参考:Vue 源码解析系列课程
系列笔记:
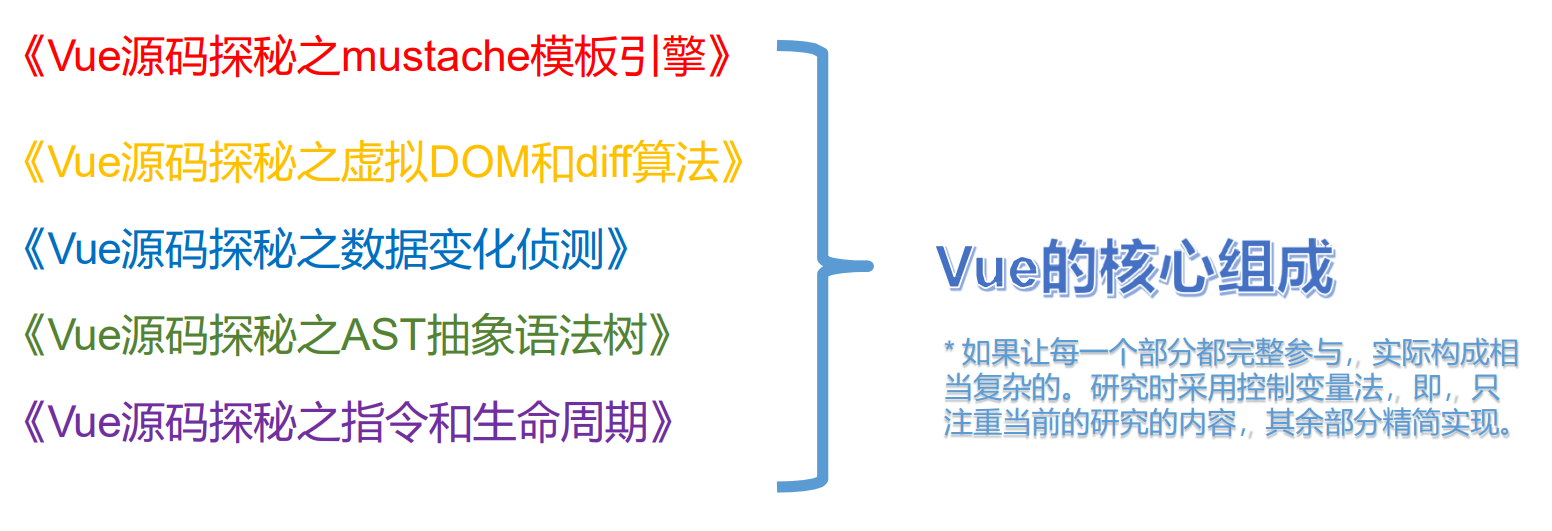
大纲:
- 相关算法储备
- AST 形成算法
- 手写 AST 编译器
- 手写文本解析功能
- AST 优化
- 将 AST 生成 h() 函数
本章源码:https://gitee.com/szluyu99/vue-source-learn/tree/master/AST_Study
抽象语法树介绍
抽象语法树是什么?
- 从 模板语法 直接编译到 HTML 语法 十分困难
- 通过 抽象语法树 进行过度会让这个工作变得简单

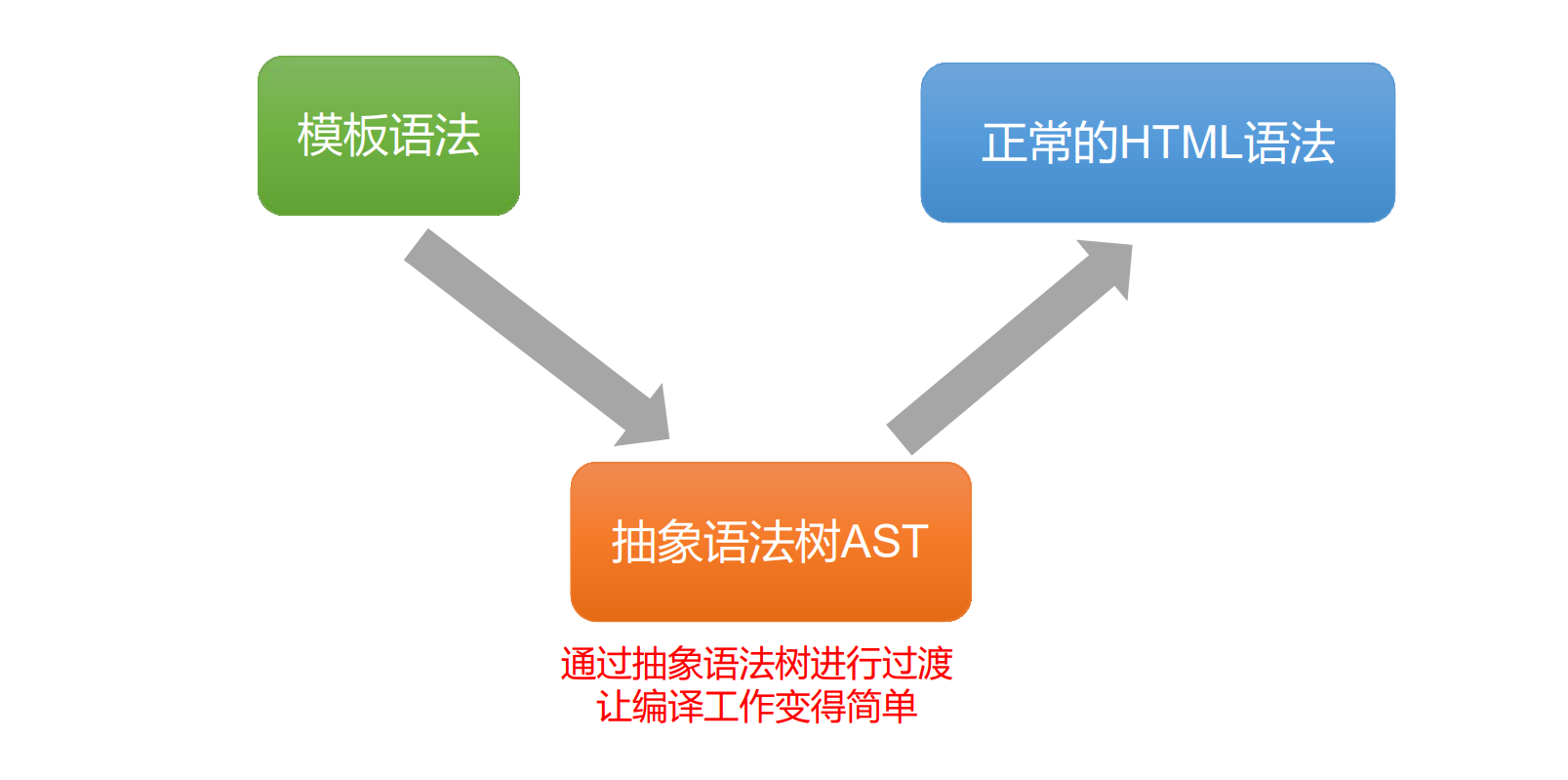
抽象语法树本质上就是一个 JS 对象:
- 理解为 HTML 语法通过一系列规则对应到的 JS 对象

抽象语法树 和 虚拟节点 的关系:
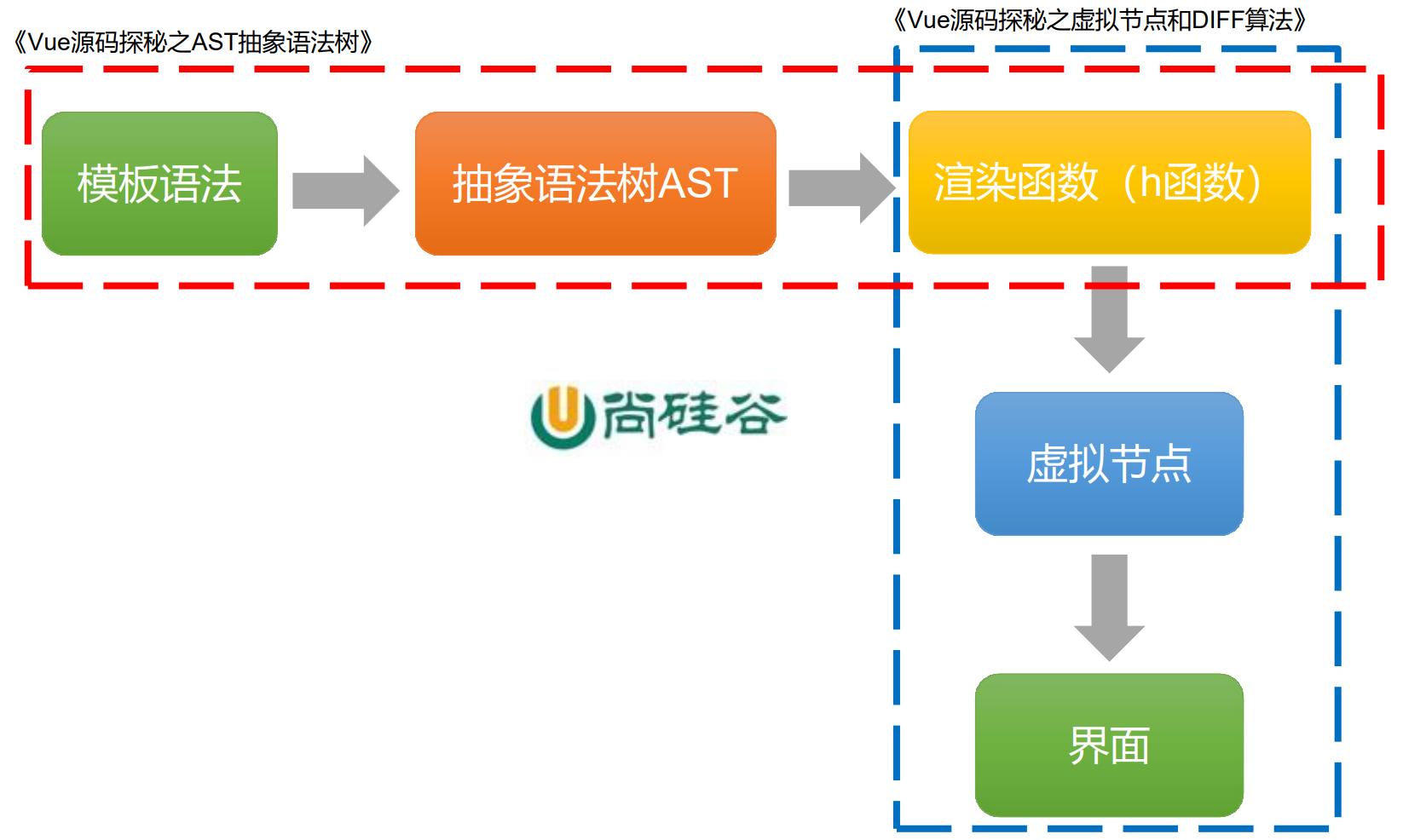
相关算法储备
相关代码:https://gitee.com/szluyu99/vue-source-learn/tree/master/AST_Study/pre
指针
题目:试寻找字符串中,连续重复次数最多的字符。
function findMaxChar(str) {
let i = 0, j = 1
let maxChar = str[i], maxRepeat = -1
while (i < str.length) {
if (str[i] != str[j]) {
if (j - i > maxRepeat) {
maxRepeat = j - i
maxChar = str[i]
}
i = j
}
j++
}
console.log(`最多的字母是 ${
maxChar},重复了 ${
maxRepeat} 次`);
}
let str = 'aaaabbbbbcccccccccccccdddddd'
findMaxChar(str)
递归
题目1:试输出斐波那契数列的前10项,即1、1、2、3、5、8、13、21、34、55。然后请思考,代码是否有大量重复的计算?应该如何解决重复计算的问题
无缓存的递归:
function fib(n) {
return n <= 1 ? n : fib(n - 1) + fib(n - 2)
}
有缓存的递归:
let cache = {
}
function fib(n) {
if (n in cache) return cache[n]
return cache[n] = (n <= 1 ? n : fib(n - 1) + fib(n - 2))
}
可以在函数中添加
console.count()来对该函数的调用次数进行计数
题目2:试将高维数组 [1, 2, [3, [4, 5], 6], 7, [8], 9] 变为下方所示的对象
{
children: [
{
value: 1 },
{
value: 2 },
{
children: [
{
value: 3 },
{
children: [{
value: 4 }, {
value: 5 }] },
{
value: 6 }
]
},
{
value: 7 },
{
children: [{
value: 8}] },
{
value: 9 }
]
};
// 转换函数1
function convert(arr) {
return {
children: help(arr)}
}
function help(arr) {
let res = [];
for (let i = 0; i < arr.length; i++) {
if (typeof arr[i] === "number") {
