Leetcode SQL【基础篇】刷题总结
SQL分类
SQL语言在功能上主要分为如下3大类:
(1)DDL(Data Definition Languages、数据定义语言),这些语句定义了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构。
主要的语句关键字包括 CREATE、DROP、ALTER等。
(2)DML(Data Manipulation Language、数据操作语言),用于添加、删除、更新和查询数据库记录,并检查数据完整性。
主要的语句关键字包括INSERT、DELETE、UPDATE、SELECT等。
SELECT是SQL语言的基础,最为重要。
(3) DCL(Data Control Language、数据控制语言),用于定义数据库、表、字段、用户的访问权限和安全级别。
主要的语句关键字包括 GRANT、REVOKE、COMMIT、ROLLBACK、SAVEPOINT等。
因为查询语句使用的非常的频繁,所以很多人把查询语句单拎出来一类:DQL(数据查询语言)。
还有单独将 COMMIT、ROLLBACK取出来称为TCL(Transaction Control Language,事务控制语言)
1、<> (!=) 和 IS NULL(IS NOT NULL)
题目链接
错误写法
SELECT name FROM customer WHERE referee_id <> 2 OR referee_id = NULL;
正确写法
SELECT name FROM customer WHERE referee_id <> 2 OR referee_id IS NULL;
MySQL 使用三值逻辑 —— TRUE, FALSE 和 UNKNOWN。任何与 NULL 值进行的比较都会与第三种值 UNKNOWN 做比较。这个“任何值”包括 NULL 本身!这就是为什么 MySQL 提供 IS NULL 和 IS NOT NULL 两种操作来对 NULL 特殊判断
2、BETWEEN value1 AND value2
BETWEEN操作符用于选取介于两个值之间的数据范围值。
BETWEEN操作符选取介于两个值之间的数据范围内的值。这些值可以是数值,文本或者日期
SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value1 AND value2
3、 Where in 和Not in
找到学校为北大、复旦和山大的同学进行调研
错误写法
select device_id,gender,age,university,gpa
from user_profile
where university =('北京大学','复旦大学','山东大学');
正确写法
select device_id,gender,age,university,gpa
from user_profile
where university in('北京大学','复旦大学','山东大学');
4、 操作符混合运用
到gpa在3.5以上(不包括3.5)的山东大学用户 或 gpa在3.8以上(不包括3.8)的复旦大学同学进行用户调研
SELECT
device_id, gender, age, university,gpa
from
user_profile
where
(gpa > 3.8 and university = '复旦大学') or (gpa > 3.5 and university = '山东大学')
5、SQL的ROUND函数用法及其实例
ROUND函数的语法及用法
(1)语法:round(value,n)
(2)用法:n表示对某个数值(字段)保留指定n数位数(四舍五入)。
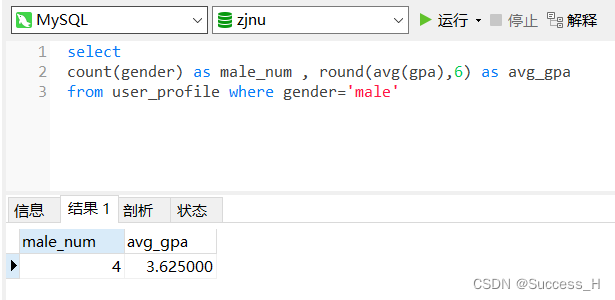
要看一下男性用户有多少人以及他们的平均gpa是多少
男性用户
where gender="male"
他们的平均gpa
round(avg(gpa), 1) as avg_gpa
合并在一起
select
count(gender) as male_num,
round(avg(gpa), 6) as avg_gpa
from user_profile where gender="male";
6、group by
select
聚合函数,
列(要求出现在group by的后面)
from
表
where
筛选条件
group by
分组的列表
order by
子句
查询邮箱中包含a字符的每个部门的平均工资
select
max(salary),
manager_id
from
employees
where
commission_pct is not null
group by
manager_id
查询每个部门 每个工种的员工平均工资,并且按照平均工资的高低排序
select
avg(salary),
department_id,
job_id
from
employees
where
department_id is not null
group by
department_id,
job_id
order by
avg(salary) desc;
请分别计算出每个学校 每种性别 的用户数、30天内平均活跃天数和平均发帖数量
select
gender,university,
count(gender)user_num,
avg(active_days_within_30)avg_active_day,
