系列文章目录
Java集群实战:单体架构升级到集群架构(一)使用NGINX建立集群
Java集群实战:单体架构升级到集群架构(二)实现session共享
Java集群实战:单体架构升级到集群架构(三)上传文件的共享
Java集群实战:单体架构升级到集群架构(四)使用REDIS分布式锁
缓存在高并发的场景下可以大大提升读取数据的性能。缓存的工作原理是先从缓存中读取数据,如果有数据则直接返回给用户;如果没有数据则从数据库中读取实际数据并且将数据放入缓存,最后将数据返回给用户。
在高并发场景下,缓存的使用有点复杂。我们这里写的代码比较适合高并发场景,如果您的业务没有高并发海量数据的话,就可以写简单一些。
我们用一个简单的商品数据库为例子,来讨论缓存REDIS的使用。
源码地址
整个项目的代码在GITHUB: https://github.com/Dengxd/JavaCluster 所有源码都在这里,GitHub经常连不上,要多刷新几次
主要的业务功能都是在类GoodsServiceImpl中,所以我们重点介绍这个类
缓存有效期、缓存预热和缓存击穿
先看代码,这是类GoodsServiceImpl中的一个方法:
public static Integer getExp(){
Random r =new Random();
return REDIS_EXP+r.nextInt(3600);
}这段代码生成一个36000到39600之间的随机数,做为缓存有效期,单位是秒。当然具体的数值大家可以根据自己的业务情况改变。
数据库中,经常被访问的数据我们称为“热点数据”,没人访问的数据就称为“冷门数据”。缓存中的冷门数据过了有效期就被自动删除,而热点数据被访问的时候我们会更新它的有效期,所以保留在缓存中的大多数都是热点数据,这样可以节省空间。
为什么使用随机数,不使用固定数值呢?一般我们在系统启动的时候,会把热点数据从数据库中读取出来,放到缓存中,这个叫做“缓存预热”。如果使用固定数值做为有效期,有效期一到,这些热点数据就可能同时被自动删除。那么大量访问热点数据的请求,都要去数据库中取数据,加大了数据库的压力。这个就是“缓存击穿”。缓存击穿指的是数据库中有数据,但是缓存中没有数据。如果使用随机数就不会在同一时刻出现大量的缓存击穿。
缓存穿透
缓存穿透是指查询不存在的数据,因为缓存和数据库中都没有这个数据,所以缓存和数据库都要查一次。如果有黑客发出大量的这种查询请求,数据库可能就撑不住了。
解决方法就是当数据库也找不到数据时,在缓存中加入一个空对象,如下所示:
goods = this.getById(id); //到数据库中查找这个id
if (goods != null) {//数据库找到数据
//加入缓存
bucket.set(JSON.toJSONString(goods), getExp(), TimeUnit.SECONDS);
} else { //数据库中找不到数据
//对这个ID,在缓存中加入空对象“{}”
bucket.set(NODATA, getNoDataExp(), TimeUnit.SECONDS);
}
这段代码在类GoodsServiceImpl的get方法中。比如用户查询ID为0的商品,我们数据库中没有,我们就把ID为0空对象“{}”加入缓存中。
下次用户再发起ID为0的查询请求,我们在缓存中找到这个ID,发现缓存中的数据是“{}”,我们就返回一个新对象,所有字段都是NULL,不用再去查数据库,减轻了数据库的负担。这段代码在类GoodsServiceImpl的getFromRedis方法中,如下所示:
if(NODATA.equals(strGood)){ //缓存中的数据是“{}”
bucket.expire(getNoDataExp(),TimeUnit.SECONDS);//更新有效期
return new Goods();//返回一个新对象,所有字段都是NULL
}
热点数据重建缓存和双重检测锁