res.push({
value: arr[i] });
} else if (Array.isArray(arr[i])) {
res.push({
children: help(arr[i]) });
}
}
return res;
}
// 转换函数2
function convert(item) {
if (typeof item == 'number')
return {
value: item }
if (Array.isArray(item))
return {
children: item.map(_item => convert(_item)) }
}
栈
JavaScript 中,栈可以用数组模拟,使用
push()和pop()
题目:试编写 “智能重复” smartRepeat 函数,实现:
- 将
3[abc]变为abcabcabc - 将
3[2[a]2[b]]变为aabbaabbaabb - 将
2[1[a]3[b]2[3[c]4[d]]]变为abbbcccddddcccddddabbbcccddddcccdddd
不用考虑输入字符串是非法的情况,比如:
2[a3[b]]是错误的,应该补一个 1,即2[1[a]3[b]][abc]是错误的,应该补一个 1,即1[abc]
一般遇到括号相关,需要做词法分析的时候,经常会使用到栈
思路:遍历每一个字符
- 如果这个字符是 数字,将数字压入栈A,空字符压入 栈B
- 如果这个字符是 字母,将 栈B 的栈顶改为该字母
- 如果这个字符是
],将 栈A 和 栈B 分别弹栈,进行组合,将组合结果拼接到 栈B 最顶层的字符串后面
function smartRepeact(templateStr) {
let stackA = [] // 存放数字
let stackB = [] // 存放临时字符串
let rest = templateStr // 剩余字符串
let idx = 0 // 指针
while (idx < templateStr.length - 1) {
rest = templateStr.substring(idx) // 更新剩余字符串
if (/^\d+\[/.test(rest)) {
// 判断是否以数字和 [ 开头
// 取出开头的数字
let times = Number(rest.match(/^(\d+)\[/)[1])
stackA.push(times)
stackB.push('')
idx += times.toString().length + 1
} else if(/^\w+\]/.test(rest)) {
// 判断是否以字母和 ] 开头
// 如果这个字符是字母,那么就把B栈顶这项改为这个字母
// 取出开头的字母
let word = rest.match(/^(\w+)\]/)[1]
stackB[stackB.length - 1] = word
idx += word.length
} else if (rest[0] === ']') {
// 如果这个字符是 ],组合两个栈的结果并放入栈B
let times = stackA.pop() // 取出栈顶的数字
let word = stackB.pop() // 取出栈顶的字符串
stackB[stackB.length - 1] += word.repeat(times)
idx++
}
}
return stackB[0].repeat(stackA[0])
}
正则表达式
补充一点 JS 中常用的正则表达式的知识:
// replace() 方法用于在字符串中用一些字符替换另一些字符,或替换一个与正则表达式匹配的子串
'abc666def123'.replace(/\d/g, '') // abcdef
