目录
引言
对于新手来说,首先要理解线程的概念以及为什么需要采用多线程进行编程。什么是线程呢?网上一般都是这样定义的:线程(thread)是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。是不是听的一脸懵,我觉得这样的定义纯粹是自说自话,新手看完了一脸懵逼。那么我们可以用白话进行解释一下:
- 假如你经营一家物业管理公司。最初,业务量很小,每件事都需要你亲力亲为,给隔壁老王家修完暖气管道,立马再去老李家换灯泡——这叫单线程,所有的工作都得顺序执行;
- 后来业务拓展了,你雇佣了几个工人,这样你的物业公司就可以同时为多位客户提供服务了——这叫多线程,你是主线程;
- 工人们使用的工具是物业管理公司提供的,大家共享——这叫多线程资源共享;
- 工人们在工作中都需要管钳,可是管钳只有一把——这叫冲突。
- 解决冲突的办法有很多,比如排队、等同事用完后的电话通知等——这叫线程同步;
- 业务不忙的时候,你就在办公室喝喝茶,下班时间一到,你群发微信,所有的工人不管手头上的工作是否完成,都立马撂下工具走人。因此如果有必要,需要避免不要在工人正忙着的时候发送下班的通知——这叫线程守护属性设置和管理;
- 再后来,你的公司是规模扩大了,同时为很多生活社区服务,你在每个生活社区设置了分公司,分公司由分公司经理管理,运营机制和你的总公司几乎一模一样——这叫多进程,总公司叫主进程,分公司叫子进程;
- 总公司以及各个分公司之间,工具都是独立的,不能借用、混用——这叫进程间不能共享资源。各个分公司之间可以通过专线电话联系——这叫管道。各个分公司之间还可以通过公司公告栏交换信息——这叫共享内存;
- 分公司可以跟着总公司一起下班,也可以把当天的工作全部做完之后再下班——这叫守护进程设置。
1 多进程
python实现多进程的方法主要有两种:os模块下的fork方法、multiprocessing模块。前者只适用于Unix/Linux系统,后者则是跨平台的实现方式。
1.1 fork方式
import os
# 注意,fork函数,只在Unix/Linux/Mac上运行,windows不可以
pid = os.fork()
if pid == 0:
print('哈哈1')
else:
print('哈哈2')注意:fork()函数只能在Unix/Linux/Mac上面运行,不可以在Windows上面运行。
说明:
- 程序执行到os.fork()时,操作系统会创建一个新的进程(子进程),然后复制父进程的所有信息到子进程中;
- 然后父进程和子进程都会从fork()函数中得到一个返回值,在子进程中这个值一定是0,而父进程中是子进程的 id号。
在Unix/Linux操作系统中,提供了一个fork()系统函数,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。子进程永远返回0,而父进程返回子进程的ID。
这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。我们可以通过os.getpid()获取当前进程ID,通过os.getppid()获取父进程ID。
那么,父子进程之间的执行有顺序吗?答案是没有!这完全取决于操作系统的调度算法。
而多次fork()就会产生一个树的结构:
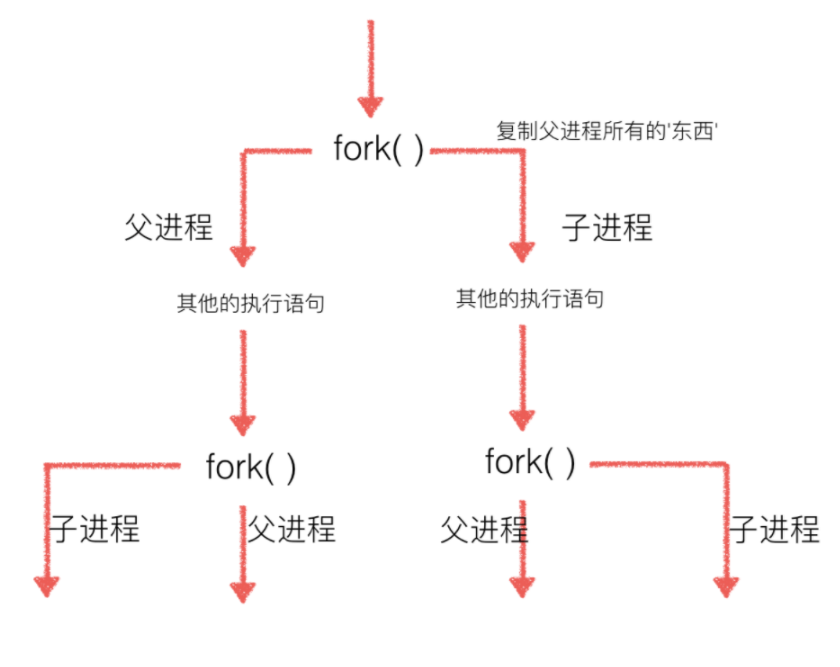
1.2 multiprocessing方式
multiprocessing提供了一个Process类来描述一个进程对象。创建子进程时,只需要传入一个执行函数和函数的参数;用start ()方法启动进程,用join ()方法实现进程间的同步:
import os
from multiprocessing import Process
def run_proc(name):
print("Child process (%s) (%s) running..." % (name, os.getpid()))
if __name__ == '__main__':
print("Current process (%s) start..." % (os.getpid()))
for i in range(5):
p = Process(target=run_proc, args=str(i))
print("Process will start.")
p.start()
p.join()
print("Process end.")
输出结果为:
Current process (26811) start...
Process will start.
Process will start.
Process will start.
Child process (0) (26872) running...
Process will start.
Child process (1) (26874) running...