我们来考虑一个特殊场景,一个大V有众多粉丝,他向粉丝推荐了一款冷门商品(没在缓存中),成千上万的粉丝立刻查询这款商品,缓存查不到,于是都到数据库中查(又是缓存击穿),查到数据之后,再往缓存中写。同时来一千个用户,就查一千次数据库,再写一千次缓存,是不是很过份?所以我们要加一个分布式锁,只让第一个用户查数据库,写缓存,写完缓存之后,其他用户就全部到缓存中取数据了。
这段代码在GoodsServiceImpl的get方法中:
goods=getFromRedis(bucket,key);
if(goods!=null){ //缓存中有数据
return goods; //直接返回了
}
//缓存中没数据
//加一个分布式锁,只让第一个用户查数据库,写缓存
RLock createCacheLock=redissonClient.getLock(PREFIX_LOCK_CREATE_CACHE+id);
createCacheLock.lock();
try{
//因为第一个用户已经把数据加到缓存中了,
//所以第二个用户,第三个用户,……,第N个用户,
//得到锁之后,再到缓存中找一次
goods=getFromRedis(bucket,key);
if(goods!=null){ //缓存中已经有数据了
return goods; //直接返回
}
//缓存中没找到数据,恭喜你,你是第一个用户,
//下面的代码,查数据库,写缓存
。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。
这个就是臭名昭著的双重检测锁,因为在上锁之前查一次缓存,得到锁之后还要再查一次缓存,所以叫双重检测。至于臭名昭著,那是因为它太难理解了,把很多童鞋绕得晕头转向。在没有互联网的年代,我只在操作系统的代码中看到过他。现在在互联网业务中看到他,我感觉我见到了下凡的神仙。
要是大家不理解也没关系,照抄就是了。这些代码就相当于一个模板,可以直接套用到我们自己的项目中。
双写不一致
“双写”指的是两个线程同时写数据库和缓存,“不一致”指的是缓存和数据库的内容不一致。看下面这张图:
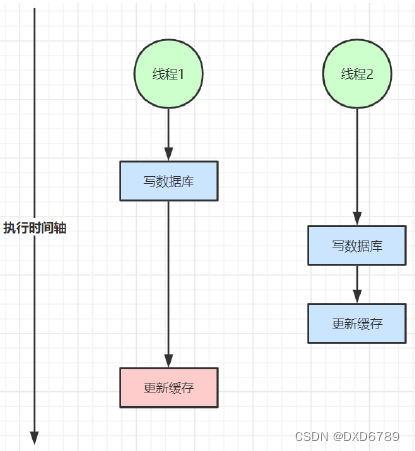
两个线程都是先写数据库再更新缓存,假设线程1是把商品价格改为1元,线程2 是把商品价格改为2元。线程1先写数据库,把数据库中的价格改为1元,然后他卡顿了。这时线程2开始写数据库,把数据库中的价格改为2元,然后线程2更新缓存,把缓存中的价格改为2元。最后线程1不卡了,继续执行,把缓存中的价格改为1元。
问题出现了,数据库中的价格是2元,缓存中的价格是1元,这就是双写不一致。
如果您的业务可以容忍这种不一致,那么缓存一过期,缓存中的数据被清掉,就不存在不一致了。如果你的业务一定要保证数据库缓存一致,那么我们只好再加锁。
读写锁
这回加的锁是读写锁,读写锁的好处是多个读锁可以一起执行,这比较适合读多写少的互联网应用。写锁和读锁是互斥的,写锁和写锁也是互斥的。也就是说,如果一个读锁得到了锁,其他读锁也可以继续执行,但是写锁就必须等待。如果一个写锁得到了锁,其他所有的锁都得等待。
我们把读锁加在读数据库的地方,把写锁加在增加、修改、删除数据库的地方。
读锁代码如下:
//读取数据库,用读锁
RReadWriteLock updateLock=redissonClient.getReadWriteLock(PREFIX_LOCK_UPDATE+id);
RLock rLock=updateLock.readLock();
rLock.lock();
写锁代码如下:
//修改数据库,用写锁
RReadWriteLock updateLock=redissonClient.getReadWriteLock(PREFIX_LOCK_UPDATE+goods.getId());
RLock wLock=updateLock.writeLock();
wLock.lock();
缓存雪崩
缓存雪崩指的是缓存层支撑不住或宕掉后,大量请求都会打到存储层, 存储层的调用量会暴增,造成存储层也会级联宕机,那么依赖缓存和存储层的服务也会出现问题,就象雪崩一样,造成整个系统崩溃。常见的解决方法就是限流或使用缓存集群。