// search() 方法用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串
// 找不到则返回 -1
'abc666def123'.search(/\d/g) // 3
// match() 方法可在字符串内检索指定的值,或找到一个或多个正则表达式的匹配
// 找不到则返回 null
'abc666def123'.match(/\d/g) // ['6', '6', '6', '1', '2', '3']
// test() 方法用于检测一个字符串是否匹配某个模式
/^\d/.test('5abc') // true
/^\d/.test('abc') // false
'555[abc]'.match(/^\d+\[/)
// ['555[', index: 0, input: '555[abc]', groups: undefined]
// () 表示捕获
'555[abc]'.match(/(^\d+)\[/)
// ['555[', '555', index: 0, input: '555[abc]', groups: undefined]
手写 AST 抽象语法树
本章源码:https://gitee.com/szluyu99/vue-source-learn/tree/master/AST_Study
识别开始结束标签
相关知识参考上面的 “算法储备 - 栈” 内容
parse.js:
export default function parse(templateStr) {
let rest = ''
// 开始标签的正则
const startRegExp = /^\<([a-z]+[1-6]?)\>/
// 结束标签的正则
const endRegExp = /^\<\/([a-z]+[1-6]?)\>/
// 结束标签前文字的正则(注意开头不含 <)
const wordRegExp = /^([^\<]+)\<\/[a-z]+[1-6]?\>/
let stackA = [], stackB = []
let index = 0
while (index < templateStr.length - 1) {
rest = templateStr.substring(index)
if (startRegExp.test(rest)) {
// 识别遍历到的字符,是 开始标签
let tag = rest.match(startRegExp)[1];
// console.log(`检测到开始标记:<${tag}>`);
stackA.push(tag) // 将开始标记推入 栈A
stackB.push([]) // 将空数组推入 栈B
// 移动开始标签的长度,由于 <> 是两个字符,所以需要 + 2
index += tag.length + 2
} else if (endRegExp.test(rest)) {
// 识别遍历到的字符,是 结束标签
let tag = rest.match(endRegExp)[1];
// console.log(`检测到结束标记:</${tag}>`);
// 此时,tag 一定和 栈A 顶部是相同的
if (tag === stackA[stackA.length - 1]) {
stackA.pop()
} else {
throw new Error(`${
stackA[stackA.length - 1]} 标签没有封闭`)
}
// 移动结束标签的长度,由于 </.> 是两个字符,所以需要 + 3
index += tag.length + 3
} else if (wordRegExp.test(rest)) {
