STL和泛型编程笔记之容器的分类和测试笔记
一、STL六大部件
- Containers
- Allocators
- Algorithms
- Adapters
- Iterators
- Functors
使用各个容器的测试
#include <iostream>
#include <algorithm>
#include <functional>
using namespace std;
int main(int argc, char const *argv[])
{
int ai[6] = {
12,45,6,78,125,69};
vector<int,allocator<int>> v(ai,ai+6);
//count_if: Return number of elements in range satisfying condition
cout << count_if(v.begin(),v.end(),not1(bind2nd(less<int>,40)));
return 0;
}
二、容器的分类与结构

三、容器的测试
测试程序的辅助函数
using std::cin;
using std::cout;
using std::string;
//获取目标数值
long get_a_target_long(){
long target = 0;
cout<< "target (0~ "<< RAND_MAX << "): ";
cin >> target;
return target;
}
//获取目标字符串
string get_a_target_string(){
long target=0;
char buf[10];
cout<< "target(0~"<<RAND_MAX<<"): ";
cin>>target;
snprintf(buf,10,"%d",target);
return string(buf);
}
//比较long
int compareLongs(const void* a,const void* b){
return *(long*)a - *(long*)b;
}
int compareStrings(const void* a,const void* b){
if(*(string*)a>*(string*)b){
return 1;
}else if(*(string*)a>*(string*)b){
return -1;
}else{
return 0;
}
}
1.Sequence Container
array
namespace testArray{
const long A_SIZE = 500000L;
void test_array(){
cout<< "\ntest_array()-----------\n";
array<long,A_SIZE> c;
//count time
long t_start = clock();
//初始化元素
for (int i = 0; i < A_SIZE; ++i)
{
c[i] = rand();
}
//output
cout << "count time :" << (clock() - t_start) << endl;//初始化整个数组的时间
cout << "c.size() :" << c.size() << endl;//数组大小
cout << "c.front() :" << c.front() << endl;//首元素值
cout << "c.back() :" << c.back() << endl;//尾元素值
cout << "c.data() :" << c.data() << endl;//首地址
//find target
long target = get_a_target_long();
t_start = clock();
//先排序后二分查找目标元素
qsort(c.data(),A_SIZE,sizeof(long),compareLongs);
long* pItem = (long*)bsearch(&target,c.data(),A_SIZE,sizeof(long),compareLongs);
//输出查找的时间
cout<<"qsort()+ bsearch() count time: " << (clock()-t_start)<<endl;
//输出查找结果
if(pItem!=NULL){
cout << "found: " << *pItem <<endl;
}else{
cout << "not found" <<endl;
}
}
}
int main(){
testArray::test_array();
return 0;
}
终端输出结果如下:

vector
成倍地申请内存空间,当申请不到的时候终止程序
#include <vector>
#include <string>
#include <cstdlib>//bsearch
#include <cstdio>//snprintf
#include <iostream>
#include <stdexcept>//try{...}catch(){...}
#include <ctime>//clock()
#include <algorithm>//find,sort
namespace testVector
{
void test_vector(long& value){
cout<< "test_vector()-----------------"<<endl;
vector<string> c;
long t = clock();
char buf[10];
for (long i = 0; i < value; i++)
{
try
{
snprintf(buf,10,"%d",rand());//初始化每一个元素
c.push_back(string(buf));//vector容器的结果是只能将添加的元素加到末尾,即函数push_back()
}
catch(exception& p)
{
cout <<"i="<< p.what() << endl;
abort();//终止程序
}
}
//输出
cout <<"count time: " << (clock()-t)<<endl;
cout << "c.size()" << c.size() << endl;//返回c中的元素数
cout << "c.front()" << c.front() << endl;
cout << "c.data()" << c.data() << endl;
cout << "c.capacity()" << c.capacity() << endl;//返回当前为vector分配的存储空间的大小,以元素表示。
string target = get_a_target_string();
//两种查找方式花费时间比较
{
t = clock();
//使用全局find函数函数直接查找
auto pItem =::find(c.begin(),c.end(),target);
//输出查找的时间
cout<<"find() count time: " << (clock()-t)<<endl;
//输出查找结果
if(pItem!=c.end()){
//如果没有等于末尾元素地址则说明找到这个元素
cout << "found: " << *pItem <<endl;
}else{
cout << "not found" <<endl;
}
}
{
t = clock();
//使用sort函数函数先排序后查找
sort(c.begin(),c.end());
string* pItem =(string*)bsearch(&target,c.data(),c.size(),sizeof(string),compareStrings);
//输出查找的时间
cout<<"sort()+ bsearch() count time: " << (clock()-t)<<endl;
//输出查找结果
if(pItem!=NULL){
//如果没有等于末尾元素地址则说明找到这个元素
cout << "found target: " << *pItem <<endl;
}else{
cout << "not found" <<endl;
}
}
}
} // namespace testVector
int main(){
long v = 1000000L;
testVector::test_vector(v);
return 0;
}
输出结果

由此观之,使用find直接查找元素比先排序后查找快速
list

#include <iostream>
#include <ctime>//clock
#include <list>
#include <cstdio>//snprintf
#include <stdexcept>//try..catch..
