软工结对项目-最长单词链
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 北航 2022 春季敏捷软件工程 |
| 这个作业的要求在哪里 | 结对编程项目-最长英语单词链 |
| 我在这个课程的目标是 | 提高工程能力,练习结对开发 |
| 这个作业在哪个具体方面帮助我实现目标 | 体验结对编程,提高工程能力 |
项目地址
项目地址:https://gitee.com/soft-pair-programming-fxj-lyyf/wordlist.git
估计时间与实际时间(独立)
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 1630 | 1830 |
| · Analysis | · 需求分析 (包括学习新技术) | 200 | 240 |
| · Design Spec | · 生成设计文档 | 30 | 20 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 100 | 120 |
| · Coding | · 具体编码 | 1000 | 1200 |
| · Code Review | · 代码复审 | 60 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 200 | 180 |
| Reporting | 报告 | 180 | 180 |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 120 | 120 |
| 合计 | 1840 | 2030 |
利用Information Hiding,Interface Design,Loose Coupling设计接口(独立)
-
信息隐藏:即将类的成员私有化,避免无意中对私有成员进行赋值。在本项目中,我们将Solution类中的graph字段进行了私有化,这样可以避免在其他地方对graph进行了更改导致错误,对graph的操作都通过graph暴露的方法来操作。
-
接口设计:一个好的接口能够提供给后面的程序设计一个良好的框架,在这本项目里,我们对可能出现的需求都在Solution类中设计了相应的接口。通过这些接口,我们可以对输入的不同需求调用相应的方法,不必在意接口的具体实现,也为后续的core接口的制作和测试提供了便利。
-
松耦合:我们设计时将字符读入与处理模块、算法模块、图模块等分开写,当代码有改动时,可以不用大规模的改动我们的代码,我们只用定位于一个出问题的模块,然后对其进行更改就好了,而且能做到不改变其它模块的服务。
计算模块接口的设计与实现过程。
计算模块指 core.dll,该模块实现了如下 4 个 API:
int gen_chains_all(char* words[], int len, char* result[])
int gen_chain_word(char* words[], int len, char* result[],
char head, char tail, bool allow_circ)
int gen_chain_word_unique(char* words[], int len, char* result[])
int gen_chain_char(char* words[], int len, char* result[],
char head, char tail, bool allow_circ)
我们对这些 API 进行了如表 2 的约定。关于 char *result[] 的问题,我的思考如下:
- 最好采用一段连续的空间来存放输出,每一行输出中仅用 ‘\0’ 来分隔,调用者通过遍历 result 中的每一个元素,可以直接输出内容。此时,第 i 个元素( char * 类型指针)都指向该段内存中第 i 行输出的首地址
- 内存需要申请者来释放,如果由 dll 来申请,则自己不可能释放,因此必须由调用者来申请
- 申请的内存位置需要传入 dll API
因此,调用者申请大小为 128 MB (假定可以存入所有有效的输出)的堆空间,并将该段内存的首地址赋值给 result[0]。由此,每生成一行有效的输出,则在 result[i - 1] 的基础上加下一行输出的长度,得到 result[i];而输出的具体内容,只需要接在上一行输出的后面存储即可。
表 2 - core.dll API 约定
| 项目 | 意义 |
|---|---|
| words | 传入读入的单词,每一个元素是单词首的指针,全部为小写,每个单词以 ‘\0’ 结尾 |
| len | 传入 words 中元素的个数 |
| results | 保存计算结果。要求调用者开辟 128 MB 的内存,并将首地址赋值给 result[0]。正常的计算结果下,每一个元素均为一行输出的首地址,每行以 ‘\0’ 结尾。若计算过程中出现异常,整个数组不变(无法输出);若整体输出的长度大于 128 MB,则仅保存小于等于 128 MB 部分的完整的行(超出部分无法取得);若返回值大于 20000,则整个数组不改变(无法输出) |
| head | 传入单词链首字母,必须是小写。若不要求首字母,则传入 NULL |
| tail | 传入单词链尾字母,必须是小写。若不要求首字母,则传入 NULL |
| allow_circ | 是否允许存在循环 |
| 返回值 | 大于等于 0 时,表示结果有效,此时 result 中每一个元素表示一个输出行;若结果大于 20000,则超出数量限制,results 数组整个不变 |
| 异常 | - invalid_argument:当 len <= 0 或 head、tail 非法 - logic_error:当输入单词非法构成循环 |
Solution 中有 4 个与 core 中 API 对应的 API(见下方),这是计算真正开始的地方。
//-n
int Solution::genAllChain(std::vector<std::string> &result)
//-w -h [head] -t [tail] -r no -h than head=='\0' no -t than tail=='\0'
int Solution::genMaxWordChain(std::vector<std::string> &result,
char head, char tail, bool allowCircle)
//-m
int Solution::genMaxWordChainNotSame(std::vector<std::string> &result)
//-c -h [head] -t [tail] -r
int Solution::genMaxCharChain(std::vector<std::string> &result,
char head, char tail, bool allowCircle)
为了便于开发,我们对传入参数和返回值进行了约定,见表 3。
表 3 - Solution 接口设计约定
| 项目 | 意义 |
|---|---|
| result | 保存单词链的结果,以引用类型传入。每一个元素表示一行输出 |
| head | 单词链首字母,必须是小写。若不要求首字母,则传入 NULL |
| tail | 单词链尾字母,必须是小写。若不要求首字母,则传入 NULL |
| allowCirc | 是否允许存在循环 |
| 返回值 | 大于等于 0 时,表示结果有效,此时 result 中每一个元素表示一个输出行;若结果为负数,表示存在异常,具体异常编码 |
core 部分仅需要将输入参数转化为 Solution 的 API 可以接受的形式,并处理相关异常和返回值即可。具体而言,对接方式如下:
- 将输入的单词数组(char ** 类型)全部转为 vector,其中大小写和重复问题,在传入 core 之前已经解决
- 调用 Solution 构造函数,建立单词图 graph
- 新建 vector result_vec 用以保存 API 输出结果
- 调用计算 API,传入参数,并获取返回值
- 判断返回值。返回值在 0 至 20000 时,开始将 result_vec 中的内容逐个拷贝到 result[0] 所指向的空间,并更新 result 数组,直到拷贝完成或该内存空间无法存入新行,然后返回总行数。若有非法成环情况,则返回错误编码;若输出行数过多,则仅返回总行数。
在 Solution 的 API 中,对参数进行分类,按需进行循环检查,然后调用 Graph 中具体的实现,或抛出异常。
以获取最大单词数的单词链(gen_chain_word)为例如,整个执行过程见图 2。该过程先转化输入单词为约定形式,然后实例化 Solution 并调用相应 API。Solution API 中,若允许成环,则直接调用 Graph API,否则先进行循环检查,再计算或返回异常。Solution API 返回后,core 根据返回值判断,正常情况下按照约定转化输出结果,否则返回异常值。
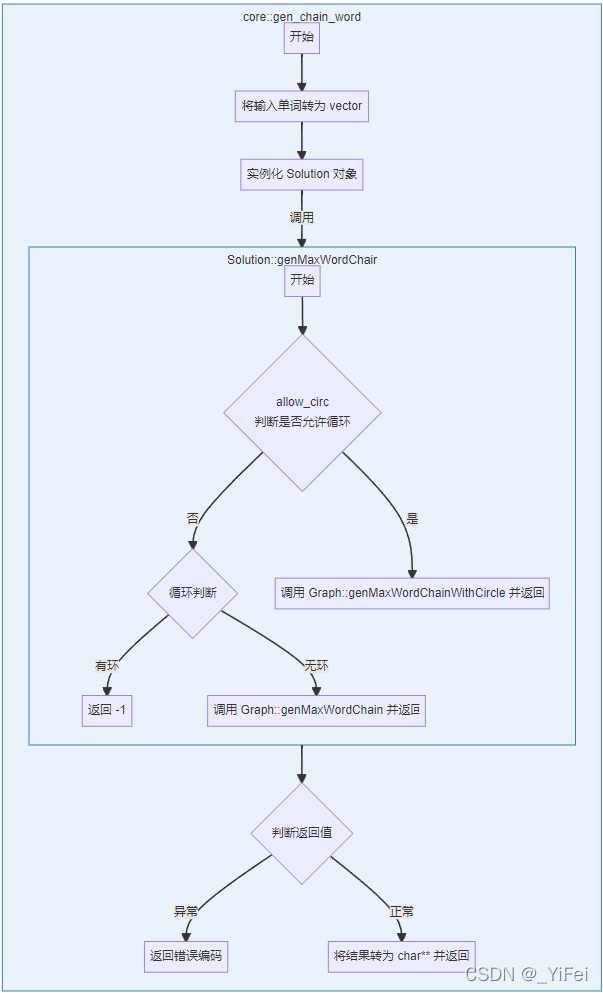
图 2 - 计算最大单词数单词链 API
UML 图(独立)

计算模块接口部分的性能改进。
我们利用 Visual Studio 自带的性能分析工具对 Wordlist 进行性能分析。考虑到并行优化需要减少数据依赖,我们选取了数据依赖最弱同时计算量很大的 -c -r 参数运行,profile 的结果如图 3 所示。可见除 main() 等必须要经过的函数之外,搜索计算部分占据大部分时间(约 60%),因此我们将这一部分并行化。
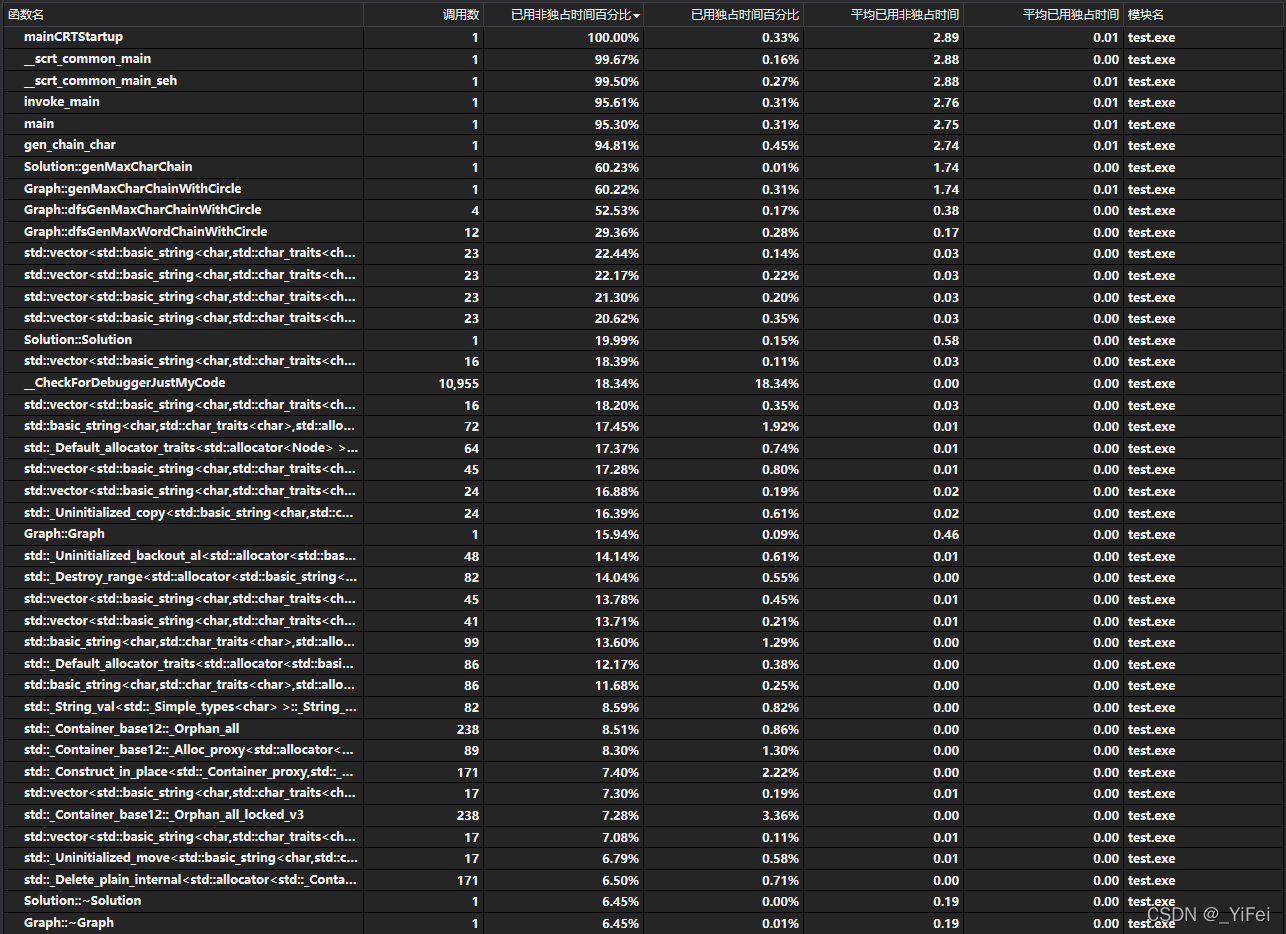
图 3 - 并行前 Profile 结果
我们采用了 OpenMP 并行框架,该框架仅需要在源代码的基础上进行少量修改即可进行并行化操作,且该标准被绝大多数编译器所支持。以获取最多字符单词链为例,线程数由操作系统自动指定,采用动态调度方式,对于不指定首字母的情况,我们同时让每一个线程都处理一个首字母;对于指定首字母的方式,将该首字母下所有单词均分给每个线程进行搜索。代码如下:
int Graph::genMaxCharChainWithCircle(vector<std::string> &result, char head, char tail) {
int max = 0;
if (head == '\0') {
#pragma omp parallel for schedule(dynamic)
for (int i = 0; i < 26; i++) {
for (Node &node: index2nodes.at(i)) {
vector<string> list;
unordered_set<string> visited;
int ret = dfsGenMaxCharChainWithCircle(list, node, tail,visited);
if (max < ret) {
#pragma omp critical
{
result = list;
max = ret;
}
}
}
}
} else {
auto &nodes = index2nodes[head - 'a'];
int ub = nodes.size();
#pragma omp parallel for
for (int i = 0; i < ub; i++) {
auto &node = nodes[i];
vector<string> list;
unordered_set<string> visited;
int ret = dfsGenMaxCharChainWithCircle(list, node, tail,visited);
if (max < ret) {
#pragma omp critical
{
result = list;
max = ret;
}
}
}
}
std::reverse(result.begin(), result.end());
return max;
}
优化之后的 Profile 结果如图 4 所示。可见该部分的占比已经下降到约 30%。粗略估计,计算部分加速比达到
a c c = 0.6 / ( 1 − 0.6 ) 0.3 / ( 1 − 0.3 ) = 3.5 × a c c = \frac{0.6 / ( 1 − 0.6 )}{ 0.3 / ( 1 − 0.3 )} = 3.5 × acc=0.3/(1−0.3)0.6/(1−0.6)=3.5×
整个程序时间从 207 s 减少到 134 s,加速比达到 1.5 × 。
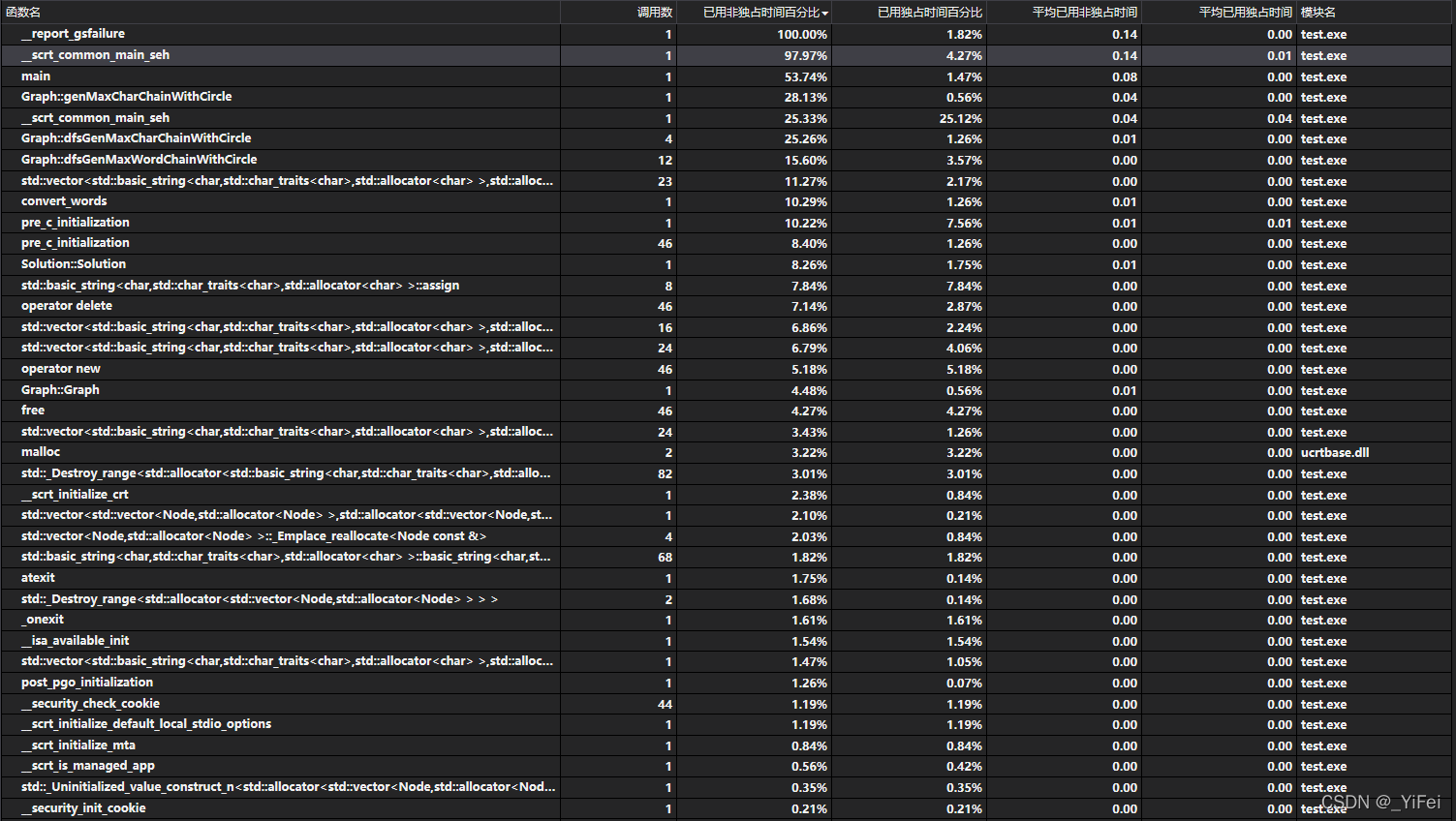
图 4 - 并行后 Profile 结果
附测试样例
ba ab
ca ac cb bc
da ad db bd dc cd
ea ae eb be ec ce ed de
fa af fb bf fc cf fd df fe ef
看 Design by Contract,Code Contract 的内容,并描述这些做法的优缺点,说明你是如何把它们融入结对作业中的。(独立)
当程序满足一些约定好的最基本需求时才进行运行,否则直接拒绝运行。
- 优点:当其他模块调用该模块时,一旦不满足即会跳出,可以很快发现问题所在。
- 缺点:稍微超出一点边界即不可运行,边界兼容性低,增加了工作量和工作难度。
在构建边时,只有小写字母可以被正确处理,一旦发现非小写字母程序将运行错误。
计算模块部分单元测试展示。
利用vs的单元测试模块,我们只需要填写要测试的函数和返回的正确答案即可。如下是我们的测试代码:
TEST_METHOD(TestMethod1) {
int len = 4;
char *words[] = {"woo", "oom", "moon", "noox"};
int ret = 6;
char *result[] = {
"woo oom",
"moon noox",
"oom moon",
"woo oom moon",
"oom moon noox",
"woo oom moon noox"
};
char *_result_buf = (char *) malloc(0x1000);
char **_result = (char **) malloc (sizeof (char *) * 100);
_result[0] = _result_buf;
int _num = gen_chains_all(words, len, _result);
Assert::AreEqual(ret, _num);
vector<string> ans_vec, ret_vec;
for (int i = 0; i < ret; i++) {
ans_vec.emplace_back(result[i]);
ret_vec.emplace_back(_result[i]);
}
sort(ans_vec.begin(), ans_vec.end());
sort(ret_vec.begin(), ret_vec.end());
for (int i = 0; i < ret; i++) {
Assert::AreEqual(ans_vec[i], ret_vec[i]);
}
}
我们对每一种可能出现的参数组合都构造了相应的样例,同时也对一些需要报错的情况做了样例构造。最终有18组样例,下面是代码覆盖率:
计算模块部分异常处理说明
非法循环异常
计算部分最为显著的异常为输入数据非法构成循环的情况。我们定义错误编码
// core.h
throw logic_error("There is a circle in the chain.")
这种异常情况最先由 Solution API 进行检测(以最大单词数量为例),在不允许循环的情况下,先检查是否有环,若有,则直接返回 -1。只有在正确的情况下,才进行后续计算。
// Solution.cpp
int Solution::genMaxWordChain(std::vector<std::string> &result,
char head, char tail, bool allowCircle) {
if (allowCircle){
return graph.genMaxWordChainWithCircle(result, head, tail);
}
else {
if (checkCircle()) return -1;
return graph.genMaxWordChain(result, head, tail);
}
}
返回异常值后,在 core.dll 中进行判断,若有异常,则输出异常提示,并直接将异常值传递给调用者。
// core.cpp
int gen_chain_word(char* words[], int len, char* result[],
char head, char tail, bool allow_circ) {
Solution solution(convert_words(words, len));
vector<string> result_vec;
if (solution.genMaxWordChain(result_vec, head, tail, allow_circ) == -1) {
throw logic_error("There is a circle in the chain.");
}
return convert_result(result_vec, result);
}
应对这种情况,我们设计了单元测试样例:在不允许循环的情况下,给出的单词文本可以构成循环。样例如下:
// UnitTest.cpp
TEST_METHOD(TestMethod12) {
int len = 3;
char* words[] = { "ab", "xyz", "ba" };
int ret = CORE_ERROR_ILLEGAL_CIRCLE;
char* _result_buf = (char*)malloc(0x1000);
char** _result = (char**)malloc(sizeof(char*) * 100);
_result[0] = _result_buf;
try {
int _num = gen_chain_word(words, len, _result, 0, 0, false);
}
catch (exception& e) {
Assert::AreEqual(e.what(), "There is a circle in the chain.");
}
}
指定首尾字母异常
调用者有可能在指定首位字母时发生异常,合法的首尾字母 head、tail应该是单个小写字母,或传入 NULL 表示不指定。用户可能传入大写字母或其他字符,此时需要给予处理或提示。当用户传入大写字母时,在 core 内部直接将其转为小写字母,增加容错性。若传入非法字符,则返回错误提示。
定义错误编码如下:
// core.h
throw invalid_argument("Head is not a single letter.")
throw invalid_argument("Tail is not a single letter.")
在 core API 中,一旦检测到非法的首位字母,则给出错误提示,并返回相应的错误编码。
// core.cpp
if ('a' <= head && head <= 'z'){
} else if ('A' <= head && head <= 'Z') {
head = (char) (head + 0x20);
}
else if(head != '\0'){
throw invalid_argument("Head is not a single letter.");
}
if ('a' <= tail && tail <= 'z'){
} else if ('A' <= tail && tail <= 'Z') {
tail = (char) (tail + 0x20);
}
else if(tail != '\0'){
throw invalid_argument("Tail is not a single letter.");
}
这一部分有两个测试样例:
// UnitTest.cpp
TEST_METHOD(TestMethod16) {
int len = 11;
int head = '-', tail = 0;
bool circ = true;
char* words[] = {
"algebra",
"apple",
"zoo",
"elephant",
"under",
"fox",
"dog",
"moon",
"leaf",
"trick",
"kkd"
};
int ret = 6;
char* result[] = {
"algebra",
"apple",
"elephant",
"trick",
"kkd",
"dog"
};
char* _result_buf = (char*)malloc(0x1000);
char** _result = (char**)malloc(sizeof(char*) * 100);
_result[0] = _result_buf;
try {
int _num = gen_chain_word(words, len, _result, head, tail, circ);
}
catch (exception& e) {
Assert::AreEqual(e.what(),"Head is not a single letter." );
}
}
TEST_METHOD(TestMethod17) {
int len = 11;
int head = 'k', tail = '=';
bool circ = true;
char* words[] = {
"algebra",
"apple",
"zoo",
"elephant",
"under",
"fox",
"dog",
"moon",
"leaf",
"trick",
"kseudopseudohypoparathyroidisa"
};
int ret = 5;
char* result[] = {
"kseudopseudohypoparathyroidisa",
"algebra",
"apple",
"elephant",
"trick"
};
char* _result_buf = (char*)malloc(0x1000);
char** _result = (char**)malloc(sizeof(char*) * 100);
_result[0] = _result_buf;
try {
int _num = gen_chain_char(words, len, _result, head, tail, circ);
}
catch (exception& e) {
Assert::AreEqual(e.what(), "Tail is not a single letter.");
}
}
传入单词长度异常
调用者有可能传入错误的单词长度。我们对这一情况进行了简单的检查,要求传入的长度 len 必须是正整数。若调用者传入了负数,则返回如下的错误码:
// core.h
throw invalid_argument("len should be large than 0.")
这种异常在 core 中的处理为:
// core.cpp
if (len<=0) {
throw invalid_argument("len should be large than 0.");
}
对于这种异常情况,我们制定的测试样例如下:
// UnitTest.cpp
TEST_METHOD(TestMethod18) {
int len = 4;
char *words[] = {"woo", "oom", "moon", "noox"};
int ret = 6;
char *result[] = {
"woo oom",
"moon noox",
"oom moon",
"woo oom moon",
"oom moon noox",
"woo oom moon noox"
};
char *_result_buf = (char *) malloc(0x1000);
char **_result = (char **) malloc (sizeof (char *) * 100);
_result[0] = _result_buf;
try {
int _num = gen_chains_all(words, -1, _result);
}
catch (exception& e) {
Assert::AreEqual(e.what(), "len should be large than 0.");
}
}
界面模块的详细设计过程
CLI
对于命令行界面,在用户体验方面最重要的是需要给与足够友好的使用提示和错误提示。因此,我们设计了如下的使用提示,当用户键入 -? 选项时即可给出提示。
Usage:
Wordlist <function> <filename> [options]
Functions:
-n Get the total number of word chains.
-w Get the word chain with the most words.
-m Get the word chain with the most words, where the
first letter of each word cannot be repeated.
-c Get the word chain with the most letters.