avg(question_cnt)avg_question_cn
from user_profile
group by gender,university
请取出平均发贴数低于5的学校或平均回帖数小于20的 学校
HAVING 往往与 GROUP BY 配合使用,为聚合操作 指定条件
select university,
avg(question_cnt) avg_quesition_cnt,avg(answer_cnt) avg_answer_cnt
from user_profile
group by university
HAVING avg_quesition_cnt < 5 OR avg_answer_cnt < 20 // 指定条件
查看不同大学的用户平均发帖情况,并期望结果按照平均发帖情况进行升序排列
group by 比order by先执行
select university,avg(question_cnt) avg_question_cnt
from user_profile
group by university
order by avg_question_cnt ASC
返回每个订单号(order_num)各有多少行数(order_lines),并按 order_lines对结果进行升序排序
select order_num,count(order_num) as order_lines
from OrderItems
group by order_num
order by order_lines asc;
返回名为 cheapest_item 的字段,该字段包含每个供应商成本最低的产品(使用 Products 表中的 prod_price),然后从最低成本到最高成本对结果进行升序排序。
【示例结果】返回供应商id vend_id和对应供应商成本最低的产品cheapest_item。
select vend_id, min(prod_price) as cheapest_item
from Products
group by vend_id
order by cheapest_item;
【where不能使用聚合函数、having中可以使用聚合函数】
返回订单数量总和不小于100的所有订单号,最后结果按照订单号升序排序
SELECT order_num
FROM OrderItems
GROUP BY order_num
HAVING SUM(quantity) >= 100
ORDER BY order_num
根据订单号聚合,返回订单总价不小于1000 的所有订单号,最后的结果按订单号进行升序排序。
提示:总价 = item_price 乘以 quantity
select order_num , sum(item_price*quantity) total_price from OrderItems group by order_num
having total_price >= 1000
order by order_num asc
7、CONCAT 拼接
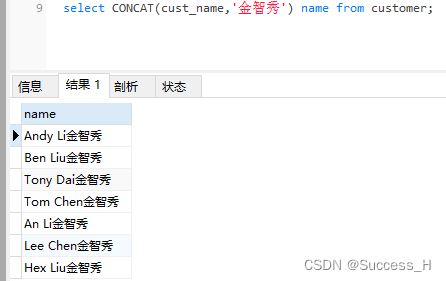
在每个用户名字后面加上金智秀 用 CONCAT 拼接,同时起别名
select CONCAT(cust_name,'金智秀') as name from customer;
8、DISTINCT去除重复
1、DISTINCT 需要放到所有列名的前面,如果写成 SELECT salary, DISTINCT department_id FROM employees 会报错。
2、DISTINCT 其实是对后面所有列名的组合进行去重,你能看到最后的结果是 74 条,因为这 74 个部门id不同,都有 salary 这个属性值。如果你想要看都有哪些不同的部门(department_id),只需要写 DISTINCT department_id 即可,后面不需要再加其他的列名了。
SELECT DISTINCT department_id,salary FROM employees
9、空值参与运算
所有运算符或列值遇到null值,运算的结果都为null
在 MySQL 里面, 空值不等于空字符串。一个空字符串的长度是 0,而一个空值的长度是空。
而且,在 MySQL 里面,空值是占用空间的。
10、显示表结构
DESCRIBE sys_user;
或
DESC sys_user;
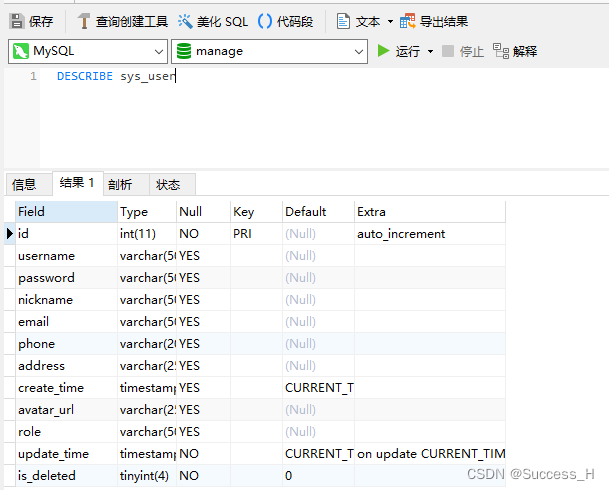
Field:表示字段名称。
Type:表示字段类型,这里barcode、goodsname是文本型的,price是整数类型的。
Null:表示该列是否可以存储NULL值。
Key:表示该列是否已编制索引。PRI表示该列是表主键的一部分;UNI表示该列是UNIQUE索引的一部分;MUL表示在列中某个给定值允许出现多次。
Default:表示该列是否有默认值,如果有,那么值是多少。
Extra:表示可以获取的与给定列有关的附加信息,例如AUTO_INCREMENT等。
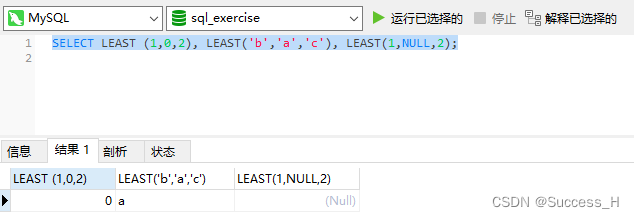
11、运算符
最小值运算符
语法格式为:LEAST(值1,值2,…,值n)。其中,“值n”表示参数列表中有n个值。
在有两个或多个参数的情况下,返回最小值。
SELECT LEAST (1,0,2), LEAST('b','a','c'), LEAST(1,NULL,2);
最大值运算符
