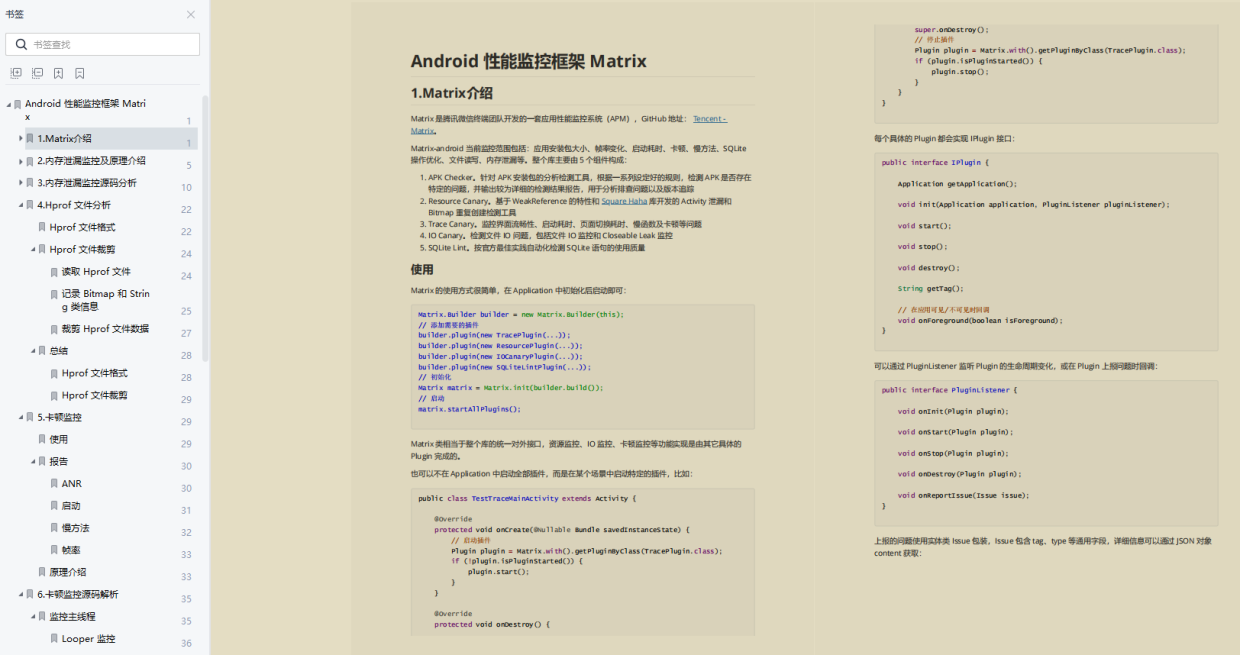
作者:leafjia
ANR监控是一个非常有年代感的话题了,但是市面上的ANR监控工具,或者并非真正意义上的ANR的监控(而是5秒卡顿监控);或者并不完善,监控不到到所有的ANR。而想要得到一个完善的ANR监控工具,必须要先了解系统整个ANR的流程。本文分析了ANR的主要流程,给出了一个完善的ANR监控方案。该方案已经在Android微信客户端上经过全量验证,稳定地运行了一年多的时间。

我们知道ANR流程基本都是在system_server系统进程完成的,系统进程的行为我们很难监控和改变,想要监控ANR就必须找到系统进程跟我们自己的应用进程是否有交互,如果有,两者交互的边界在哪里,边界上应用一端的行为,才是我们比较容易能监控到的,想要要找到这个边界,我们就必须要了解ANR的流程。
一、ANR流程
无论ANR的来源是哪里,最终都会走到ProcessRecord中的appNotResponding,这个方法包括了ANR的主要流程,所以也比较长,我们找出一些关键的逻辑来分析:frameworks/base/services/core/java/com/android/server/am/ProcessRecord.java:
void appNotResponding(String activityShortComponentName, ApplicationInfo aInfo,
String parentShortComponentName, WindowProcessController parentProcess,
boolean aboveSystem, String annotation, boolean onlyDumpSelf) {
//......