#include <algorithm>//find,sort
namespace testList
{
void test_list(long& v){
cout<< "test_list()-----------------"<<endl;
list<string> c;
long t = clock();
char buf[10];
for (long i = 0; i < v; i++)
{
try
{
snprintf(buf,10,"%d",rand());//初始化每一个元素
c.push_back(string(buf));
}
catch(exception& p)
{
cout <<"i="<< p.what() << endl;
abort();//终止程序
}
}
//输出
cout <<"count time: " << (clock()-t)<<endl;
cout << "c.size():" << c.size() << endl;//返回列表容器中的元素个数
cout << "c.max_size():" << c.max_size() << endl;//返回列表容器所能容纳的最大元素数。
cout << "c.back():" << c.back() << endl;
cout << "c.front():" << c.front() << endl;
string target = get_a_target_string();
//两种查找方式花费时间比较
{
t = clock();
//使用全局find函数函数直接查找
auto pItem =::find(c.begin(),c.end(),target);
//输出查找的时间
cout<<"find() count time: " << (clock()-t)<< " ms"<<endl;
//输出查找结果
if(pItem!=c.end()){
//如果没有等于末尾元素地址则说明找到这个元素
cout << "found: " << *pItem <<endl;
}else{
cout << "not found" <<endl;
}
}
{
t = clock();
//使用容器自带的sort函数排序后
c.sort();
//输出查找的时间
cout<<"c.sort() count time: " << (clock()-t)<< " ms"<<endl;
}
}
} // namespace testList
int main(){
long v = 1000000L;
testList::test_list(v);
return 0;
}
测试结果:
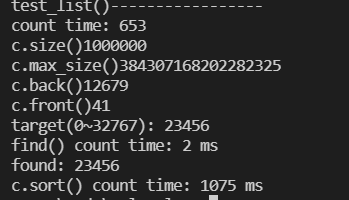
find函数的查找比排序快
Forward_list
#include <iostream>
#include <stdexcept>//try...catch
#include <algorithm>//find,sort
#include <cstdio>//snprintf
#include <cstdlib>//bsearch, abort()
#include <ctime>//clock
#include <forward_list>
namespace testForwardList
{
void test_forwardlist(long& v){
cout<< "test_list()-----------------"<<endl;
forward_list<string> c;
long t = clock();
char buf[10];
for (long i = 0; i < v; i++)
{
try
{
snprintf(buf,10,"%d",rand());//初始化每一个元素
c.push_front(string(buf));
}
catch(exception& p)
{
cout <<"i="<< p.what() << endl;
abort();//终止程序
}
}
//输出
cout <<"count time: " << (clock()-t)<<endl;
cout << "c.max_size():" << c.max_size() << endl;//返回列表容器所能容纳的最大元素个数。
cout << "c.front():" << c.front() << endl;
//单向链表无size()函数和back()函数
string target = get_a_target_string();
//两种查找方式花费时间比较
{
t = clock();
//使用全局find函数函数直接查找
auto pItem =::find(c.begin(),c.end(),target);
//输出查找的时间
cout<<"find() count time: " << (clock()-t)<< " ms"<<endl;
//输出查找结果
if(pItem!=c.end()){
//如果没有等于末尾元素地址则说明找到这个元素
cout << "found: " << *pItem <<endl;
}else{
cout << "not found" <<endl;
}
}
{
t = clock();
//使用容器自带的sort函数排序后
c.sort();
//输出查找的时间
cout<<"c.sort() count time: " << (clock()-t)<< " ms"<<endl;
}
}
} // namespace testForwardList
int main(){
long v = 1000000L;
testForwardList::test_forwardlist(v);
return 0;
}
测试结果:
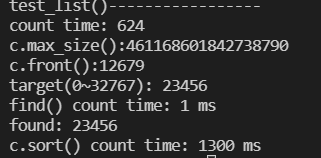
find()函数查找比排序快
slist
#include <iostream>
#include <cstdio>//snprintf
#include <cstdlib>//abort
#include <stdexcept>//try...catch
#include <ctime>
#include <ext\slist>
#include <string>
namespace testSList
{