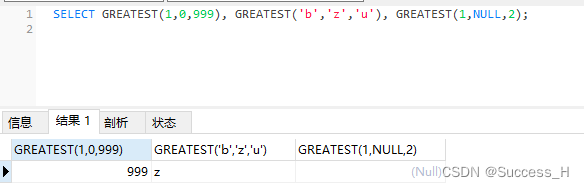
语法格式为:GREATEST(值1,值2,…,值n)。其中,n表示参数列表中有n个值。
当有两个或多个参数时,返回值为最大值。假如任意一个自变量为NULL,则GREATEST()的返回值为NULL。
SELECT GREATEST(1,0,999), GREATEST('b','z','u'), GREATEST(1,NULL,2);
12、分页
分页显式公式:(当前页数-1)*每页条数,每页条数
SELECT * FROM table
LIMIT(PageNo - 1)*PageSize,PageSize;
13、limit、offset、ifnull 的用法
limit n子句表示查询结果返回前n条数据
offset n表示跳过x条语句
limit y offset x 分句表示查询结果跳过 x 条数据,读取前 y 条数据
例如:lselect * from student limit m,n;
m 开始值(从第m+1行开始)
n 结束值(1.共展示n行数据;2.第m+n行结尾)
判断空值的函数(ifnull)函数来处理特殊情况。
ifnull(a,b)函数解释:
如果value1不是空,结果返回a
如果value1是空,结果返回b
LIMIT 返回行数
SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数 ;
- 起始索引从0开始,起始索引 = (查询页码 - 1)* 每页显示记录数。
- 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT。
- 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 10。
需要查看前2个用户明细设备ID数据
select device_id from user_profile limit 0,2
查询性别为男,且年龄在20-40 岁(含)以内的前5个员工信息,对查询的结果按年龄升序排序,年龄相同按入职时间升序排序
select * from emp where gender = '男' and age between 20 and 40 order by age asc ,
entrydate asc limit 5 ;
14、UNION
语法: SQL1 UNION SQL2
只要两个结果集的列数相同就可以使用,即使字段类型不相同,也可以使用
将两个 SELECT 语句结合起来,以便从 OrderItems表中检索产品 id(prod_id)和 quantity。
其中,一个 SELECT 语句过滤数量为 100 的行,另一个 SELECT 语句过滤 id 以 BNBG 开头的产品,最后按产品 id 对结果进行升序排序
select
prod_id,
quantity
from
OrderItems
where
quantity = 100
union
select
prod_id,
quantity
from
OrderItems
where
prod_id like 'BNBG%'
order by
prod_id
组合查询 UNION ALL
分别查看学校为山东大学或者性别为男性的用户的device_id、gender、age和gpa数据
SELECT device_id,gender,age,gpa
FROM user_profile
where university='山东大学'
UNION ALL
SELECT device_id,gender,age,gpa
FROM user_profile
where gender='male'
15、视图
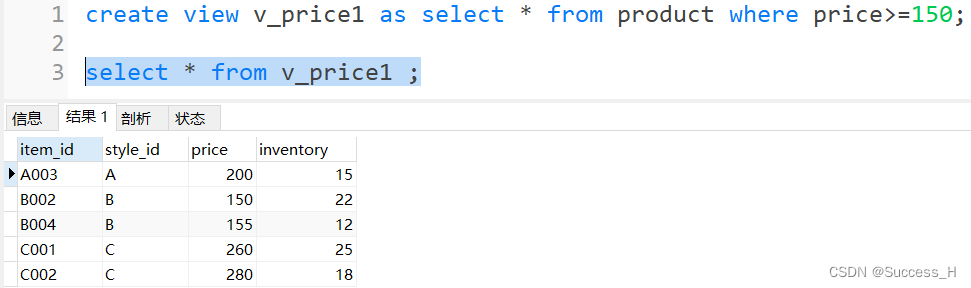
创建视图
create view v_price as select * from product where price>=80;
select * from v_price ;
查看视图
16、聚合函数
将一列数据作为一个整体,进行纵向计算,常见的聚合函数:

count(1) 其实是计算一共有多少符合条件的行
select count(*)和select count(1)的区别:
- 一般情况下,Select Count ()和Select Count(1)两着返回结果是一样
- 假如表没有主键(Primary key), 那么count(1)比count(*)*快
- 如果有主键的话,那主键作为count的条件时候count(主键)最快
- 如果你的表只有一个字段的话那count(*)就是最快的。
- count(*) 跟 count(1) 的结果一样,都包括对NULL的统计,而count(column) 是不包括NULL的统计
Min 聚合函数
写一条 SQL 查询语句获取每位玩家 第一次登陆平台的日期
select player_id , min(player_id) first_login
from Activity
group by player_id
# 第一次登录 也就是 min(player_id) 第一次登陆平台的日期,其实就是找每个玩家的最小日期。
DESC降序函数
用户信息表中对应的数据,并先按照gpa、年龄降序排序输出
降序排序不可连写,如下是错误写法
order by gpa,age desc
select
device_id,gpa,age
from user_profile
order by gpa desc,age desc