final boolean isSilentAnr;
synchronized (mService) {
// PowerManager.reboot() can block for a long time, so ignore ANRs while shutting down.
if (mService.mAtmInternal.isShuttingDown()) {
Slog.i(TAG, "During shutdown skipping ANR: " + this + " " + annotation);
return;
} else if (isNotResponding()) {
Slog.i(TAG, "Skipping duplicate ANR: " + this + " " + annotation);
return;
} else if (isCrashing()) {
Slog.i(TAG, "Crashing app skipping ANR: " + this + " " + annotation);
return;
} else if (killedByAm) {
Slog.i(TAG, "App already killed by AM skipping ANR: " + this + " " + annotation);
return;
} else if (killed) {
Slog.i(TAG, "Skipping died app ANR: " + this + " " + annotation);
return;
}
// In case we come through here for the same app before completing
// this one, mark as anring now so we will bail out.
setNotResponding(true);
// Log the ANR to the event log.
EventLog.writeEvent(EventLogTags.AM_ANR, userId, pid, processName, info.flags,
annotation);
// Dump thread traces as quickly as we can, starting with "interesting" processes.
firstPids.add(pid);
// Don't dump other PIDs if it's a background ANR or is requested to only dump self.
isSilentAnr = isSilentAnr();
//......
}
先是一长串if else,给出了几种比较极端的情况,会直接return,而不会产生一个ANR,这些情况包括:进程正在处于正在关闭的状态,正在crash的状态,被kill的状态,或者相同进程已经处在ANR的流程中。
另外很重要的一个逻辑就是判断当前ANR是否是一个SilentAnr,所谓“沉默的ANR”,其实就是后台ANR,后台ANR跟前台ANR会有不同的表现:前台ANR会弹无响应的Dialog,后台ANR会直接杀死进程。前后台ANR的判断的原则是:**如果发生ANR的进程对用户来说是有感知的,就会被认为是前台ANR,否则是后台ANR。**另外,如果在开发者选项中勾选了“显示后台ANR”,那么全部ANR都会被认为是前台ANR。
我们继续分析这个方法:
if (!isSilentAnr && !onlyDumpSelf) {
int parentPid = pid;
if (parentProcess != null && parentProcess.getPid() > 0) {
parentPid = parentProcess.getPid();
}
if (parentPid != pid) firstPids.add(parentPid);
if (MY_PID != pid && MY_PID != parentPid) firstPids.add(MY_PID);
for (int i = getLruProcessList().size() - 1; i >= 0; i--) {
ProcessRecord r = getLruProcessList().get(i);
if (r != null && r.thread != null) {
int myPid = r.pid;
if (myPid > 0 && myPid != pid && myPid != parentPid && myPid != MY_PID) {
if (r.isPersistent()) {
firstPids.add(myPid);
if (DEBUG_ANR) Slog.i(TAG, "Adding persistent proc: " + r);
} else if (r.treatLikeActivity) {
firstPids.add(myPid);
if (DEBUG_ANR) Slog.i(TAG, "Adding likely IME: " + r);
} else {
lastPids.put(myPid, Boolean.TRUE);
if (DEBUG_ANR) Slog.i(TAG, "Adding ANR proc: " + r);
}
}
}
}
}
//......
