
前言
最近在学习一些数据挖掘方面的内容,发现涉及到csv文件处理的必定是离不开Pandas命令的,而且Pandas的强大远远超出我的认知,相比于自己写一些功能代码,使用Pandas 命令处理起来要更加方便、快速,代码也更加简洁。下面整理一些常用的到的Pandas命令。
文中代码建议在 jupyter notebook 中运行
一、基本命令
以下面这个作为要处理的例子:
data=pd.DataFrame({
"name":['Bob','Mike','James','John','Neix','Amy','Sera','Lee','Jay','Claso','Bio','David'],
"area":['A','A','B','C','C','C','B','A','C','C','A','B'],
"age":[24, 23, 16, 22, 34, 11, 23, 28, 26, 41, 25, 42],
"weight":[54, 55, 51, 59, 50, 56, 56, 55, 66, 76, 69, 54]
})

1、基础命令
令data是读取csv文件后的DataFrame
data.head(n)————————显示前n行数据
data.tail(n)————————显示后n行数据
data1 = data.set_index("xxx")————————将xxx列设置为索引
data.infoo()————————获取 dataFrame 的大致信息(有无缺失值、占用内存等)
data.describe()————————获取基本的统计值信息(最大值/最小值、方差等)
2、进阶命令
2.1 Groupby() :根据一个或多个列中的值对数据进行分组,然后对每个组执行聚合操作
2.1.1 配合 sum()/mean()操作
按照地区分类求年龄总和(平均值:.mean())