// 识别到遍历的字符,是 文字(并且不能为全空)
let word = rest.match(wordRegExp)[1];
if (!/^\s+$/.test(word)) {
console.log(`检测到文字:${
word}`);
}
// 指针移动到文字的末尾
index += word.length
} else {
index++
}
// 未考虑文字在标签后面的情况,如:
// <p>123</p> hello
}
}
使用栈形成 AST
达到效果:
let htmlStr = `<div>
<h1>Hello</h1>
<ul>
<li>111</li>
<li>222</li>
<li>333</li>
</ul>
</div>`;
const ast = parse(htmlStr)
console.log(ast);
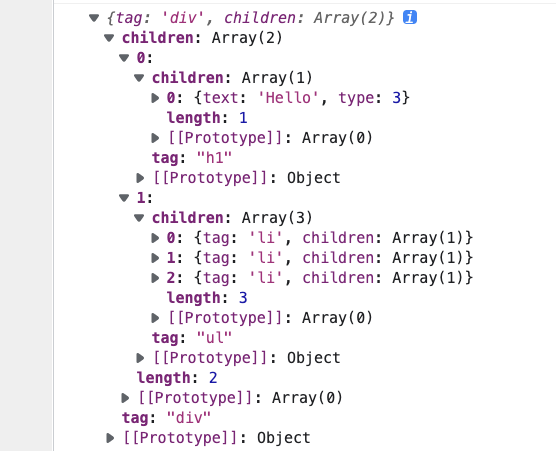
parse.js:
export default function parse(templateStr) {
let rest = "";
// 开始标签的正则
const startRegExp = /^\<([a-z]+[1-6]?)\>/;
// 结束标签的正则
const endRegExp = /^\<\/([a-z]+[1-6]?)\>/;
// 结束标签前文字的正则(注意开头不含 <)
const wordRegExp = /^([^\<]+)\<\/[a-z]+[1-6]?\>/;
let stackA = [];
let stackB = [{
children: [] }];
let index = 0;
while (index < templateStr.length - 1) {
rest = templateStr.substring(index);
if (startRegExp.test(rest)) {
// 识别遍历到的字符,是 开始标签
let tag = rest.match(startRegExp)[1];
console.log(`检测到开始标记:<${
tag}>`);
stackA.push(tag); // 将开始标记推入 栈A
stackB.push({
tag: tag, children: [] }); // 将空数组推入 栈B
// 移动开始标签的长度,由于 <> 是两个字符,所以需要 + 2
index += tag.length + 2;
// console.log(stackA, stackB);
} else if (endRegExp.test(rest)) {
// 识别遍历到的字符,是 结束标签
let tag = rest.match(endRegExp)[1];
console.log(`检测到结束标记:</${
tag}>`);
let pop_tag = stackA.pop();
// 此时,tag 一定和 栈A 顶部是相同的
if (tag === pop_tag) {
let pop_arr = stackB.pop();
if (stackB.length > 0) {
stackB[stackB.length - 1].children.push(pop_arr);
}
} else {
throw new Error(`${
stackA[stackA.length - 1]} 标签没有封闭`);
}
// 移动结束标签的长度,由于 </.> 是两个字符,所以需要 + 3
index += tag.length + 3;
// console.log(stackA, stackB);
} else if (wordRegExp.test(rest)) {
// 识别到遍历的字符不是 文字(并且不能为全空)
let word = rest.match(wordRegExp)[1];
// 文字不能全是空
if (!/^\s+$/.test(word)) {
console.log(`检测到文字:${
word}`);
// 改变此时 stackB 中的栈顶元素
stackB[stackB.length - 1].children.push({
text: word, type: 3 });
console.log(stackB);
}
// 指针移动到文字的末尾
index += word.length;
} else {
index++;
}
// 未考虑文字在标签后面的情况,如:
// <p>123</p> hello
}
console.log(stackB);
return stackB[0].children[0]
}
识别 Attrs
parseAttrsString.js:把 attrsString 解析成 attrs 对象数组
- 解析前的字符串:
class="box red" id="mybox" - 解析后的对象数组:
[
{
name: 'class',
value: 'box red'
},
{
name: 'id',
value: 'mybox'
}
]
parseAttrsString 算法核心思路:
- 遍历 attrsStr,如果遇到了空格,且不在引号中,则将前一个断点到当前为止的字符串加入 result
/**
* 把 attrsString 解析成 attrs 对象数组
*/
export default function parseAttrsString(attrsStr) {
if (!attrsStr) return []
let inFlag = false // 当前是否处于引号内
let point = 0 // 断点处
let result = []
// 遍历 attrsStr,不能直接用 split(),有如下情况 class="aa bb cc" id="gg"
for (let i = 0; i < attrsStr.length; i++) {
let c = attrsStr[i]
if (c === '"') inFlag = !inFlag // 遇到 双引号,切换 inFlag 状态
else if (c === ' ' && !inFlag) {
// 遇见 空格,且不在引号中
if (!/^\s*$/.test(attrsStr.substring(point, i))) {
// 不全为空格
result.push(attrsStr.substring(point, i).trim())
point = i
}
}
}
// 循环结束后,还剩一个属性
result.push(attrsStr.substring(point).trim())
// 将 ["k1=v1", "k2=v2"] 变为 [{name: k1, value: v1}, {name: k2, value: v2}]
result = result.map(item => {
const o = item.match(/^(.+)="(.+)"$/)
return {
name: o[1], value: o[2] }
})
return result
}
parse.js:
export default function parse(templateStr) {
let rest = "";
// 开始标签的正则
const startRegExp = /^\<([a-z]+[1-6]?)(\s[^\<]+)?\>/;
// 结束标签的正则
const endRegExp = /^\<\/([a-z]+[1-6]?)\>/;
// 结束标签前文字的正则(注意开头不含 <)
const wordRegExp = /^([^\<]+)\<\/[a-z]+[1-6]?\>/;
let stackA = [];
let stackB = [{
children: [] }];
let index = 0;
while (index < templateStr.length - 1) {
rest = templateStr.substring(index); // 更新剩余字符串
if (startRegExp.test(rest)) {
// 识别遍历到的字符,是 开始标签
let tag = rest.match(startRegExp)[1]; // 标签内容
let attrsString = rest.match(startRegExp)[2] // attr 内容
// console.log(`检测到开始标记:<${tag}>`);
stackA.push(tag); // 将开始标记推入 栈A
stackB.push({
tag: tag,
children: [],
attrs: parseAttrsString(attrsString) // 解析属性字符串
}); // 将空数组推入 栈B
// 移动开始标签的长度,由于 <> 是两个字符,所以需要 + 2,还需加上 attrs 的长度
index += tag.length + 2 + (attrsString?.length || 0);
// console.log(stackA, stackB);
} else if (endRegExp.test(rest)) {
// 识别遍历到的字符,是 结束标签
let tag = rest.match(endRegExp)[1]; // 标签内容
// console.log(`检测到结束标记:</${tag}>`);
let pop_tag = stackA.pop(); // 栈A 顶部元素
// 此时,tag 一定和 栈A 顶部是相同的
if (tag === pop_tag) {
let pop_arr = stackB.pop();
if (stackB.length > 0) {
stackB[stackB.length - 1].children.push(pop_arr);
}
} else {
throw new Error(`${
pop_tag} 标签没有封闭`);
}
// 移动结束标签的长度,由于 </> 是两个字符,所以需要 + 3
index += tag.length + 3;
// console.log(stackA, stackB);
} else if (wordRegExp.test(rest)) {
// 识别到遍历的字符,是 文字(并且不能为全空)
let word = rest.match(wordRegExp)[1];
// 文字不能全是空
if (!/^\s+$/.test(word)) {
// console.log(`检测到文字:${word}`);
// 改变此时 stackB 中的栈顶元素
stackB[stackB.length - 1].children.push({
text: word, type: 3 });
// console.log(stackB);
}
// 指针移动到文字的末尾
index += word.length;
} else {
index++;
}
// 未考虑文字在标签后面的情况,如:
// <p>123</p> hello
}
return stackB[0].children[0]
}