// don't dump native PIDs for background ANRs unless it is the process of interest
String[] nativeProcs = null;
if (isSilentAnr || onlyDumpSelf) {
for (int i = 0; i < NATIVE_STACKS_OF_INTEREST.length; i++) {
if (NATIVE_STACKS_OF_INTEREST[i].equals(processName)) {
nativeProcs = new String[] { processName };
break;
}
}
} else {
nativeProcs = NATIVE_STACKS_OF_INTEREST;
}
int[] pids = nativeProcs == null ? null : Process.getPidsForCommands(nativeProcs);
ArrayList<Integer> nativePids = null;
if (pids != null) {
nativePids = new ArrayList<>(pids.length);
for (int i : pids) {
nativePids.add(i);
}
}
发生ANR后,为了能让开发者知道ANR的原因,方便定位问题,会dump很多信息到ANR Trace文件里,上面的逻辑就是选择需要dump的进程。ANR Trace文件是包含许多进程的Trace信息的,因为产生ANR的原因有可能是其他的进程抢占了太多资源,或者IPC到其他进程(尤其是系统进程)的时候卡住导致的。
选择需要dump的进程是一段挺有意思逻辑,我们稍微分析下:需要被dump的进程被分为了firstPids、nativePids以及extraPids三类:
-
firstPIds:firstPids是需要首先dump的重要进程,发生ANR的进程无论如何是一定要被dump的,也是首先被dump的,所以第一个被加到firstPids中。如果是SilentAnr(即后台ANR),不用再加入任何其他的进程。如果不是,需要进一步添加其他的进程:如果发生ANR的进程不是system_server进程的话,需要添加system_server进程;接下来轮询AMS维护的一个LRU的进程List,如果最近访问的进程包含了persistent的进程,或者带有BIND_TREAT_LIKE_ACTVITY标签的进程,都添加到firstPids中。
-
extraPids:LRU进程List中的其他进程,都会首先添加到lastPids中,然后lastPids会进一步被选出最近CPU使用率高的进程,进一步组成extraPids;
-
nativePids:nativePids最为简单,是一些固定的native的系统进程,定义在WatchDog.java中。
拿到需要dump的所有进程的pid后,AMS开始按照firstPids、nativePids、extraPids的顺序dump这些进程的堆栈:
File tracesFile = ActivityManagerService.dumpStackTraces(firstPids,
isSilentAnr ? null : processCpuTracker, isSilentAnr ? null : lastPids,
nativePids, tracesFileException, offsets);
这里也是我们需要重点分析的地方,我们继续看这里做了什么,跟到AMS里面,
frameworks/base/services/core/java/com/android/server/am/ActivityManagerService.java:
public static Pair<Long, Long> dumpStackTraces(String tracesFile, ArrayList<Integer> firstPids,
ArrayList<Integer> nativePids, ArrayList<Integer> extraPids) {
long remainingTime = 20 * 1000;
//......
if (firstPids != null) {
int num = firstPids.size();
for (int i = 0; i < num; i++) {
//......
final long timeTaken = dumpJavaTracesTombstoned(pid, tracesFile,
remainingTime);
remainingTime -= timeTaken;
if (remainingTime <= 0) {
Slog.e(TAG, "Aborting stack trace dump (current firstPid=" + pid
+ "); deadline exceeded.");
return firstPidStart >= 0 ? new Pair<>(firstPidStart, firstPidEnd) : null;
}
//......
}
}
//......
}
我们首先关注到remainingTime,这是一个重要的变量,规定了我们dump所有进程的最长时间,因为dump进程所有线程的堆栈,本身就是一个重操作,何况是要dump许多进程,所以规定了发生ANR之后,dump全部进程的总时间不能超过20秒,如果超过了,马上返回,确保ANR弹窗可以及时的弹出(或者被kill掉)。我们继续跟到dumpJavaTracesTombstoned
private static long dumpJavaTracesTombstoned(int pid, String fileName, long timeoutMs) {
final long timeStart = SystemClock.elapsedRealtime();
boolean javaSuccess = Debug.dumpJavaBacktraceToFileTimeout(pid, fileName,
(int) (timeoutMs / 1000));
//......
return SystemClock.elapsedRealtime() - timeStart;
}
再一路追到native层负责dump堆栈的system/core/debuggerd/client/debuggerd_client.cpp:
bool debuggerd_trigger_dump(pid_t tid, DebuggerdDumpType dump_type, unsigned int timeout_ms, unique_fd output_fd) {
pid_t pid = tid;
//......
// Send the signal.
const int signal = (dump_type == kDebuggerdJavaBacktrace) ? SIGQUIT : BIONIC_SIGNAL_DEBUGGER;
sigval val = {.sival_int = (dump_type == kDebuggerdNativeBacktrace) ? 1 : 0};
if (sigqueue(pid, signal, val) != 0) {
log_error(output_fd, errno, "failed to send signal to pid %d", pid);
return false;
}
//......
