
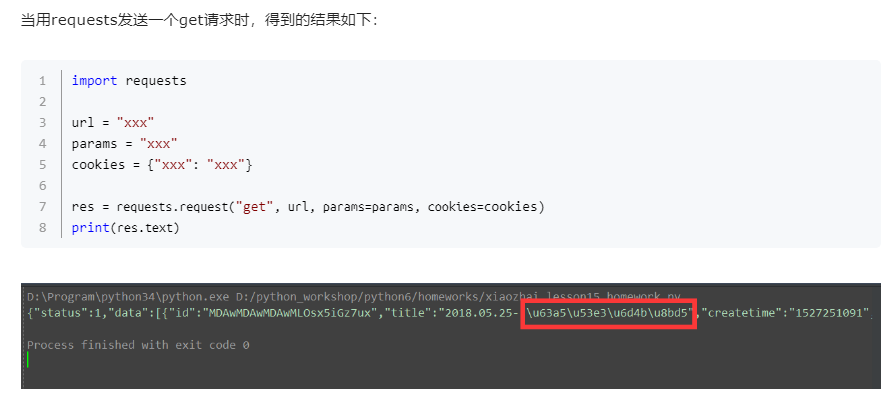
那么,问题来了,\u表示的那一 串unicode编码, 怎么转换成中文,可以用下面的命令
print(res.text.encode().decode("unicode_escape"))

那么问题来了,这个unicode-escape什么来的呢
在python中,对于unicode存储时,可以采用另一种方法:
将unicode的内存编码值进行存储,读取文件时在反向转换回来。这里就采用了unicode-escape的方式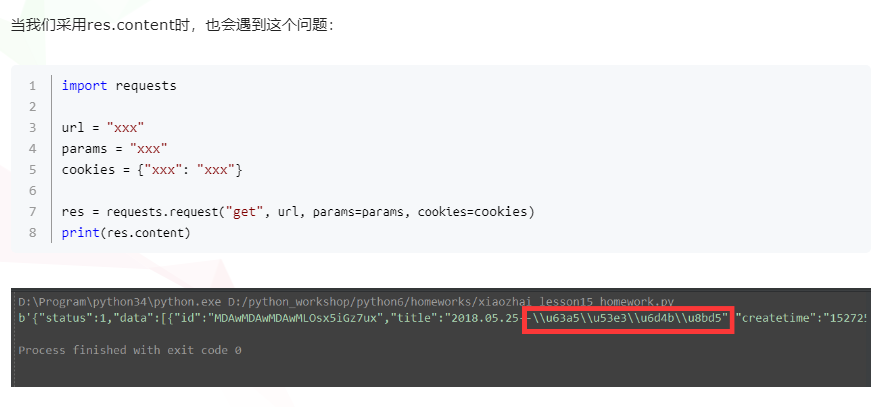
解决办法:
print(res.content.decode("unicode_escape"))

如果type(text) is bytes,那么
text.decode("unicode_escape")
如果type(text) is str,那么
text.encode('utf-8').decode('unicode_escape')