PyTorch指定GPU
千次阅读
2021-11-13 23:44:39
PyTorch指定GPU
1. 设置可见GPU
2. 终端运行时设定
3. 代码中设定
看后台显卡使用情况(每1s刷新一次) watch -n 1 nvidia-smi
- 设置可见GPU
注意!!!!!!!!!!!!!!
os.environ[“CUDA_VISIBLE_DEVICES”] = "0, 1, 2"此条命令运行必须放在import torch之前,否则不能生效!!!!!!!!!!!!!!!!!!!此条坑了我一上午
当然还是建议这条方法或者第二条,这样设置了以后对程序可见的卡就固定在这几张了,不会对他人正在使用的卡产生任何影响
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1, 2"
- 终端运行时设定
CUDA_VISIBLE_DEVICES=1,2,3 python train.py
- 代码中设定
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "2,3,4,5"
#将模型放入GPU中
if torch.cuda.device_count() > 1:
model = torch.nn.DataParallel(model, device_ids=[0,1,2,3])
等价于
if torch.cuda.device_count() > 1:
model = torch.nn.DataParallel(model, device_ids=[2,3,4,5])
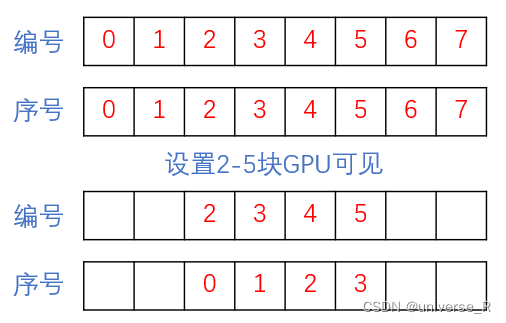
这是因为在第一段中已经设置了可见GPU为2,3,4,5,就是说假设我们有八块GPU,序号分别为0,1,2,3,4,5,6,7,本来他们的编号也分别为0,1,2,3,4,5,6,7,但是因为设置了可见GPU为2,3,4,5所以我们选取的GPU的序号为2,3,4,5,但是对于程序来说他们的编号分别为[0,1,2,3],如下图所示
原文链接:https://www.csdn.net/tags/MtTaEg0sNDg1MDk5LWJsb2cO0O0O.html
pytorch教程原文:Optional: Data Parallelism
pytorch:
https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html#optional-data-parallelism
GitHub::
https://github.com/pytorch/tutorials/blob/master/beginner_source/blitz/data_parallel_tutorial.py
"""
Optional: Data Parallelism
==========================
**Authors**: `Sung Kim <https://github.com/hunkim>`_ and `Jenny Kang <https://github.com/jennykang>`_
In this tutorial, we will learn how to use multiple GPUs using ``DataParallel``.
It's very easy to use GPUs with PyTorch. You can put the model on a GPU:
.. code:: python
device = torch.device("cuda:0")
model.to(device)
Then, you can copy all your tensors to the GPU:
.. code:: python
mytensor = my_tensor.to(device)
Please note that just calling ``my_tensor.to(device)`` returns a new copy of
``my_tensor`` on GPU instead of rewriting ``my_tensor``. You need to assign it to
a new tensor and use that tensor on the GPU.
It's natural to execute your forward, backward propagations on multiple GPUs.
However, Pytorch will only use one GPU by default. You can easily run your
operations on multiple GPUs by making your model run parallelly using
``DataParallel``:
.. code:: python
model = nn.DataParallel(model)
That's the core behind this tutorial. We will explore it in more detail below.
"""
######################################################################
# Imports and parameters
# ----------------------
#
# Import PyTorch modules and define parameters.
#
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# Parameters and DataLoaders
input_size = 5
output_size = 2
batch_size = 30
data_size = 100
######################################################################
# Device
#
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
######################################################################
# Dummy DataSet
# -------------
#
# Make a dummy (random) dataset. You just need to implement the
# getitem
#
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size),
batch_size=batch_size, shuffle=True)
######################################################################
# Simple Model
# ------------
#
# For the demo, our model just gets an input, performs a linear operation, and
# gives an output. However, you can use ``DataParallel`` on any model (CNN, RNN,
# Capsule Net etc.)
#
# We've placed a print statement inside the model to monitor the size of input
# and output tensors.
# Please pay attention to what is printed at batch rank 0.
#
class Model(nn.Module):
# Our model
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print("\tIn Model: input size", input.size(),
"output size", output.size())
return output
######################################################################
# Create Model and DataParallel
# -----------------------------
#
# This is the core part of the tutorial. First, we need to make a model instance
# and check if we have multiple GPUs. If we have multiple GPUs, we can wrap
# our model using ``nn.DataParallel``. Then we can put our model on GPUs by
# ``model.to(device)``
#
model = Model(input_size, output_size)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs
model = nn.DataParallel(model)
model.to(device)
######################################################################
# Run the Model
# -------------
#
# Now we can see the sizes of input and output tensors.
#
for data in rand_loader:
input = data.to(device)
output = model(input)
print("Outside: input size", input.size(),
"output_size", output.size())
######################################################################
# Results
# -------
#
# If you have no GPU or one GPU, when we batch 30 inputs and 30 outputs, the model gets 30 and outputs 30 as
# expected. But if you have multiple GPUs, then you can get results like this.
#
# 2 GPUs
# ~~~~~~
#
# If you have 2, you will see:
#
# .. code:: bash
#
# # on 2 GPUs
# Let's use 2 GPUs!
# In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
# In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
# Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
# In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
# In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
# Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
# In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
# In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
# Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
# In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])
# In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])
# Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
#
# 3 GPUs
# ~~~~~~
#
# If you have 3 GPUs, you will see:
#
# .. code:: bash
#
# Let's use 3 GPUs!
# In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
# In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
# In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
# Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
# In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
# In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
# In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
# Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
# In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
# In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
# In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
# Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
# Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
#
# 8 GPUs
# ~~~~~~~~~~~~~~
#
# If you have 8, you will see:
#
# .. code:: bash
#
# Let's use 8 GPUs!
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
# In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
# Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
# In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
# In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
# In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
# In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
# In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
# Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
#
######################################################################
# Summary
# -------
#
# DataParallel splits your data automatically and sends job orders to multiple
# models on several GPUs. After each model finishes their job, DataParallel
# collects and merges the results before returning it to you.
#
# For more information, please check out
# https://pytorch.org/tutorials/beginner/former\_torchies/parallelism\_tutorial.html.
#
其实正如GitHub文章和pytorch文章所说的核心的代码只有:
model = Model(input_size, output_size)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs
model = nn.DataParallel(model)
model.to(device)
其他的和单gpu的代码一样