目录
上一篇文章与大家分享并深度讨论研究了自定义类型中结构体和位段的内容,那么今天继续研究枚举和联合体的内容,希望对你有所帮助
1.枚举
枚举类型顾名思义就是一一列举。
把可能的取值一一列举出来。
一周的星期一到星期日是七天时间;
一年有十二个月份;
男女的性别也可以列举出来;
等等等等其他有很多可以被列举出来
枚举类型的关键字是enum,
enum SEX
{
};和结构体相似,有枚举类型的关键字,有枚举标签,在大括号中放的是枚举未来的可能取值
那在这里我们枚举性别来了解一下
enum SEX
{
//枚举的可能取值
MALE,
FEMALE,
SECRET,
};这样我们就创建好了一个枚举类型;
我们也可以用这个枚举类型在main函数中创建出一个枚举变量,完整的情况如下
#include<stdio.h>
enum SEX
{
//枚举的可能取值
MALE,
FEMALE,
SECRET,
};
int main()
{
enum SEX s = MALE;
return 0;
} 只能把枚举值赋予枚举变量,不能把元素的数值直接赋予枚举变量。
那我们更加直观的来了解一下这些枚举的取值到底是什么,为什么可以被直接赋值呢?
我们直接将他们打印出来

可以看到他们的可能取值默认值是0 1 2
所以,枚举的可能取值,默认是从0开始,1递增;
我们也可以给它设置一个初始值,让他从你想要的值开始加1递增
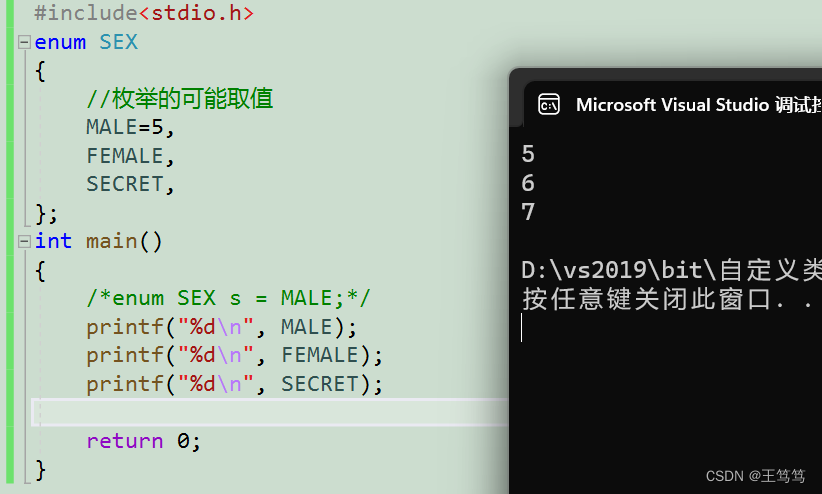
可以看到我们给MALE后面的值就会从5开始往后递增1;
那如果不给MALE赋值,而是给FEMALE赋值呢?

那么 就会从被赋值的枚举常量开始赋值,还是0默认为初始值。
既然枚举是默认从零开始,那在main函数中的枚举变量是否可以直接数字初始化呢?
