
Title:Deep Unrestricted Document Image Rectification
Paper:https://arxiv.org/pdf/2304.08796.pdf
Code:https://github.com/fh2019ustc/DocTr-Plus
Demo:https://doctrp.docscanner.top/
导读
近年来,随着文档数字化的需求日益增加,文档图像矫正领域取得了显著进展。然而,现有的基于深度学习的解决方案多仅限于处理限定场景下的文档图像,即输入图像须包含完整的文档。当输入的文档图像仅包含局部区域而不包含完整的文档边界时,矫正质量会受到明显影响。为了解决这一问题,作者团队提出 DocTr++,一种面向各类文档图像的无约束统一矫正框架。
引言
如下图展示了三类常见的形变文档图像:(a) 包含完整文档边界, (b) 包含部分文档边界, © 不包含文档边界。

现有的矫正方法多是聚焦于有边界的文档矫正,即 (a) 对应的图像类型,而对于后两种形变图像的矫正效果欠佳。本方法可以实现对文档边界不全或无边界文档的矫正恢复。
作者团队采用了多尺度的编码器-解码器结构进行有效的特征编解码,并且重新定义了各类形变文档图像与无形变文档图像之间的逐像素映射关系。此外,作者团队还贡献了一个新的无约束文档图像测试基准及其适用的评价指标,以便研究人员对该方法进行后续的验证和改进。
通过定量实验和定性对比,作者团队验证了 DocTr++ 的性能优势及泛化性,并在现有及所提出的基准测试中刷新了多项最佳记录。
方法
作为开始,给出一张框架图,其非常生动形象的展示了本方法的核心思想:
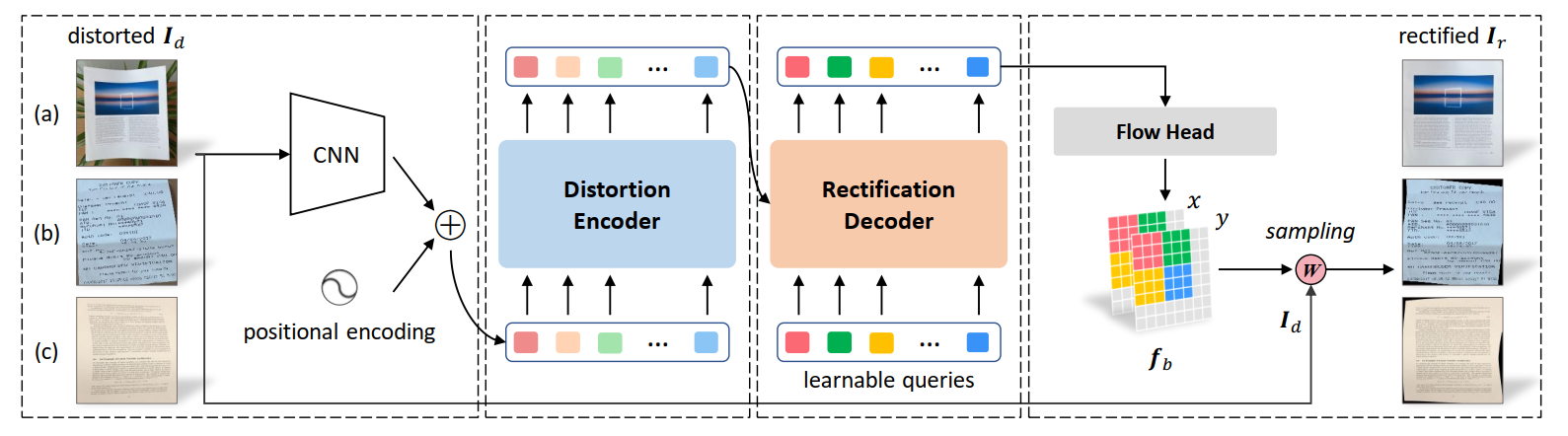
如上图所示,本方法致力于弥补现有的基于深度学习的方法在应用场景上的不足。具体地,现有的基于深度学习的方法,大多只能矫正文档完整的图像,即文档的四条边完整地出现在输入图像中。
然而,在实际应用时,用户可能只关注于文档的部分区域或内容。例如,在教育场景中,用户可能只想分享书本中的某一道题目。
为了解决这一局限性,在我们的方法中,输入包含各类常见的形变文档图像,包含(a)有完整文档边界的图像,(b)有部分文档边界的图像,以及(c)无文档边界的图像。
我们的方法包含三个主要组件:(a) 畸变特征编码器,(b) 矫正解码器,和 © 坐标映射预测器。
首先, 在畸变特征编码器中,我们采用自注意力机制捕获形变文档的结构特征,并构建多尺度编码器提取和融合这些特征。编码器由三个子模块组成,每个子模块包含两个标准的 Transformer 编码层。这使得本方法既能编码具有高分辨率纹理细节的特征,又能获得低分辨率具有高层语义信息的特征。
接下来,矫正解码器接收编码器输出的多尺度特征以及可学习的矫正提示向量序列(learnable queries),输出解码后的表征用于后续坐标映射矩阵的预测。其中,可学习的矫正提示向量序列零初始化,并加上固定的位置编码。实验发现,每一个矫正提示向量会关注输入形变文档图像中的某一特定区域 (如下图所示),这些区域组合起来便覆盖整张输入图像。同样,解码器由三个子模块组成,每个子模块包含两个标准的 Transformer 解码层。