void test_slist(long& v)
{
cout<<"test_slist()------------------"<<endl;
__gnu_cxx::slist<string> c;
char buf[10];
long t = clock();
for (long i = 0; i < v; i++)
{
try
{
snprintf(buf,10,"%d",rand());
c.push_front(string(buf));
}
catch(exception& e)
{
cout << "i = "<<e.what() << endl;
abort();
}
}//for
cout<<"count time: " << (clock()-t) << " ms" <<endl;
cout<<"c.size(): " << c.size() <<endl;
cout<<"c.front(): " << c.front() <<endl;
string target = get_a_target_string();
t=clock();
auto pItem = ::find(c.begin(),c.end(),target);
//输出查找的时间
cout<<"find() count time: " << (clock()-t)<< " ms"<<endl;
//输出查找结果
if(pItem!=c.end()){
cout << "found: " << *pItem <<endl;
}else{
cout << "not found" <<endl;
}
t = clock();
c.sort();
cout<<"c.sort() count time: " << (clock()-t)<< " ms"<<endl;
}//test_slist
} // namespace testSList
输出

deque
queue和stack是deque容器适配器
#include <deque>
#include <iostream>
#include <stdexcept>
#include <string>
#include <cstdio>//abort,snprintf
#include <cstdlib>//
namespace testDeque
{
void test_deque(long& v){
cout << " test_deque(long& v)" << endl;
deque<string> c;
char buf[10];
long t = clock();
//初始化
for (long i = 0; i < v; i++)
{
try
{
snprintf(buf,10,"%d",rand());
c.push_back(string(buf));
}
catch(exception& e)
{
cout << " i = " << e.what() << '\n';
abort();
}
}
cout << "time :" << (clock()- t) <<" ms"<< endl;
cout << "c.size() : " << c.size() << endl;
cout << "c.front() : " << c.front() << endl;
cout << "c.back() : " << c.back() << endl;
cout << "c.max_size() : " << c.max_size() << endl;
//
string target = get_a_target_string();
{
t = clock();
auto pItem = ::find(c.begin(),c.end(),target);
cout << "time :" << (clock()- t) <<" ms"<< endl;
if (pItem!=c.end())
{
cout << "found : " << *pItem << endl;
}else{
cout << "not found " << endl;
}
}
{
t = clock();
::sort(c.begin(),c.end());
cout << "::sort() time : " << (clock()-t)<<" ms"<< endl;
}
}//test_deque(long& v)
} // namespace testDeque
int main(){
long v = 1000000L;
testDeque::test_deque(v);
return 0;
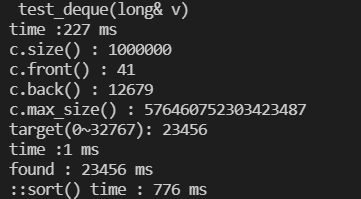
全局函数sort()比全局函数find()快
2.Associative Container
需要搜寻大量元素的话,用Associative Container(set/multiset、map/multimap)比较合适,因为是先排好序的
multiset
结构如图所示:
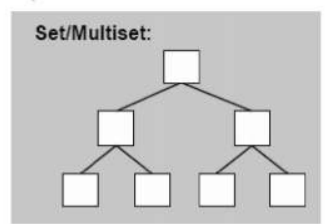
multiset是红黑树底层结构,插入元素时,元素会先按照规则移动排序再确度安插位置
multiset中的元素的value即key
multiset是set的一个特例,只要include <set>即可
测试容器代码:
#include <iostream>
#include <stdexcept>
#include <string>
#include <set>
#include <cstdio>//abort,snprintf
#include <cstdlib>
namespace testMultiset
{
void test_multiset(long& v){
cout << " test——multiset(long& v)" << endl;
multiset<string> c;
char buf[10];
long t = clock();
//初始化
for (long i = 0; i < v; i++)
{
try
{
snprintf(buf,10,"%d",rand());
c.insert(string(buf));
}
catch(exception& e)
{
cout << " i = " << e.what() << '\n';
abort();
}