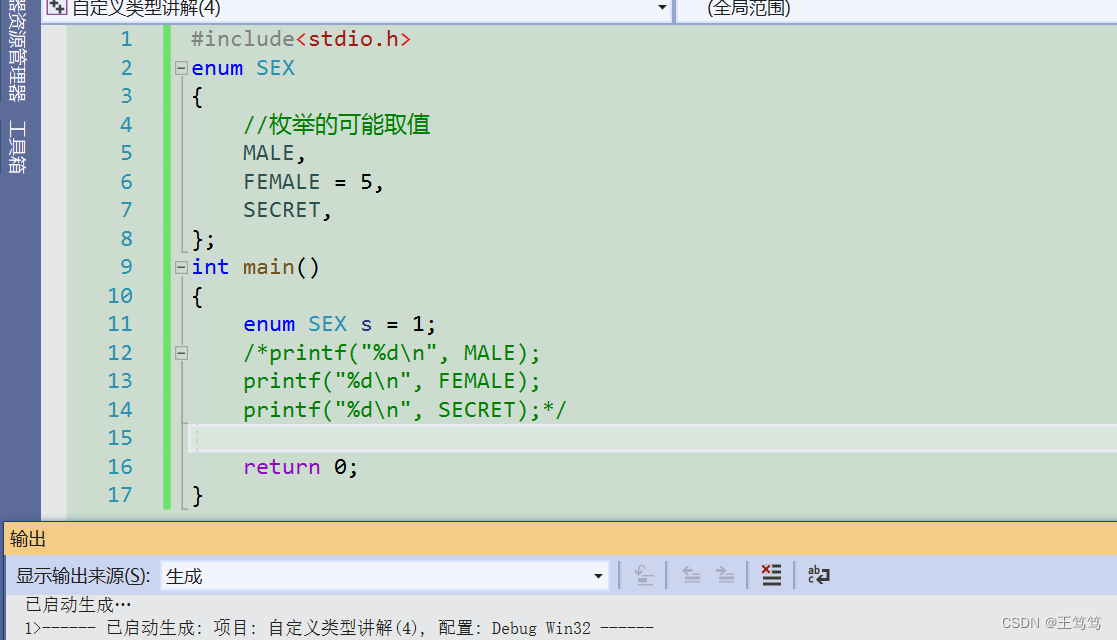
这里要注意的是我们,这样的写法在C语言是可以的,因为我们写C语言时创建的都是.C的文件
但是一旦到了C++的开发环境下,这样的写法就会出现错误
所以严谨一点,在给枚举变量赋值或者初始化时都要使用枚举常量。
1.1枚举优点
那枚举类型的好处是什么呢?
大家以前可能接触过一些c语言的小游戏,在开始的菜单时会提供选项和对应的内容供玩家选择
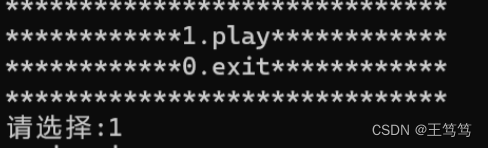
输入1就对应着游戏开始,数字0就对应着退出游戏,但是我们看到这样的代码时用数字和操作对应起来会有点别扭的感觉,我们不妨用枚举来提高代码的可读性;
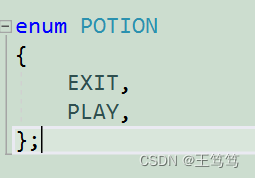
这样看到EXIT就是0;PLAY就是1;代码的可读性和可维护性提高了,也更加严谨。
我们同样可以使用#define对EXIT和PLAY
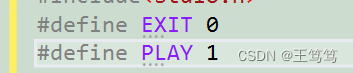
那这样与枚举类型有什么区别呢?