LOG(INFO) << TAG "done dumping process " << pid;
return true;
}
**来了来了!之前说的交互边界终于找到了!**这里会通过sigqueue向需要dump堆栈的进程发送SIGQUIT信号,也就是signal 3信号,而发生ANR的进程是一定会被dump的,也是第一个被dump的。这就意味着,只要我们能监控到系统发送的SIGQUIT信号,也许就能够监控到发生了ANR。
每一个应用进程都会有一个SignalCatcher线程,专门处理SIGQUIT,来到art/runtime/signal_catcher.cc:
void* SignalCatcher::Run(void* arg) {
//......
// Set up mask with signals we want to handle.
SignalSet signals;
signals.Add(SIGQUIT);
signals.Add(SIGUSR1);
while (true) {
int signal_number = signal_catcher->WaitForSignal(self, signals);
if (signal_catcher->ShouldHalt()) {
runtime->DetachCurrentThread();
return nullptr;
}
switch (signal_number) {
case SIGQUIT:
signal_catcher->HandleSigQuit();
break;
case SIGUSR1:
signal_catcher->HandleSigUsr1();
break;
default:
LOG(ERROR) << "Unexpected signal %d" << signal_number;
break;
}
}
}
WaitForSignal方法调用了sigwait方法,这是一个阻塞方法。这里的死循环,就会一直不断的等待监听SIGQUIT和SIGUSR1这两个信号的到来。
整理一下ANR的过程:**当应用发生ANR之后,系统会收集许多进程,来dump堆栈,从而生成ANR Trace文件,收集的第一个,也是一定会被收集到的进程,就是发生ANR的进程,接着系统开始向这些应用进程发送SIGQUIT信号,应用进程收到SIGQUIT后开始dump堆栈。**来简单画个示意图:

所以,事实上进程发生ANR的整个流程,也只有dump堆栈的行为会在发生ANR的进程中执行。这个过程从收到SIGQUIT开始(圈1),到使用socket写Trace(圈2)结束,然后再继续回到server进程完成剩余的ANR流程。我们就在这两个边界上做做文章。
首先我们肯定会想到,我们能否监听到syste_server发送给我们的SIGQUIT信号呢?如果可以,我们就成功了一半。
二、监控SIGQUIT信号
Linux系统提供了两种监听信号的方法,一种是SignalCatcher线程使用的sigwait方法进行同步、阻塞地监听,另一种是使用sigaction方法注册signal handler进行异步监听,我们都来试试。
2.1. sigwait
我们首先尝试前一种方法,模仿SignalCatcher线程,做一模一样的事情,通过一个死循环sigwait,一直监听SIGQUIT:
static void *mySigQuitCatcher(void* args) {
while (true) {
int sig;
sigset_t sigSet;
sigemptyset(&sigSet);
sigaddset(&sigSet, SIGQUIT);
sigwait(&sigSet, &sig);
if (sig == SIGQUIT) {
//Got SIGQUIT
}
}
}
pthread_t pid;
pthread_create(&pid, nullptr, mySigQuitCatcher, nullptr);
pthread_detach(pid);
这个时候就有了两个不同的线程sigwait同一个SIGQUIT,具体会走到哪个呢,我们在sigwait的文档中找到了这样的描述(sigwait方法是由sigwaitinfo方法实现的):

原来当有两个线程通过sigwait方法监听同一个信号时,具体是哪一个线程收到信号时不能确定的。不确定可不行,当然不满足我们的需求。
3.2. Signal Handler
那我们再试下另一种方法是否可行,我们通过可以sigaction方法,建立一个Signal Handler:
void signalHandler(int sig, siginfo_t* info, void* uc) {
if (sig == SIGQUIT) {
//Got An ANR
}
}
struct sigaction sa;
sa.sa_sigaction = signalHandler;
sa.sa_flags = SA_ONSTACK | SA_SIGINFO | SA_RESTART;
sigaction(SIGQUIT, &sa, nullptr);
建立了Signal Handler之后,我们发现在同时有sigwait和signal handler的情况下,信号没有走到我们的signal handler而是依然被系统的Signal Catcher线程捕获到了,这是什么原因呢?
