];
int *parr1[10];
int (*parr2)[10];
int (*parr3[10])[5];int arr[5];
arr是一个整形数组,每个元素是int类型的,有5个元素int* parr1[10];
parr1是一个数组,数组10个元素,每个元素的类型是int*int(*parr2)[10];
parr2是一个指向数组的指针,指向的数组有10个元素,每个元素的类型是intint(* parr3[10])[5];
parr3 是一个数组,数组有10个元素,每个元素的类型是:int(*)[5]
parr3是存放数组指针的数组
4. 数组参数、指针参数
4.1 一维数组传参
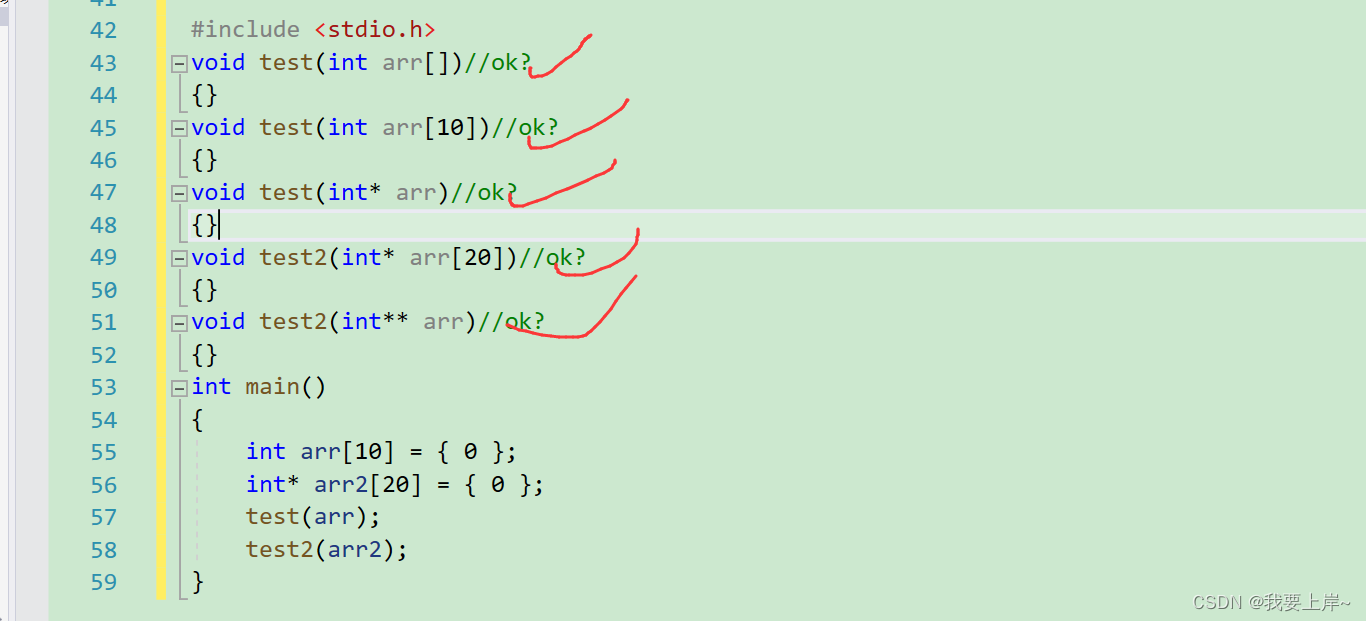
上述图片中五种传参方式都是可行的,一维数组传参时传的是数组名,也就是数组首元素地址,这里足够简单就不用再赘述了。唯一要注意的是第五个,arr2数组的元素类型是int*,所以arr2首元素的地址其实就是int*类型的地址,所以要在int*再加一个*,也就是int**。
4.2 二维数组传参

首先,二维数组传参,函数形参的设计只能省略第一个[ ]的数字。
因为对一个二维数组,可以不知道有多少行,但是必须知道一行多少元素,这样才方便运算。
在强调一遍二维数组的首元素地址就是它的第一行地址,所以函数形参可以写成数组指针形式,而其他的形式都不可以。二级指针是用来存放一级指针的地址的,所以也不可以。
void test1(int (*p)[5])
{}
void test2(int(*p)[3][5])
{
*p;
}
int main()
{
int arr[3][5];
test1(arr);//传递的第一行的地址
test2(&arr);//传递的是整个二维数组的地址
return 0;
}4.3 一级指针传参
#include <stdio.h>
void print(int* p, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d\n", *(p + i));
}
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9 };
int* p = arr;
int sz = sizeof(arr) / sizeof(arr[0]);
//一级指针p,传给函数
print(p, sz);
return 0;
}一级指针说烂了,不说了。但是我们还要做到这样一点,就是看传的形参类型,想出它的实参类型。比如:
你想一想它能以什么样的参数传过来?
你是不是可以想到这些
void test(int* ptr)
{
//...