注意:#define的宏定义是没有规定类型的,而枚举是自带类型检查的,是枚举类型,并且用枚举的方式也便于我们调试,调试如下

并且相对于#define的宏定义也相对方便,不用一个一个的#define宏定义。
2.联合(共用体)
联合体又叫共用体,也是一种特殊的自定义类型
同样的联合体也有自己的关键词:union
和我们之前分享的struct、enum类似的关键字,都可以定义自定义类型
这种类型的变量同样也包含一系列成员,特征是这些成员公用同一块空间,所以联合体也叫共用体;具体是什么意思呢?我们从他们的空间大小来入手
上代码
#include<stdio.h>
union Un
{
char c;
int i;
};
int main()
{
union Un u;
printf("%d\n", sizeof(u));
return 0;
}和其他自定义类型相似的,有关键词有标签名,我们在成员中定义了两个变量;
char c占一个字节;
int i占四个字节
我们在main函数中输出他们的大小,可以预测一下它的大小;
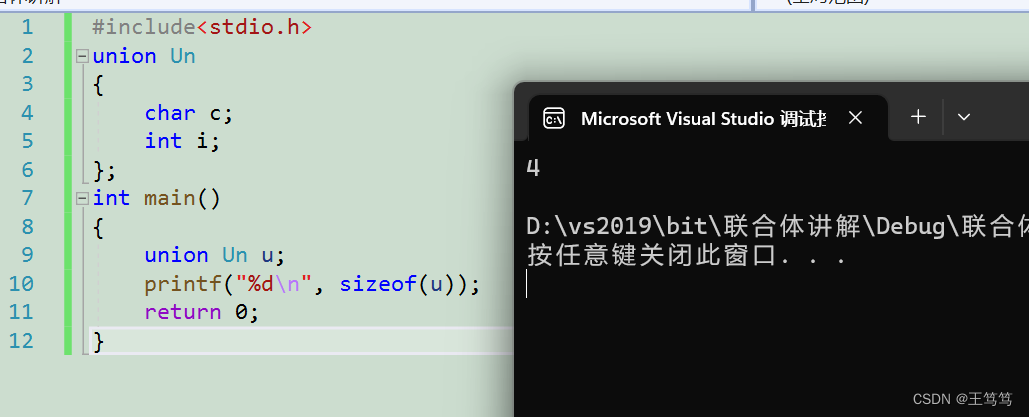
可以看到输出的联合体大小是4,是否和你预想的一样呢?
这时候问题来了,四个字节加上一个字节不是五个字节的大小吗?
我们不妨将他们的地址打印出来,通过地址来了解他们
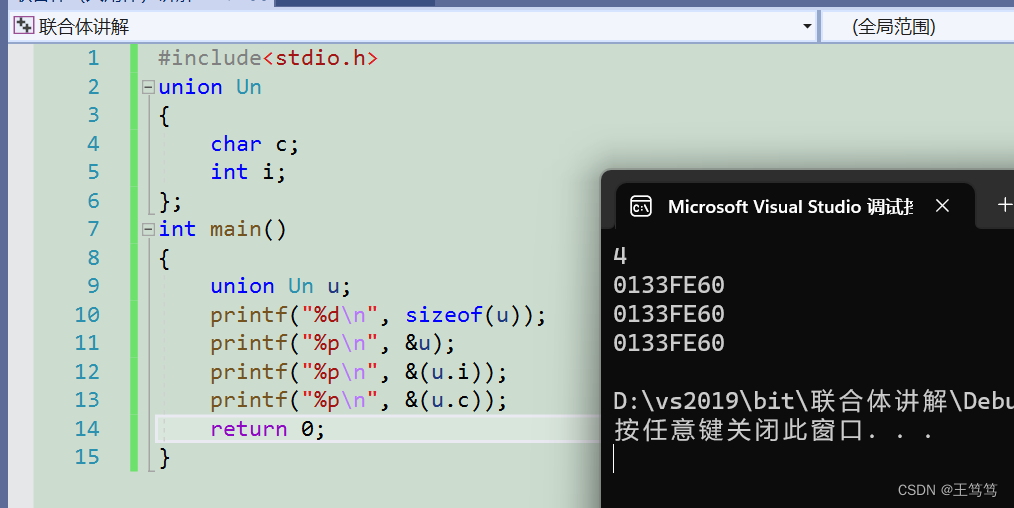
这下通过访问地址就一目了然
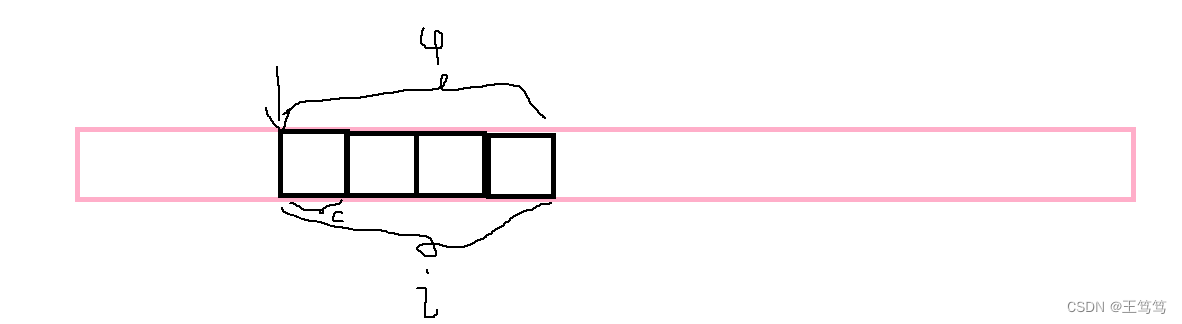
