一、问题描述
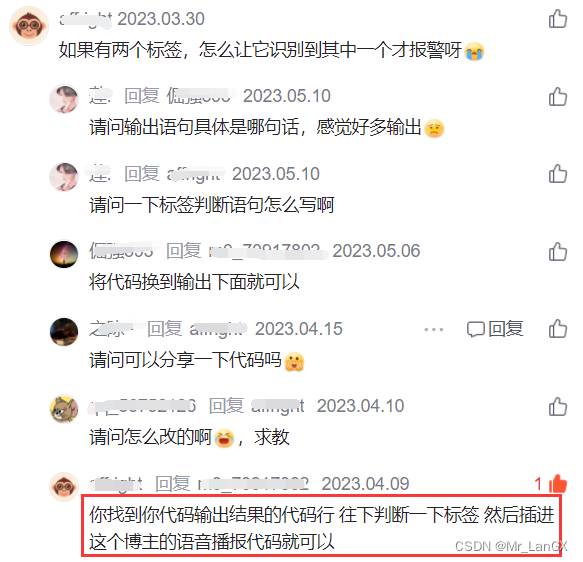
在之前的博文中,好多朋友通过私信和评论给我留言,问到了一个问题:“如果有两个标签,怎么让它识别到其中一个才报警?” 其实下面这位C友已经给出解决方法了,但是大家可能对YOLOv5各个部分的代码还没了解透,所以自己改还有难度。
在这里,我把我自己改进的方法说一下,大家可以改着试试看。
二、改进方法
我的方法比较简单,只要在detect.py里的画框的代码那里加个判断即可。
在这里,我以检测安全帽为例子操作一下。
代码版本:YOLOv5-6.2
检测权重:安全帽检测的开源权重,s版本
检测对象:person和hat两个
步骤一
在detect.py中,找到这一部分代码行,截图如下:
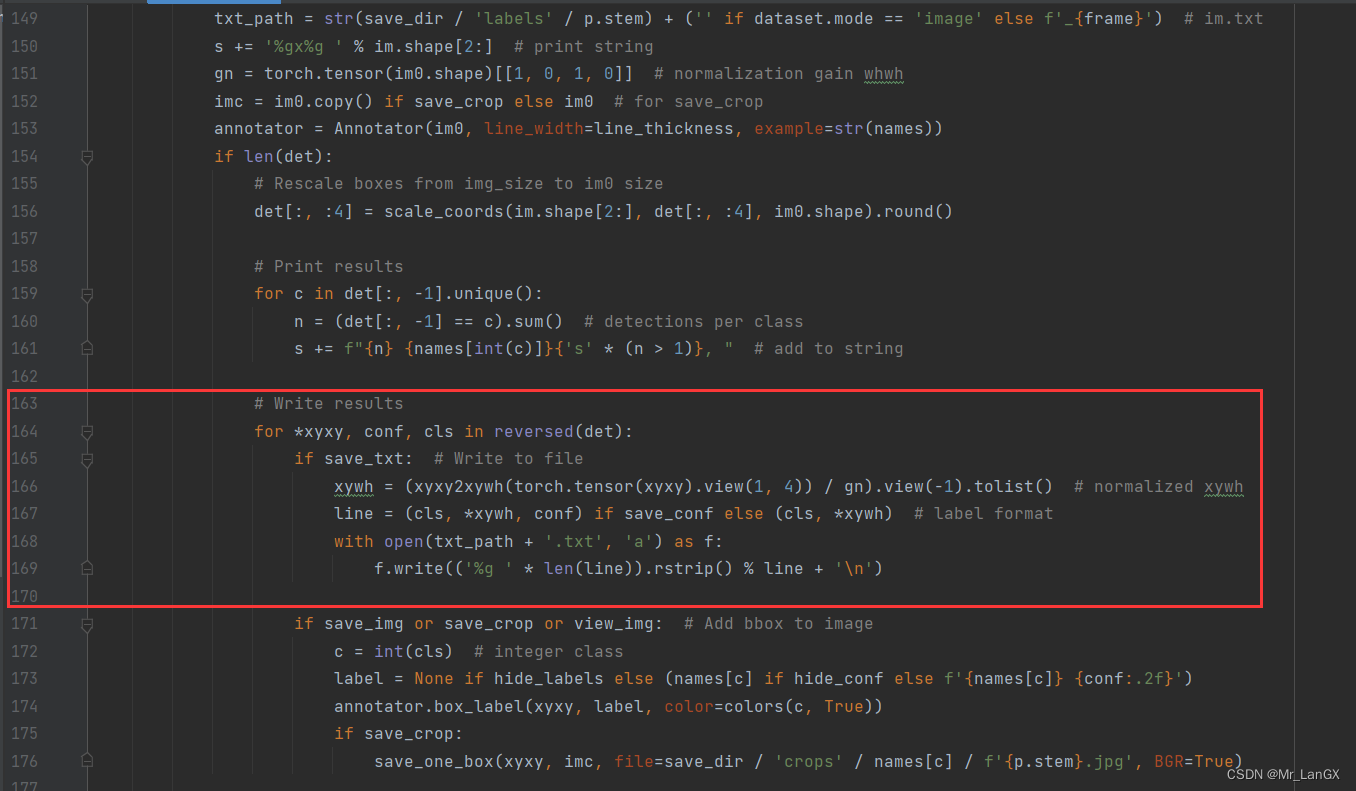
步骤二
然后,输入代码
if names[int(cls)] == 'person':
步骤三
然后,在if语句下,插入语音播报代码:
value = det[:, 4].max().item() #进行多个目标检测,检测的所需目标才发出语音告警
if value > 0.80:
count += 1
if count > 8:
count = 0
if time.time() - tplay > 4.0:
import os
os.system(
'start /b D:/yolov5-6.2-helmet/ffmpeg/bin/ffplay.exe -autoexit -nodisp D:/yolov5-6.2-helmet/helmet-warning.mp3') # 音乐播放