最终显示时发现索引列不在同一行上,可以使用.reset_index()解决。

2.1.2 配合 agg() 操作——更常用
用法:grouped_data = data.groupby('分组列').agg(操作函数)

按照地区分类求年龄和体重平均值

按照地区分类只求体重的最大值

如果想针对不同的列采取不同处理,可以使用字典指定相应的操作
例如:按照地区分类,求年龄的均值和体重的最大值

2.1.3 配合 apply() 操作——更灵活
apply能够传入自定义函数,实现更复杂的操作(agg也可以)
按照地区分类,求年龄和体重的平均值,保留1位小数
def avg(row):
return round(row.mean(), 1)
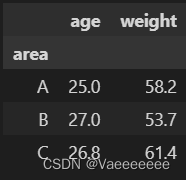
c = data.groupby('area').apply(avg)
c
2.2 map():映射操作
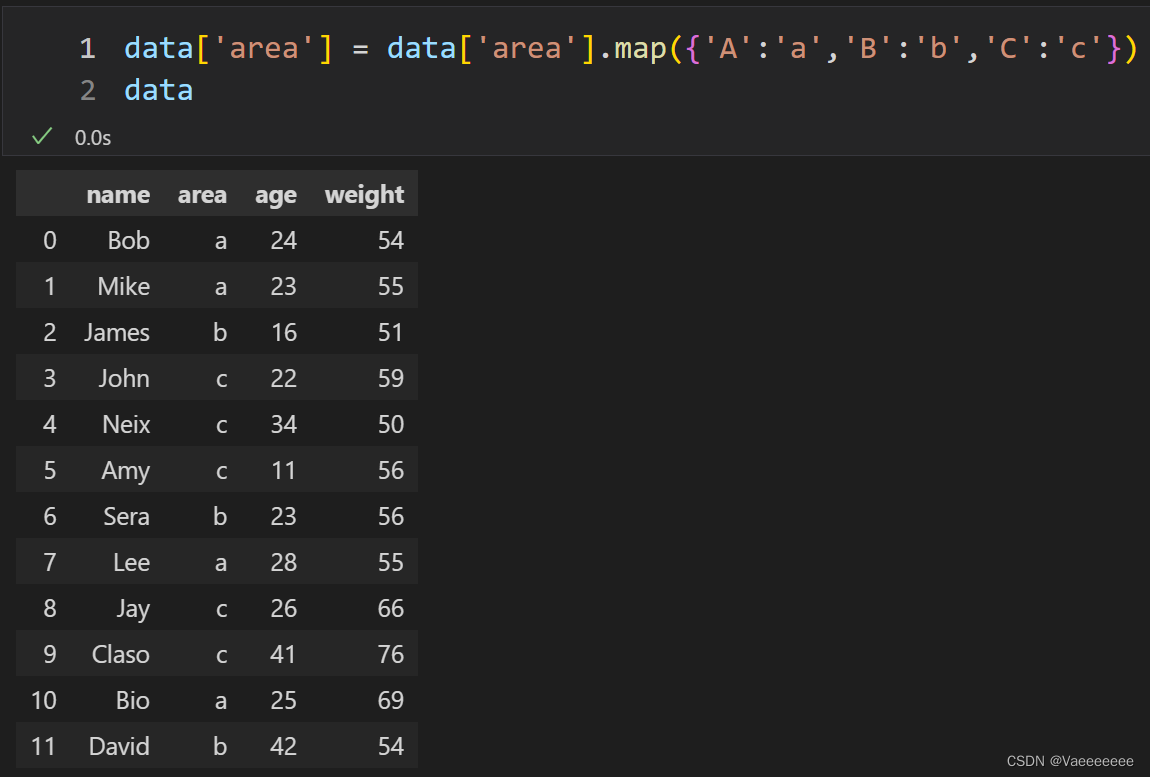
2.2.1 使用字典映射
将area的大写字母换成小写字母
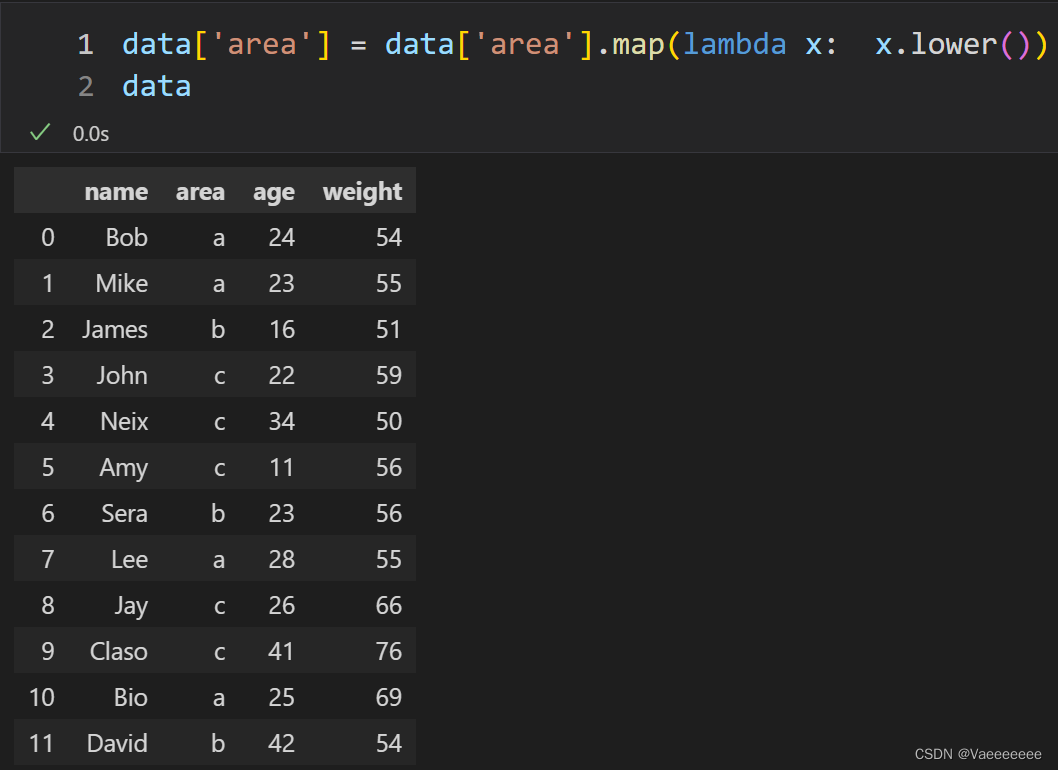
2.2.1 使用函数映射
2.3 筛选操作
2.3.1 常规筛选命令
筛选出年龄大于30且体重大于60的所有数据
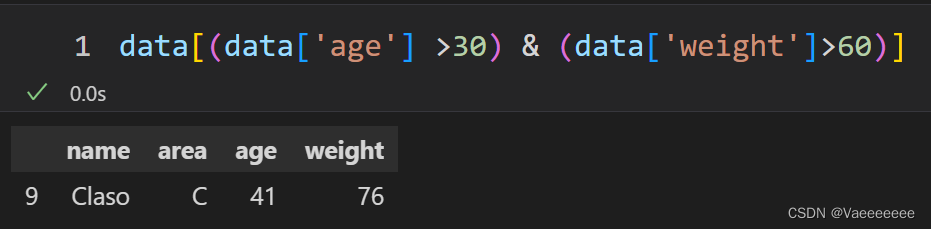
注意:在 Pandas 中,使用 & 符号代替 and,使用 | 符号代替 or,否则会报错。
2.3.2 loc和iloc命令—类似列表切片
loc:使用标签索引进行筛选
iloc:使用位置索引进行筛选
# 通过单个标签选择一行数据
# 下面两个代码结果相同,但是要注意1的含义不同
data.loc[1] # 行标签为1
data.iloc[1] # 1代表第二行
'''
name Mike
area A
age 23
weight 55