原来是Android默认把SIGQUIT设置成了BLOCKED,所以只会响应sigwait而不会进入到我们设置的handler方法中。我们通过pthread_sigmask或者sigprocmask把SIGQUIT设置为UNBLOCK,那么再次收到SIGQUIT时,就一定会进入到我们的handler方法中。需要这样设置:
sigset_t sigSet;
sigemptyset(&sigSet);
sigaddset(&sigSet, SIGQUIT);
pthread_sigmask(SIG_UNBLOCK, &sigSet, nullptr);
最后需要注意,我们通过Signal Handler抢到了SIGQUIT后,原本的Signal Catcher线程中的sigwait就不再能收到SIGQUIT了,原本的dump堆栈的逻辑就无法完成了,我们为了ANR的整个逻辑和流程跟原来完全一致,需要在Signal Handler里面重新向Signal Catcher线程发送一个SIGQUIT:
int tid = getSignalCatcherThreadId(); //遍历/proc/[pid]目录,找到SignalCatcher线程的tid
tgkill(getpid(), tid, SIGQUIT);
(如果缺少了重新向SignalCatcher发送SIGQUIT的步骤,AMS就一直等不到ANR进程写堆栈,直到20秒超时后,才会被迫中断,而继续之后的流程。直接的表现就是ANR弹窗非常慢(20秒超时时间),并且/data/anr目录下无法正常生成完整的 ANR Trace文件。)
以上就得到了一个不改变系统行为的前提下,比较完善的监控SIGQUIT信号的机制,这也是我们监控ANR的基础。
三、完善的ANR监控方案
监控到SIGQUIT信号并不等于就监控到了ANR。
3.1. 误报
充分非必要条件1:发生ANR的进程一定会收到SIGQUIT信号;但是收到SIGQUIT信号的进程并不一定发生了ANR。
考虑下面两种情况:
-
其他进程的ANR:上面提到过,发生ANR之后,发生ANR的进程并不是唯一需要dump堆栈的进程,系统会收集许多其他的进程进行dump,也就是说当一个应用发生ANR的时候,其他的应用也有可能收到SIGQUIT信号。进一步,我们监控到SIGQUIT时,可能是监听到了其他进程产生的ANR**,从而产生误报。**
-
非ANR发送SIGQUIT:发送SIGQUIT信号其实是很容易的一件事情,开发者和厂商都可以很容易的发送一个SIGQUIT(java层调用android.os.Process.sendSignal方法;Native层调用kill或者tgkill方法),所以我们可能会收到非ANR流程发送的SIGQUIT信号,从而产生误报。
怎么解决这些误报的问题呢,我重新回到ANR流程开始的地方:
void appNotResponding(String activityShortComponentName, ApplicationInfo aInfo,
String parentShortComponentName, WindowProcessController parentProcess,
boolean aboveSystem, String annotation, boolean onlyDumpSelf) {
//......
synchronized (mService) {
if (isSilentAnr() && !isDebugging()) {
kill("bg anr", ApplicationExitInfo.REASON_ANR, true);
return;
}
// Set the app's notResponding state, and look up the errorReportReceiver
makeAppNotRespondingLocked(activityShortComponentName,
annotation != null ? "ANR " + annotation : "ANR", info.toString());
// show ANR dialog ......
}
}
private void makeAppNotRespondingLocked(String activity, String shortMsg, String longMsg) {
setNotResponding(true);
// mAppErrors can be null if the AMS is constructed with injector only. This will only
// happen in tests.