}
cout << "time :" << (clock()- t) <<" ms"<< endl;
cout << "c.size() : " << c.size() << endl;
cout << "c.max_size() : " << c.max_size() << endl;
//
string target = get_a_target_string();
{
t = clock();
auto pItem = ::find(c.begin(),c.end(),target);
cout << "::find() time :" << (clock()- t) <<" ms"<< endl;
if (pItem!=c.end())
{
cout << "found: " << *pItem <<" ms"<< endl;
}else{
cout << "not found " << endl;
}
}
{
t = clock();
auto pItem = c.find(target);
cout << "c.find() time : " << (clock()-t)<<" ms"<< endl;
if (pItem!=c.end())
{
cout << "found: " << *pItem << endl;
}else{
cout << "not found " << endl;
}
}
}
} // namespace testMultiset
int main(){
long v = 1000000L;
testMultiset::test_multiset(v);
return 0;
}
测试结果:
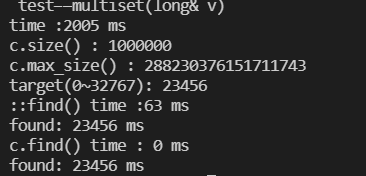
multiset容器自带的find()函数查找速度比::find()快很多
multimap
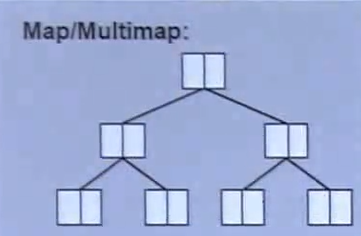
在multimap中元素的key和map是分开来的,查找是用key来查找的,所以key是可以重复的
#include <iostream>
#include <stdexcept>
#include <string>
#include <map>
#include <cstdio>//abort,snprintf
#include <cstdlib>
#include <utility>//pair container
namespace testMultimap
{
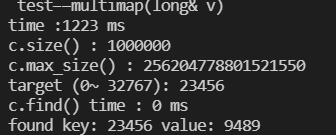
void test_multimap(long& v){
cout << " test——multimap(long& v)" << endl;
multimap<long,string> c;
char buf[10];
long t = clock();
//初始化
for (long i = 0; i < v; i++)
{
try
{
snprintf(buf,10,"%d",rand());
//multimap不可使用[]来insert,要用pair container
c.insert(pair<int,string>(i,buf));
}
catch(exception& e)
{
cout << " i = " << e.what() << '\n';
abort();
}
}
cout << "time :" << (clock()- t) <<" ms"<< endl;
cout << "c.size() : " << c.size() << endl;
cout << "c.max_size() : " << c.max_size() << endl;
//
long target = get_a_target_long();
{
t = clock();
auto pItem = c.find(target);
cout << "c.find() time : " << (clock()-t)<<" ms"<< endl;
if (pItem!=c.end())
{
cout << "found key: "<<(*pItem).first << " value: "<<(*pItem).second<< endl;
}else{
cout << "not found " << endl;
}
}
}
} // namespace testMultimap
int main(){
long v = 1000000L;
testMultimap::test_multimap(v);
return 0;
}
3.Unordered Container
unodered_multiset


实现原理是散列表,篮子一定比元素多
#include <iostream>
#include <unordered_set>
#include <stdexcept>
#include <algorithm>//find()
#include <string>
#include <cstdio>//abort,snprintf
#include <cstdlib>
#include <ctime>//clock()
using namespace std;
namespace testUnorderedmultiSet
{
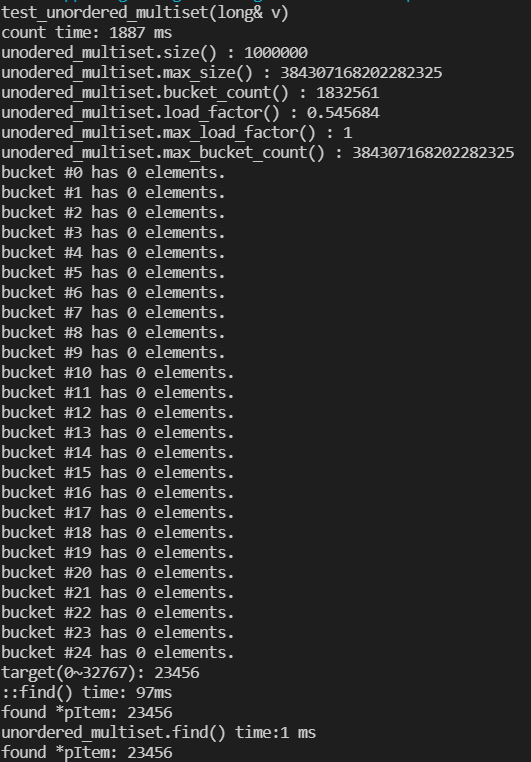
void test_unordered_multiset(long& v){
cout<<"test_unordered_multiset(long& v)"<<endl;
unordered_multiset<string> c;
char buf[10];
long t = clock();
for (long i = 0; i < v; i++)
{
try
{
snprintf(buf,10,"%d",rand());
c.insert(string(buf));
}
catch(exception& e)
{
cout << "i = "<<e.what() << endl;
abort();
}
}
cout<<"count time: " << (clock()-t) << " ms"<< endl;
cout<<"unodered_multiset.size() : " << c.size() << endl;