Name: 1, dtype: object
'''
# 通过标签列表选择多行数据
data.loc[[1,3]]
data.iloc[[1,3]]
'''
name area age weight
1 Mike A 23 55
3 John C 22 59
'''
# 通过标签范围选择多行数据
data.loc[1:3] #左闭右闭
data.iloc[1:4] # 左闭右开
'''
name area age weight
1 Mike A 23 55
2 James B 16 51
3 John C 22 59
'''
# 通过列标签进行筛选
data.loc[:,'name']
'''
0 Bob
1 Mike
2 James
3 John
4 Neix
5 Amy
6 Sera
7 Lee
8 Jay
9 Claso
10 Bio
11 David
Name: name, dtype: object
'''
2.3.3 str.contains用法:Series中用于查找子字符串
用法:
s.str.contains(pat, case=True, flags=0, na=nan) #s为 series
pat: 要查找的子字符串,可以是正则表达式。
case: 是否区分大小写,默认为 True。
flags: 用于控制正则表达式的行为。
na: 当某个元素为缺失值(NaN)时,返回什么值,默认为 NaN
将姓名首字母A到G的数据筛选出来

3、日期(时间)处理
添加一列随机的日期数据:
data['date'] = pd.Series(['2015/08/06','2015/04/19','2016/11/11','2015/01/30','2016/09/01',
'2015/02/02','2016/07/16','2016/03/19','2016/06/10','2015/12/15',
