学习笔记,以李宏毅的视频讲解为主,chatGPT的官方博客作为补充。
自己在上古时期接触过人工智能相关技术,现在作为一个乐子来玩,错漏之处在所难免。
若有错误,欢迎各位神仙批评指正。
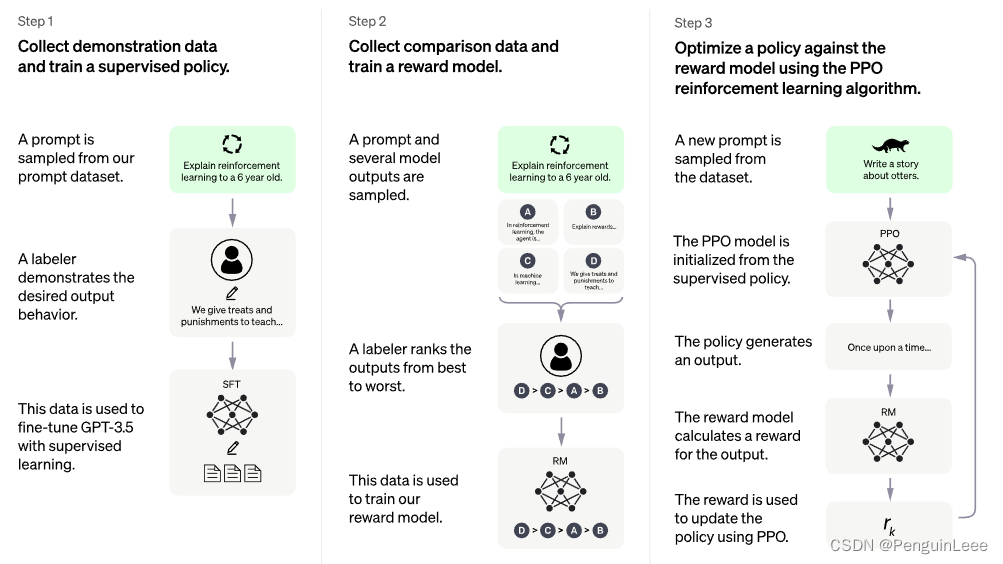
chatGPT的训练分为四个阶段:
- 给一段不完整的话,让基线模型(GPT3)学习怎么接话茬子。这个步骤基于GPT3进行fine-tuning。
- 弄一个人工标注的数据集,对1中的模型进行训练,通过人工数据集让GPT3了解人类的喜好。
- 基于另一个人工标注的数据集(包括问题、答案和人类打的分)训练一个打分模型,其功能主要在于:输入问题和答案,让打分模型根据排序进行打分。
- 用PPO让基线模型和打分模型进行对抗,优化GPT3,得到chatGPT。

首先,chatGPT从网上找大量的语料学习怎么说话,其方式为文字接龙,即根据前面已有的句子成分来说下面的话。这个过程是无监督的。