cout<<"unodered_multiset.max_size() : " << c.max_size() << endl;
cout<<"unodered_multiset.bucket_count() : " << c.bucket_count()<< endl;
cout<<"unodered_multiset.load_factor() : " << c.load_factor()<< endl;
cout<<"unodered_multiset.max_load_factor() : " << c.max_load_factor()<< endl;
cout<<"unodered_multiset.max_bucket_count() : " << c.max_bucket_count()<< endl;
//输出前二十个bucket的拥有的元素个数
for(unsigned i=0;i<25;++i){
cout << "bucket #" <<i <<" has " << c.bucket_size(i) << " elements.\n";
}
//查找测试
string target = get_a_target_string();
{
//::find()
t = clock();
auto pItem = ::find(c.begin(),c.end(),target);
cout << "::find() time: " << (clock()-t) <<"ms"<< endl;
if (pItem != c.end())
{
cout << "found *pItem: " << *pItem << endl;
}else{
cout << "not found" << endl;
}
}
{
// unordered_multiset.find()
t = clock();
auto pItem = c.find(target);
cout << "unordered_multiset.find() time:" << (clock() - t) << " ms"<<endl;
if (pItem != c.end())
{
cout << "found *pItem: " << *pItem << endl;
}else{
cout << "not found" << endl;
}
}
}
} // namespace testUnorderedmultiSet
int main(){
long v = 1000000L;
testUnorderedmultiSet::test_unordered_multiset(v);
return 0;
}
unordered multimap

#include <iostream>
#include <unordered_map>
#include <algorithm>//find
#include <cstdio>//abort,snprintf
#include <cstdlib>//abort
#include <stdexcept>
#include <unordered_map>
#include <utility>
using namespace std;
namespace testUnorderedMultimap
{
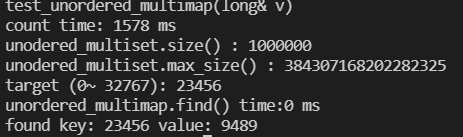
void test_unordered_multimap(long& v){
cout<<"test_unordered_multimap(long& v)"<<endl;
unordered_multimap<long,string> c;
char buf[10];
long t = clock();
for (long i = 0; i < v; i++)
{
try
{
snprintf(buf,10,"%d",rand());
c.insert(pair<long,string>(i,buf));
}
catch(exception& e)
{
cout << "i = "<<e.what() << endl;
abort();
}
}
cout<<"count time: " << (clock()-t) << " ms"<< endl;
cout<<"unodered_multiset.size() : " << c.size() << endl;
cout<<"unodered_multiset.max_size() : " << c.max_size() << endl;
//查找测试
long target = get_a_target_long();
// {
// //::find()
// t = clock();
// auto pItem = ::find(c.begin(),c.end(),target);
// cout << "::find() time: " << (clock()-t) <<"ms"<< endl;
// if (pItem != c.end())
// {
// cout << "found key: "<<(*pItem).first << "value: " << (*pItem).second << endl;
// }else{
// cout << "not found" << endl;
// }
// }
{
// unordered_multiset.find()
t = clock();
auto pItem = c.find(target);
cout << "unordered_multimap.find() time:" << (clock() - t) << " ms"<<endl;
if (pItem != c.end())
{
cout << "found key: "<<(*pItem).first << " value: " << (*pItem).second << endl;
}else{
cout << "not found" << endl;
}
}
}
} // namespace testUnorderedMultimap
int main(){
long v = 1000000L;
testUnorderedMultimap::test_unordered_multimap(v);
return 0;
}