}int main()
{
int a = 0;
int* p = &a;
int arr[5] = 0;
test(&a);
test(p);
test(arr);
return 0;
}4.4 二级指针传参
void test(char** ppc)
{
}
int main()
{
char a = 'w';
char* pa = &a;
char** ppa = &pa;//ppa就是一个二级指针
test(ppa);
return 0;
}二级指针是用来存放一级指针的地址的。
当函数的参数为二级指针的时候,可以接收什么参数。
void test(char** ppc)
{
}
int main()
{
char ch = 'a';
char* pc = &ch;
char** ppc = &pc;
char* arr[4];
//char arr2[3][5];
//test(arr2);//err 这里是错误的,不可以。要用数组指针来接收
test(arr);
test(&pc);
test(ppc);
}5. 函数指针
int test(char* str)
{
}
int Add(int x, int y)
{
return x + y;
}
int main()
{
int arr[10];
//arr
//&arr
int (*p)[10] = &arr;//p是一个数组指针变量
printf("%p\n", &Add);
printf("%p\n", Add);
int (* pf)(int, int) = Add;//就是函数指针变量
//0x0012ff40
int ret = (*pf)(2,3);
//int ret = Add(2, 3);
//int ret = pf(2, 3);
printf("%d\n", ret);
//int (*pt)(char*) = test;
return 0;
}还是类比学习一下,根据数组指针的写法,来写出函数指针。
函数指针的写法 返回值类型 (*) (参数)
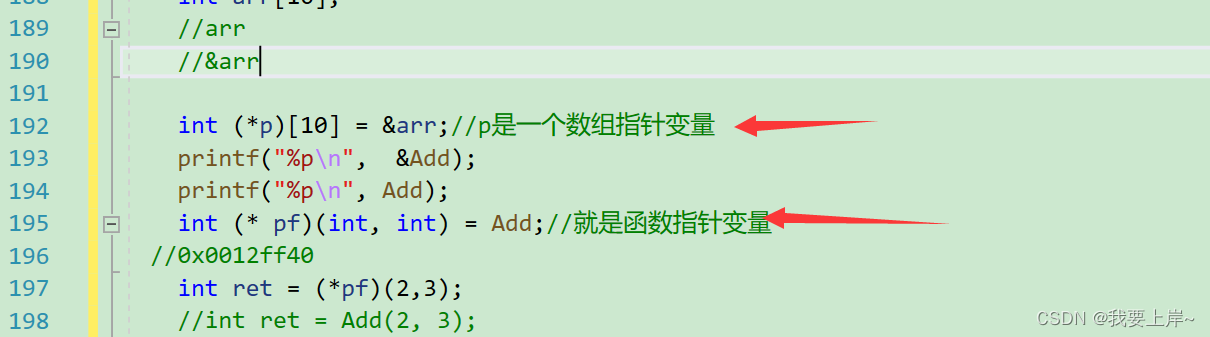
再将函数的地址打印一下
 你会发现加不加取地址符号,Add函数的地址都是一样的。
你会发现加不加取地址符号,Add函数的地址都是一样的。
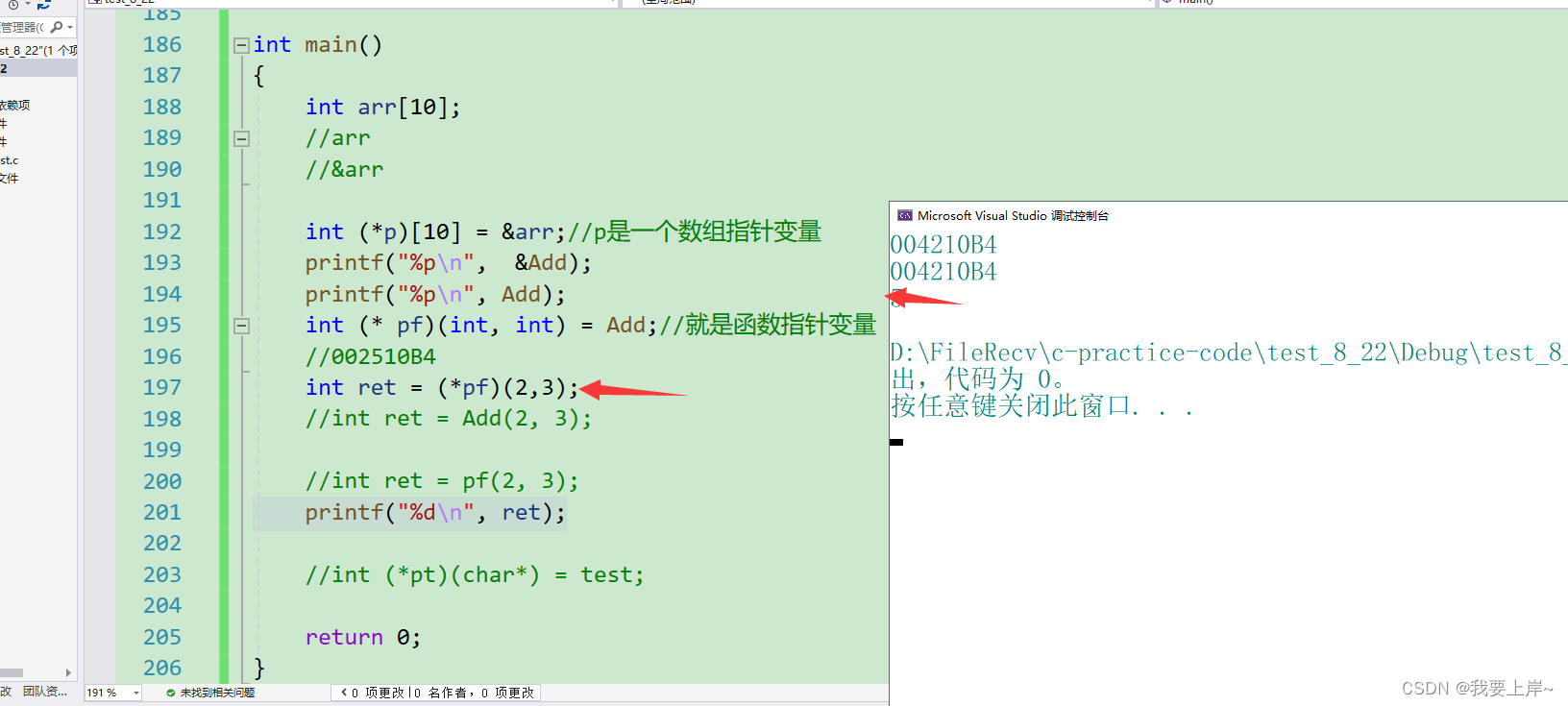 而*pf是不是就等价于Add,而直接用pf也可以等价于Add.这就跟上面的Add函数的地址一样,无论你加不加&,它都没有影响,也就是说函数名就是地址,但这其实是编译器自动处理的,所以加不加*解引用操作符都没有影响。
而*pf是不是就等价于Add,而直接用pf也可以等价于Add.这就跟上面的Add函数的地址一样,无论你加不加&,它都没有影响,也就是说函数名就是地址,但这其实是编译器自动处理的,所以加不加*解引用操作符都没有影响。
接下来带你看两段有趣的代码

代码1
void (*)() 是函数指针类型
( void (*)() ) 强制类型转换
(类型)
( void (*)() )0 对0进行强制类型的转换
( *( void (*)() )0 )();
1. 首先是把0强制类型转换为一个函数指针类型,这就意味着0地址处放一个返回类型是void,无参的一个函数
2. 调用0地址处的这个函数
函数声明
int Add(int, int);
代码2
void (* signal(int, void(*)(int)) )(int);//函数声明typedef void(* pf_t)(int) ;//给函数指针类型void(*)(int)重新起名叫:pf_t
pf_t signal(int, pf_t);
signal是一个函数的声明
signal函数的参数,第一个是int类型的,第二个是void(*)(int)的函数指针类型
signal函数的返回值类型是:void(*)(int)的函数指针
6. 函数指针数组
数组是一个存放相同类型数据的存储空间,那我们已经学习了指针数组,那要把函数的地址存到一个数组中,那这个数组就叫函数指针数组,那函数指针的数组如何定义呢? 加个下标引用操作符即可。
int (*parr1[10])();函数指针数组的用途:转移表。
举个例子(计算器)
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("**************************\n");
printf("**** 1.add 2.sub ****\n");
printf("**** 3.mul 4.div ****\n");
printf("**** 0.exit ****\n");
printf("**************************\n");
}
int main()
{
int input = 0;
int x = 0;
int y = 0;
int ret = 0;
do
{
menu();
printf("请选择:>");
scanf("%d", &input);
switch (input)
{
case 1:
printf("请输入2个操作数:>");
scanf("%d%d", &x, &y);
ret = Add(x, y);
printf("ret = %d\n", ret);
break;
case 2:
printf("请输入2个操作数:>");
scanf("%d%d", &x, &y);
ret = Sub(x, y);
printf("ret = %d\n", ret);
break;
case 3:
printf("请输入2个操作数:>");
scanf("%d%d", &x, &y);
ret = Mul(x, y);
printf("ret = %d\n", ret);
break;
case 4:
printf("请输入2个操作数:>");
scanf("%d%d", &x, &y);
ret = Div(x, y);
printf("ret = %d\n", ret);
break;
case 0:
printf("退出计算器\n");
break;
default:
printf("选择错误\n");
break;
}
} while (input);
return 0;
}
我们可以发现使用case语句实现的计算器代码太冗余了。但是使用函数指针呢?我们就可以发现代码量一下子就减少了。
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("**************************\n");
printf("**** 1.add 2.sub ****\n");
printf("**** 3.mul 4.div ****\n");
printf("**** 0.exit ****\n");
printf("**************************\n");
}
int main()
{
int input = 0;
int x = 0;
int y = 0;
int ret = 0;
//转移表
int (*pfArr[])(int, int) = {0, Add, Sub, Mul, Div};
do
{
menu();
printf("请选择:>");
scanf("%d", &input);
if (input == 0)
{
printf("退出计算器\n");
}
else if(input >= 1 && input<=4)
{
printf("请输入2个操作数:>");
scanf("%d%d", &x, &y);
ret = pfArr[input](x, y);
printf("ret = %d\n", ret);
}
else
{
printf("选择错误\n");
}
} while (input);
return 0;
}
计算器的另一种实现方法
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("**************************\n");
printf("**** 1.add 2.sub ****\n");
printf("**** 3.mul 4.div ****\n");
printf("**** 0.exit ****\n");
printf("**************************\n");
}
void calc(int (*pf)(int,int))
{
int x = 0;
int y = 0;
int ret = 0;
printf("请输入2个操作数:>");
scanf("%d%d", &x, &y);
ret = pf(x, y);
printf("ret = %d\n", ret);
}
int main()
{
int input = 0;
do
{
menu();
printf("请选择:>");
scanf("%d", &input);
switch (input)
{
case 1:
calc(Add);
break;
case 2:
calc(Sub);
break;
case 3:
calc(Mul);
break;
case 4:
calc(Div);
break;
case 0:
printf("退出计算器\n");
break;
default:
printf("选择错误\n");
break;
}
} while (input);
return 0;
}7. 指向函数指针数组的指针
指向函数指针数组的指针是一个 指针
指针指向一个 数组 ,而·这个数组的元素都是 函数指针 ;
int Add(int x, int y)
{
return x + y;
}
int main()
{
int arr[10] = {1,2,3,4,5,6,7};
int(*p)[10] = &arr;//p得是数组指针
int* arr2[5];
int* (*p2)[5] = &arr2;
//函数指针
int (*pf)(int, int) = &Add;
//函数指针数组
int (* pfarr[4])(int, int);
int (* (*p3)[4])(int, int) = &pfarr;//p3是一个指向函数指针数组的指针
return 0;
}同样的,类比学习。
8. 回调函数
回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个
函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由该函数
的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进
行响应。
void test()
{
printf("hehe\n");
}
void print_hehe(void (*p)())
{
if (1)
p();
}
int main()
{
print_hehe(test);
return 0;
}test函数的作用是是打印hehe,但是我们并没有直接调用test函数,而是将其地址传给了print_hehe,通过print_hehe来使用这个函数。test函数就被称为回调函数。
再来看一个qsort函数的例子
qsort是c语言的一个库函数,基于快速排序算法实现的一个排序的函数。
首先,最好从冒泡排序引入。
void bubble_sort(int arr[],int sz)
{
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