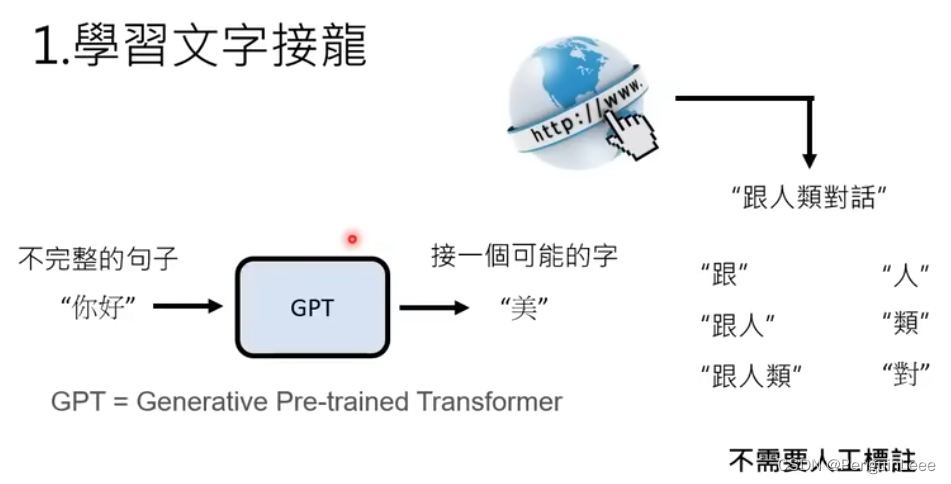
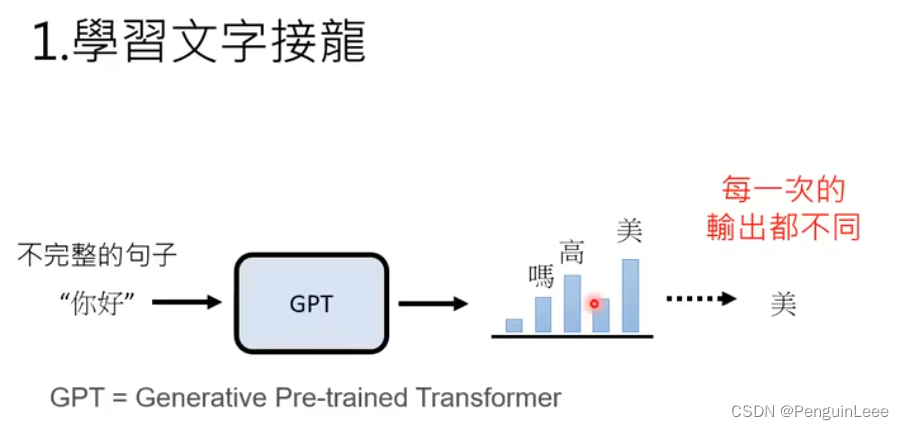
但是,即使我们知道了半句话,这半句话的后面也可以接很多东西,所以输出的是一个概率分布。GPT模型要输出字的话,就从概率分布里采样。
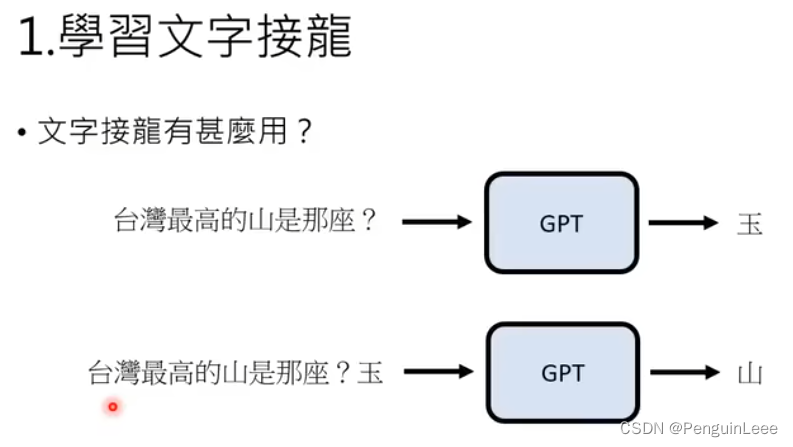
学习文字接龙的用处在于,给GPT一段话它就可以续写,续写的一种可能就是回答问题了。
但是,GPT的输出是随机的,通过网上的语料进行学习,什么话都可能被这玩意拿来接。一个典型的例子是下图:
于是问题变成引导GPT产生有用的输出。
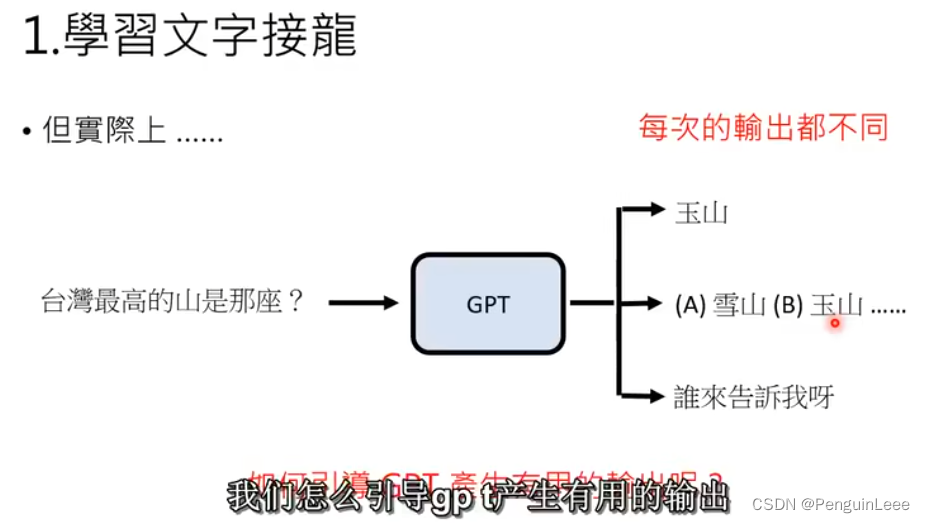
如何进行引导?让人类引导文字接龙的方向。通过引入一个人工标注的数据集,里面都是问题-答案,从而告诉GPT人类的偏好是什么。

这样的人工标注的问题-答案不需要太多,几万个足够。