if (mService.mAppErrors != null) {
notRespondingReport = mService.mAppErrors.generateProcessError(this,
ActivityManager.ProcessErrorStateInfo.NOT_RESPONDING,
activity, shortMsg, longMsg, null);
}
startAppProblemLocked();
getWindowProcessController().stopFreezingActivities();
}
在ANR弹窗前,会执行到makeAppNotRespondingLocked方法中,在这里会给发生ANR进程标记一个NOT_RESPONDING的flag。而这个flag我们可以通过ActivityManager来获取:
private static boolean checkErrorState() {
try {
Application application = sApplication == null ? Matrix.with().getApplication() : sApplication;
ActivityManager am = (ActivityManager) application.getSystemService(Context.ACTIVITY_SERVICE);
List<ActivityManager.ProcessErrorStateInfo> procs = am.getProcessesInErrorState();
if (procs == null) return false;
for (ActivityManager.ProcessErrorStateInfo proc : procs) {
if (proc.pid != android.os.Process.myPid()) continue;
if (proc.condition != ActivityManager.ProcessErrorStateInfo.NOT_RESPONDING) continue;
return true;
}
return false;
} catch (Throwable t){
MatrixLog.e(TAG,"[checkErrorState] error : %s", t.getMessage());
}
return false;
}
监控到SIGQUIT后,我们在20秒内(20秒是ANR dump的timeout时间)不断轮询自己是否有NOT_RESPONDING对flag,一旦发现有这个flag,那么马上就可以认定发生了一次ANR。
(你可能会想,有这么方便的方法,监控SIGQUIT信号不是多余的吗?直接一个死循环,不断轮训这个flag不就完事了?是的,理论上确实能这么做,但是这么做过于的低效、耗电和不环保外,更关键的是,下面漏报的问题依然无法解决)
另外,Signal Handler回调的第二个参数siginfo_t,也包含了一些有用的信息,该结构体的第三个字段si_code表示该信号被发送的方法,SI_USER表示信号是通过kill发送的,SI_QUEUE表示信号是通过sigqueue发送的。但在Android的ANR流程中,高版本使用的是sigqueue发送的信号,某些低版本使用的是kill发送的信号,并不统一。
而第五个字段(极少数机型上是第四个字段)si_pid表示的是发送该信号的进程的pid,这里适用几乎所有Android版本和机型的一个条件是:如果发送信号的进程是自己的进程,那么一定不是一个ANR。可以通过这个条件排除自己发送SIGQUIT,而导致误报的情况。
3.2. 漏报
充分非必要条件2:进程处于NOT_RESPONDING的状态可以确认该进程发生了ANR。但是发生ANR的进程并不一定会被设置为NOT_RESPONDING状态。
考虑下面两种情况:
-
**后台ANR(SilentAnr):**之前分析ANR流程我们可以知道,如果ANR被标记为了后台ANR(即SilentAnr),那么杀死进程后就会直接return,并不会走到产生进程错误状态的逻辑。这就意味着,后台ANR没办法捕捉到,而后台ANR的量同样非常大,并且后台ANR会直接杀死进程,对用户的体验也是非常负面的,这么大一部分ANR监控不到,当然是无法接受的。
-