void print_arr(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
//冒泡排序
void test1()
{
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
print_arr(arr, sz);
}
int main()
{
test1();
return 0;
}首先看一下qsort函数所需要的参数

这里待排序数据的起始位置与待比较的两个元素的地址用的是void*类型,是因为我们qsort函数的作者在设计这个函数时,他不会想到会对什么样类型的数据进行排序,所以用void*来表示元素类型,排序数据的类型需要使用者自己转换。
为什么要使用到自定义的比较函数呢?
我们排序的整形数据:用 > <
但是我们排序的是结构体数据:可能不方便直接使用 > < 比较了
这时候使用者就要根据实际情况,提供一个函数,实现2个数据的比较。
这是用qsort来排序整型数据。
void print_arr(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
int cmp_int(const void* e1,const void* e2)
{
return (*(int*)e1 - *(int*)e2);
}
void test2()
{
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
qsort(arr, sz,sizeof(arr[0]),cmp_int);
print_arr(arr, sz);
}
int main()
{
//test1();
test2();
return 0;
}
qsort这个函数的排序结果默认是升序的。如果你要实现逆序,只需要将你所定义的函数的返回值颠倒即可。

qsort用来排序结构体数据,排序结构体可不能简单的> <,而是要规定比较的类型。
这是用qsort来排序结构体类型。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct Stu
{
char name[20];
int age;
double score;
};
int cmp_stu_by_age(const void* e1,const void* e2)
{
return ((struct Stu*)e1)->age - ((struct Stu*)e2)->age;
}
int cmp_stu_by_name(const void* e1, const void* e2)
{
strcmp(((struct Stu*)e1)->name, ((struct Stu*)e2)->name);
}
int cmp_stu_by_score(const void* e1, const void* e2)
{
return ((struct Stu*)e1)->score - ((struct Stu*)e2)->score;
}
void test3()
{
struct Stu arr[3] = { {"zhangshan",30,80.0},{"lisi",20,60.0},{"wangwu",40,90.0}};
int sz = sizeof(arr) / sizeof(arr[0]);
qsort(arr, sz, sizeof(arr[0]), cmp_stu_by_age); //按年龄排序
qsort(arr, sz, sizeof(arr[0]), cmp_stu_by_name); // 按名字排序
qsort(arr, sz, sizeof(arr[0]), cmp_stu_by_score); //按成绩排序
}
int main()
{
//test1();
//test2();
test3();
return 0;
}
我们前面写的冒泡排序只能用于整型数据,接下来,我们来使用回调函数,模仿qsort函数的功能来实现一个通用的冒泡排序。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int cmp_int(const void* e1, const void* e2)
{
return (*(int*)e1 - *(int*)e2);
}
void Swap(char* buf1, char* buf2, int width)
{
int i = 0;
for (i = 0; i < width; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
void bubble_sort(void* base, int num, int width, int (*cmp)(const void* e1, const void* e2))
{
int i = 0;
for (i = 0; i < num - 1; i++)
{
int j = 0;
for (j = 0; j < num - 1 - i; j++)
{
//if (arr[j] > arr[j + 1])//比较
if (cmp((char*)base + j * width, (char*)base + (j + 1) * width) > 0)
{
//交换
Swap((char*)base + j * width, (char*)base + (j + 1) * width, width);
}
}
}
}
void test4()
{
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz, sizeof(arr[0]), cmp_int);
print_arr(arr, sz);