Process will start.
Child process (2) (26876) running...
Child process (3) (26882) running...
Child process (4) (26885) running...
Process end.1.3 Pool方式
使用Process方法的不足在于需要启动大量的子进程,只能适用于被操作对象数目不大的情况,而使用Pool便能解决这一问题。简单说来,Pool可以指定进程的数量,默认为CPU的核数,同一时候最多有指定数量的进程执行:
import os, time, random
from multiprocessing import Pool
def run_task(name):
print("Task %s (pid = %s) is running..." % (name, os.getpid()))
time.sleep(random.random() * 3)
print("Task %s end." % name)
if __name__ == '__main__':
print("Current process (%s) start..." % (os.getpid()))
p = Pool(processes=3)
for i in range(5):
p.apply_async(run_task, args=(i, ))
print("Waiting for all subprocess done...")
p.close()
p.join()
print("All subprocess done.")
输出结果为:
Current process (4202) start...
Waiting for all subprocess done...
Task 0 (pid = 4255) is running...
Task 1 (pid = 4256) is running...
Task 2 (pid = 4257) is running...
Task 0 end.
Task 3 (pid = 4255) is running...
Task 2 end.
Task 4 (pid = 4257) is running...
Task 4 end.
Task 1 end.
Task 3 end.
All subprocess done.需要注意的是Pool对象调用 join ()方法会等待所有子进程执行完毕,调用join () 之前必须调用close ();调用close ()之后就不能继续添加新的Process。
1.4 进程间通信
Python提供了多种进程间通信的方式,本文主要讲Queue和Pipe这两种。
1 Queue
主要用于多个进程间的通信,操作如下:
- 在实例化Queue类,可以传递最大消息数,如q = Queue(5),这段代码是指只允许消息队列中最大有5个消息数据。如果不加最大消息数或数量为负值,则表达不限制数量直到占满内存;
- Queue.qsize():返回当前队列包含的消息数量;
- Queue.empty():如果队列为空,返回True,反之False ;
- Queue.full():如果队列满了,返回True,反之False;
- Queue.get([block[, timeout]]):获取队列中的一条消息,然后将其从列队中移除,block默认值为True;
- 如果block使用默认值,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了timeout,则会等待timeout秒,若还没读取到任何消息,则抛出”Queue.Empty”异常;
- 如果block值为False,消息列队如果为空,则会立刻抛出”Queue.Empty”异常;
- Queue.get_nowait():相当Queue.get(False);
- Queue.put(item,[block[, timeout]]):将item消息写入队列,block默认值为True;
- 如果block使用默认值,且没有设置timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了timeout,则会等待timeout秒,若还没空间,则抛出”Queue.Full”异常;
- 如果block值为False,消息列队如果没有空间可写入,则会立刻抛出”Queue.Full”异常;
- Queue.put_nowait(item):相当Queue.put(item, False);
为了更好地说明利用Queue进行通信,举例如下:在父进程中创建三个子进程,其中两个子进程往Queue中写入数据,另一个子进程从Queue中读取数据。
import os, time
from multiprocessing import Process, Queue
"""Write to process."""