**闪退ANR:**除此之外,我们还发现相当一部分机型(例如OPPO、VIVO两家的高Android版本的机型)修改了ANR的流程,即使是发生在前台的ANR,也并不会弹窗,而是直接杀死进程,即闪退。这部分的机型覆盖的用户量也非常大。并且,确定两家今后的新设备会一直维持这个机制。
所以我们需要一种方法,在收到SIGQUIT信号后,能够非常快速的侦查出自己是不是已处于ANR的状态,进行快速的dump和上报。很容易想到,我们可以通过主线程是否处于卡顿状态来判断。那么怎么最快速的知道主线程是不是卡住了呢?上一篇文章中,分析Sync Barrier泄漏问题时,我们反射过主线程Looper的mMessage对象,该对象的when变量,表示的就是当前正在处理的消息入队的时间,我们可以通过when变量减去当前时间,得到的就是等待时间,如果等待时间过长,就说明主线程是处于卡住的状态,这时候收到SIGQUIT信号基本上就可以认为的确发生了一次ANR:
private static boolean isMainThreadStuck(){
try {
MessageQueue mainQueue = Looper.getMainLooper().getQueue();
Field field = mainQueue.getClass().getDeclaredField("mMessages");
field.setAccessible(true);
final Message mMessage = (Message) field.get(mainQueue);
if (mMessage != null) {
long when = mMessage.getWhen();
if(when == 0) {
return false;
}
long time = when - SystemClock.uptimeMillis();
long timeThreshold = BACKGROUND_MSG_THRESHOLD;
if (foreground) {
timeThreshold = FOREGROUND_MSG_THRESHOLD;
}
return time < timeThreshold;
}
} catch (Exception e){
return false;
}
return false;
}
我们通过上面几种机制来综合判断收到SIGQUIT信号后,是否真的发生了一次ANR,最大程度地减少误报和漏报,才是一个比较完善的监控方案。
3.3. 额外收获:获取ANR Trace
回到之前画的ANR流程示意图,Signal Catcher线程写Trace(圈2)也是一个边界,并且是通过socket的write方法来写Trace的,如果我们能够hook到这里的write,我们甚至就可以拿到系统dump的ANR Trace内容。这个内容非常全面,包括了所有线程的各种状态、锁和堆栈(包括native堆栈),对于我们排查问题十分有用,尤其是一些native问题和死锁等问题。Native Hook我们采用PLT Hook 方案,这种方案在微信上已经被验证了其稳定性是可控的。
int (*original_connect)(int __fd, const struct sockaddr* __addr, socklen_t __addr_length);
int my_connect(int __fd, const struct sockaddr* __addr, socklen_t __addr_length) {
if (strcmp(__addr->sa_data, "/dev/socket/tombstoned_java_trace") == 0) {
isTraceWrite = true;
signalCatcherTid = gettid();
}
return original_connect(__fd, __addr, __addr_length);
}
int (*original_open)(const char *pathname, int flags, mode_t mode);
int my_open(const char *pathname, int flags, mode_t mode) {
if (strcmp(pathname, "/data/anr/traces.txt") == 0) {
isTraceWrite = true;
signalCatcherTid = gettid();
}
return original_open(pathname, flags, mode);
}
ssize_t (*original_write)(int fd, const void* const __pass_object_size0 buf, size_t count);