本来chatGPT就有能力生成这些答案,但是需要让它知道并模仿人类的喜好。
第三步,训练一个新的Teacher model,数据集中的元素主要包括:一个问题和几个针对这个问题的答案,每个答案都打了分。
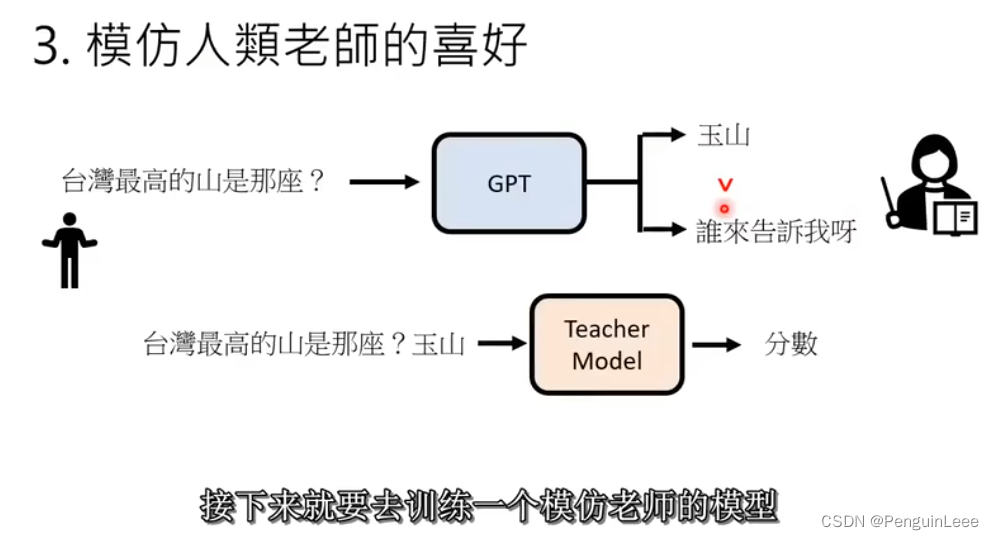
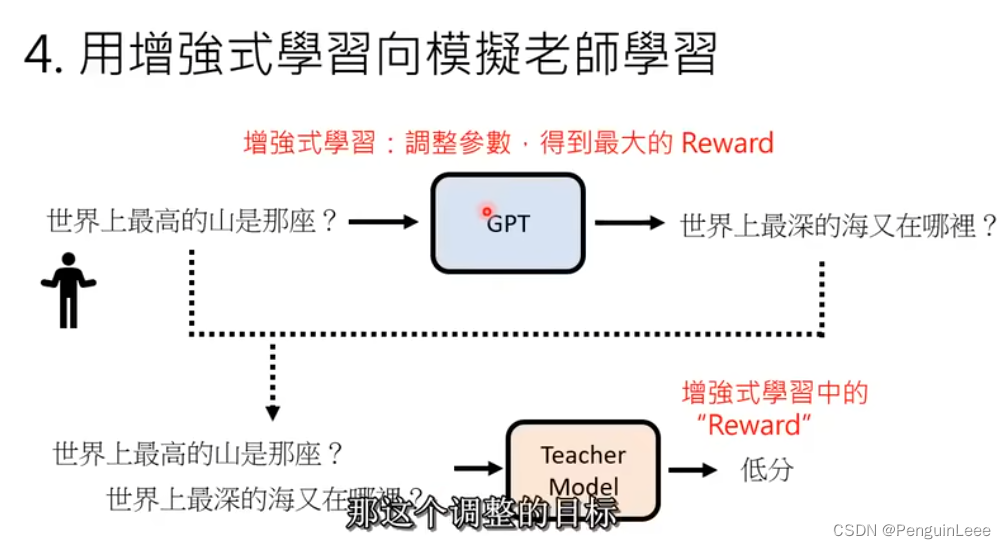
最后,用强化学习PPO算法让GPT和Teacher model进行对抗。
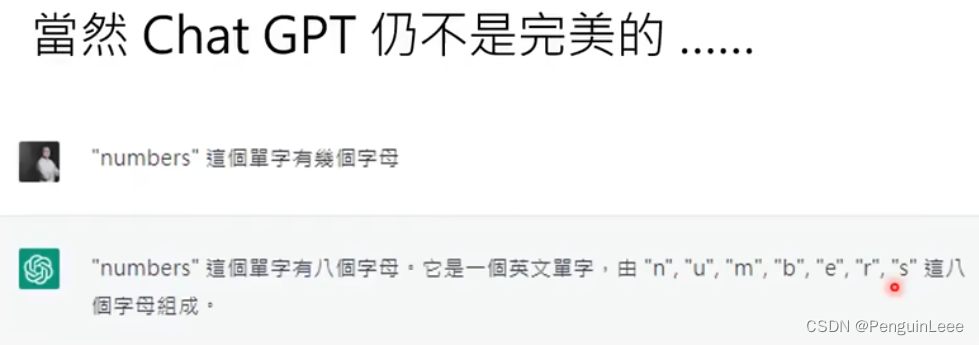
chatGPT仍然不是完美的。本质上,它还是学习了两点:人类怎么说话和人类的偏好。ChatGPT根据人的偏好来说话。
在使用中的一个比较致命的点:让它找文献的时候它存在一定的概率瞎编几个。
再比如,可以用一些冷门问题(没有涵盖在2和3的数据集中的问题)来头吸:
下图是openAI给出的插头GPT的训练图。