def proc_write(q, urls):
print("Process (%d) is writing..." % os.getpid())
for url in urls:
q.put(url)
print('Put %s to queue...' % url)
time.sleep(0.1)
"""Read form process."""
def proc_read(q):
print("Process (%d) is reading..." % (os.getpid()))
while True:
url = q.get(True)
print("Get %s from queue." % url)
if __name__ == '__main__':
# 创建父进程
q = Queue()
writer1 = Process(target=proc_write, args=(q, ['张飞', '黄忠', "孙尚香"]))
writer2 = Process(target=proc_write, args=(q, ['马超', '关羽', "赵云"]))
reader = Process(target=proc_read, args=(q, ))
# 启动
writer1.start()
writer2.start()
reader.start()
writer1.join()
writer2.join()
# 读操作是死循环,必须强行终止
reader.terminate()
输出结果为:
Process (19307) is writing...
Put 张飞 to queue...
Process (19308) is writing...
Put 马超 to queue...
Process (19309) is reading...
Get 张飞 from queue.
Get 马超 from queue.
Put 黄忠 to queue...
Get 黄忠 from queue.
Put 关羽 to queue...
Get 关羽 from queue.
Put 孙尚香 to queue...
Get 孙尚香 from queue.
Put 赵云 to queue...
Get 赵云 from queue2 Pipe
Pipe()返回两个连接对象代表Pipe的两端,每个连接对象都有send()方法和recv()方法。
但是如果两个进程或线程对象同时读取或写入管道两端的数据时,管道中的数据有可能会损坏。当进程使用的是管道两端不同的数据则不会有数据损坏的风险。
import os, time
from multiprocessing import Process, Pipe
def proc_send(p, urls):
print("Process (%d) is sending..." % os.getpid())
for url in urls:
p.send(url)
print('Send %s...' % url)
time.sleep(0.1)
def proc_recv(p):
print("Process (%d) is receiving..." % (os.getpid()))
while True:
print("Receive %s" % p.recv())
time.sleep(0.1)
if __name__ == '__main__':
# 创建父进程
p = Pipe()
p1 = Process(target=proc_send, args=(p[0], ['张飞' + str(i) for i in range(3)]))
p2 = Process(target=proc_recv, args=(p[1], ))
p1.start()
p2.start()
p1.join()
p2.join()
输出结果为:
Process (39203) is sending...
Send 张飞0...
Process (39204) is receiving...
Receive 张飞0
Send 张飞1...
Receive 张飞1
Send 张飞2...