通过图例的意思就是这四个字节的空间是变量u的,变量u中,i也同样占了四个空间,而i的首地址与u的首地址相同,在一个位置上;同样的c只占了一个字节的空间,起始地址和u和i也同样在一起,这样我们就验证了共用体其实联合使用了一块空间。
这样在我们使用联合体的时候我们就会发现,我们只能同时使用联合体中的一个变量,因为他们所使用的是同一块空间,改变其中一个数据,另一个可能也会随之而改变。
2.1联合体的应用
既然只能同时使用一个联合体成员变量,我们不妨用大小端储存来举例子
大小端储存简单复习就是高低位字节数据的存放位置,小端储存方式就是将低位字节数据放到低地址,将高位字节数据放到高地址;大端储存方式相反,就是将地位字节数据放到高地址,将高位字节数据放到低地址;
之前的一种方法如下

1的二进制序列就是00 00 00 01,很显然1位于低位字节处,放在了低地址处,我们定义一个char类型的指针(访问一个字节),如果第一次访问的到并将其解应用等于1的话,那就是小端储存(低位字节数据放在低地址)。
那接下来使用联合体来判断大小端储存方式;
union Un
{
char c;
int i;
};
int main()
{
union Un u;
u.i = 1;
if (u.c == 1)
printf("小端\n");
else
printf("大端\n");
return 0;
}配合图示一齐讲解这串代码
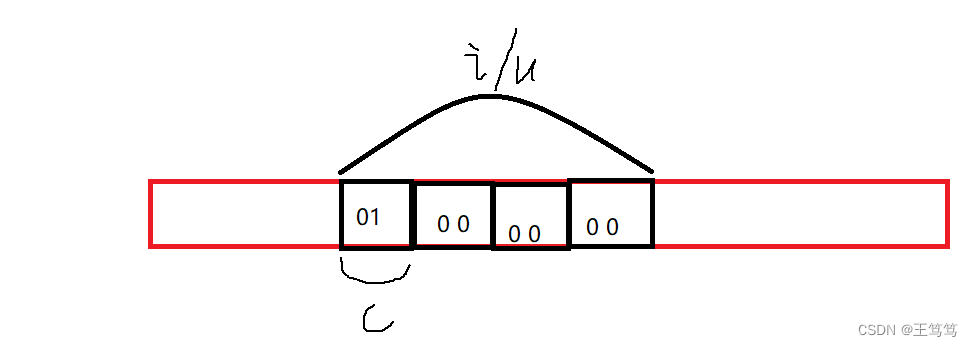
我们可以看到联合体变量中 i 所占空间最大,所以 u 就申请到了4个空间,同样的 i 也占了四个空间;