ssize_t my_write(int fd, const void* const buf, size_t count) {
if(isTraceWrite && signalCatcherTid == gettid()) {
isTraceWrite = false;
signalCatcherTid = 0;
char *content = (char *) buf;
printAnrTrace(content);
}
return original_write(fd, buf, count);
}
void hookAnrTraceWrite() {
int apiLevel = getApiLevel();
if (apiLevel < 19) {
return;
}
if (apiLevel >= 27) {
plt_hook("libcutils.so", "connect", (void *) my_connect, (void **) (&original_connect));
} else {
plt_hook("libart.so", "open", (void *) my_open, (void **) (&original_open));
}
if (apiLevel >= 30 || apiLevel == 25 || apiLevel ==24) {
plt_hook("libc.so", "write", (void *) my_write, (void **) (&original_write));
} else if (apiLevel == 29) {
plt_hook("libbase.so", "write", (void *) my_write, (void **) (&original_write));
} else {
plt_hook("libart.so", "write", (void *) my_write, (void **) (&original_write));
}
}
其中有几点需要注意:
-
只Hook ANR流程:有些情况下,基础库中的connect/open/write方法可能调用的比较频繁,我们需要把hook的影响降到最低。所以我们只会在接收到SIGQUIT信号后(重新发送SIGQUIT信号给Signal Catcher前)进行hook,ANR流程结束后再unhook。
-
只处理Signal Catcher线程open/connect后的第一次write:除了Signal Catcher线程中的dump trace的流程,其他地方调用的write方法我们并不关心,并不需要处理。例如,dump trace的流程会在在write方法前,系统会先使用connet方法链接一个path为“/dev/socket/tombstoned_java_trace”的socket,我们可以hook connect方法,拿到这个socket的name,我们只处理connect这个socket后,相同线程(即Signal Catcher线程)的第一次write,这次write的内容才是我们唯一关心的。
-
Hook点因API Level而不同:需要hook的write方法在不同的Android版本中,所在的so也不尽相同,不同API Level需要分别处理,hook不同的so和方法。目前这个方案在API 18以上都测试过可行。
这个Hook Trace的方案,不仅仅可以用来查ANR问题,任何时候我们都可以手动向自己发送一个SIGQUIT信号,从而hook到当时的Trace。Trace的内容对于我们排查线程死锁,线程异常,耗电等问题都非常有帮助。
这样我们就得到了一个完善的ANR监控方案,这套方案在微信上平稳运行了很长一段时间,给我们评估和优化微信Android客户端的质量提供了非常重要根据和方向。
根据不同的性能监控问题,我们需要采用不同的性能优化手段,而目前还是有些人群对于性能优化中间的一些优化手段掌握的不是很熟练,因此针对性能优化中间的所有不同类型的优化手段进行了归类整理,有启动优化、内存优化、网络优化、卡顿优化、存储优化……等,整合成名为《Android 性能优化核心知识点手册》,大家可以参考下:
《APP 性能调优进阶手册》:https://qr18.cn/FVlo89
启动优化
内存优化

UI优化
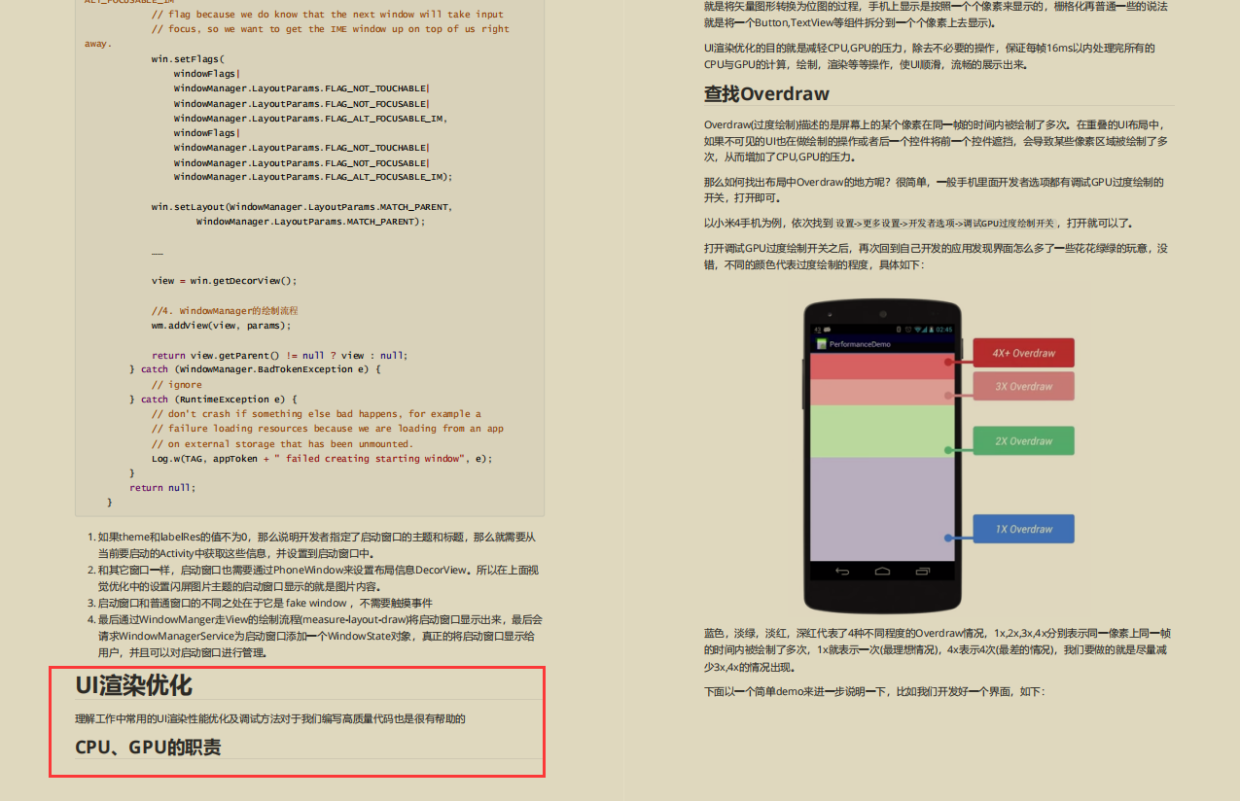
网络优化

Bitmap优化与图片压缩优化

多线程并发优化与数据传输效率优化
体积包优化
《Android 性能调优核心笔记汇总》:https://qr18.cn/FVlo89
《Android 性能监控框架》:https://qr18.cn/FVlo89