Receive 张飞22 多线程
多线程类似于执行多个不同的程序,具有以下优点:
- 任务可后台处理
- 用户界面可以更吸引人,例如进度条
- 可能加快程序运行速度
- 在一些需要等待的任务上,如用户输入、文件读写、网络收发数据等,可以释放一些资源,如内存占用。
Python的标准库提供了两个模块:thread和threading,thread是低级模块,threading是高级模块,对thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。threading.Thread的更多方法:
- start:线程准备就绪,等待CPU调度
- setName:为线程设置名称
- getName:获取线程名称
- setDaemon:设置为后台线程或前台线程(默认);如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论成功与否,均停止;如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执行完毕后,等待前台线程也执行完成后,程序停止
- join:逐个执行每个线程,执行完毕后继续往下执行,该方法使得多线程变得无意义
- run:线程被cpu调度后自动执行线程对象的run方法
- Lock:线程锁(互斥锁Mutex)
- Event
2.1 threading
方法1:传入函数并创建Thread实例,再start()运行:
import time, threading
def thread_run(urls):
print("Current %s is running..." % threading.current_thread().name)
for url in urls:
print("%s --->>> %s" % (threading.current_thread().name, url))
time.sleep(0.1)
print("%s ended." % threading.current_thread().name)
if __name__ == '__main__':
print("%s is running..." % threading.current_thread().name)
t1 = threading.Thread(target=thread_run, name='t1', args=(['唐僧', '孙悟空', '猪八戒'],))
t2 = threading.Thread(target=thread_run, name='t2', args=(['张飞', '关于', '刘备'],))
t1.start()
t2.start()
t1.join()
t1.join()
print("%s ended." % threading.current_thread().name)输出结果为:
MainThread is running...
Current t1 is running...Current t2 is running...
t2 --->>> 张飞
t1 --->>> 唐僧
t2 --->>> 关于t1 --->>> 孙悟空
t2 --->>> 刘备t1 --->>> 猪八戒
t1 ended.t2 ended.
MainThread ended.
方法2:从threading.Thread 继承并创建线程类,然后重写__init__ 方法和run方法:
import time, threading
class testThread(threading.Thread):
def __init__(self, name, urls):
threading.Thread.__init__(self, name=name)
self.urls = urls
def run(self):
print("Current %s is running..." % threading.current_thread().name)
for url in self.urls:
print("%s --->>> %s" % (threading.current_thread().name, url))
time.sleep(0.1)
print("%s ended." % threading.current_thread().name)
if __name__ == '__main__':
print("%s is running..." % threading.current_thread().name)
t1 = testThread(name='t1', urls=['唐僧', '孙悟空', '猪八戒'])
t2 = testThread(name='t2', urls=['张飞', '关于', '刘备'])
t1.start()
t2.start()
t1.join()
t1.join()
print("%s ended." % threading.current_thread().name)输出结果为:
MainThread is running...
Current t1 is running...Current t2 is running...
t1 --->>> 唐僧
t2 --->>> 张飞
t1 --->>> 孙悟空t2 --->>> 关于
t1 --->>> 猪八戒t2 --->>> 刘备
t1 ended.t2 ended.
MainThread ended.
2.2 线程同步
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。具体说明:
- 使用Thread对象的Lock和RLock可以实现简单的线程同步,这两个对象都有acquire()方法和release()方法;
- 对于每次只允许一个线程操作的数据,可以将其操作放在acquire()和release()之间。
- 对于Lock对象而言,如果一个线程连续两次进行acquire()操作,将使线程死锁;
- RLock对象允许一个线程连续多次进行acquire()操作,因为其内部通过一个counter变量维护着acquire()的次数;
- 每一个acquire()对象必须有一个release()与之对应;
- 所有的release()操作完成之后,别的线程才能申请该RLock对象。
import threading
test_lock = threading.RLock()
num = 0
class testThread(threading.Thread):
def __init__(self, name):