}
int main()
{
//test1();
//test2();
//test3();
test4();
return 0;
}先来说明bubble_sort函数的实现,冒泡排序还是基于原来的有n个元素,就进行n-1趟的冒泡排序,每一趟之后都会确定一个元素的最终位置,每一趟要比较的次数比剩余带排序数字的个数少一。所以,只是将上文中目录中第8部分开始的常规方法的冒泡排序中的sz改成了num。
再之后,要进行比较

base指向的带排序数据的起始位置,而我们知道数据大小是四个字节,base是空指针类型,如果要交换的话,就要先将它强转为char*类型,然后加上数据的大小就可以进行比较了。
再之后是交换,我把它封装成了一个函数,我们要把地址传进去,还要将数据大小也传进去,因为传进去的地址,swap函数只知道从哪里开始,却不知道从哪里停下。

而在内存中 ,数据是这样存放的,而char*类型的指针每次只能移动一个字节,所以要swap函数里要有四次循环,逐一将两个元素进行交换。
9. 指针和数组笔试题解析
做题之前,先复习一下之前的知识。
数组名是什么呢?
数组名通常来说是数组首元素的地址
但是有2个例外:
1. sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小
2. &数组名,这里的数组名表示整个数组,取出的是整个数组的地址
sizeof是一个操作符
sizeof 计算的是对象所占内存的大小-单位是字节,size_t
不在乎内存中存放的是什么,只在乎内存大小
strlen 库函数
求字符串长度,从给定的地址向后访问字符,统计\0之前出现的字符个数
//一维数组
int main()
{
int a[] = { 1,2,3,4 };
//0 1 2 3
int (*p)[4] = &a;
printf("%d\n", sizeof(a)); //4*4 = 16
printf("%d\n", sizeof(a + 0)); //4/8 a+0是数组第一个元素的地址,是地址,大小就是4/8个字节
printf("%d\n", sizeof(*a)); //4 a表示数组首元素的地址,*a表示数组的第一个元素
//sizeof(*a)就是第一个元素的大小-4
printf("%d\n", sizeof(a + 1)); //4/8 a表示数组首元素的地址,a+1数组第二个元素的地址
//sizeof(a+1)就是第二个元素的地址的大小
printf("%d\n", sizeof(a[1])); //4 计算的是第二个元素的大小
printf("%d\n", sizeof(&a)); //4/8 &a取出的是数组的地址,数组的地址也是地址呀,是地址大小就是4/8字节
printf("%d\n", sizeof(*&a)); //16 计算的整个数组的大小
printf("%d\n", sizeof(&a + 1)); //4/8 - &a是数组的地址,+1跳过整个数组,产生的4后边位置的地址
printf("%d\n", sizeof(&a[0])); //4/8 取出的数组第一个元素的地址
printf("%d\n", sizeof(&a[0] + 1)); //4/8 数组第二个元素的地址
}//字符数组
int main()
{
char arr[] = { 'a','b','c','d','e','f' };//[a b c d e f]
printf("%d\n", strlen(arr));//随机值,arr数组中没有\0,所以strlen函数会继续往后找\0,统计\0之前出现的字符个数
printf("%d\n", strlen(arr + 0));//随机值,arr+0还是数组首元素的地址
//printf("%d\n", strlen(*arr));//err - arr是数组首元素的地址,*arr是数组的首元素,‘a’-97
//printf("%d\n", strlen(arr[1]));//err -'b' - 98
printf("%d\n", strlen(&arr));//随机值
printf("%d\n", strlen(&arr + 1));//随机值
printf("%d\n", strlen(&arr[0] + 1));//随机值
printf("%d\n", sizeof(arr));//6
printf("%d\n", sizeof(arr + 0));//4/8 arr + 0是数组首元素的地址
printf("%d\n", sizeof(*arr));//1 - *arr是首元素,首元素是一个字符,大小是一个字节
printf("%d\n", sizeof(arr[1]));//1 - arr[1]是数组的第二个元素,大小是1个字节
printf("%d\n", sizeof(&arr));//4/8 &arr是数组的地址
printf("%d\n", sizeof(&arr + 1));//4/8 &arr + 1是从数组地址开始向后跳过了整个数组产生的一个地址
printf("%d\n", sizeof(&arr[0] + 1));//4/8 &arr[0] + 1 是数组第二个元素的地址
}//字符数组
int main()
{
//char arr[] = { 'a', 'b', 'c','d', 'e', 'f' };
char arr[] = "abcdef";
//[a b c d e f \0]
printf("%d\n", strlen(arr));//6
printf("%d\n", strlen(arr + 0));//6
//printf("%d\n", strlen(*arr));//err
//printf("%d\n", strlen(arr[1]));//err
