1.作品介绍:
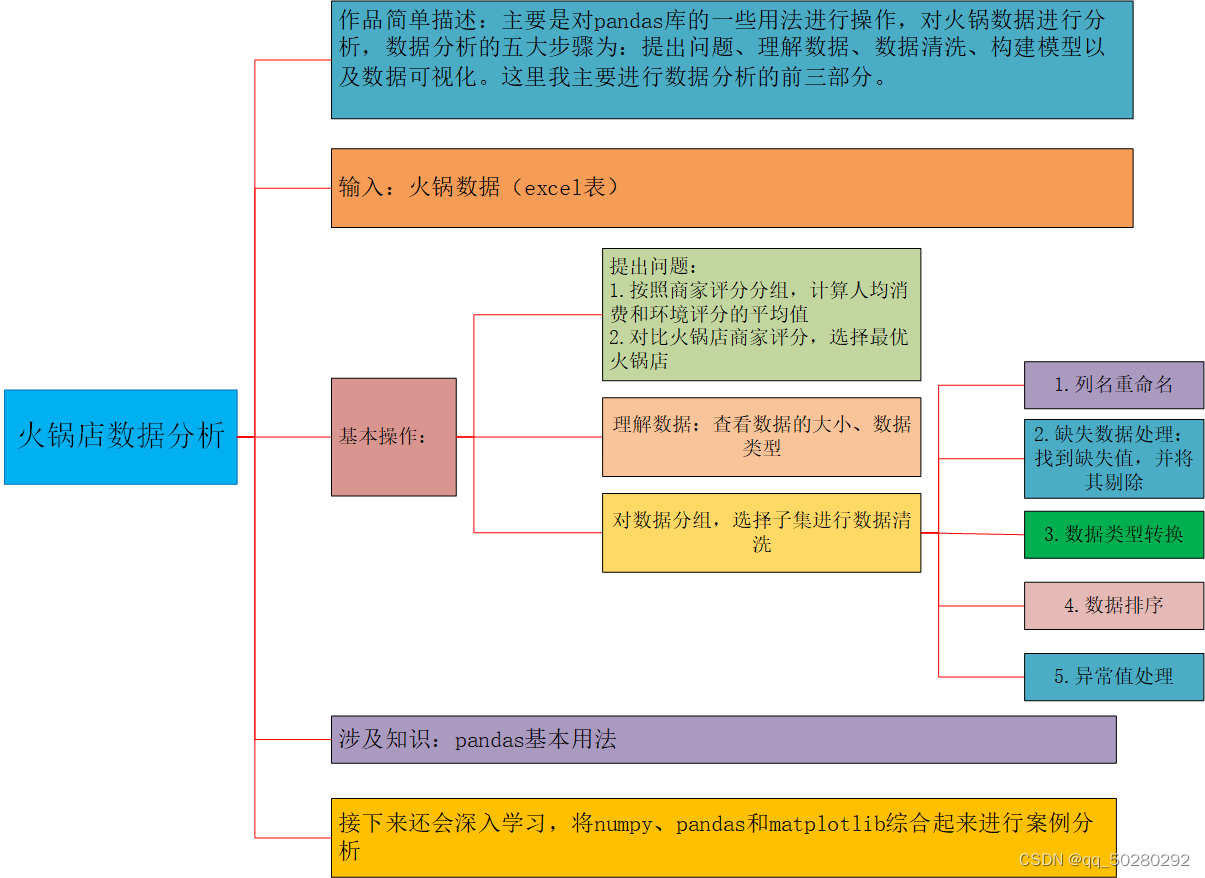
主要是对pandas库的一些用法进行操作,对火锅数据进行分析,数据分析的五大步骤为:提出问题、理解数据、数据清洗、构建模型以及数据可视化。这里我主要进行数据分析的前三部分。
2.思维导图
3.思路分析
3.1提出问题
(1)按照商家评分分组,怎样计算人均消费和环境评分的平均值?
(2)对比火锅店商家评分,如何选择最优火锅店?
3.2理解数据
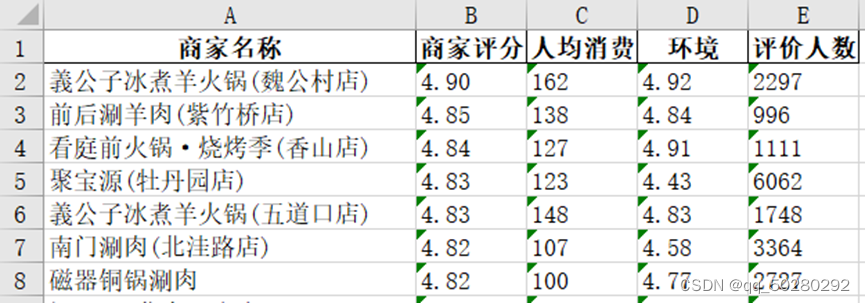
北京市火锅数据,里面主要包括五个字段,分别为商家名称、人均消费、商家评分、环境评价以及评价人数,分别查看数据的大小和类型。
3.3 选择子集进行数据清洗
1. 列名重命名
2. 缺失值处理
3. 数据转化类型
4. 数据排序
5. 异常值处理
4.程序代码
4.1 数据文件读取
import numpy as np
import pandas as pd
df=pd.read_excel('C:/Users/Administrator/Desktop/hotpot.xlsx')
print(df.head())
print(df.tail())
print(df.shape)
print(df.dtypes)
基本函数介绍:
| 函数名称 | 基本用法 |
|---|---|
| .read_excel | Pandas中用于读取excel表,有很多参数设置,例如sheet_name等 |
| .head | 用于显示表内容,默认显示前五行内容 |
| .tail | 用于显示表内容,默认显示前五行内容 |
| .shape | 用于查看表大小,结果为元组形式 |
| .dtypes | 用于查看表中数据类型,如int64、float64等 |
代码结果展示:
(1)前五行输出结果:
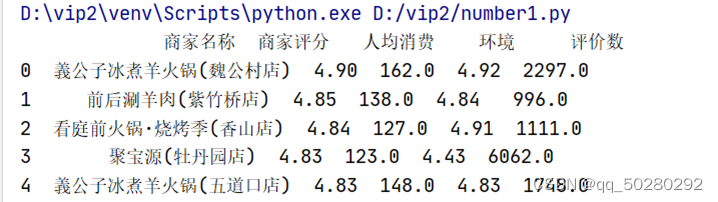 (2)后五行输出结果:
(2)后五行输出结果:
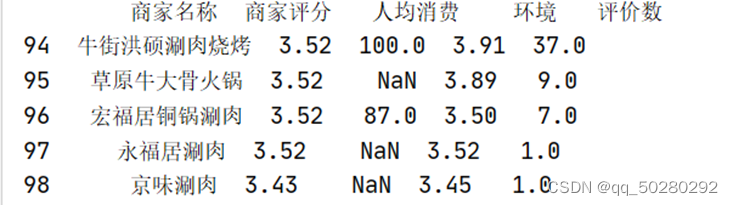
(3)查看数据大小:
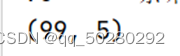
(4)查看数据类型:

4.2 选择子集进行数据清洗
subdf=df.loc[:,'商家评分':'评价数']
print(subdf.head())
基本函数介绍:
| 函数名称 | 基本用法 |
|---|---|
| .loc | 显示索引查看数据,可以使用切片操作 |
| .iloc | 隐式索引查看结果 |
| .ix | 混合式索引查看数据 |
3.2.1 在选择子集的基础上进行列名重命名
colnamedict={
'评价数':'评价人数'}
df.rename(columns=colnamedict,inplace=True)
print(df.head())
基本函数介绍:
| 函数名称 | 基本用法 |
|---|---|
| .rename | 用于对列重命名,参数inplace默认为false,df本身的列名没有变化;columns是列,可以将修改的名字写成字典格式 |
| .columns | df.columns=new_columns这是对全部列进行重命名,其中new_columns为列表或者元组 |
3.2.2 缺失值处理
print("删除缺失值前大小:",df.shape)
df=df.dropna(subset=['人均消费','评价人数'],how='any')
print("删除缺失值后大小:",df.shape)
基本函数介绍:
| 函数名称 | 基本用法 |
|---|---|
| .isnull | 用于判断缺失值,返回bool类型 |
| .notnull | 用于判断缺失值,返回bool类型 |
| .fullna | 用于填充缺失值,可以选择method参数,比如:method=’ffill’,表示从前往后填充缺失值 |
| .dropna | 用于剔除缺失值,默认为行,可以选择行或者列;how=’all’时表示删除全是缺失值的行(列);how='any’时表示删除只要含有缺失值的行(列); |
代码结果展示:

3.2.3 数据转化类型
df['评价人数']=df['评价人数'].astype(int)
print("转换后的数据类型为:\n",df.dtypes)
基本函数介绍:
| 函数名称 | 基本用法 |
|---|---|
| .astype | 用于转换数据类型,强制类型转换 |
| to_numeric()、to_datetime() | 也可以使用pandas中的函数进行转换 |
3.2.4 数据排序
print("排序前的数据集:")
print(df.head(3))
df=df.sort_values(by='人均消费',
ascending=True,
na_position='first')
print('排序后的数据集:')
print(df.tail())
基本函数介绍:
| 函数名称 | 基本用法 |
|---|---|
| .sort_values | 用于数据排序,其中参数by可以选择按照某一列进行排序;ascending参数表示升序还是降序;na_position参数表示缺省值在前面还是后面,默认是在前面 |
代码结果展示:


3.2.5 异常值处理
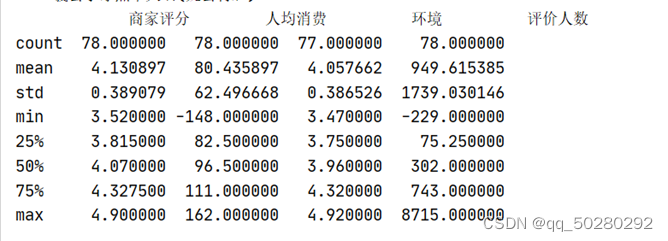
print(df.describe())
querySer=df.loc[:,'人均消费']>0
print("删除异值前:",df.shape)
df=df.loc[querySer,:]
print("删除异值后:",df.shape)
基本函数介绍:
| 函数名称 | 基本用法 |
|---|---|
| .describe | describe()函数就是返回这两个核心数据结构的统计变量,比如平均值、方差等 |
| .reshape | 替换异常值 |
代码结果展示: