本文目录
前言
继之前写过阿里编码规约对线程池的创建,关于线程池还想再写写自己的理解。
1、为啥要有线程池
2、线程池怎么创建
3、线程池是怎么运行的
4、Executors创建线程的弊端
下面来一一说一下自己的理解(有说的不对的还请同学不吝赐教)
一、为啥有线程池
我感觉线程池就像公交总站,那路上跑的不同线路的不同公交车就是一个个线程,倘若没有公交总站,每趟跑完的公交何去何从,直接销毁,再次跑的时候需要重头建一辆公交车,重建一辆还好,但是几千辆公交车都需要重新建,浪费资源不说,响应时间就更不用说了,车还没建好,我都走回家了,还要公交车干啥,而且公交车跑完之后无处安放,如何管理。
综上,有了公交总站,有三点好处:
一是降低资源的消耗,提高利用率;
二是提高响应时间,只要有可用的公交车,隔一段时间(很短)就可以继续提供服务了;
三是便于管理,公交车每次跑完都有地方可以安放,下次再运行的时候就直接从总站发车就行,不用到处找了,而且也可能找不到,因为可能已经销毁了。
以上类比与线程池就是公交总站,线程就是公交车,所以使用线程池的好处也显而易见,也是降低资源消耗,提高响应时间和便于管理。
因此使用线程池的好处还是大大的有的。
二、线程池怎么创建
关于线程池的使用场景,我在之前的工作中遇到过,可以看我之前的这篇博客
这里也再重温一下
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder()
.setNameFormat("thread-call-runner-%d")
.build();
ExecutorService taskExe = new ThreadPoolExecutor(4,6,200L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(),
namedThreadFactory,
new ThreadPoolExecutor.AbortPolicy());
我们来看一下ThreadPoolExecutor的源码
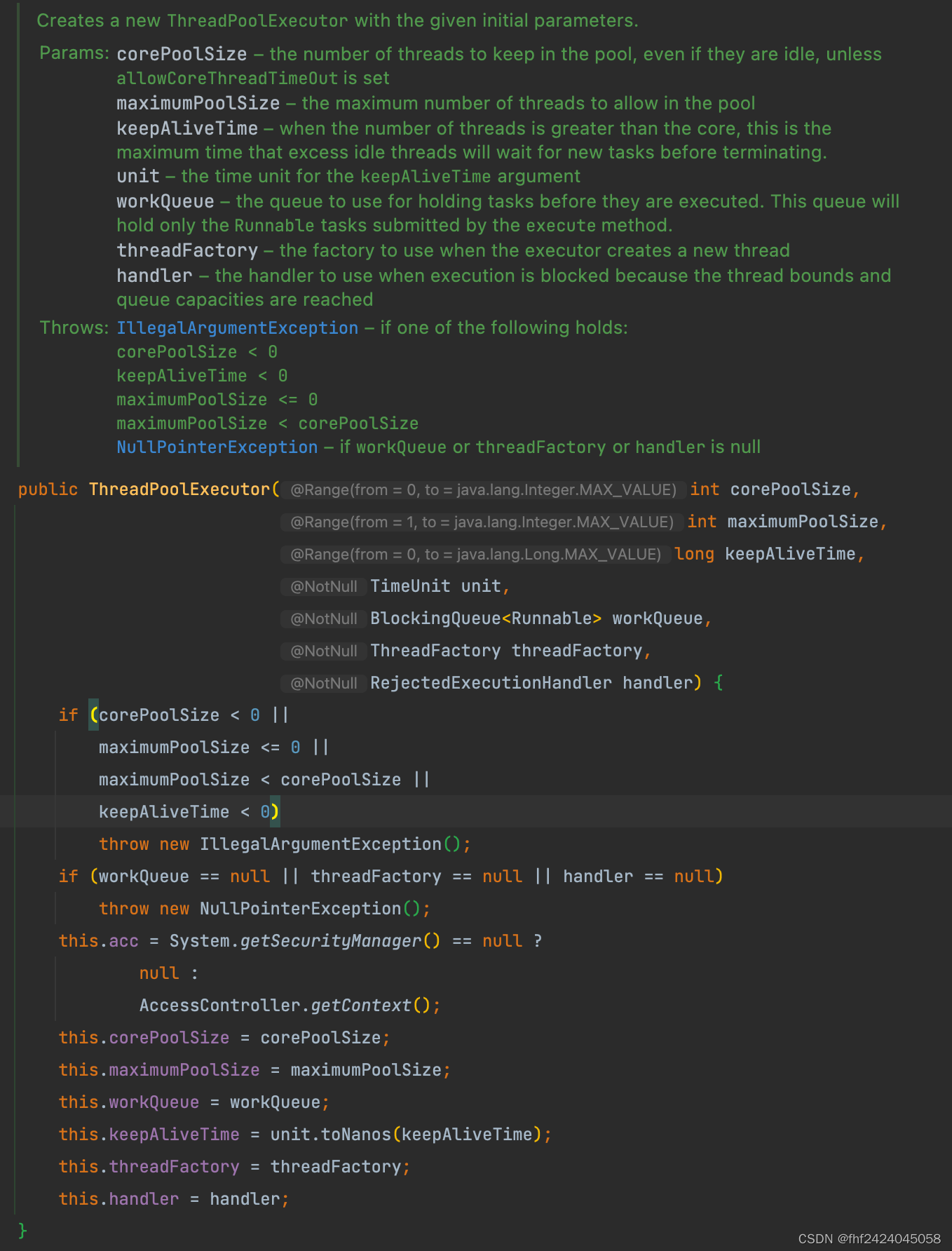
把里面的参数拎出来:
corePoolSize – the number of threads to keep in the pool, even if they are idle, unless allowCoreThreadTimeOut is set
maximumPoolSize – the maximum number of threads to allow in the pool
keepAliveTime – when the number of threads is greater than the core, this is the maximum time that excess idle threads will wait for new tasks before terminating.
unit – the time unit for the keepAliveTime argument
workQueue – the queue to use for holding tasks before they are executed. This queue will hold only the Runnable tasks submitted by the execute method.
threadFactory – the factory to use when the executor creates a new thread
handler – the handler to use when execution is blocked because the thread bounds and queue capacities are reached
中文again说明:
1、corePoolSize(核心线程数):一直在线程池中的线程数。当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。
2、maximumPoolSize(线程池最大大小):线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是如果使用了无界的任务队列这个参数就没什么效果。
3、keepAliveTime(线程活动保持时间):线程池中的超过核心线程数的空闲线程等待新的任务多久再进行销毁的时间,工作线程空闲后保持存活的时间。所以如果任务很多,并且每个任务执行的时间比较短,可以调大这个时间,提高线程的利用率。
4、unit(线程活动保持时间的单位):keepAliveTime的时间单位,可选的单位有天(DAYS),小时(HOURS),分钟(MINUTES),毫秒(MILLISECONDS),微秒(MICROSECONDS, 千分之一毫秒)和毫微秒(NANOSECONDS, 千分之一微秒)。
5、workQueue(任务队列):用于保存等待执行的任务的阻塞队列。可以选择以下几个阻塞队列。
- ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
- LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue,静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
- SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
- PriorityBlockingQueue:一个具有优先级得无限阻塞队列。
6、threadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字,Debug和定位问题时非常又帮助,比如我上面所自定义的线程的名字。
7、handler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。以下是JDK1.5提供的四种策略。
- AbortPolicy:不做任何处理,直接抛出异常。
- CallerRunsPolicy:用调用者所在的线程来执行任务。
- DiscardOldestPolicy:丢弃队列里最老的一个任务,并执行当前任。
- DiscardPolicy:不处理,丢弃掉。
当然也可以根据应用场景需要来实现RejectedExecutionHandler接口自定义策略。如记录日志或持久化不能处理的任务。
三、线程池是怎么运行的(亲试面试官真的很喜欢问的)
1、在创建了线程池后,等待提交过来的任务请求。
2、当调用execute()方法添加一个请求任务时,线程池会做如下判断:
- 2.1 如果正在运行的线程数小于核心数,那么会马上创建线程运行这个任务;
- 2.2如果正在运行的线程数大于或等于核心数,队列没有满,会将此任务放入队列中;
- 2.3如果队列已满,且运行的线程数小于最大线程数大于核心数,就会创建非核心线程运行此任务;
- 2.4 如果队列已满,且运行的线程数大于最大线程数,那么就会根据饱和策略来拒绝执行;
3、当一个线程完成任务会从队列中取下一个任务来执行;
4、当一个线程无事可做超过一定时间后,线程池会进行判断:如果当前运行的线程数大于核心数,此线程就会被停掉;
当线程池所有的任务完成后一段时间就会缩减到核心数;
四、Executors创建线程的弊端
1、newSingleThreadExecutor
核心和最大线程数都是1, 空闲存活时间为0 , 任务队列是无限长度的LinkedBlockingQueue。 默认异常拒绝策略。适用于任务持续加入但是任务数并不多的场景。
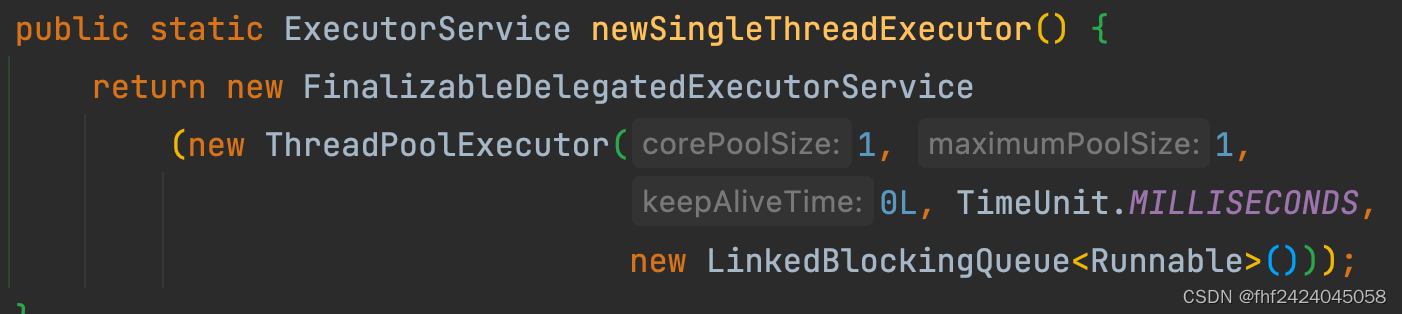
导致的问题:这个线程池的核心数和最大数一样都是1个,且任务队列是无界的LinkedBlockingQueue, 对于加进来的任务会无限制的存入队列, 如果使用不当很容易导致OOM。
2、newFixedThreadPool
核心线程和最大线程数都是自己传入的参数。 其他参数和 newSingleThreadExecutor一样,空闲存活时间为0 , 任务队列是无线长度的LinkedBlockingQueue。 默认异常拒绝策略。