最后,在坐标映射预测器中,本方法根据解码器输出的特征来预测矫正图像所需的坐标映射矩阵。根据坐标映射矩阵中每一个坐标,基于双线性插值算法重采样出输入形变图像中对应的像素,填入输出图像中。在对所有映射坐标并行执行此操作后,本方法获得完整的矫正图像。
评价指标

在这篇文章中,作者团队提出了两种新的评价指标 MSSIM-M 和 LD-M,用于通用形变文档图像矫正质量的评估。因为边界不完整的形变文档图像在矫正后可能会出现像素缺失,如上图所示,本文将有效像素区域的掩膜矩阵与目标图像进行矩阵乘法,得到更适宜进行评价的目标图像。如下图所示,与传统的 MSSIM 和 LD 指标相比,改进后的 MSSIM-M 和 LD-M 更为稳健和可靠。

实验
本文在公开的有边界形变文档图像测试基准和本文新提出的通用形变文档图像测试基准上都进行了性能评估,在两种数据集上都展现了优异的性能。

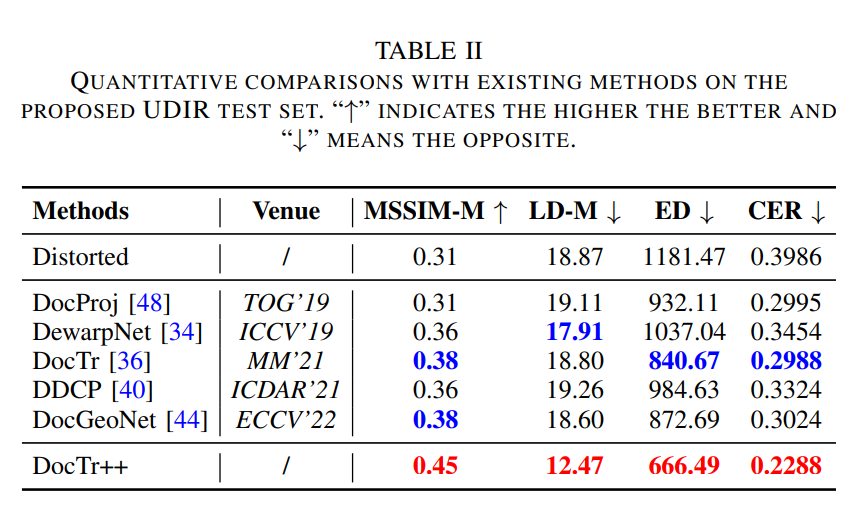


可以直观地看出,本方法在有边界和边界不全两种情况下都实现了有效的矫正。
效果展示
下图展示了各类形变文档图像的矫正结果,包括试卷、文本段落、书页、手写文档等。

作者团队还提供了一个在线Demo供大家自行体验:
https://doctrp.docscanner.top/

总结
本文介绍了一种全新的通用形变文档图像矫正框架,作者团队的方法突破了现有多数矫正方法的场景局限性,能够恢复日常生活中常见的各种形变文档图像。为了实现优秀的矫正效果,作者团队采用了一种多尺度编解码器结构,构建各类形变文档图像与无形变文档图像之间的逐像素映射关系。此外,该团队还贡献了一个真实场景的测试基准和新的评估指标,以评估各类真实文档图像的矫正质量。
通过在公开的测试基准和本工作提出的测试基准上进行大量实验,验证了该方法的有效性和鲁棒性。作者团队希望能为未来本领域研究提供一个强有力的基准方法,为进一步研究和发展通用形变文档图像矫正方法提供基础。
CVHub是一家专注于计算机视觉领域的高质量知识分享平台,全站技术文章原创率常年高达99%,每日为您呈献全方位、多领域、有深度的前沿AI论文解决及配套的行业级应用解决方案,提供科研 | 技术 | 就业一站式服务,涵盖有监督/半监督/无监督/自监督的各类2D/3D的检测/分类/分割/跟踪/姿态/超分/重建等全栈领域以及最新的AIGC等生成式模型。欢迎关注微信公众号CVHub或添加小编好友:cv_huber,备注“知乎”,参与实时的学术&技术互动交流,领取CV学习大礼包,及时订阅最新的国内外大厂校招&社招资讯!