'2016/10/27','2016/05/22'])
将数据类型转换为标准日期类型
data['date'] = pd.to_datetime(data['date'])
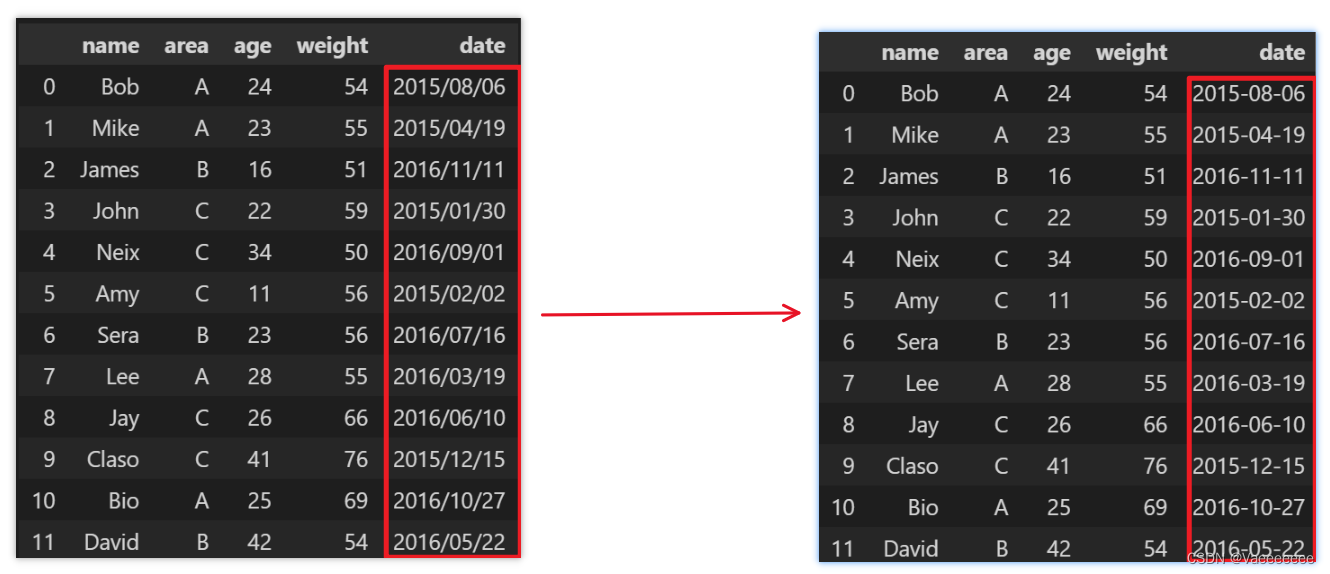
3.1基本命令
3.1.1 将所有数据按时间顺序排列
data.sort_values(by='date',ascending=True,inplace=False)
ascending:Ture为升序,False为降序
3.1.2 筛选某一时间段的数据——truncate方法
truncate:用于按照给定的开始和结束时间戳截断时间序列型数据。它可以用于索引为 DatetimeIndex 的 DataFrame 或 Series 对象中,但是在使用之前需要确保索引已经按照时间序列排序。
用法:
DataFrame.truncate(before=None, after=None, axis=None, copy=True)
或者
Series.truncate(before=None, after=None, copy=True)
before: 提取开始时间,类型为字符串或者时间戳。
after: 提取结束时间,类型为字符串或者时间戳。
axis: 可选参数,如果是 DataFrame,可以指定 0 行轴或 1 列轴,默认为 0。
copy: 如果为 True, 返回新的 DataFrame 或 Series 或者视图;如果为 False, 返回原始的 DataFrame 或 Series 或者视图(如果没有复制),默认为 True。
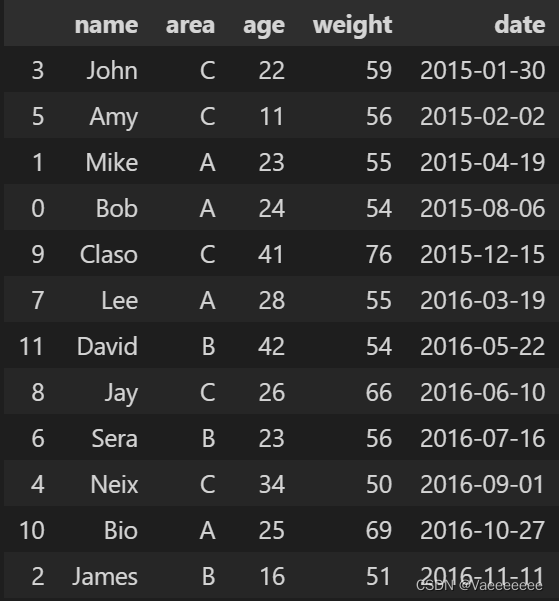
筛选得到2015年年初到年中的所有数据
# 将date列设置为索引
df = data.set_index("date")
# 对索引按照时间顺序排序
df.sort_values(by='date',ascending=True,inplace=True)
# 提取 2015-01-01 到 2015-06-30 之间的数据
start_date = "2015-01-01"
end_date = "2015-06-30"
df_1 = df.truncate(before=start_date, after=end_date)
df_1.reset_index()
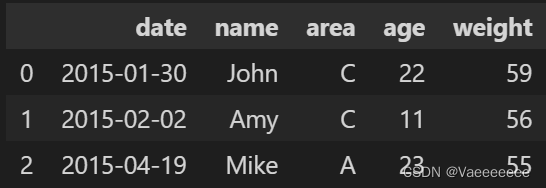
3.2 季节处理
3.1.1 按阴历划分
| 1—3月 | 春 |
|---|---|
| 4—6月 | 夏 |
| 7—9月 | 秋 |
| 10—12月 | 冬 |
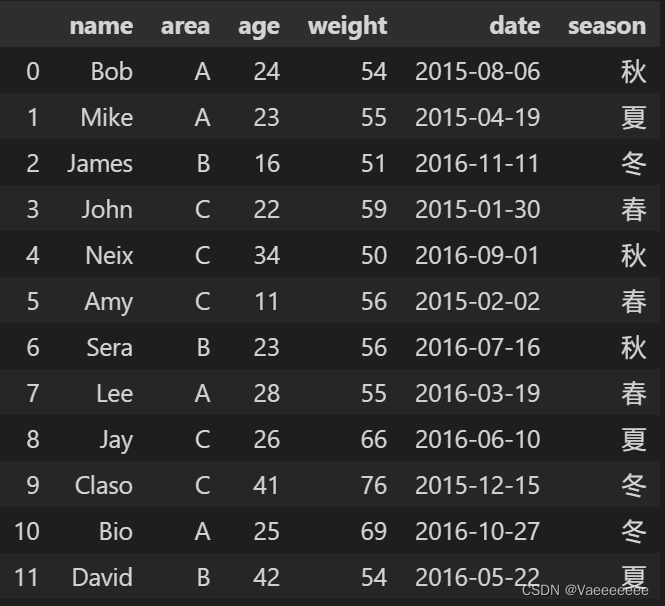
代码(效果:新增一列,获取每个日期对应的季节):
# 使用dt.month属性获取每个日期的月份信息
months = data['date'].dt.month
# 根据月份信息生成季节信息
seasons = ((months + 2) // 3).map({
1: '春', 2: '夏', 3: '秋', 4: '冬'})
# 将季节信息添加到DataFrame中
data['season'] = seasons
3.1.1 按阳历划分
| 3—5月 | 春 |
|---|---|
| 6—8月 | 夏 |
| 9—11月 | 秋 |
| 12—次年2月 | 冬 |
将上面的seasons改为:
seasons = ((months % 12 + 3) // 3).map({
1: '冬', 2: '春', 3: '夏', 4: '秋'})
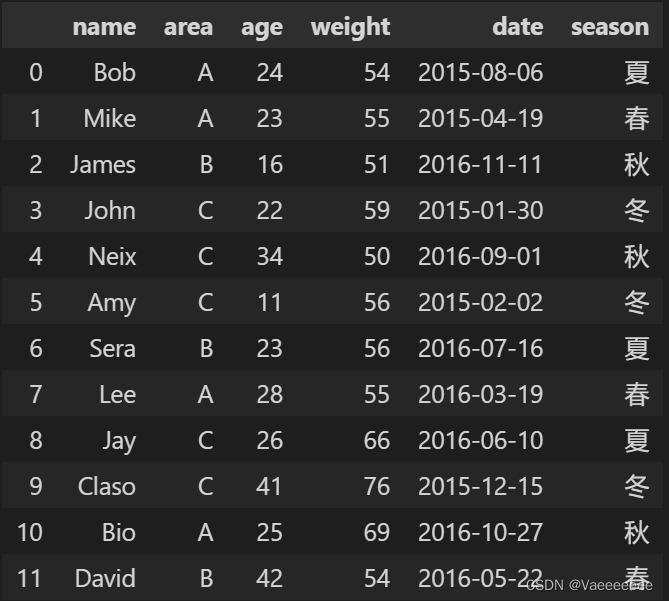
总结
本文后续会长期更新,作为一份简单速查的Pandas笔记,方便快速处理一些简单的数据分析问题。