在之前的文章中我们介绍过阿里的开源离线数据同步工具——datax,我们可以使用datax来完成我们异构数据库之间的离线数据同步工作,它可以通过给予的主键(文本或数值)进行任务切分来同步进行,数据同步的效率还是非常高效的。
下图是datax钉钉交流群网友的任务截图。

阿里ETL工具——DataX使用简介
阿里开源ETL——DataX与Kettle联用
https://github.com/alibaba/DataX (这是阿里的github地址)
在日常工作中经常会用到datax来进行数据同步,但是每次都需要手动来配置json任务显得非常繁琐,作为一个热爱偷懒事业的人,是不允许继续这样下去的!

于是想到用python来编写个小脚本来驱动datax任务的执行。我呢,就看着它干活就好了!

python脚本驱动datax

首先,我们需要归纳下自己经常进行数据同步的数据库类型,我这边经常用到oracle、mysql、sqlserver这传统关系型数据库哥仨。因此先准备几个样例json作为我们Python调用的模板。

然后我们把需要用到的数据库连接整理到一个数据库连接的类中,然后通过import导入
import os # 用来执行python调用命令import time # 获取任务执行时间import pandas as pd # 处理jsonimport threading # 多线程执行任务from db_conn import Db_conn as db # 从自己编写的数据库连接模块导入数据库连接
任务的启动需要我们首先确定几个变量,
运行平台(windows/linux)
reader类型
writer类型
reader数据库信息
writer数据库信息
要进行同步的表对应关系
# ['windows','linux']任务执行平台选择plat_form = 'windows'# 数据库可选列表 [SqlServer,MySQL,Oracle]reader = 'sqlserver' # 读取数据的数据库类型writer = 'oracle' # 写入数据的数据库类型# 不同的数据库名称对应不同的连接函数调用。在reader_db = '' # 读取数据的业务系统数据库名称writer_db = '' # 写入数据的业务系统数据库名称# 需要同步的表名称对应关系。我这里用的是字典列表来处理tables = [{'reader_table':'','writer_table':'','splitPk':''},{'reader_table':'','writer_table':'','splitPk':''},{'reader_table':'','writer_table':'','splitPk':''},]
(我这里处理的思路是统一处理同一个reader和writer的批量任务,也可以修改成不同reader和writer的批量任务)
接下来,我们开始遍历这个字典列表,获取需要同步的表的对照关系和切分主键字段
for i in range(len(tables)):reader_table = tables[i]['reader_table']writer_table = tables[i]['writer_table']splitPk = tables[i]['splitPk']
下面,我们首先获取下json模板信息,因为我们把json都放在了这个python脚本同目录下面,因此我们使用os来获取这个脚本文件的所属文件夹绝对路径
current_path = os.path.dirname(os.path.abspath(__file__))
根据前面提供的平台参数和reader、writer参数,我们获取需要调用的json文件
if plat_form == 'windows':json_file = current_path + '\\' + reader.lower().title() + '2' + writer.lower().title() + '.json' # windows执行else:json_file = current_path + '/' + reader.lower().title() + '2' + writer.lower().title() + '.json' # linux执行
因为路径信息在windows和linux下用了不同的斜杠。
再根据提供的数据库来获取对应的数据库连接
if reader_db == 'a':conn = db.get_ERP_Re1_outer_conn()elif reader_db == 'b':conn = db.get_ERP业务242_2017_outer_conn()elif reader_db == 'c':conn = db.get_ERP业务242_2016_outer_conn()
然后我们就可以读取这个json了
read_df = pd.read_json(json_file)reader_parameter = read_df.to_dict()['job']['content'][0]['reader']['parameter'] # 获取需要修改的reader部分writer_parameter = read_df.to_dict()['job']['content'][0]['writer']['parameter'] # 获取需要修改的writer部分
在json文件中,我们需要提供给reader和writer下面这些信息
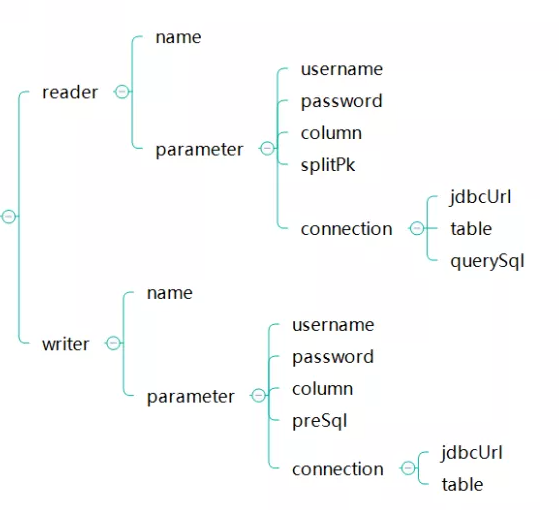
jdbcUrl、username、password、table、splitpk、column
(我们做的全量多任务分割同步,所以querysql和presql参数我们不使用了)
数据库的这些连接信息(jdbcUrl、username、password)我们通过获取数据仓库数据库中某个表中存储的数据库连接信息,如下图所示