printf("%d\n", strlen(&arr));//6
printf("%d\n", strlen(&arr + 1));//随机值
printf("%d\n", strlen(&arr[0] + 1));//5
printf("%d\n", sizeof(arr));//7
printf("%d\n", sizeof(arr + 0));//4/8 arr+0是数组首元素的地址
printf("%d\n", sizeof(*arr));//1 - *arr 数组的首元素
printf("%d\n", sizeof(arr[1]));//1 arr[1]数组的第二个元素
printf("%d\n", sizeof(&arr));//4/8 - &arr数组的地址,但是数组的地址依然是地址,是地址大小就是4/8
printf("%d\n", sizeof(&arr + 1));//4/8 - &arr + 1是\0后边的这个地址
printf("%d\n", sizeof(&arr[0] + 1));//4/8 - &arr[0] + 1是数组第二个元素的地址
}//字符指针
int main()
{
char* p = "abcdef";
printf("%d\n", strlen(p));//6
printf("%d\n", strlen(p + 1));//5 从b的位置开始向后数字符
//printf("%d\n", strlen(*p)); //err
//printf("%d\n", strlen(p[0]));//err
printf("%d\n", strlen(&p));//随机值
printf("%d\n", strlen(&p + 1));//随机值
printf("%d\n", strlen(&p[0] + 1));//5 从b的位置开始向后数字符
printf("%d\n", sizeof(p));//4/8 p是指针变量,计算的是指针变量的大小
printf("%d\n", sizeof(p + 1));//4/8 p+1是'b'的地址
printf("%d\n", sizeof(*p)); //1 - *p 其实就是'a'
printf("%d\n", sizeof(p[0]));//1 - p[0]-> *(p+0)-> *p
printf("%d\n", sizeof(&p));//4/8 &p 是指针变量p在内存中的地址
printf("%d\n", sizeof(&p + 1));//4/8 - &p+1是跳过p之后的地址
printf("%d\n", sizeof(&p[0] + 1));//4/8 &p[0]是‘a’的地址,&p[0]+1就是b的地址
}
//二维数组
int main()
{
int a[3][4] = { 0 };
printf("%d\n", sizeof(a));//计算的是整个数组的大小,单位是字节3*4*4 = 48
printf("%d\n", sizeof(a[0][0]));//4 第1行第一个元素的大小
printf("%d\n", sizeof(a[0]));//16 - a[0]是第一行的数组名,sizeof(a[0])就是第一行的数组名单独放在sizeof内部,计算的是第一行的大小
printf("%d\n", sizeof(a[0] + 1));//4/8 a[0]作为第一行的数组名,并没有单独放在sizeof内部,也没有被取地址
//所以a[0]就是数组首元素的地址,就是第一行第一个元素的地址,a[0]+1就是第一行第二个元素的地址
printf("%d\n", sizeof(*(a[0] + 1)));//4 - *(a[0] + 1))表示的是第一行第二个元素
printf("%d\n", sizeof(a + 1));//4/8 - a表示首元素的地址,a是二维数组,首元素的地址就是第一行的地址
//所以a表示的是二维数组第一行的地址,a+1就是第二行的地址
printf("%d\n", sizeof(*(a + 1)));//16 对第二行的地址解引用访问到就是第二行
//*(a+1) -> a[1]
//sizeof(a[1])
//
printf("%d\n", sizeof(&a[0] + 1));//4/8 - a[0]是第一行的数组名,&a[0]取出的就是第一行的地址
//&a[0] + 1 就是第二行的地址
printf("%d\n", sizeof(*(&a[0] + 1)));//16 - 对第二行的地址解引用访问到就是第二行
printf("%d\n", sizeof(*a));//16 - a就是首元素的地址,就是第一行的地址,*a就是第一行
//*a - > *(a+0) -> a[0]
printf("%d\n", sizeof(a[3]));//16 int [4]
//int a = 10;
//printf("%d\n", sizeof(a));//4
//printf("%d\n", sizeof(int));//4
return 0;
}10. 指针笔试题
10.1
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int* ptr = (int*)(&a + 1);
printf("%d,%d", *(a + 1), *(ptr - 1));
return 0;
}
程序的结果是什么 答案是 2 , 5。
答案是 2 , 5。
10.2
//由于还没学习结构体,这里告知结构体的大小是20个字节
struct Test
{
int Num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
}* p;
//假设p 的值为0x100000。 如下表表达式的值分别为多少?
//已知,结构体Test类型的变量大小是20个字节
int main()
{
p = (struct Test*)0x100000;
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}这题,我们要复习一下前面的知识。指针的类型决定了指针向前或者向后走一步有多大(距离)

p是结构体指针类型,所以p+1,指针会向后偏移20个字节。而p被强转为无符号整数时,地址加一就是加一,p被转化为无符号整型指针类型时,加一会向后偏移四个字节。
10.3
int main()
{
int a[4] = { 1, 2, 3, 4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);
return 0;
}%x的意思是以16进制打印,但是只打印有效位。


10.4
#include <stdio.h>
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int* p;
p = a[0];
printf("%d", p[0]);
return 0;
}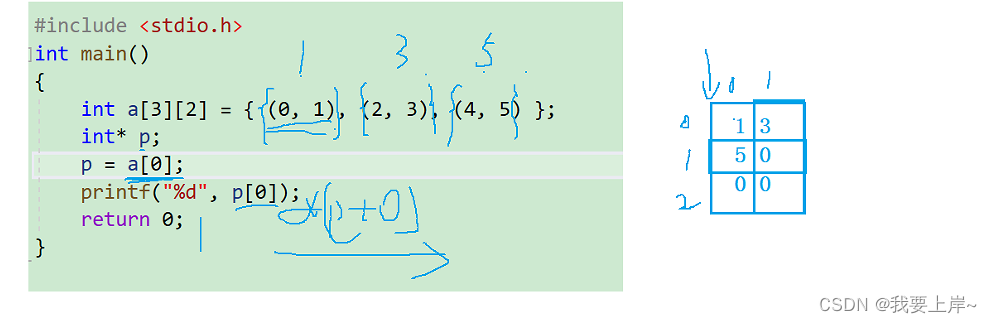 注意,这个是逗号表达式。
注意,这个是逗号表达式。
10.5
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}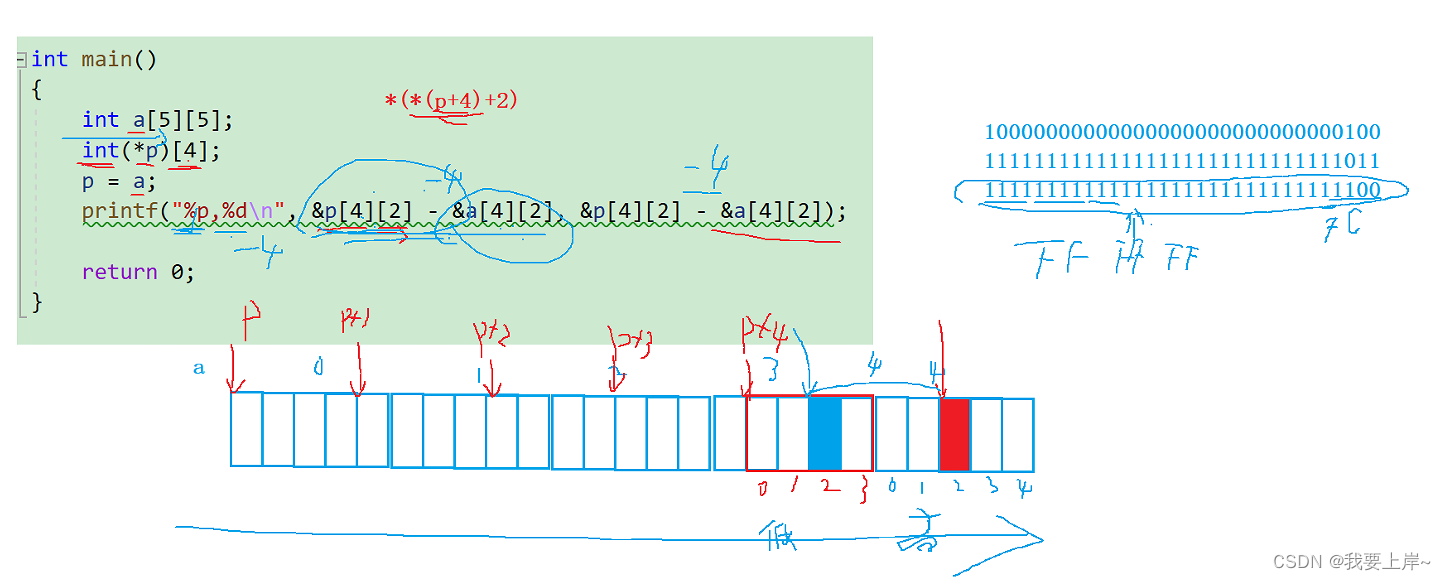