Options:
-h <head> Specify the first letter of the chain.
-t <tail> Specify the last letter of the chain.
-r Allow implicit word circles.
对于开发者,很重要的工作是进行命令行参数的切分。对此,我们专门设计了 OptParser 模块来读取参数,该模块仿照 GNU Linux 开源库中的参数读取部分,但是更加适配 C++,可移植性更强。我们指定了对 -n -w -m -c -h -r 选项的读入以及相关参数提取,同时对参数的合法性进行检查。若用户给出参数有误,如缺少功能指定、缺少输入文件等,都会给与相应的错误提示,并给出上述的使用方法。例如,OptParser 中参数分割的代码如下:
int OptParser::next_opt() {
argv_index++;
if (argv_index == argc) {
return 0;
}
if (argv[argv_index][0] == '-') {
char c = argv[argv_index][1];
if ('?' == c || 'a' <= c && c <= 'z' || 'A' <= c && c <= 'Z') {
if (options[c] == 0 && argv[argv_index][2] == 0) {
param = "";
return c;
}
if (options[c] == 1) {
if (argv[argv_index][2] == 0) {
argv_index++;
if (argv_index == argc) {
fprintf(stderr, "Missing option for -%c.\n", c);
if (exit_on_error) {
exit(-1);
} else {
return -1;
}
}
param = string(argv[argv_index]);
} else {
param = string(argv[argv_index] + 2);
}
return c;
}
if (options[c] == 2) {
if (argv[argv_index][2] == 0) {
fprintf(stderr, "Missing option for -%c.\n", c);
if (exit_on_error) {
exit(-1);
} else {
return -1;
}
}
param = string(argv[argv_index] + 2);
return c;
}
}
}
// param directly given
param = string(argv[argv_index]);
return 1;
}
调用者可在初始化 Parser 后,通过循环来读取其中的参数。具体代码太长,在此不便贴出,可参见 Gitee:src/opt_parser.cpp、src/Wordlist.cpp#L126。
当用户给出了合法的参数,CLI 程序将会寻找输入文件并进行检查。检查合法后,将会读入文件中的所有单词,将单词全部转为小写,并去重(见 Gitee:src/Wordlist.cpp#L68)。
完成上述步骤后,加载 core.dll,并根据参数调用相关 API。
API 调用完成后,读取返回值,判断异常情况。正常情况下,会将结果输出至 stdout 或 Solution.txt。若存在异常,则给与错误提示(本程序中,错误提示在 core.dll 中就已经输出至 stderr)。
GUI
在进行GUI设计时,我们首先对命令行参数进行了可视化的设计,使得GUI界面可完整实现所有正确的参数组合。最终界面设计如下:
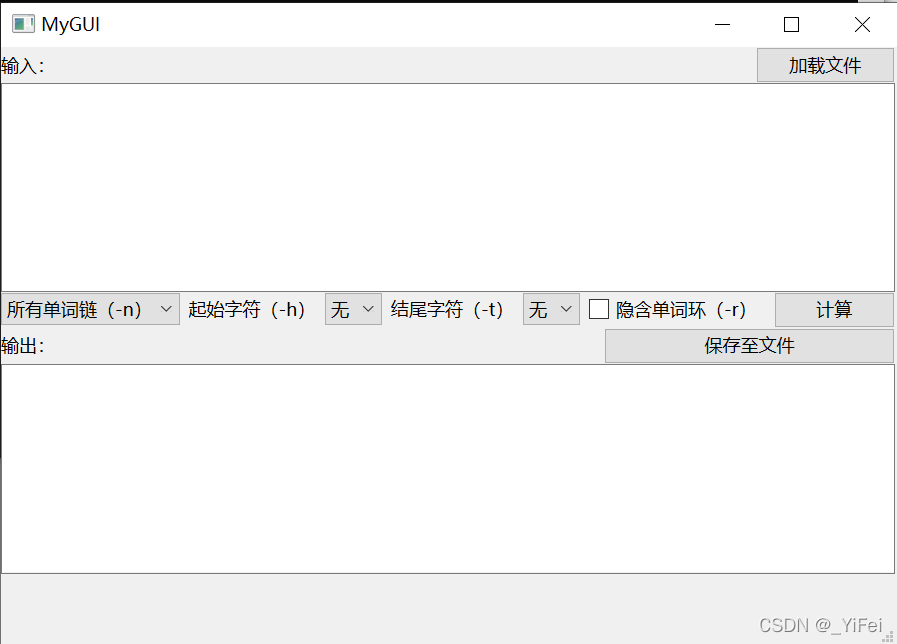
用户可选择从文件中导入或手动复制到输入框中:
设置好相应的参数后点击计算即可得到答案,也可将答案导出保存至文件。
在实现上,我们采用了QT作为GUI框架,首先将上述的可视化界面通过QT的设计器摆好,之后对3个按钮分别进行点击函数的实现:
如计算按钮的点击函数:
void MyGUI::startCalc() {
const int MAX_WORD_NUM = 10020;
const int MAX_CHAIN_NUM = 20020;
char head = ui->head->currentIndex()>0 ? ui->head->currentIndex() + 'a' - 1 : '\0';
char tail = ui->tail->currentIndex()>0 ? ui->tail->currentIndex() + 'a' - 1 : '\0';
bool isC = ui->iscircle->isChecked();
int func = ui->type->currentIndex();
QString s = ui->input->toPlainText();
char* word_buf = (char*)malloc(0x4000000);
char** words = (char**)malloc(sizeof(char*) * MAX_WORD_NUM);
int n_words;
char *result_buf = (char *) malloc(0x10000000);
char **result = (char**) malloc (sizeof (char*) * MAX_CHAIN_NUM);
result[0] = result_buf;
if (!result) {
QMessageBox::warning(nullptr, "111", "111");
}
int n_return;
HMODULE core = LoadLibraryA("core.dll");
n_words = Qstring2words(s,word_buf, words);
if (func == 0) {
if(head!='\0'||tail!='\0'||isC){
QMessageBox::warning(this, "参数选择有误", "-n不可与-h、-t、-r共同使用");
}
else{
n_return = gen_chains_all(words,n_words,(char**)(void*) result);
}