def get_db_info(plat_form,dbname):"""获取数据库的连接信息"""if plat_form == 'windows':BI_conn = db.get_BI20_outer_conn() # windows中我们用外网ipelse:BI_conn = db.get_BI20_inner_conn() # linux中我们用内网ipsql = f'''SELECT * FROM ETL_DB_INFO WHERE DB_ALIAS = '{dbname}''''db_info = pd.read_sql(sql,BI_conn)return db_inforeader_dbinfo = get_db_info(plat_form,reader_db)writer_dbinfo = get_db_info(plat_form,writer_db)
表名称和分割主键是由前面的参数提供
我们只需要获取下对应表的字段信息即可
# 获取要读取数据的表的列信息,以列表形式给出columns = list(pd.read_sql(f'select * from {reader_table} where 1=0',conn).columns)
拿到这些基本信息之后我们就对json来进行修改赋值
reader_parameter['connection'][0]['jdbcUrl'] = [reader_dbinfo.loc[0,'DB_JDBC']]reader_parameter['username'] = reader_dbinfo.loc[0,'DB_UNAME']reader_parameter['password'] = reader_dbinfo.loc[0,'DB_PWD']reader_parameter['connection'][0]['table'] = [reader_table]reader_parameter['column'] = columns# 如果没有给出splitpk,那么我们默认获取表的第一个字段作为splitpkif len(splitPk) > 0:reader_parameter['splitPk'] = splitPkelse:reader_parameter['splitPk'] = columns[0]writer_parameter['connection'][0]['jdbcUrl'] = writer_dbinfo.loc[0,'DB_JDBC']writer_parameter['username'] = writer_dbinfo.loc[0,'DB_UNAME']writer_parameter['password'] = writer_dbinfo.loc[0,'DB_PWD']writer_parameter['connection'][0]['table'] = [writer_table]writer_parameter['column'] = columnsread_df.to_json(f'{json_file}') # 将json写入模板文件
json修改之后,我们就在系统上执行python调用datax执行这个json
"""执行datax"""time1 = time.time()if plat_form == 'windows':os.system('chcp 65001') # 在windows上防止执行日志出现乱码os.system(f'python D:\\datax\\bin\\datax.py {json_file}') # windows本地执行else:os.system(f'python3 home/Python/datax/bin/datax.py {json_file}') # linux服务器执行print(f'表{reader_table}执行完毕!耗时',time.time()-time1,'s')
上面执行命令中的datax.py的路径大家自行定义。
在实际调用时,我利用多线程来同步执行多个表的执行
threading.Thread(target=update_json,args=(plat_form,reader,writer,reader_db,writer_db,reader_table,writer_table,splitPk)).start()
到这里,我们就完成了这个python自动调用datax执行json进行离线数据同步的小脚本了。