前言
虽然在 YuleFox、Yang.Y、acgtyrant等诸位大佬的努力下,Google 开源项目风格指南——中文版已经大幅减轻了我们的学习成本,但是文中部分专业的术语或者表达方式还是让过于萌新的读者(比如说我)在流畅的阅读过程中突遇卡顿,不得不查阅各种资料理清原委,这也是写学习笔记的初衷。
0. 缩写名词解释
- ODR(One Definition Rule):单一定义规则
- POD(Plain Old Data):原生数据类型
- RVO(Return value optimization):返回值优化
- NRVO(Named Return Value Optimization):具名返回值优化
- RAII(Resource Acquisition Is Initialization):资源获取就是初始化,保证在任何情况下,使用对象时先构造对象,最后析构对象,是种避免内存泄漏的方法。
- RTTI(Run-Time Type Identification):运行时类型识别
1. 头文件
1.1. Self-contained 头文件
Self-contained(自给自足) :所有头文件要能够自给自足。换言之,include 该头文件之后不应该为了使用它而再包含额外的头文件。举个例子:
// a.h
class MyClass {
MyClass(std::string s);
};
// a.cc
#include “a.h”
int main(){
std:string s;
MyClass m(s);
return 0;
}
a.cc文件会因为没有 #include <string> 而无法成功编译。但是,本质原因是因为 a.h 文件用到了 std::string 却没有 #include <string>,因此 a.h 文件没有做到自给自足 (Self-contained )。
特殊情况
- 如果
.h文件声明并定义了一个模板或内联函数。那么凡是有用到模版或内联函数的.cc文件,就必须包含该头文件(不是.cc文件对应的.h是否包含该头文件的问题了),否则程序可能会在构建中链接失败。 - 虽然推荐在头文件中对模版进行声明并定义,但是如果某函数模板为所有相关模板参数显式实例化,或本身就是某类的一个私有成员,那么它就只能定义在实例化该模板的
.cc文件里。
1.2. 头文件保护
头文件保护旨在防止头文件被多重包含,当一个头文件被多次 include 时,可能会出现以下问题:
- 增加编译工作的工作量;
- 有可能引起错误,例如在头文件中定义了全局变量,重复包含会引起重复定义。
为保证唯一性,通常有两种解决方法:
- #program once:“同一个文件”指存储在相同位置的文件,即物理位置下相同;当编译器意识到文件存储位置相同时便会跳过“副本文件”,仅仅编译一次该物理位置的文件;但如果发生拷贝情况,即同一个文件在别的物理位置有“备份”,那么仍然有可能出现重复包含的情况。
- #ifndef—#define—#endif:在#define阶段对头文件进行宏定义(规定别名),头文件的命名应该基于所在项目源代码树的全路径。注意别名不能重复。
例如,项目 foo 中的头文件 foo/src/bar/baz.h 可按如下方式保护:
#ifndef FOO_BAR_BAZ_H_ // if not defined,如果FOO_BAR_BAZ_H_没有被宏定义过
#define FOO_BAR_BAZ_H_ // 那么对FOO_BAR_BAZ_H_进行宏定义
...
#endif // if范围结束
#program once 较 #ifndef 出现的晚,因此兼容性会较 #ifndef 差一些,但性能会好一些。
1.3. 前置声明
「前置声明」(forward declaration)是类、函数和模板的纯粹声明,没有定义。
优点:
- 省时间,无需编译不需要的部分,include 会编译整个头文件。
- 还是省时间,使用前置声明时,如果修改头文件中的无关部分,不会重新编译整个头文件。
缺点 - 很难判断什么时候该用前置声明,什么时候该用
#include。极端情况下,用前置声明代替#include甚至会改变代码的含义:
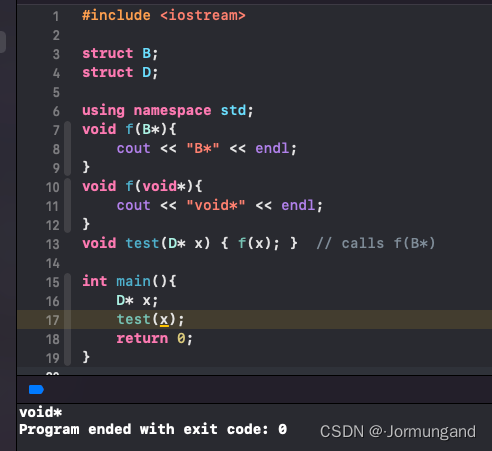
// b.h:
struct B {
};
struct D : B {
};
// good_user.cc:
#include "b.h"
void f(B*);
void f(void*);
void test(D* x) {
f(x); } // calls f(B*)
如果 #include 被 B 和 D 的前置声明替代,此时由于没有函数定义,D继承自B这一关系未显现,因此调用 test 函数时会调用f(void*)。
实测:
1.4 内联函数
- 滥用内联将导致程序变得更慢;
- 最好不要内联超过
10行的函数; - 谨慎对待析构函数,析构函数往往比其表面看起来要更长,因为有隐含的成员和基类析构函数被调用;
- 内联那些包含循环或
switch语句的函数常常是得不偿失 ; - 有些函数即使声明为内联的也不一定会被编译器内联:比如虚函数和递归函数。
- 通常,递归函数不应该声明成内联函数。(递归调用堆栈的展开并不像循环那么简单, 比如递归层数在编译时可能是未知的,大多数编译器都不支持内联递归函数)。
- 虚函数内联的主要原因则是想把它的函数体放在类定义内,为了图个方便,亦或是当作文档描述其行为,比如精短的存取函数。
- 类内部的函数一般会自动内联。所以某函数一旦不需要内联,其定义就不要再放在头文件里,而是放到对应的
.cc文件里。这样可以使头文件的类保持精炼,也很好地贯彻了声明与定义分离的原则。 - 内联函数必须放在
.h文件中,如果成员函数比较短,也直接放在.h中(让它成为内联函数)。
1.5. #include 的路径及顺序
路径
项目内头文件应按照项目源代码目录树结构排列,避免使用 UNIX 特殊的快捷目录: . (当前目录) 或 .. (上级目录)。例如,google-awesome-project/src/base/logging.h 应该按如下方式包含:
#include "base/logging.h"
顺序
dir/foo.cc 的主要作用是实现或测试 dir2/foo2.h 的功能,foo.cc 中包含头文件的次序如下:
- 相关头文件(此处的
dir2/foo2.h) - C 系统文件
- C++ 系统文件
- 其他库的
.h文件(比如OpenGL和Qt) - 本项目内
.h文件
按字母顺序分别对每种类型的头文件进行二次排序是不错的主意。
例外:有时,部分 include 语句需要条件编译(conditional includes),这些代码可以放到其它 includes 之后。
#include "foo/public/fooserver.h"
#include "base/port.h" // For LANG_CXX11.
#ifdef LANG_CXX11
#include <initializer_list>
#endif // LANG_CXX11
内容
- 依赖的符号 (
symbols) 被哪些头文件所定义,就应该包含(include)哪些头文件,即使这些头文件可能已经被已经包含(include)的头文件包含(include)了。举例:- 比如要用到
bar.h中的某个符号,哪怕所包含的foo.h已经包含了bar.h,也照样得包含bar.h, 除非foo.h有明确说明它会自动提供bar.h中的symbol。
- 比如要用到
- 凡是
cc文件所对应的「相关头文件」已经包含的,就不用再重复包含进cc文件里面了,就像foo.cc只包含foo.h就够了,不用再管foo.h所包含的其它内容。
2. 作用域
2.1. 命名空间
- 鼓励在
.cc文件内使用匿名命名空间或static声明,但不要在.h文件中这么做; - 在头文件中使用匿名空间违背 C++ 的唯一定义原则 (ODR);
- 不要在头文件中使用
命名空间别名除非显式标记内部命名空间使用。 - 使用具名的命名空间时,其名称可基于项目名或相对路径;
- 禁止使用
using指示(using-directive); - 禁止使用内联命名空间(inline namespace);
- 在命名空间的最后注释出命名空间的名字;
namespace a {
...code for a... // 左对齐 不缩进
} // namespace a
/* 即使是匿名空间也需要在最后做出注释 */
namespace {
...
} // namespace
- 声明嵌套命名空间时,每个命名空间都独立成行。
namespace foo {
namespace bar {
// 不要有额外缩进
} // namespace bar
} // namespace foo
- 声明嵌套命名空间时,每个命名空间都独立成行。
namespace foo {
namespace bar {
// 不要有额外缩进
} // namespace bar
} // namespace foo
2.2. 非成员函数、静态成员函数和全局函数
- 尽量使用 静态成员函数 或 命名空间内的非成员函数 来代替 裸的(不在命名空间内的)全局函数。对于前两者而言,如果一个函数跟类没有密切关系,那么就将它作为非成员函数直接置于命名空间中,即不要随便用类的静态方法模拟出命名空间的效果,类的静态方法应当和类的实例或静态数据紧密相关。
- 如果必须定义非成员函数,又只是在
.cc文件中使用它,可在.cc文件中使用 匿名命名空间 或 static链接关键字 限定其作用域。如:
// .cc 文件内
static int Foo() {
...
}
2.3. 局部变量
- 将函数变量尽可能置于最小作用域内,并且不要将初始化分离成 声明 + 赋值。
- 属于
if、while和for语句的变量应当在这些语句中声明,以此将变量的作用域限制在语句中。
有一个例外,如果变量是一个对象,每次进入作用域都要调用其构造函数,每次退出作用域都要调用其析构函数,这会导致效率降低。
// 低效的实现
for (int i = 0; i < 1000000; ++i) {
Foo f; // 构造函数和析构函数分别调用 1000000 次!
f.DoSomething(i);
}
在循环作用域外面声明这类变量要高效的多:
Foo f; // 构造函数和析构函数只调用 1 次
for (int i = 0; i < 1000000; ++i) {
f.DoSomething(i);
}
2.4. 静态和全局变量
以下提及的 静态变量 泛指 静态生存周期的对象,包括:全局变量、静态变量、静态类成员变量以及函数静态变量。
不定顺序问题
同一个编译单元内初始化顺序是明确的,静态初始化优先于动态初始化(如果动态初始化未被提前),初始化顺序按照声明顺序进行,销毁则逆序。但是不同的编译单元之间初始化和销毁顺序属于未明确行为 (unspecified behaviour)。
同时,静态变量在程序中断时会被析构,无论所谓中断是从main()返回还是对exit()的调用。析构顺序正好与构造函数调用的顺序相反。但如第一段所言,既然构造顺序未定义,那么析构顺序当然也就不定了。比如,在程序结束时某静态变量已经被析构了,但代码还在跑,此时其它线程试图访问它且失败;再比如,一个静态string变量也许会在一个引用了它的其它变量析构之前被析构掉。
- 静态生存周期的对象都必须是
POD:即int、char和float,以及POD类型的指针、数组和结构体。即完全禁用vector(可以使用 C 数组替代) 和string(可以使用const char []替代)。 - 如果确实需要一个
class类型的静态变量,可以考虑在main()函数或pthread_once()内初始化一个指针且永不回收。注意只能用raw(原始) 指针,别用智能指针,毕竟后者的析构函数涉及到不定顺序问题。 - 禁止使用类的
static变量:因为它的生命周期不跟随类的生命周期,因此会导致难以发现的bug。不过constexpr变量除外,毕竟它们又不涉及动态初始化或析构。 - 禁用 类类型的静态变量。尽量不用全局函数和全局变量,考虑作用域和命名空间限制,尽量单独形成编译单元。
- 只能用不涉及任何 静态变量 的函数其 返回值 来初始化 POD变量。【这里说的不涉及任何静态变量不包括函数作用域里的静态变量,毕竟它的初始化顺序是有明确定义的,而且只会在指令执行到它的声明那里才会发生。】
3. 类
3.1. 构造函数的职责
- 构造函数应该只做一件事:初始化成员,但不是一定要初始化全部成员。
- 不要在构造函数中调用虚函数:
- 因为虚函数表指针也是对象的成员之一,是在构造函数初始值列表执行时时才生成的。
- 如果在构造函数内调用了自身的虚函数, 这类调用是不会重定向到子类的虚函数实现。即使当前没有子类化实现,将来仍是隐患。
- 构造函数内仅允许执行不会失败的初始化行为,因为在没有使程序崩溃 (因为并不是一个始终合适的方法) 或者使用异常 (因为已经被禁用了) 等方法的条件下,构造函数很难上报错误。
举个例子,假定A的初始化可能会出错,因此使用命名空间Initialization内的函数InitializationA来初始化A(方便捕捉错误信息),假设B中有A这样的初始化可能会出错的成员,也有POD成员,那么POD成员的初始化可以放在构造函数中执行,而A这样的初始化可能会出错的成员必须放在一个单独的成员函数InitMember中去执行,并捕捉错误信息且返回。在真正构造B的对象时,必须调用构造函数+InitMember才能完整实现构造行为,之后才能使用B中的成员:
class A{
...// 类内详情不表
};
namespace Initialization{
std::string InitializationA(){
std::string errorInfo;
...// 执行 成员a 的初始化,并且将可能出现的错误信息保存到变量errorInfo中并输出
return errorInfo;
}
} // namespace Initialization
class B{
A a;
... // 其他初始化有可能失败的成员
int bi;
public:
B(int bi_):bi(bi_){
} // 构造函数中不执行B类成员a的初始化,因为a的初始化可能出错
std::string InitMember(){
if (!(Initialization::InitializationA().empty())) {
// 如果返回值不为空说明初始化 a 失败
return Initialization::InitializationA(); // 返回错误说明
}
... // 执行其他可能失败的初始化
return NULL; // 所有可能失败的初始化都成功了,返回空
}
void useA(){
...// 使用 成员a 的代码
}
};
int main(){
// 调用顺序
B b(3); // 构造函数
b.InitA(); // 初始化 a
if(b.InitMember().empty()) {
b.useA(); // 有可能失败的初始化都成功才能使用对应的成员
}
return 0;
}
3.2. 隐式类型转换
不要定义隐式类型转换。对于转换运算符和单参数构造函数,请使用explicit关键字。否则会有类型转换二义性的问题。
- 拷贝、移动构造函数不应当被标记为
explicit,因为它们并不执行类型转换。 - 不能以一个参数进行调用的构造函数不应当加上
explicit。初始化器列表构造函数(接受一个std::initializer_list作为参数的构造函数)也应当省略explicit,以便支持拷贝初始化(例如MyType m = {1, 2};)。 - 对于设计目的就是用于对其他类型进行透明包装的类来说,隐式类型转换有时是必要且合适的。这时应当写明注释以便于理解。
3.3. 可拷贝类型和可移动类型
如果类型不需要支持拷贝/ 移动,就把隐式产生的拷贝和移动函数禁用。因为某种情况下(如:通过传值的方式传递对象)编译器会隐式调用拷贝和移动函数。
禁用隐式产生的拷贝和移动函数有两种方法:
- 在
public域中通过=delete:
class A{
public:
A() = default; // 使用合成的默认构造函数
// class A is neither copyable nor movable.
A(const A&) = delete; // 阻止拷贝
A &operator=(const A&) = delete; // 阻止赋值
};
- 在旧标准中通过 声明成
private但不定义的方法 来起到新标准中=delete的作用,此时试图使用该种函数的用户代码将在编译阶段被标记为链接错误。
复制消除
- 对指南中提到的 拷贝/ 移动构造函数支持Copy elision(复制消除)优化 这一项做出介绍。
总结
- 如果拷贝操作不是一眼就能看出来的,那就不要把类型设置为可拷贝。
- 拷贝的两个操作(拷贝构造函数和赋值操作)应该同时存在/被禁用,移动的两个操作(移动构造函数和赋值操作)同理。
- 可拷贝对象都是可移动的,但可移动对象未必是可拷贝的,如:
std::unique_ptr<int>。 - 由于存在 对象切割 的风险,不要为基类提供赋值操作或者拷贝/移动构造函数。如果基类需要可复制属性,请提供一个
public virtual Clone()和一个protected的拷贝构造函数以供派生类实现。 - 拷贝构造函数使用不当会造成过度拷贝,导致性能上的问题。
- 如果定义了拷贝/移动操作, 则要保证这些操作的默认实现是正确的。记得时刻检查默认操作的正确性,并且在文档中说明类是可拷贝的且/或可移动的。
3.4. struct VS class
struct 用来定义包含数据的被动式(等待初始化或赋值)对象,也可以包含相关的常量,但除了存取数据成员之外,没有别的函数功能。并且存取功能是通过直接访问位域实现的,而非函数调用。除了构造函数、析构函数、Initialize()、Reset()、Validate() 等类似的用于设定数据成员的函数外,不能提供其它功能的函数。
- 如果需要更多的函数功能,
class更适合。如果拿不准,就用class。 - 为了和
STL保持一致,对于仿函数等特性可以不用class而是使用struct。 - 类和结构体的成员变量使用不同的命名规则。
3.5. 继承
组合 > 实现继承 > 接口继承 > 私有继承
- 继承主要用于两种场合:
- 实现继承,子类继承父类的实现代码;
- 接口继承,子类仅继承父类的方法名称。
- 所有继承必须是
public的。如果想使用私有继承,可以把基类的实例作为类内成员。 is-a的情况下才实现继承,has-a的情况下使用组合。即如果Bar的确 “是一种”Foo,Bar才能继承Foo。- 有虚函数的类的析构函数必须定义为虚析构函数。
- 对于重写的虚函数或虚析构函数,使用
override或 (较不常用的)final关键字显式地进行标记。早于C++11的代码可能会使用virtual关键字作为不得已的选项。
3.6. 多重继承
真正需要用到多重实现继承的情况少之又少。
多重继承应遵循:最多只有一个基类是非抽象类;其它基类都是以 Interface 为后缀的纯接口类。
3.7. 接口
纯接口:
- 这些类的类名以
Interface为后缀(不强制)。
class Foo_Interface {
... // 类的具体细节
};
- 除带实现的虚析构函数、静态成员函数外,其他均为纯虚函数。没有非静态数据成员。
- 没有定义任何构造函数。如果有,也不能带有参数,并且必须为
protected。 - 如果它是一个子类,也只能从满足上述条件并以
Interface为后缀的类继承而来。
为确保接口类的所有实现可被正确销毁,必须为之声明虚析构函数(因此析构函数不能是纯虚函数)。
3.8. 运算符重载
尽量不要重载运算符,也不要创建用户定义字面量。不得不使用时提供说明文档。
不要
- 不要将不进行修改的二元运算符定义为成员函数。如果一个二元运算符被定义为类成员,这时隐式转换会作用于右侧的参数却不会作用于左侧。会出现
a < b能够通过编译而b < a不能的情况,这是很让人迷惑的。 - 不要引入用户定义字面量,即不要重载
operator""。 - 不要重载
&&、||、,、一元运算符 &。重载一元运算符&会导致代码具有二义性。重载&&、||和,会导致运算顺序和内建运算的顺序不一致。
而要
- 合理性。不要为了避免重载操作符而走极端。比如说,应当定义
==、=和<<而不是Equals()、CopyFrom()和PrintTo()。但是,不要只是为了满足函数库需要而去定义运算符重载。比如说,如果类型没有自然顺序,而又要将它们存入std::set中,最好还是定义一个自定义的比较运算符(比较函数?)而不是重载<。 - 一致性。只有在意义明显,不会出现奇怪的行为并且与对应的内建运算符的行为一致时才定义重载运算符。例如:
|要作为位或或逻辑或来使用,而不是作为shell中的管道。 - 模块化。将类型重载运算符和它们所操作的类型定义在同一个
头文件中、.cc中和命名空间中。这样做无论类型在哪里都能够使用定义的运算符,并且最大程度上避免了多重定义的风险。 - 普适性。如果可能的话,请避免将运算符定义为模板,因为此时它们必须对任何模板参数都能够作用。
- 整体性。如果你定义了一个运算符,请将其相关且有意义的运算符都进行定义,并且保证这些定义的语义是一致的。例如,如果你重载了
<,那么请将所有的比较运算符都进行重载,并且保证对于同一组参数,<和>不会同时返回true。
3.9. 存取控制与声明顺序
- 不要将大段的函数定义内联在类定义中。
- 将 所有 数据成员声明为
private,除非是static const类型成员。 - 类定义一般应以
public:开始,后跟protected:,最后是private:; - 除
public外,其他关键词前要空一行。如果类比较小的话也可以不空。但是关键词后不要保留空行。 - 将类似的声明放在一起,并且建议以如下的顺序:
- 类型 (包括
typedef、using和嵌套的结构体与类) - 常量
- 工厂函数
- 构造函数
- 赋值运算符
- 析构函数
- 其它函数
- 数据成员
- 类型 (包括
4. 函数
如果函数超过 40 行,可以思索一下能不能在不影响程序结构的前提下对其进行分割。
4.1. 引用参数
所有按引用传递的参数必须加上 const。
- 在 C 语言中,如果函数需要修改变量的值,参数必须为指针,如
int foo(int *pval)。 - 在 C++ 中,函数还可以声明为引用参数
int foo(int &val)。
引用参数的优点
- 可以防止在函数体中出现
(*pval)++这样丑陋的代码。 - 对于拷贝构造函数而言是必需的。
- 更明确地表示不接受空指针。
引用参数不使用的情况
有时候,在输入形参中用 const T* 指针比 const T& 更明智。比如:
- 有传空指针的需求。
- 函数要把指针或对地址(而不是对象)的引用赋值给输入形参。
- 换言之,可以有指向指针/引用的指针,没有绑定指针/引用的引用。
- 或者说指针可以操作复合类型,但是引用不可以。
double a = 3.0;
double *p = &a;
double &b = p; // 引用不能绑定地址的引用(指针本身)
double &b = *p; // 引用可以绑定指针指向的对象
4.2. 函数重载
在同一个作用域下,对于相同的函数名:
- 参数类型不同
- 参数顺序不同
- 参数个数不同
都可以形成函数的重载。
- 参数名不同
- 返回值不同
不形成重载。
缺点
- 如果函数重载是根据参数顺序和参数类型不同,使用时就得十分熟悉 C++ 五花八门的匹配规则,以了解匹配过程。
- 如果派生类只重载了某个函数的部分变体,继承语义就容易令人困惑。
结论
- 将重载行为改为在函数名里加上参数信息。例如,用
AppendString()和AppendInt()等而不是一口气重载多个Append()。 - 如果重载函数的目的是为了支持不同数量的同一类型参数,则优先考虑使用
std::vector作为形参以便使用者可以用 列表初始化 传入实参。
4.3. 缺省参数
- 只允许在非虚函数中使用缺省参数,且必须保证(子类重定义的)缺省参数的值(与父类的同名函数缺省参数的值)始终一致。
- 一般情况下建议使用函数重载,除非缺省函数带来的可读性提升弥补了它的缺点。
- 可读性:更好地区别了 必要参数 和 可选参数(有缺省值的就是可选参数)。
缺点
- 在一个现有函数添加缺省参数,就会改变它的函数签名,这会干扰函数指针,导致函数签名与调用点的签名不一致。而函数重载不会导致这样的问题。
- C 函数签名只有函数名
- C++ 函数签名是函数名 + 参数类型
- 函数签名在同一作用域内唯一
// Before change.
void func(int a);
func(42);
void (*func_ptr)(int) = &func;
// After change.
void func(int a, int b = 10);
func(42); // Still works.
void (*func_ptr)(int) = &func; // Error, wrong function signature.
/* 此外把自带缺省参数的函数地址赋值给指针时,会丢失缺省参数信息。*/
void optimize(int level=3);
void (*fp)() = &optimize; // 即使参数是缺省的,也不可以省略对类型的说明
// 错误 error: invalid conversion from ‘int (*)(int)’ to ‘int (*)()’
void (*fpi)(int) = &optimize; // 正确
- 缺省实参并不一定是常量表达式,可以是任意表达式,甚至可以通过函数调用给出。如果缺省实参是任意表达式,则函数每次被调用时该表达式被重新求值,这会造成生成的代码迅速膨胀。尤其不要写像
void f(int n = counter++);这样的代码。
int my_rand() {
srand(time(NULL));
int ra = rand() % 100;
return ra;
}
void fun(int a, int b = my_rand()) {
// 缺省实参是表达式
cout << "a = " << a << " b= " << b << endl;
}
- 虚函数调用的缺省参数取决于目标对象的静态类型,而绑定的具体函数是动态绑定,因此即使基类与派生类缺省参数值是一致的,就会造成阅读障碍。举个例子:
#include <iostream>
using namespace std;
class A {
public:
virtual void Fun(int number = 10)
{
cout << "A::Fun with number " << number;
}
};
class B: public A {
public:
virtual void Fun(int number = 20)
{
cout << "B::Fun with number " << number << endl;
}
};
int main() {
B b;
A &a = b;
a.Fun(); // 输出结果是 B::Fun with number 10
return 0;
}
输出结果是B::Fun with number 10。调用虚函数Fun时,A类指针a指向了B类对象b,这就导致缺省值静态绑定了A类成员函数Fun的缺省值number = 10,而函数内容动态绑定了指向对象B类的成员函数Fun。
结论
可以在以下情况使用缺省参数:
- 位于
.cc文件里的静态函数或匿名空间函数,毕竟他们的生命周期被限定在局部文件里。 - 可以在构造函数里用缺省参数,毕竟不可能取得构造函数的地址。
- 可以用来模拟变长数组(详见6.2):
// b、c、d 作为变长数组,维度根据 gEmptyAlphaNum 指定
string StrCat(const AlphaNum &a,
const AlphaNum &b = gEmptyAlphaNum,
const AlphaNum &c = gEmptyAlphaNum,
const AlphaNum &d = gEmptyAlphaNum);
4.4. 输入和输出
按值返回 > 按引用返回。 避免返回指针,除非可以为空。
- C++ 函数的输出可以由返回值提供也可以通过输出参数提供。尽量使用返回值,因为它的可读性高,性能更好。
- 某些参数既是输出参数同时又是输入参数, Google 开源项目风格指南 中称之为输出/输入参数,而这里将其单纯称之为输出参数。举个例子:
void foo (int input1, double input2, int &output){
output = output - (input1 + input2);
// 函数外继续使用output对应的实参进行后续操作即可
// 什么是纯输出参数呢?
// 个人理解就是 outpet 不参与类型运算,仅接受输入参数运算结果的情况吧
// 即上面的语句变更为 output = input1 + input2;
}
- 避免定义需要const引用参数超出生命周期的函数, 比如const引用参数需要与临时变量绑定的情况。要尽量消除生命周期限制:
- 通过复制参数代替const引用参数;
- 通过const指针传递临时变量并记录生命周期和非空要求。
- 在给函数参数排序时,将所有输入参数放在所有输出参数之前。加入新参数时不要置于参数列表最后,仍然要按照前述的规则,即将新的输入参数也置于输出参数之前。
函数参数的类型选择
- 对于非可选的参数(该参数没有缺省值):
- 输入参数通常是值参或const引用;(若用
const T*则说明有特殊情况【详见4.1】,所以应在注释中给出相应的理由。) - 输出参数通常应该是不为空的引用;
- 输入参数通常是值参或const引用;(若用
- 对于可选的参数:
- 通常使用
std::optional来表示按值输入; - 使用
const指针来表示其他输入; - 使用
非const指针来表示输出参数。 - C++17之
std::optional详见两篇博客:
- 通常使用
4.5. 函数返回类型后置语法
- 前置返回类型:
int foo(int x);
- 在函数名前使用
auto关键字,在参数列表之后说明后置返回类型:
auto foo(int x) -> int;
优点
- 后置返回类型是显式地指定 Lambda 表达式 的返回值的唯一方式。
- 在返回类型依赖于模板参数时,后置返回类型比前置可读性更高,例如:
// 后置
template <class T, class U> auto add(T t, U u) -> decltype(t + u);
// 前置
template <class T, class U> decltype(declval<T&>() + declval<U&>()) add(T t, U u);
5. 所有权与智能指针
动态分配对象的所有者是一个对象或函数,所有者负责确保当前者无用时就自动销毁前者。
两种智能指针
std::unique_ptr离开作用域时(其本身被销毁),对象就会被销毁。std::unique_ptr不能被复制,但可以把所指对象移动(move)给新所有者。std::shared_ptr同样表示动态分配对象的所有权,但可以被共享和复制;对象的所有权由所有复制者共同拥有,最后一个复制者被销毁时,对象也会随着被销毁。
结论
- 对于
const对象来说,智能指针简单易用,也比深拷贝高效。 - 值语义的开销经常被高估,所以所有权传递带来的性能提升不一定能弥补可读性和复杂度的损失。
- 智能指针是一把双刃剑,虽然不会忘记释放资源,但是释放资源的位置不明显。
- 某些极端情况下 (例如循环引用),所有权被共享的对象永远不会被销毁。
- 只有在为避免开销昂贵的拷贝操作、性能提升非常明显,并且操作的对象是不可变的(比如说
std::shared_ptr<const Foo>)时候,才该使用std::shared_ptr。
6. 其他 C++ 特性
6.1. 右值引用
- 只在定义移动构造函数与移动赋值操作时使用右值引用,不要使用
std::forward。 - 要高效率地使用某些标准库类型,例如
std::unique_ptr,std::move是必需的。
6.2. 变长数组和 alloca()
变长数组中的“变”指的是:在创建数组时,可以使用变量指定数组的维度。而不是可以修改已创建数组的大小。一旦创建了变长数组,它的大小则保持不变。
- 变长数组和
alloca()不是标准 C++ 的组成部分(C99中变长数组作为函数形参)。 - 变长数组和
alloca()根据数据大小动态分配堆栈内存,会引起难以发现的内存越界bug: “在我的机器上运行的好好的,发布后却莫名其妙的挂掉了。”
6.3. 友元
- 友元扩大了(但没有打破)类的封装边界。部分情况下,相对于将类的
private、protected成员声明为public,使用友元是更好的选择。尤其是只允许另一个类访问该类的私有成员时。下面列举两个情景:- 将
FooBuilder声明为Foo的友元,以便FooBuilder正确构造Foo的内部状态。 - 另一种情景是将一个单元测试类声明成待测类的友元。
- 将
- 通常友元应该定义在同一文件内,避免代码读者跑到其它文件查找使用私有成员的友元。
friend实际上只对函数/类赋予了对其所在类的访问权限,并不是有效的声明语句。所以除了在头文件类内部写friend函数/类,还要在类作用域之外正式地声明一遍,最后在对应的.cc文件加以定义。
6.4. 异常
- 禁止使用 C++ 异常.
优点
- 异常是处理构造函数失败的唯一途径。虽然可以用工厂函数(
factory function,即「简单工厂模式」)或Init()方法代替异常,但是前者要求在堆栈分配内存,后者会导致构造函数创建的实例处于“无效”状态。(调用Init()方法真正完成对类内成员的构造后才能叫做“有效”)
缺点
- 启用异常会增加二进制文件数据,延长编译时间(或许影响小),还可能加大地址空间的压力。
- 滥用异常会变相鼓励开发者去捕捉不合时宜,或本来就已经没法恢复的「伪异常」。比如,用户的输入不符合格式要求时,也用不着抛异常。如此之类的伪异常列都列不完。
- 在现有函数中添加
throw语句时,必须检查所有调用点。要么让所有调用点统统具备最低限度的异常安全保证,要么眼睁睁地看异常一路欢快地往上跑,最终中断掉整个程序。举例:f()调用g()、g()又调用h()、且h抛出的异常被f捕获,忽略了g。
结论
- 对于异常处理,显然不是短短几句话能够说清楚的,以构造函数为例,很多 C++ 书籍上都提到当构造失败时只有异常可以处理。
- Google 禁止使用异常这一点,说大了,无非是考虑到软件管理成本,实际使用中还是自己决定。
- 对使用 C++ 异常处理应具有怎样的态度? 非常值得一读。
6.5. 运行时类型识别
RTTI 允许程序员在运行时识别 C++ 类对象的类型。它通过使用 typeid 或者 dynamic_cast 完成。
RTTI 有合理的用途但是容易被滥用,因此在使用时请务必注意。
- 在运行时判断类型通常意味着设计问题。请考虑用以下的两种替代方案之一来查询类型:
- 虚函数:把查询类型交给对象本身去处理,可以根据调用对象的不同而执行不同代码。
- 类型判断需要在对象之外完成时,可以考虑使用双重分发的方案。例如使用访问者设计模式。
- 如果能够保证给定的基类实例实际上都是某个派生类的实例,(确保不会发生对象切割)那么就可以使用
dynamic_cast。 - 随意地使用 RTTI 会使代码难以维护。它使得基于类型的判断树或者
switch语句散布在代码各处,不方便后续修改。基于类型的判断树:
if (typeid(*data) == typeid(D1)) {
...
} else if (typeid(*data) == typeid(D2)) {
...
} else if (typeid(*data) == typeid(D3)) {
...
}
一旦在类层级中加入新的子类,像这样的代码往往会崩溃。而且,一旦某个子类的属性改变了,很难找到并修改所有受影响的代码块。
6.6. 类型转换
不要使用 C 风格类型转换,而应该使用 C++ 风格。详见。
6.7. 流
- 流用来替代
printf()和scanf()。 - 不要使用流,除非是日志接口需要,使用
printf + read/write代替。
6.8. 前置自增和自减
- 前置(
++i)通常要比后置(i++)效率更高。因为后置自增/自减会对表达式的值i进行一次拷贝。如果i是迭代器或其他非数值类型,拷贝的代价是比较大的。 - 对简单数值(非对象),两种都无所谓。对迭代器和模板类型,使用前置(
++i)自增 / 自减。
6.9. const 和 constexpr
在有需要的情况下都要使用 const,有时改用 C++11 推出的 constexpr 更好。
注意初始化 const 对象时,必须在初始化的同时值初始化。
const 用法
- 为类中的函数加上
const限定符表明该函数不会修改类成员变量的状态:
class Foo {
int Bar(char c) const;
};
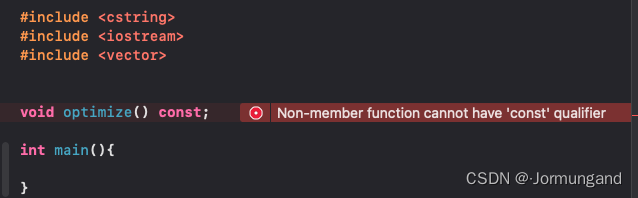
- 非成员函数不能有
const限定符。
const 使用场景
- 如果函数不会修改你传入的引用或指针类型参数,该参数应声明为 const。
- 用来访问成员的函数应该总是 const。
- 不会修改任何数据成员、函数体内未调用非 const 函数、只会返回数据成员 const 指针或引用的函数应该声明成 const。
- 如果数据成员在对象构造之后不再发生变化,可将其定义为 const。
- 注意修饰指针、引用变量时const有顶层和底层之分。
- 关键字 mutable 可以使用,但是在多线程中是不安全的,使用时首先要考虑线程安全。
constexpr
6.10. 整型
<stdint.h>定义了int16_t、uint32_t、int64_t等整型,在需要确保整型大小时可以使用它们代替short、unsigned long long等。在合适的情况下,推荐使用标准类型如size_t和ptrdiff_t。- 不要使用
uint32_t等无符号整型,除非是在表示一个位组而不是一个数值,或是需要定义二进制补码溢出。尤其是不要为了指出数值永不为负而使用无符号类型,而应使用断言。 - 如果代码涉及容器返回的大小(
size),确保接收变量的类型足以应付容器各种可能的用法。拿不准时,类型越大越好。 - 小心整型类型转换和整型提升(
integer promotions),比如int与unsigned int运算时,前者被提升为unsigned int可能导致溢出。
6.11. 预处理宏
尽量以内联函数,枚举和常量代替宏。
这样代替宏
- 以往用宏展开性能关键的代码,现在可以用内联函数替代。
- 用宏表示常量可被
const变量代替。 - 用宏 “缩写” 长变量名可被引用代替。
- 用宏进行条件编译……这个,千万别这么做,会令测试更加痛苦 (
#define防止头文件重包含当然是个特例)。
如果无法避免使用宏
- 宏可以做一些其他技术无法实现的事情,在一些代码库 (尤其是底层库中) 可以看到用
#字符串化,用##连接等等。
如果非要用宏,请遵守:
- 不要在
.h文件中定义宏; - 在马上要使用时才进行
#define,使用后要立即#undef; - 不要只是对已经存在的宏使用
#undef,也可以选择一个不会冲突的名称; - 不要试图使用展开后会导致 C++ 构造不稳定的宏,非要使用也至少要附上文档说明其行为;
- 不要用
##处理函数,类和变量的名字。
6.12. 0、nullptr 和 NULL
整数用 0,实数用 0.0,字符 (串) 用 '\0'。
对于指针(地址值),到底是用 0、NULL 还是 nullptr?
- C++11 项目用
nullptr; - C++03 项目则用
NULL,毕竟它看起来像指针。实际上,一些 C++ 编译器对NULL的定义比较特殊,可以用来输出警告,比如sizeof(NULL)就和sizeof(0)不一样。
6.13. sizeof
尽可能用 sizeof(varname) 代替 sizeof(type):
Struct data;
// 如果要使用 sizeof
memset(&data, 0, sizeof(data)); // 这样做
memset(&data, 0, sizeof(Struct)); // 而不是
- 使用
sizeof(varname)是因为当代码中变量类型改变时会自动更新。 - 可以用
sizeof(type)处理不涉及任何变量的代码,比如处理来自外部或内部的数据格式,这时用变量名就不合适了。
if (raw_size < sizeof(int)) {
LOG(ERROR) << "compressed record not big enough for count: " << raw_size;
return false;
}
6.14. auto
只要可读性好就可以用 auto 绕过繁琐的类型名,但别用在局部变量之外的地方。
缺点
- 区分
auto和const auto&的不同之处,否则会复制错东西。 - 对一般不可见的代理类型(
normally-invisible proxy types)使用auto会有意想不到的陷阱。比如auto和 C++11 列表初始化的合体:
auto x(3); // 圆括号。
auto y{
3}; // 大括号。
- 最终结果:
x的类型是int,y的类型则是std::initializer_list<int>。 - 代理人类型详见:Why is vector not a STL container?
总结
auto还可以和 C++11 特性「尾置返回类型」一起用,不过后者只能用在lambda表达式里。
6.15. 列表初始化
详见 列表初始化。
6.16. Lambda 表达式
适当使用 lambda 表达式。禁用默认 lambda 捕获,所有捕获都要显式写出来。
[=](int x) {
return x + n;} // 差,可读性不高
[n](int x) {
return x + n;} // 好,读者一眼看出 n 是被捕获的值。
C++11 首次提出Lambdas,还提供了一系列处理函数对象的工具,比如多态包装器 std::function。Lambda 表达式是创建匿名函数对象的一种简易途径,常用于把函数当参数传,例如:
std::sort(v.begin(), v.end(), [](int x, int y) {
return Weight(x) < Weight(y);
});
优点
- 传函数对象给 STL 算法,
Lambdas最简易,可读性也好。 Lambdas、std::functions和std::bind可以搭配成通用回调机制;写接收有界函数为参数的函数也很容易了。
缺点
- Lambdas 的变量捕获略旁门左道,可能会造成悬空指针。
- Lambdas 可能会失控;层层嵌套的匿名函数难以阅读。
结论
- 匿名函数始终要简短,如果函数体超过了五行,那么还不如起名(即把 lambda 表达式赋值给对象),或改用函数。
- 如果可读性更好,就显式写出
lambda的尾置返回类型,就像auto。
6.17. 模板编程
因为模板的维护成本较高,因此最好只用在少量的基础组件、基础数据结构上,这样模版的使用率高,维护模版就是值得的。(如果一个东西用得少,成本还高你会买吗?)
如果无法避免使用模版编程
- 如果不得不使用模板编程,必须把复杂度最小化,并且尽量不要让模板对外暴露。最好只在实现里面使用模板,然后给用户暴露的接口里面并不使用模板,以提高接口的可读性。
- 在使用模板的代码上写尽可能详细的注释,注释应该包含这些代码是怎么用的,这些模板生成出来的代码大概是什么样子的。
- 在用户错误使用你的模板代码的时候需要输出更人性化的出错信息,因为这些出错信息也是接口的一部分,所以必须做到错误信息是易于理解且修改的。
6.18. C++11
C++11 以下特性能不用就不要用:
- 编译时合数
<ratio>,因为它涉及一个重模板的接口风格。 <cfenv>和<fenv.h>头文件,因为编译器尚不支持。- 尾置返回类型,比如用
auto foo() -> int代替int foo()。 - Should the trailing return type syntax style become the default for new C++11 programs? 讨论了
auto与尾置返回类型一起用的全新编码风格,值得一看。
7. 命名约定
这些约定是Google开发团队遵守的,如果和你的开发团队的规则相冲突,请遵循你的团队的规则。
7.1. 少用缩写
好的做法:
int price_count_reader; // 无缩写
int num_errors; // "num" 是一个常见的写法
int num_dns_connections; // 人人都知道 "DNS" 是什么
此外,一些特定的广为人知的缩写是允许的,例如用
i表示迭代变量和用T表示模板参数。
坏的做法:
int n; // 毫无意义.
int nerr; // 含糊不清的缩写.
int n_comp_conns; // 含糊不清的缩写.
int wgc_connections; // 只有贵团队知道是什么意思.
int pc_reader; // "pc" 有太多可能的解释了.
int cstmr_id; // 删减了若干字母.
7.2. 文件命名
- 文件名要全部小写,可以包含下划线 (_) 或连字符 (-)。好的做法:
my_useful_class.cc/my-useful-class.cc/ myusefulclass.ccmyusefulclass_test.cc已弃用。(部分词语以符号隔开,部分不隔开,不统一)_unittest和_regtest已弃用。(不以符号开头)
- C++ 文件要以
.cc结尾,头文件以.h结尾,专门插入文本的文件则以.inc结尾。 - 不要使用已经存在于
/usr/include下的文件名(即编译器搜索系统头文件的路径)。 - 通常应尽量让文件名更加明确。
http_server_logs.h就比logs.h要好。定义类时文件名一般成对出现,如foo_bar.h和foo_bar.cc。
7.3. 类型命名
类、结构体、类型定义 (typedef)、枚举、类型模板参数名称 的每个单词首字母均大写,不包含下划线:
// 类和结构体
class UrlTable {
...
class UrlTableTester {
...
struct UrlTableProperties {
...
// 类型定义
typedef hash_map<UrlTableProperties *, string> PropertiesMap;
// using 别名
using PropertiesMap = hash_map<UrlTableProperties *, string>;
// 枚举
enum UrlTableErrors {
...
7.4. 变量命名
普通变量命名 / 结构体变量
变量(包括函数参数)和数据成员名一律小写,单词之间用下划线连接。
string table_name; // 好 - 用下划线.
string tablename; // 好 - 全小写.
string tableName; // 差 - 混合大小写
// 结构体
struct UrlTableProperties {
string name;
int num_entries;
static Pool<UrlTableProperties>* pool;
};
类数据成员
类的成员变量以下划线结尾。
class TableInfo {
...
private:
string table_name_; // 好 - 后加下划线.
string tablename_; // 好.
static Pool<TableInfo>* pool_; // 好.
};
7.5. 常量命名
声明为 constexpr 或 const 的变量,或在程序运行期间其值始终保持不变的,命名时以 k 开头,大小写混合。例如:
const int kDaysInAWeek = 7;
- 所有具有静态存储类型的变量(参见 存储类型)都应当以此方式命名。
- 对于非静态的存储类型的变量,如自动变量等,如果不采用这条规则,就按照一般的变量命名规则。
7.6. 函数命名
- 常规函数使用大小写混合,取值和设值函数则要求与变量名匹配。
MyExcitingFunction();
my_exciting_member_variable();
set_my_exciting_member_variable();
- 函数名的每个单词首字母大写(即 “驼峰变量名” 或 “帕斯卡变量名”),没有下划线。对于首字母缩写的单词,更倾向于将它们视作一个单词进行首字母大写。
StartRpc(); // 好的
StartRPC(); // 不好
- 命名规则同样适用于类作用域与命名空间作用域的常量,因为它们是作为 API 的一部分暴露对外的,因此应当让它们看起来像是一个函数。
7.7. 命名空间命名
- 命名空间以小写字母命名。
- 顶级命名空间的名称应当是项目名或者是该命名空间中的代码所属的团队的名字。命名空间中的代码应当存放于和命名空间的名字匹配的文件夹或其子文件夹中。
- 要避免嵌套的命名空间与常见的顶级命名空间发生名称冲突,尤其是不要创建嵌套的
std命名空间。由于名称查找规则的存在,命名空间之间的冲突完全有可能导致编译失败。 - 要当心加入到同一
internal命名空间的代码之间发生冲突。 在这种情况下,请使用文件名使内部名称独一无二(例如frobber.h,使用websearch::index::frobber_internal)。
7.8. 宏命名
通常 不应该 使用宏,如果不得不用,其命名要像枚举命名一样全部大写,使用下划线:
#define ROUND(x) ...
#define PI_ROUNDED 3.0
7.9. 枚举命名
- 单独的枚举值应该优先采用 常量 的命名方式(如
kEnumName),但 宏 方式的命名也可以接受。 - 枚举名
UrlTableErrors/ AlternateUrlTableErrors是类型,所以要用大小写混合的方式:
enum UrlTableErrors {
kOK = 0,
kErrorOutOfMemory,
kErrorMalformedInput,
...
};
enum AlternateUrlTableErrors {
OK = 0,
OUT_OF_MEMORY = 1,
MALFORMED_INPUT = 2,
...
};
8. 注释
8.1. 文件注释
- 每个文件都应该包含许可证引用。为项目选择合适的许可证版本。
- 如果你对原始作者的文件做了重大修改,请考虑删除原作者信息。
8.2. 类注释
- 类注释应当提供如何使用与何时使用的说明,以及使用的注意事项。
- 如果类有同步前提,请用文档说明。
- 如果该类的实例可被多线程访问,要说明多线程环境下相关的规则和常量使用。
- 如果想用一小段代码演示这个类的基本用法,放在类注释里也非常合适。
- 如果类的声明和定义分开了(例如分别放在了
.h和.cc文件中),此时,描述类用法的注释应当和接口定义放在一起,描述类的操作的注释应当和实现放在一起。
// Iterates over the contents of a GargantuanTable.
// Example:
// GargantuanTableIterator* iter = table->NewIterator();
// for (iter->Seek("foo"); !iter->done(); iter->Next()) {
// process(iter->key(), iter->value());
// }
// delete iter;
class GargantuanTableIterator {
...
};
8.3. 函数注释
- 基本上每个函数声明处前都应当加上注释,描述函数的功能和用途。只有在函数的功能简单而明显时才能省略这些注释。详细来讲应该包含:
- 函数的输入输出。
- 对类成员函数而言:函数调用期间对象是否需要保持引用参数,是否会释放这些参数。
- 函数是否分配了必须由调用者释放的空间。
- 参数是否可以为空指针。
- 是否存在函数使用上的性能隐患。
- 函数定义部分注释描述函数如何工作。
- 解释编程技巧的步骤或实现理由,如:为什么函数的前半部分要加锁而后半部分不需要。
- 注释函数重载时,注释的重点应该是函数中被重载的部分,而不是简单的重复被重载的函数的注释。多数情况下,函数重载不需要额外注释。
- 注释构造/析构函数时,“销毁这一对象” 这样的注释是没有意义的,应当注明构造函数对参数做了什么(例如,是否取得指针所有权)以及析构函数清理了什么。如果都是些无关紧要的内容,直接省掉注释。
8.4. 变量注释
类数据成员
- 每个成员变量都应该用注释说明用途。如果变量类型与变量名已经足以描述一个变量,那么就不再需要加上注释。
- 特别地,如果变量可以接受
NULL或-1等警戒值,须加以说明。比如:
private:
// Used to bounds-check table accesses. -1 means
// that we don't yet know how many entries the table has.
int num_total_entries_;
全局变量
- 所有全局变量也要注释说明含义及用途,以及作为全局变量的原因。
// The total number of tests cases that we run through in this regression test.
const int kNumTestCases = 6;
8.5. 实现注释
对于代码中巧妙的、晦涩的、有趣的、重要的地方加以注释。
代码前注释
// Divide result by two, taking into account that x
// contains the carry from the add.
for (int i = 0; i < result->size(); i++) {
x = (x << 8) + (*result)[i];
(*result)[i] = x >> 1;
x &= 1;
}
行注释
// If we have enough memory, mmap the data portion too.
mmap_budget = max<int64>(0, mmap_budget - index_->length());
if (mmap_budget >= data_size_ && !MmapData(mmap_chunk_bytes, mlock))
return; // Error already logged.
如果你需要连续进行多行注释,可以使之对齐获得更好的可读性:
DoSomething(); // Comment here so the comments line up.
DoSomethingElseThatIsLonger(); // Two spaces between the code and the comment.
{
// One space before comment when opening a new scope is allowed,
// thus the comment lines up with the following comments and code.
DoSomethingElse(); // Two spaces before line comments normally.
}
std::vector<string> list{
// Comments in braced lists describe the next element...
"First item",
// .. and should be aligned appropriately.
"Second item"};
DoSomething(); /* For trailing block comments, one space is fine. */
函数参数注释
万不得已时,才考虑在调用点用注释阐明参数的意义。
// 参数意义不明,单独加注释并不是一个好的解决方案
const DecimalNumber product = CalculateProduct(values, 7, false, nullptr);
不如:
// 用变量options接收上面第二、第三个参数
// 并用变量名解释他们的含义,这比为两者添加注释要好
ProductOptions options;
options.set_precision_decimals(7);
options.set_use_cache(ProductOptions::kDontUseCache);
const DecimalNumber product =
CalculateProduct(values, options, /*completion_callback=*/nullptr);
不允许的行为
- 不要描述显而易见的现象,要假设读代码的人 C++ 水平比你高。比如:
// Find the element in the vector. <-- 差: 这太明显了!
// 或者下面这样的注释
// Process "element" unless it was already processed.
auto iter = std::find(v.begin(), v.end(), element);
if (iter != v.end()) {
Process(element);
}
- 最好是让代码自文档化,即代码本身不需要注释来额外说明。比如:
if (!IsAlreadyProcessed(element)) {
Process(element);
}
8.6. TODO 注释
- 对那些临时的解决方案,或已经写好但仍不完美的代码使用
TODO注释。 TODO注释使用全大写的字符串,在随后的圆括号里写上身份标识和与TODO相关的issue。
// TODO([email protected]): Use a "*" here for concatenation operator.
// TODO(Zeke) change this to use relations.
// TODO(bug 12345): remove the "Last visitors" feature
- 如果加
TODO是为了在 “将来某一天做某事”,可以附上一个非常明确的时间,或者一个明确的事项。
// TODO(bug 12345): Fix by November 2022
// TODO([email protected]): Remove this code when all clients can handle XML responses.
8.7. 弃用注释
- 通过弃用注释(
DEPRECATED:comments)以标记某接口点已弃用。注释可以放在接口声明前,或者同一行。 - 同样的在随后的圆括号里写上身份标识。
- 在 C++ 中,你可以将一个弃用函数改造成一个内联函数,这一函数将调用新的接口。
9. 格式
通用规则
- 书写格式为可读性服务。
- 左圆括号和左大括号不要新起一行。
- 右圆括号和左大括号间总是有一个空格。
9.1. 非 ASCII 字符 / 空格
- 尽量不使用非
ASCII字符,使用时必须使用UTF-8编码。尽量不将字符串常量耦合到代码中,比如独立出资源文件,这不仅仅是风格问题了; UNIX/Linux下无条件使用空格,MSVC的话使用Tab也无可厚非;
9.2. 函数格式与 Lambda 表达式
函数参数格式
- 要么一行写完函数调用:
bool retval = DoSomething(argument1, argument2, argument3);
- 要么在圆括号里对参数分行,后面每一行都和第一个实参对齐,左圆括号后和右圆括号前不要留空格:
bool retval = DoSomething(averyveryveryverylongargument1,
argument2, argument3);
- 要么参数另起一行且缩进四格.:
if (...) {
DoSomething( // 两格缩进
argument1, argument2, // 4 空格缩进
argument3, argument4);
}
// 或者
ReturnType LongClassName::ReallyReallyReallyLongFunctionName(
Type par_name1, // 4 space indent
Type par_name2,
Type par_name3) {
DoSomething(); // 2 space indent
...
}
- 如果参数是复杂的表达式,那么可以创建临时变量描述该表达式,并传递给函数:
int my_heuristic = scores[x] * y + bases[x];
bool retval = DoSomething(my_heuristic, x, y, z);
- 或者放着不管,补充上注释:
bool retval = DoSomething(scores[x] * y + bases[x], // Score heuristic.
x, y, z);
- 如果一系列参数本身就有一定的结构,可以酌情地按其结构来决定参数格式:
// 通过 3x3 矩阵转换 widget.
my_widget.Transform(x1, x2, x3,
y1, y2, y3,
z1, z2, z3);
函数体格式
// 对于单行函数的实现,在大括号内加上空格,然后是函数实现
void Foo() {
} // 大括号里面是空的话, 不加空格.
void Reset() {
baz_ = 0; } // 用空格把大括号与实现分开.
void 函数里要不要用 return 语句
从 本讨论 来看return;比return ;更约定俗成(事实上cpplint会对后者报错,指出分号前有多余的空格),且可用来提前跳出函数栈。
Lambda 表达式
- 若用引用捕获,在变量名和
&之间不留空格:
int x = 0;
auto add_to_x = [&x](int n) {
x += n; };
- 短
lambda就写得和内联函数一样:
std::set<int> blacklist = {
7, 8, 9};
std::vector<int> digits = {
3, 9, 1, 8, 4, 7, 1};
digits.erase(std::remove_if(digits.begin(), digits.end(), [&blacklist](int i) {
return blacklist.find(i) != blacklist.end();
}),
digits.end());
9.3. 列表初始化格式
下面的示例应该可以涵盖大部分情景:
// 一行列表初始化示范.
return {
foo, bar};
functioncall({
foo, bar});
pair<int, int> p{
foo, bar};
// 当不得不断行时.
SomeFunction(
{
"assume a zero-length name before {"}, // 假设在 { 前有没有其他参数
some_other_function_parameter);
SomeType variable{
some, other, values,
{
"assume a zero-length name before {"}, // 假设在 { 前有其他参数
SomeOtherType{
"Very long string requiring the surrounding breaks.",
// 非常长的字符串, 前后都需要断行.
some, other values},
SomeOtherType{
"Slightly shorter string", // 稍短的字符串.
some, other, values}};
SomeType variable{
"This is too long to fit all in one line"}; // 字符串过长, 因此无法放在同一行.
MyType m = {
// 注意了, 您可以在 { 前断行.
superlongvariablename1,
superlongvariablename2,
{
short, interior, list},
{
interiorwrappinglist,
interiorwrappinglist2}};
9.4. 构造函数初始值列表
// 如果初始值列表能放在同一行:
MyClass::MyClass(int var) : some_var_(var) {
DoSomething();
}
// 如果不能放在同一行,
// 必须置于冒号后, 并缩进 4 个空格
MyClass::MyClass(int var)
: some_var_(var), some_other_var_(var + 1) {
DoSomething();
}
// 如果初始化列表需要置于多行, 将每一个成员放在单独的一行
// 并逐行对齐
MyClass::MyClass(int var)
: some_var_(var), // 4 space indent
some_other_var_(var + 1) {
// lined up
DoSomething();
}
// 右大括号 } 可以和左大括号 { 放在同一行
// 如果这样做合适的话
MyClass::MyClass(int var)
: some_var_(var) {
}
9.5. 条件语句 和 布尔表达式
if 判断句的空格要求
if(condition) // 差 - IF 后面没空格.
if (condition){
// 差 - { 前面没空格.
if(condition){
// 变本加厉地差.
if (condition) {
// 好 - IF 和 { 都与空格紧邻.
执行语句只有一句
只有当语句简单并且没有使用 else 子句时允许将简短的条件语句写在同一行来增强可读性:
if (x == kFoo) return new Foo();
if (x == kBar) return new Bar();
如果语句有 else 分支则不允许:
// 不允许 - 当有 ELSE 分支时 IF 块却写在同一行
if (x) DoThis();
else DoThat();
{} - 大括号的使用
Apple 因为没有正确使用大括号栽过跟头 ,因此除非 条件语句能写在一行,否则一定要有大括号。
布尔表达式
逻辑操作符总位于行尾:
if (this_one_thing > this_other_thing &&
a_third_thing == a_fourth_thing &&
yet_another && last_one) {
...
}
9.6. 循环语句 和 switch 选择语句
循环语句
空循环体应使用 {} 或 continue,而不是一个简单的分号:
while (condition) {
// 反复循环直到条件失效.
}
for (int i = 0; i < kSomeNumber; ++i) {
} // 可 - 空循环体.
while (condition) continue; // 可 - contunue 表明没有逻辑.
while (condition); // 差 - 看起来仅仅只是 while/loop 的部分之一.
switch 选择语句
如果有不满足 case 条件的枚举值,switch 应该总是包含一个 default 匹配(如果有输入值没有case去处理,编译器将给出warning)。如果default永远执行不到,简单的加条 assert:
switch (var) {
case 0: {
// 2 空格缩进
... // 4 空格缩进
break;
}
case 1: {
...
break;
}
default: {
assert(false);
}
}
9.7. 指针/引用表达式 和 函数返回值
指针/引用表达式
int x, *y; // 不允许 - 在多重声明中不能使用 & 或 *
char * c; // 差 - * 两边都有空格
const string & str; // 差 - & 两边都有空格.
函数返回值
return result; // 返回值很简单, 没有圆括号.
// 可以用圆括号把复杂表达式圈起来, 改善可读性.
return (some_long_condition &&
another_condition);
9.8. 变量及数组初始化
- 用
=、()和{}均可:
int x = 3;
int x(3);
int x{
3};
string name("Some Name");
string name = "Some Name";
string name{
"Some Name"};
- 小心列表初始化
{...}用std::initializer_list 构造函数初始化出的类型:
vector<int> v(100, 1); // 内容为 100 个 1 的向量.
vector<int> v{
100, 1}; // 内容为 100 和 1 的向量.
- 列表初始化不允许整型类型的四舍五入,这可以用来避免一些类型上的编程失误:
int pi(3.14); // 好 - pi == 3.
int pi{
3.14}; // 编译错误: 缩窄转换.
9.9. 预处理指令
即使位于缩进代码块中,预处理指令也应从行首开始:
// 差 - 指令缩进
if (lopsided_score) {
#if DISASTER_PENDING // 差 - "#if" 应该放在行开头
DropEverything();
#endif // 差 - "#endif" 不要缩进
BackToNormal();
}
// 好 - 指令从行首开始
if (lopsided_score) {
#if DISASTER_PENDING // 正确 - 从行首开始
DropEverything();
# if NOTIFY // 非必要 - # 后跟空格
NotifyClient();
# endif
#endif
BackToNormal();
}