}else if(func == 1){
n_return = gen_chain_word(words, n_words, result, head, tail,isC);
}else if(func == 2){
n_return = gen_chain_char(words, n_words, result, head, tail, isC);
}else if(func == 3){
if(head!='\0'||tail!='\0'||isC){
QMessageBox::warning(this, "参数选择有误", "-m不可与-h、-t、-r共同使用");
} else
n_return = gen_chain_word_unique(words, n_words, result);
}
if(n_return<0) {
QMessageBox::warning(this, "文本中有单词环", "非-r时不可包含单词环");
return;
}
QString res;
if(func == 0){
res = QString::number(n_return);
res.append('\n');
}
for (int i = 0; i < n_return; i++) {
res.append(result[i]);
res.append('\n');
}
ui->output->setPlainText(res);
FreeLibrary(core);
free(words);
free(word_buf);
free(result);
free(result_buf);
}
实际上是将之前写好的core进行了调用,将qt中的Qstring转为core的输入格式即可,然后调用相关函数。之后再将结果显示在输出框中。
界面模块与计算模块的对接。
CLI
CLI 与计算模块的对接在前文均已提到,主要是满足了表 2 的约定。具体的细节为:
- 读入单词时,开辟连续的空间(64 MB)存储单词内容,并新开辟一个 char *words[] 数组,每个元素存储单词首地址,并保证去重、转为小写,对于存在的首位字母等参数,也转为合法形式
- 开辟 128 MB 空间存储结果,并另开一个 char *words[] 数组,将首地址赋给 result[0]
- API 调用完成后,检查返回值。若返回值在 0 至 20000,则正常输出 result 中指向的单词链;否则,不予输出,并给出相应的错误提示
满足上述实现要求后,CLI 程序即可与 core.dll 成功对接。
GUI
GUI主要是调用了core中的方法,对接时满足表2的约定,与CLI类似,先开辟相应大小的空间,将参数、文本等传入计算模块,再获得结果。
另外错误处理的对接也是相同的,若发现计算模块返回错误值,则GUI也会跳出相应的提示。
描述结对的过程
结对编程采用线下的形式进行(图 3),地点通常在五教 305 或新主楼 G 座 5 楼。

在结对编程过程中,先商定需求,例如,采用 C++ 语言、CMake 框架。然后对每个人的开发内容进行分工(考虑到工作量实在太大,全程采用一个人写一个人看的方式难以如期完成,仅在关键部分采用这种方式),本人主要负责算法部分、GUI部分。然后约定各个模块对接的契约,如表 2、表 3 所示的接口对接规则,进行开发。在遇到问题或 bug 时,会二人共同解决,提高 debug 效率。
与其他组互换模块
我们与另一个小组进行了模块互换。互换过程中最大的问题是字长问题,本组两人的编译器全部是 x86 的编译器,而另一组同学全部采用的是 x64 编译器。在对接的过程中,不同字长的编译器编译出的模块不能互通,发现此问题花费了极长的时间。
另一组组员:
- 潘天蔚 19373307
- 张羿凡 19373758
dev-combine 分支地址:https://gitee.com/soft-pair-programming-fxj-lyyf/wordlist/tree/dev-combine/。不包含另一组同学的源代码,仅在 dev-combine/ 目录下有两个组合好的程序,分别是本组 core 与另一组 GUI、本组 CLI 与另一组 core。
本组 core 与另一组 GUI
另一组的 GUI 调用 core 的 API 是形式如下的统一 API:
const char* gui_engine(const char* input, int type, char head,
char tail, bool weighted)
因此,我们对我们的 core 进行了修改,增加了上述函数,并将功能和输入映射到我们原本的 4 个 API 中,使得另一小组同学在不修改前端代码的情况下,即可直接调用本组的 core.dll 实现正常的功能。
另一组的 GUI 采用了 Electron 框架,主要用 Vue 编写前端,界面精美,但是启动较慢,体积臃肿,尤其是在解包之后,达到了 200 MB。
本组 CLI 与另一组 core
另一组的 core 除了实现上述统一 API 之外,同样实现了课程组给定的 4 个API,且对内存管理的规定恰好符合< a href=" ">表 2</ a> 的约定。因此,在将本组的编译器替换成 64 位字长的编译器后,编译出的 CLI 程序部分,可以直接搭配另一组的 core.dll 实现正常的功能。
另一组的 core.dll 在实现 -c -r 功能时采用了状压 dp,时间复杂度更低。运行前文性能分析时给出的样例只需要约 2 s 时间,这方面值得我们学习,这也与另一组队员优秀的算法功底密不可分。
结对编程的优点和缺点。(独立)
结对编程:
- 优点:可以有效减少一个人写代码时出现的错误,因为另一个队友将看着你完成代码。
- 缺点:
- 有可能一个人的实现细节和另一个人的不一样,可能导致一些分歧,浪费统一细节的时间(实际上两种细节都是正确的)
- 两个人找可以讨论写代码的地方非常浪费时间,新主楼经常没有位置。
我的结对队友是周二班的冯旭杰同学。
| 冯旭杰 | 我 | |
|---|---|---|
| 优点 | 1、对cpp非常熟悉,搭建总体框架时非常快速 2、熟练掌握cmake,解决了dll的生成等在我看来比较奇怪的问题 3、写代码效率高,结对时准时到场不迟到。 |
1、乐于学习新知识,喜欢挑战自己 2、写算法某种意义上比较熟练,可快速完成算法代码 3、按时完成ddl |
| 缺点 | 偶尔没看清题目要求(?) | 对cpp不熟悉,对cpp动态链接等知识非常欠缺,导致背大锅。 |