这里,注意一点p作为一个函数指针,每次加1跳过4个字节。 指针减指针 表示的是 两个地址之间元素个数的绝对值。
10.6
#include <stdio.h>
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int* ptr1 = (int*)(&aa + 1);
int* ptr2 = (int*)(*(aa + 1));
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}
10.7
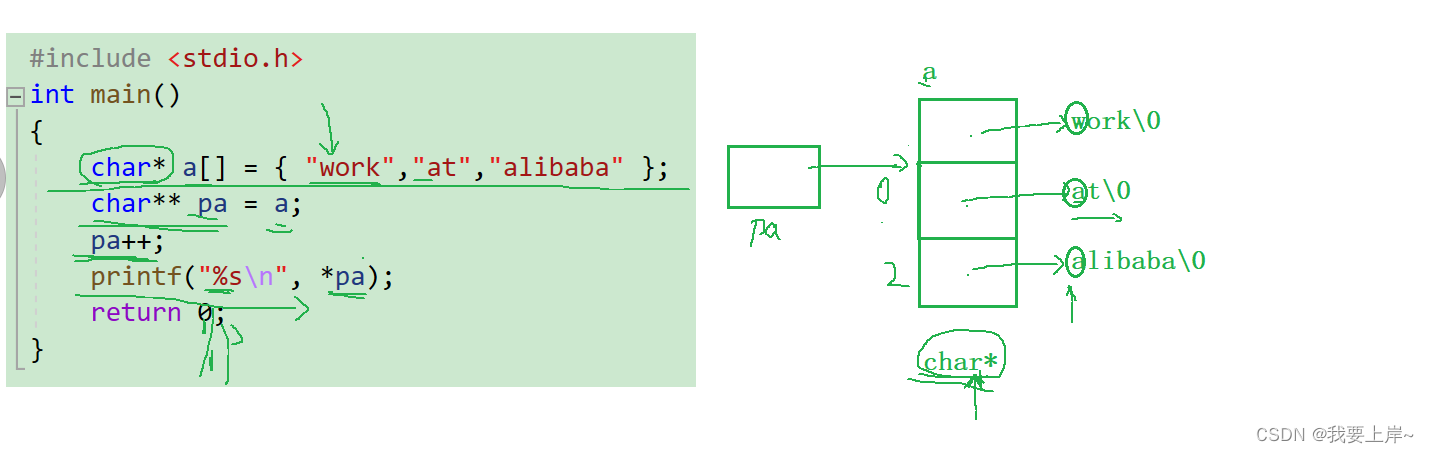
int main()
{
char* a[] = { "work","at","alibaba" };
char** pa = a;
pa++;
printf("%s\n", *pa);
return 0;
}

10.8
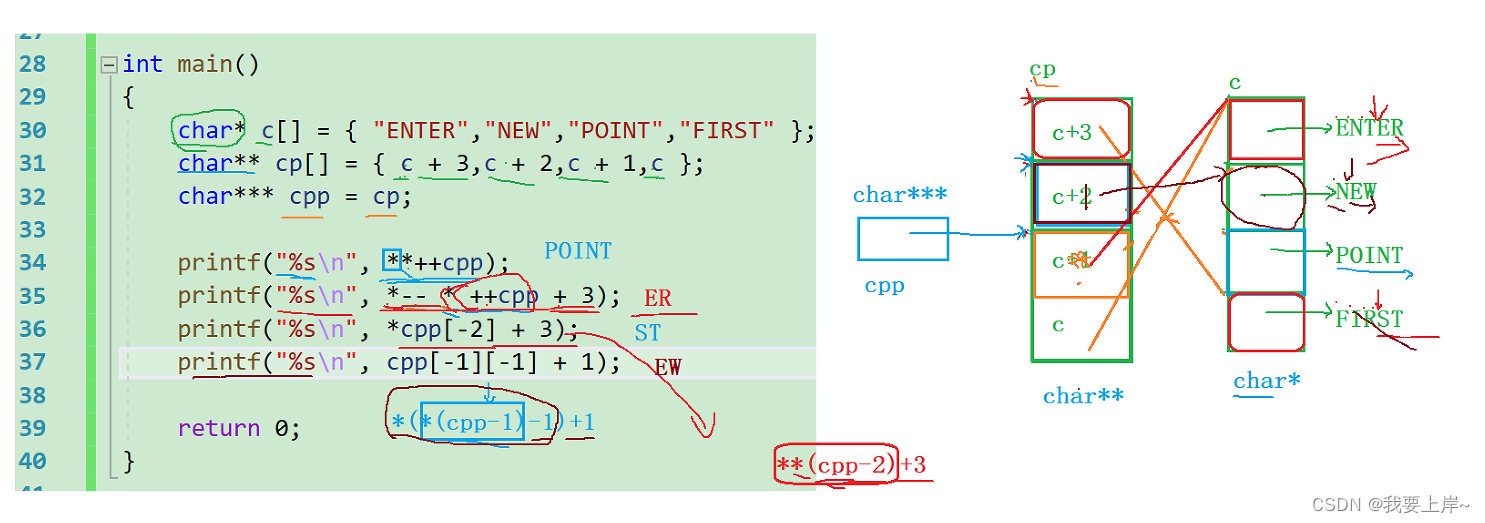
int main()
{
char* c[] = { "ENTER","NEW","POINT","FIRST" };
char** cp[] = { c + 3,c + 2,c + 1,c };
char*** cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *-- * ++cpp + 3);
printf("%s\n", *cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);
return 0;
}