threading.Thread.__init__(self, name=name)
def run(self):
global num
while True:
test_lock.acquire()
print("%s locked, Number: %d" % (threading.current_thread().name, num))
if num >= 4:
test_lock.release()
print("%s released, Number: %d" % (threading.current_thread().name, num))
break
num += 1
print("%s released, Number: %d" % (threading.current_thread().name, num))
test_lock.release()
if __name__ == '__main__':
t1 = testThread('孙悟空先上')
t2 = testThread("终于到八戒了")
t1.start()
t2.start()输出结果为:
孙悟空先上 locked, Number: 0
孙悟空先上 released, Number: 1
孙悟空先上 locked, Number: 1
孙悟空先上 released, Number: 2
孙悟空先上 locked, Number: 2
孙悟空先上 released, Number: 3
孙悟空先上 locked, Number: 3
孙悟空先上 released, Number: 4
孙悟空先上 locked, Number: 4
孙悟空先上 released, Number: 4终于到八戒了 locked, Number: 4
终于到八戒了 released, Number: 42.3 死锁和递归锁
1 死锁
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。如下所示的例子就是死锁:
from threading import Thread,Lock
import time
mutexA = Lock()
mutexB = Lock()
class testThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print('%s 拿到A锁' %self.name)
mutexB.acquire()
print('%s 拿到B锁' %self.name)
mutexB.release()
mutexA.release()
def func2(self):
mutexB.acquire()
print('%s 拿到B锁' %self.name)
time.sleep(2)
mutexA.acquire()
print('%s 拿到A锁' %self.name)
mutexA.release()
mutexB.release()
if __name__ == '__main__':
for i in range(5):
t = testThread()
t.start()输出结果为:
Thread-1 拿到A锁
Thread-1 拿到B锁
Thread-1 拿到B锁Thread-2 拿到A锁分析如上代码是如何产生死锁的:
启动5个线程,执行run方法,假如thread1首先抢到了A锁,此时thread1没有释放A锁,紧接着执行代码mutexB.acquire(),抢到了B锁,在抢B锁时候,没有其他线程与thread1争抢,因为A锁没有释放,其他线程只能等待,然后A锁就执行完func1代码,然后继续执行func2代码,与之同时,在func2中,执行代码 mutexB.acquire(),抢到了B锁,然后进入睡眠状态,在thread1执行完func1函数,释放AB锁时候,其他剩余的线程也开始抢A锁,执行func1代码,如果thread2抢到了A锁,接下来thread2要抢B锁,ok,在这个时间段,thread1已经执行func2抢到了B锁,然后在sleep(2),持有B锁没有释放,为什么没有释放,因为没有其他的线程与之争抢,他只能睡着,然后thread1握着B锁,thread2要抢B锁,ok,这样就形成了死锁。
2 递归锁
上面我们分析了死锁,那么python里面是如何解决死锁这样的问题呢? 在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
from threading import Thread,RLock
import time
mutexA = mutexB = RLock()
class testThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
mutexA.acquire()
print('%s 拿到A锁' %self.name)
mutexB.acquire()
print('%s 拿到B锁' %self.name)
mutexB.release()
mutexA.release()
def f2(self):
mutexB.acquire()
print('%s 拿到B锁' % self.name)
time.sleep(0.1)
mutexA.acquire()
print('%s 拿到A锁' % self.name)
mutexA.release()
mutexB.release()
if __name__ == '__main__':
for i in range(5):
t=testThread()
t.start()输出结果为:
Thread-1 拿到A锁
Thread-1 拿到B锁
Thread-1 拿到B锁
Thread-1 拿到A锁
Thread-2 拿到A锁
Thread-2 拿到B锁
Thread-2 拿到B锁
Thread-2 拿到A锁
Thread-4 拿到A锁
Thread-4 拿到B锁
Thread-4 拿到B锁
Thread-4 拿到A锁
Thread-3 拿到A锁
Thread-3 拿到B锁
Thread-3 拿到B锁
Thread-3 拿到A锁
Thread-5 拿到A锁
Thread-5 拿到B锁
Thread-5 拿到B锁
Thread-5 拿到A锁解释下递归锁的代码:
由于锁A,B是同一个递归锁,thread1拿到A,B锁,counter记录了acquire的次数2次,然后在func1执行完毕,就释放递归锁,在thread1释放完递归锁,执行完func1代码,接下来会有2种可能,1、thread1在次抢到递归锁,执行func2代码 2、其他的线程抢到递归锁,去执行func1的任务代码。