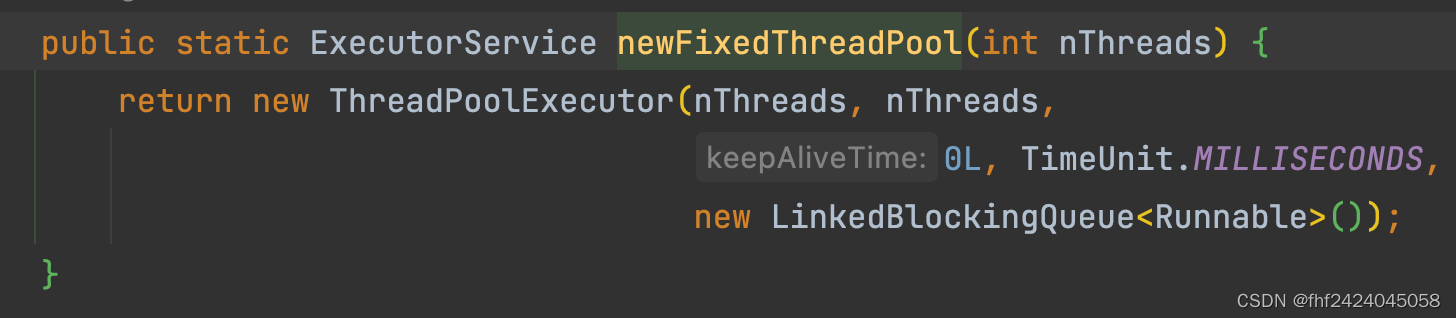
导致的问题:这个线程池的任务队列也是无界的LinkedBlockingQueue, 对于加进来的任务会无限制的存入队列, 如果使用不当很容易导致OOM。
3、ScheduledThreadPoolExecutor
这个是用于定时任务的线程池, 内部实现和上面三个都有不同。
核心线程是传入的参数,最大线程数是int上限, 默认存活时间是0, 任务队列使用DelayedWorkQueue, 拒绝策略异常策略。
加入任务的时候,会把任务和定时时间构建一个RunnableScheduledFuture对象,再把这个对象放入DelayedWorkQueue队列中,
DelayedWorkQueue是一个有序队列, 他会根据内部的RunnableScheduledFuture的运行时间排序内部对象。任务加入后就会启动一个线程。 这个线程会从DelayedWorkQueue中获取一个任务。

导致的问题:最大线程数和任务队列没有上限,可能发生前一次定时任务还没有完成, 后一个定时任务的运行时间到了, 它也会运行, 线程不够就创建,如果定时任务运行的时间过长, 就会导致前后两个定时任务同时执行,但如果他们之间有锁,就可能出现死锁,那就麻烦大了。
4、newCachedThreadPool
核心线程数是0 , 最大线程数是int上限,线程空闲存活时间1分钟。 默认异常拒绝策略,使用SynchronousQueue队列。它的特点:
由于核心数为0,每次有新的任务就会放到队列中,但队列却是阻塞的,除非有其他线程取走任务才能结束阻塞,所以每次添加任务如果没有空闲线程就会新建一个线程去执行。
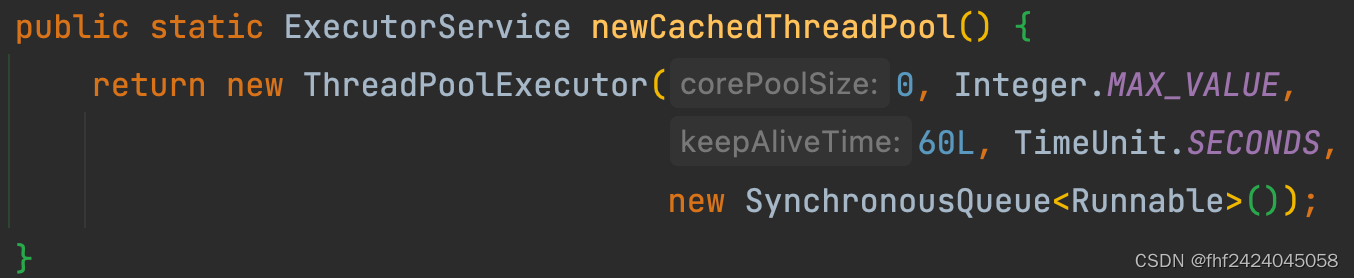
导致的问题:由于最大线程数是无限的, 任务队列是SynchronousQueue。 也就是说这个线程池对任务来着不拒,线程不够用就创建一个, 如果同一时刻应用的来了大量的任务, 很容易就创建过多的线程, 就容易导致应用卡顿或者直接OOM。
综上:
Executors各个方法的弊端:
1)newFixedThreadPool和newSingleThreadExecutor:
主要问题是任务队列是无界的,可能会耗费非常大的内存,甚至OOM。
2)newCachedThreadPool和newScheduledThreadPool:
主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。
所以这就是为什么阿里规约不建议使用它的原因!
-------------你知道的越多,不知道的越多---------------