# 参数含义: start /b 后台启动 ffplay音乐播放软件的位置 -autoexit 播放完毕自动退出 -nodisp不显示窗口 mp3语音的位置
tplay = time.time()
代码添加完成后,呈现出如下效果,截图如下:

步骤四
然后,在detec.py里面,找到这一部分代码,截图如下:
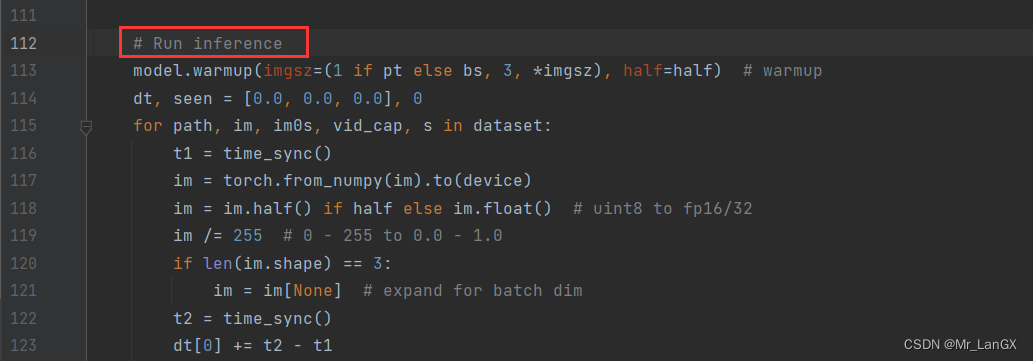
然后加入这几行代码:
t0 = time.time()
count = 0
tplay = 0
加入之后的效果如下:
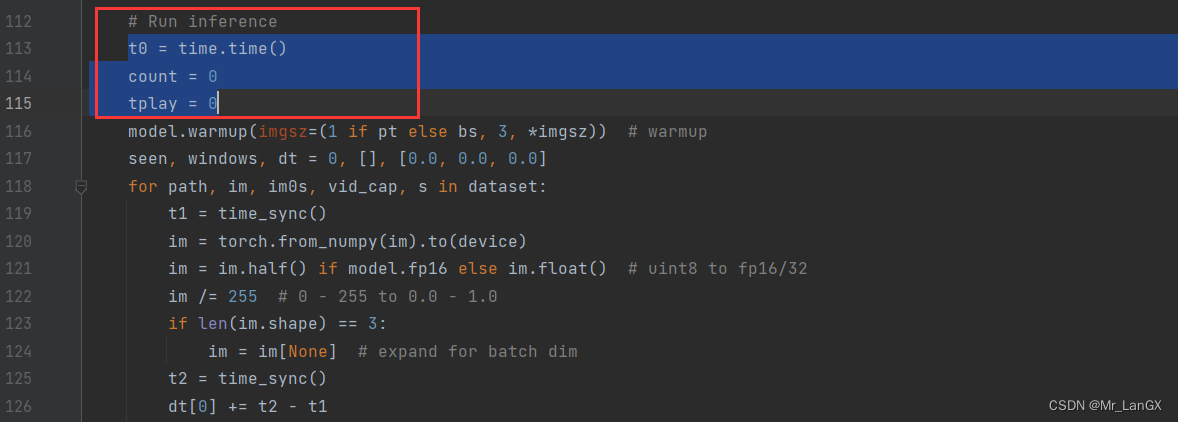
到这里就改完了,运行detect.py脚本就行。
语音告警的MP3文件如何生成呢?可以看我的这一篇博文:如何使YOLOv5在检测到目标后进行声音告警提示?这篇博文的前面几部分已经详细介绍过了。
三、检测效果展示
YOLOv5算法在检测完成后保存下来的带检测框的视频是没有声音的,原作者就是这样写的。所以这里的展示我用的QQ录屏功能将其录下来的。
YOLOv5多目标检测,出现特定目标进行语音告警的效果
视频中,一开始此人未带安全帽,算法检测后进行了语音告警;在其带上帽子后,算法检测出已带了帽子,便不发出语音告警。
五、写在最后
为自己推销一下。这里还有:
1、标注好的吸烟数据集、接打电话手机数据集、电梯按键数据集,以及使用上述数据集训练好的YOLOv5检测权重。
2、还有YOLOv5-5.0版本的改进好的方案(如注意力机制、结构改进等)。
3、YOLOv5的PyQT的检测界面并带有语音告警的全套程序。
检测界面效果展示
有需要的同学私信滴滴我哦,绝对物美价廉。