目录
一. 前言
本小节将跟大家分享有关字符查找,错误信息报告,内存操作函数的功能与实现。
二. 正文
2. 1 字符查找
2.11 strstr
char * strstr ( const char * , const char * )
- 参数一: 被查找的主字符串
- 参数二: 需要查找的子字符串
功能:从主字符串中,寻找子字符串,如果不存在返回空指针;若存在则返回子字符串在主字符串中首元素的地址。
代码实现如下:
char* my_strstr(const char* p1, const char *p2)
{
assert(p1 && p2);
char* cnt = p1;
char* cur = p2;
while (*cnt)
{
char* room = cnt;
while (*cnt && *cnt == *cur)
{
cnt++;
cur++;
if (*cur == '\0')
{
return room;
}
}
cnt = room; // 如果不匹配就重新指向进入判断的起点
cur = p2; // 如果不匹配就重新指向进入的起点
cnt++;
}
return NULL;
}
int main()
{
char a[20] = "ahuangCCChinaahuang";
char b[20] = "China";
printf("%s\n", my_strstr(a, b));
return 0;
}2.12 strtok
char * strtok ( char * str, const char * sep );
返回类型是char* ,如果找到分割符后会返回这一段字符串的首字母的地址。
- 参数一: 是要分割的字符串。(一般要创建一个临时字符数组,因为需要将标记字符替换为“\0”,会修改数据,但我感觉会有性能损失)
值得注意的是: 第一次进行strtok时,输入字符串指针,分割一次;第二次使用时,则参数一输入NULL,因为里面会有一个static 修饰的变量,会保存分割符下一个字符的地址。
- 参数二: sep是分割符的集合字符串。
运用代码可以这样写:
int main()
{
char a[30] = "[email protected]";
char copy[30] = { 0 };
strcpy(copy, a);
char* tok = "@.";
char *pro = NULL;
// 利用该函数会保存分割符号下一个字符指针的特性
for (pro = strtok(copy, tok); pro != NULL; pro = strtok(NULL, tok))
{
printf("%s\n", pro);
}
return 0;
}2.13 atoi函数
int atoi( const char *string );
- 功能: 将字符串转化为数字,例如:“123455” 转化为123455; “-126432”转为-126432; “123.432" 转为 123。
- 实现思路:如果遇到空格符跳过,然后遇到正负符号保存,接着读取字符内容,如果不在'0' ~'9'就不是数字字符,即停止循环,返回0。
功能实现:
#include<stdio.h>
#include<limits.h>
int my_atoi(const char* str)
{
int sign = 1;
// 跳过空格
while (*str == ' ')
{
str++;
}
// 找出正负
if (*str == '-' || *str == '+')
{
if (*str == '-')
{
sign = -1;
}
str++;
}
// 开始转化
int sum = 0;
while (*str <= '9' && *str >= '0')
{
sum = 10 * sum + (*str - '0');
if (sum < 0 && sign == 1) // 正数超出
{
sum = INT_MAX;
break;
}
else if (sum < 0 && sign == -1) // 负数超出
{
sum = INT_MIN;
break;
}
str++;
}
return sum * sign;
}
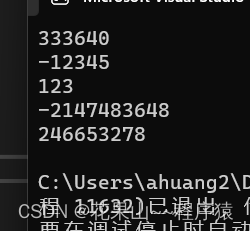
int main()
{
char* s1 = "333640";
char* s2 = "-12345";
char* s3 = "123.3113";
char* s4 = "-8362865623872387698";
char* s5 = "+246653278";
printf("%d\n", my_atoi(s1));
printf("%d\n", my_atoi(s2));
printf("%d\n", my_atoi(s3));
printf("%d\n", my_atoi(s4));
printf("%d\n", my_atoi(s5));
return 0;
}结果:
2.2 错误信息报告
我们在编写程序时,调用库函数失败后,会返回错误码(errno), 一般我们想要获取错误码时,需要一个头文件(#inlcude <errno.h>), 里面会有一个全局变量 errno 用来接收错误码的。
strerror功能是将编号转化为对应错误信息的首字母地址。
运用代码如下:
#include<stdio.h>
#include<errno.h> // 当我们需要用errno接收错误码时,需要的头文件
#include<stdlib.h>
#include<string.h>
#include<limits.h> // 可以调出整型数据范围的头文件
int main()
{
printf("%s\n", strerror(errno));
printf("%s\n", strerror(2));
printf("%s\n", strerror(3));
printf("%s\n", strerror(4));
int* a = (int*)malloc(sizeof(int) * INT_MAX);
if (a == NULL)
{
perror("malloc"); //perror("自定义内容")
}
return 0;
}这里对strerror函数和perror函数作一些区别:
strerror函数的参数是错误码,然后转化为对应错误消息首字符的地址,而perror则是保存最近一次错误码(因此错误码会被迭代),然后打印 自定义字符串部分和错误码对应错误信息。
2.3 内存操作 函数
头文件:#include<string.h>
2.31 memcpy
void * memcpy ( void * destination, const void * source, size_t num );
destination : 拷贝开始的起始地址
source: 被拷贝的起始地址
num : 拷贝内容的字节数
- 函数memcpy从source的位置开始向后复制num个字节的数据到destination的内存位置。
- 这个函数在遇到 '\0' 的时候并不会停下来。
- 如果source和destination有任何的重叠,复制的结果都是未定义的
核心思维:是在内存中一个字节一个字节拷贝数据。我们可以回想,strcpy其能拷贝字符串,但不能拷贝其他数据,而memcpy则是拷贝指定内存的任何数据。
运用代码如下:
#include<stdio.h>
#include<string.h>
int main()
{
int a[30] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int b[30] = { 0 };
memcpy(b, a, 16); // %s是对字符串数据进行打印,则进行监视。
return 0;
}结果:

实现代码如下:
#include<stdio.h>
#include<string.h>
#include<assert.h>
// 自己模拟实现的函数不能实现p1与p2区域覆盖原地拷贝的情况
// 但c语言的库函数memcpy可以实现原地覆盖拷贝
void* my_memcpy(void* p1, const void* p2, int count)
{
assert(p1 && p2);
void* ret = p1;
while (count--)
{
*(char*)p1 = *(char*)p2;
p2 = (char*)p2 + 1;
p1 = (char*)p1 + 1;
}
return ret;
}
int main()
{
int a[30] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int b[30] = { 0 };
my_memcpy(b, a, 16);
return 0;
}
2.32 memmove-- 内存移动
void * memmove ( void * destination, const void * source, size_t num );
memmove函数跟memmove函数差不多,只是能更好的解决本地覆盖拷贝情况。
实现过程中我们会发现三种情况:


实现代码如下:
void* my_memmove(void* p1, void* p2, int count)
{
assert(p1 && p2);
void* ret = p1;
if (p1 > p2) // 后->前
{
while (count)
{
*((char*)p1 + count) = *((char*)p2 + count);
count--;
}
}
else // 前->后
{
while (count--)
{
*(char*)p1 = *(char*)p2;
p1 = (char*)p1 + 1;
p2 = (char*)p2 + 1;
}
}
return ret;
}
int main()
{
int a[30] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
//3 4 5 6 5 6 7 8 9 10
int b[30] = { 0 };
my_memmove(a, a + 2, 16); // %s是对字符串数据进行打印,这里我们通过监视查看。
return 0;
}2.33 memcmp--内存比较
int memcmp ( const void * ptr1, const void * ptr2, size_t num );
返回值: ptr1 > ptr2 返回1
ptr1 < ptr2 返回-1
ptr1 == ptr2 返回0
其核心思想就是,数据在内存中存储(默认为小端),进行一个字节一个字节的比较。
运用代码如下:
#include<stdio.h>
#include<string.h>
int main()
{
int a[10] = { 1, 2, 3,4 };
int b[10] = { 1,2 ,3, 0x11223305};
printf("%d\n", memcmp(a, b, 13));
return 0;
}我们查看内存如下:


由以上两图可知在第12个字节时还相同,但在13个位时已经小于。
2.34 memset---内存设置
void *__cdecl memset(void *_Dst, int _Val, size_t _Size);
_Dst: 目标数据的起始地址。
_Val: 替换为的数
_Size: 字节数
功能: 将指定内存范围内的数据全部覆盖为_Val
功能应用:
#include<stdio.h>
#include<string.h>
int main()
{
int a[10] = { 1, 2, 3, 4, 5,6 };
memset(a, 1, 12); // 在小端字节上运行
return 0;
}
内存如下:

可知从首地址后的12个字节全部覆盖为1。
三. 结语
本小节到此结束,感谢小伙伴的浏览,如果有什么疑问欢迎大家在评论区评论。