我们给这个空间存放int类型的数字1,占四个字节的空间,接下来我们用c来判断,因为 c 只占用一个字节,并且起始地址和i相同,如果这个 c 解应用等于1,那就是小端储存;
如果i中储存1的方式是00 00 00 01,这时 c 解应用为0,那么这就是大端储存方式;
代码运行起来看一下啊
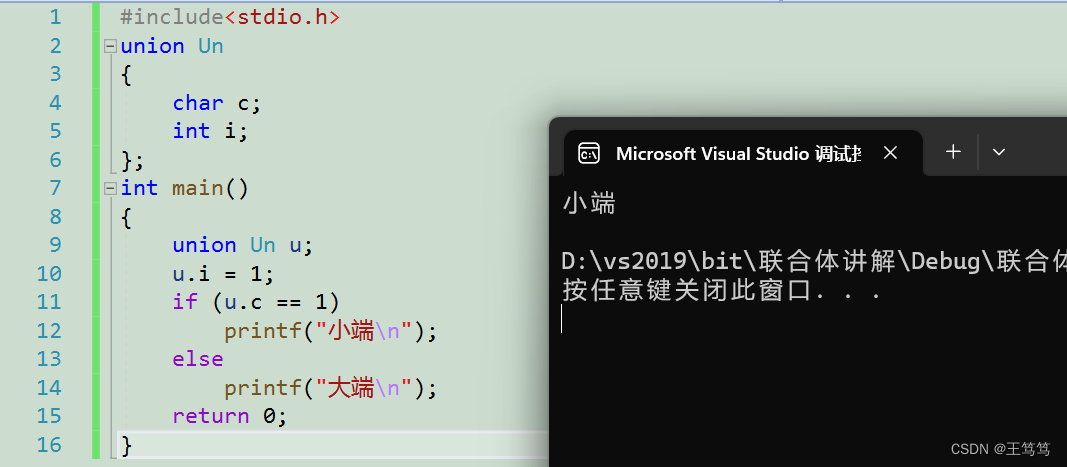
这就说明联合体的成员使用或者访问的就是同一块空间
还要注意的是联合体的大小至少是其中最大成员的大小,因为联合体变量申请的空间最小也要满足成员变量的空间。
2.2联合体的存放
用代码来引出联合体存放的问题
union Un
{
char arr[5];//占用5个字节
int n;//占用4个字节
};
int main()
{
printf("%d", sizeof(union Un));
return 0;
}我们可以预测一下输出的结果
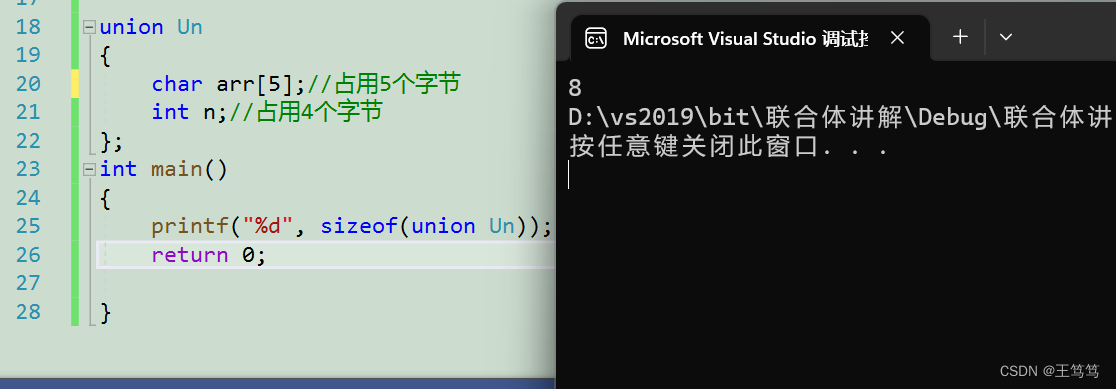
结果是否和你想的一样呢?
这样的结果反馈出了联合体的内存也需要对齐
其实也不难理解
char arr[5]是连续存放的,我们也可以将其理解为5个char类型的变量,然后根据上一章的内容找对齐数。char类型的对齐数是1,int类型的对齐数是4,默认对齐数必须是最大对齐数的整数倍,所以5个char类型的数据占据5个字节的空间(从零开始到四占了五个),四是int的倍数,刚好可以存放剩下int类型的字节空间,总共占据了8个空间。
所以在这里要更强调的一点是联合体的大小,至少是成员里最大成员的大小。
以上就是本次要分享的自定义类型讲解的内容,希望对你有所帮助。