校招前端面试常见问题【5】——前端框架及常用工具
写在前面:
全部面试问题整理已分享至GitHub,欢迎各位star。
地址:https://github.com/shadowings-zy/front-end-school-recruitment-question
React
Q:请简述一下虚拟 DOM 的概念?
基于 React 进行开发时所有的 DOM 构造都是通过虚拟 DOM 进行,每当数据变化时,React 都会重新构建整个 DOM 树,然后 React 将当前整个 DOM 树和上一次的 DOM 树进行对比,得到 DOM 结构的区别,然后仅仅将需要变化的部分进行实际的浏览器 DOM 更新。
React 在构建 DOM 的时候,是使用 javascript 的对象模拟 DOM 的,针对 js 的对象进行比较要比针对浏览器 DOM 进行比较的开销小很多。
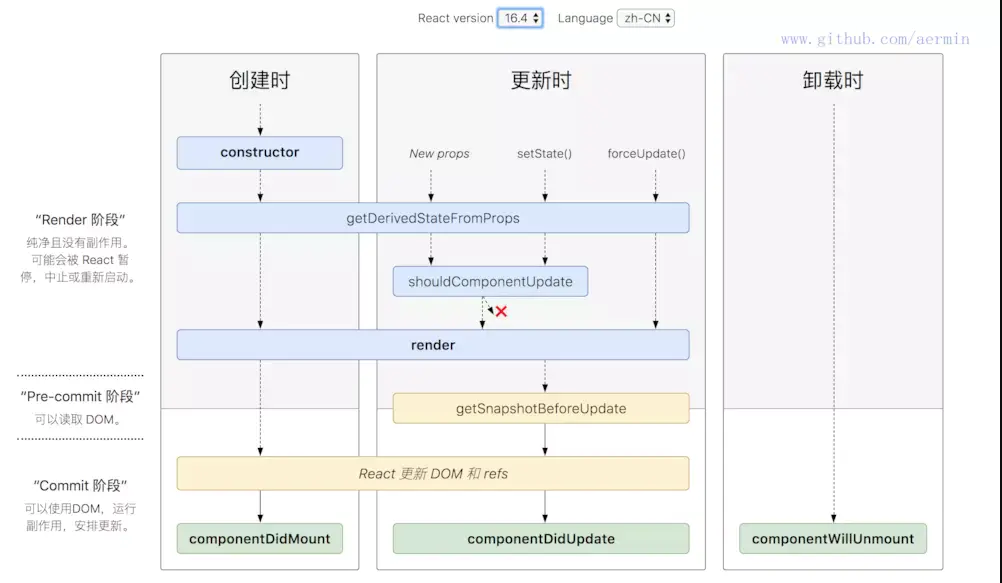
Q:请简述一下 React 的生命周期?
Q:请简述一下 React Fiber 的概念?
在页面元素很多,且需要频繁刷新的场景下,React 15 会出现掉帧的现象。那么为什么会出现掉帧问题呢?其根本原因,是大量的同步计算任务阻塞了浏览器的 UI 渲染。默认情况下,JS 运算、页面布局和页面绘制都是运行在浏览器的主线程当中,他们之间是互斥的关系。如果 JS 运算持续占用主线程,页面就没法得到及时的更新。当我们调用 setState 更新页面的时候,React 会遍历应用的所有节点,计算出差异,然后再更新 UI。如果页面元素很多,整个过程占用的时机就可能超过 16 毫秒,就容易出现掉帧的现象。而原因就是 React 15 采用的是递归的方式遍历整颗组件树。
react16 将底层更新单元的数据结构改成了链表结构。以前的协调算法是递归调用,通过 react dom 树级关系构成的栈递归。而 fiber 是扁平化的链表的数据存储结构,通过 child 找第一个子节点,return 找父节点,sibling 找兄弟节点。遍历从递归改为循环。
这是 React 核心算法的一次大的更新,重写了 React 的 reconciliation 算法。reconciliation 算法是用来更新并且渲染 DOM 树的算法。以前 React 15.x 的版本使用的算法称为“stack reconciliation”,现在称为“fiber reconciler”。
fiber reconciler 主要的特点是可以把更新流程拆分成一个一个的小的单元进行更新,并且可以中断,转而去执行高优先级的任务或者浏览器的动画渲染等,等主线程空闲了再继续执行更新。
对于流畅度问题,我们很容易想到一个 api:requestldleCallback , 这个 api 可以在浏览器空闲的时候执行回调,我们把复杂的任务分片在浏览器空闲的时间执行,就不会影响浏览器的渲染等工作。这个就可以解决复杂任务长时间霸占主线程导致渲染延迟。
但是可能由于兼容性的考虑,react 团队放弃了这个 api,转而利用 requestAnimationFrame 和 MessageChannel pollyfill 了一个 requestIdleCallback
当前帧先执行浏览器的渲染等任务,如果当前帧还有空闲时间,则执行任务,直到当前帧的时间用完。如果当前帧已经没有空闲时间,就等到下一帧的空闲时间再去执行。
Q:React setState 的时机?
使用 setState 时不会直接更新数据,而是会直接将其挂到更新队列中。
更新的时机是:当前宏任务结束后,微任务开始前。
this.state = {
a: 1,
}
// 这种情况只会+1,因为它相当于Object.assign(oldState, {count: XXX}, {count: XXX})
this.setState({
count: this.state.count + 1 })
this.setState({
count: this.state.count + 1 })
console.log(this.state.count) // 这时候会取到原来的state,也就是1
// 进行改造,这样就一定会+2了
this.setState((state, props) => {
return {
count: state.count + 1 }
})
this.setState((state, props) => {
return {
count: state.count + 1 }
})
Vue
Q:什么是 mvvm 模式?
M: 模型 => 数据,业务逻辑,验证逻辑,模型常常包含业务逻辑。
V: 视图 => 交互界面,是模型数据的可视化呈现,视图可能包含展示逻辑。
VM:视图和模型的中间人。
数据双向绑定:V 的变动直接反映在了 VM 上,M 的变化也直接反映在了 VM 上。
Q:请简述一下 vue 响应式数据的原理?
响应式数据的关键在于:data 如何更新 view,以及 view 如何更新 data。
1、view 更新 data 可以通过事件监听,比如 input 标签监听 ‘input’ 事件就可以实现了。
2、而 data 更新 view 的重点是如何知道数据变了。这时候我们就通过Object.defineProperty()对属性设置一个 set 函数,当数据改变了就会来触发这个函数,所以我们只要将一些需要更新的方法放在这里面就可以实现 data 更新 view 了。
Object.defineProperty 的具体用法:
Object.defineProperty(obj, prop, descriptor)
obj:要在其上定义属性的对象。
prop:要定义或修改的属性的名称。
descriptor:将被定义或修改的属性描述符。
descriptor 具有以下两种可选值:
get:给属性提供 getter 的方法,如果没有 getter 则为 undefined。当访问该属性时,该方法会被执行,方法执行时没有参数传入,但是会传入 this 对象。
set:给属性提供 setter 的方法,如果没有 setter 则为 undefined。当属性值修改时,触发执行该方法。该方法将接受唯一参数,即该属性新的参数值。
一个简单的响应式数据的例子:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>defineProperty</title>
</head>
<body>
<div id="app">
<input type="text" id="txt" />
<p id="show"></p>
</div>
<script>
let obj = {
}
Object.defineProperty(obj, 'txt', {
get: function () {
return obj
},
set: function (newValue) {
document.getElementById('txt').value = newValue
document.getElementById('show').innerHTML = newValue
},
})
document.addEventListener('keyup', function (e) {
obj.txt = e.target.value
})
</script>
</body>
</html>
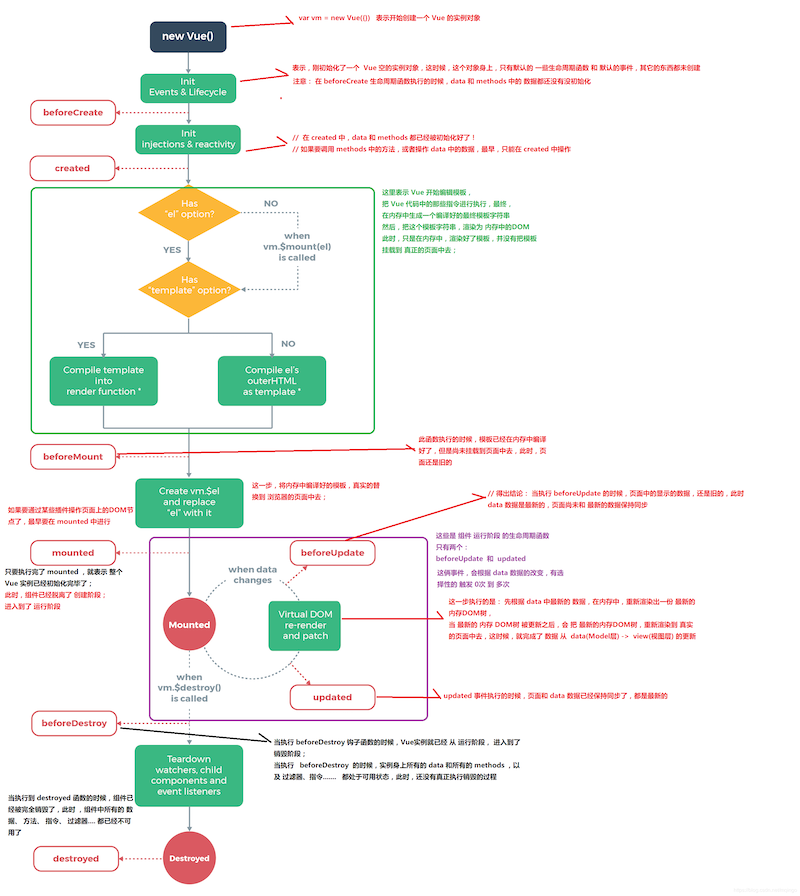
Q:请简述一下 Vue 的生命周期?
Q:请简述一下 Vue router 的原理?
Vue router 有两种模式:hash 模式和 history 模式,分别对应了两种原理:
hash 模式:
hash("#")符号的本来作用是加在 URL 指示网页中的位置,例如:
http://www.example.com/index.html#print
#本身以及它后面的字符称之为 hash 可通过 window.location.hash 属性读取。
hash 虽然出现在 url 中,但不会被包括在 http 请求中,对服务器端完全无用,因此,改变 hash 不会重新加载页面。
我们可以为 hash 的改变添加监听事件:
window.addEventListener("hashchange",funcRef,false)
每一次改变 hash,我们都会重新注入对应的组件,就可以来实现前端路由"更新视图但不重新请求页面"的功能了。
history 模式:
从HTML5开始,History interface提供了2个新的方法:pushState(),replaceState()使得我们可以对浏览器历史记录栈进行修改。
window.history.pushState(stateObject, title, URL)
window.history.replaceState(stateObject, title, URL)
stateObject: 当浏览器跳转到新状态时,触发popState事件,该事件将携带stateObject参数的副本
title: 所添加记录的标题
URL: 所添加记录的URL
我们可以为window.history的改变添加监听事件:
window.addEventListener("popstate",funcRef,false)
在监听事件中,重新注入对应的组件,就可以来实现前端路由"更新视图但不重新请求页面"的功能了。
用 HTML5 实现,单页路由的 url 就不会多出一个#,变得更加美观。但因为没有 # 号,所以当用户刷新页面之类的操作时,浏览器还是会给服务器发送请求,可能会造成404。
打包工具
Q:介绍一下 webpack?
webpack 是一个模块打包工具,在 webpack 中,一切文件都是模块,webpack 能做的就是将它们打包在一起。
webpack 在配置时主要有如下常用属性:
1、entry 以及 output:
入口起点(entry point)指示 webpack 应该使用哪个模块,来作为构建其内部依赖图的开始。进入入口起点后,webpack 会找出有哪些模块和库是入口起点(直接和间接)依赖的。
output 属性告诉 webpack 在哪里输出它所创建的 bundles,以及如何命名这些文件,默认值为 ./dist。基本上,整个应用程序结构,都会被编译到你指定的输出路径的文件夹中。你可以通过在配置中指定一个 output 字段,来配置这些处理过程。
const path = require('path')
module.exports = {
entry: './path/to/my/entry/file.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'my-first-webpack.bundle.js',
},
}
2、loader:
loader 让 webpack 能够去处理那些非 JavaScript 文件。loader 可以将所有类型的文件转换为 webpack 能够处理的有效模块,然后你就可以利用 webpack 的打包能力,对它们进行处理。
本质上,webpack loader 将所有类型的文件,转换为应用程序的依赖图(和最终的 bundle)可以直接引用的模块。
const path = require('path')
const config = {
module: {
rules: [{
test: /\.txt$/, use: 'raw-loader' }],
},
}
3、plugins:
插件相比于 loader,可以用于执行范围更广的任务,比如压缩打包,优化等。想要使用一个插件,你只需要 require() 它,然后把它添加到 plugins 数组中。
const HtmlWebpackPlugin = require('html-webpack-plugin') // 通过 npm 安装
const webpack = require('webpack') // 用于访问内置插件
const config = {
module: {
rules: [{
test: /\.txt$/, use: 'raw-loader' }],
},
plugins: [new HtmlWebpackPlugin({
template: './src/index.html' })],
}