今天开始理,反向传播了……哎……反向传播有点难啊,码字猿正在一点点学习,学到一些写一些,希望看到这个博客的大佬们能指点一二……跪谢
好吧,先从损失函数开始写起。
说到损失函数,最先需要提及的就是交叉熵了。当然也有用均方差来作为损失函数的,这两者之间的区别,或许这张图比较适合解释这个问题。参考网址:https://wenku.baidu.com/view/c93b4dd9b04e852458fb770bf78a6529647d35a7.html

现在先从分类问题开始说起,因为码字猿最近比较热衷于这个分类的神经网络,嘻嘻。
损失函数可以看做是误差部分+正则化部分得到,其中误差部分分类问题一般使用的就是交叉熵。
1、交叉熵
关于分类问题的损失函数,究其根源则是需要回归到熵的概念。我们可以把分类问题看做是概率分布问题。
这样,在概率问题里面有一个概念叫做KLD,即KL距离,这个是一种用于量化两种概率pq之间差异的方式,又可以称为相对熵,是度量一个分布近似另一个分布时损失的信息。
其中KLD表达为:
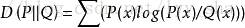
由于H(P)已定,是一个常量。而H(P,Q)是根据Q分布而改变的。当Q越接近P时,H(P,Q)越小,所以,H(P,Q)可以作为神经网络的损失函数。
在概率论中,H(P,Q)称为交叉熵,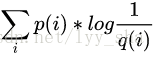
另一种解释,则是从logistic函数的最大似然估计方面来进行解释的。
求交叉熵的最小值,也等效于求最大似然估计。
最大似然估计是利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值(模型已知,参数未知)
在已知结果为logistic函数分布时,得到似然函数(估计函数)。参考网址:https://blog.csdn.net/u014403897/article/details/45871203


对L求log得:
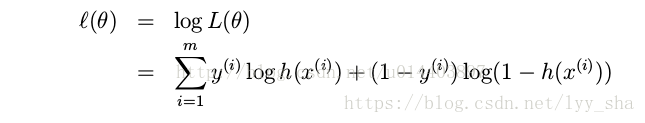
上述函数就是H(P,Q)的值的相反数,正好就是该行数的交叉熵。
在进行求导的:
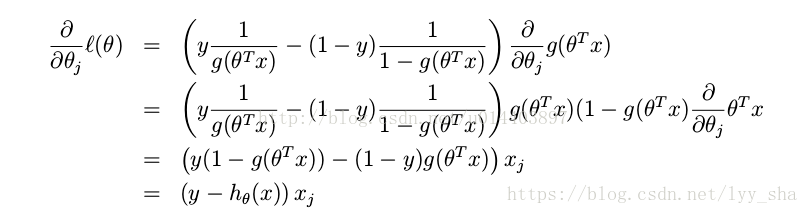
所以在进行梯度下降法进行数据更新的时候,所用的迭代公式为:

参考网址:https://blog.csdn.net/qq547276542/article/details/77980042
参考网址:https://blog.csdn.net/heyongluoyao8/article/details/52462400
1.2 gold standard ,0-1损失函数

可以看出,该损失函数的意义就是,当预测错误时,损失函数值为1,预测正确时,损失函数值为0。该损失函数不考虑预测值和真实值的误差程度,也就是只要预测错误,预测错误差一点和差很多是一样的。
1.3 perceptron Loss 感知损失,绝对值损失函数

在感知算法(PLA)中取t=0.5。其中t是一个超参数阈值。
1.4 Hinge Loss 折叶损失
与支持向量机(SVM)息息相关,用于“最大边缘”分类。对于预期输出t =±1和分类器得分y,预测y的铰链损失定义为


最初SVM优化函数如下:



1.5 均方差损失
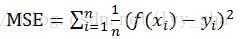
一般用于线性回归的神经网络。
1.6 指数损失函数


应用于boost算法,常见于Adaboost算法中。
1.7 对数损失函数

下面是一些损失函数的图像:
