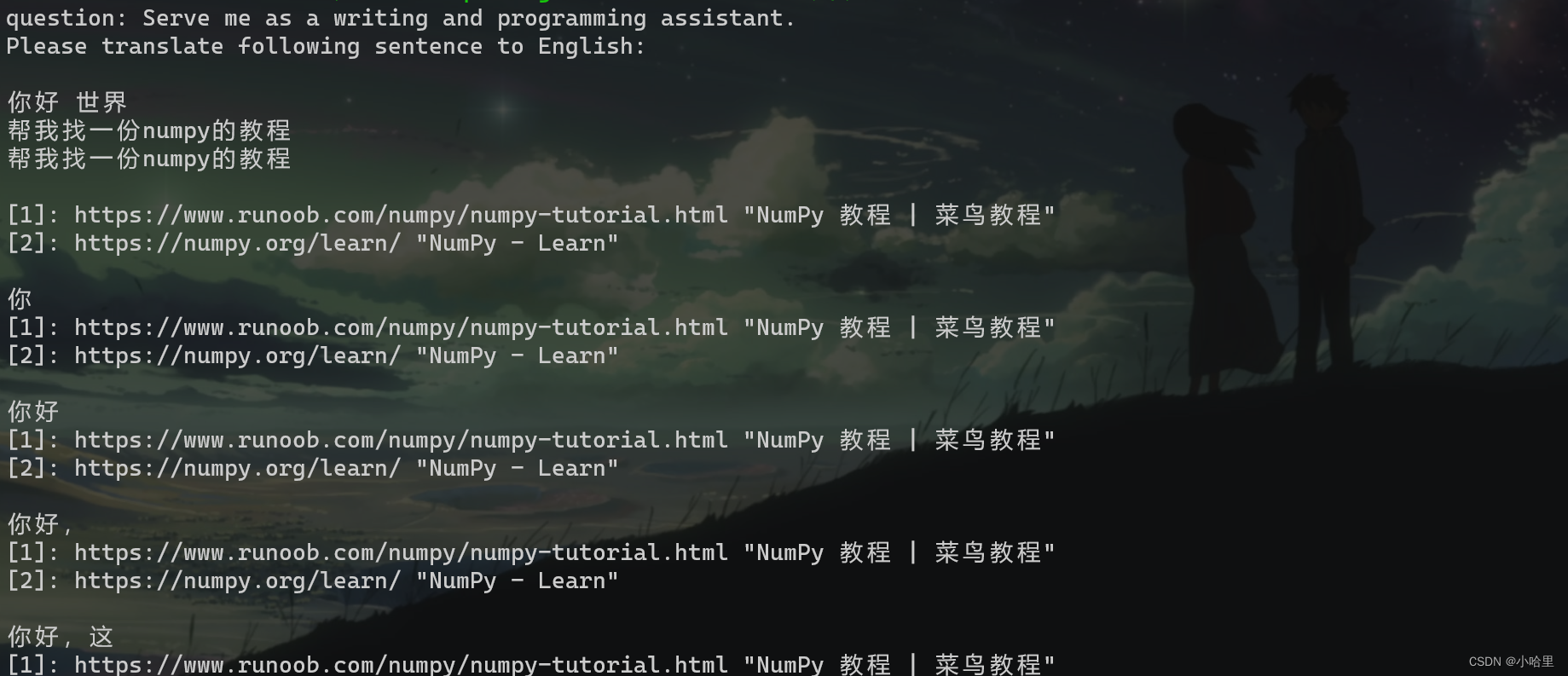
1、GPT Academic
项目地址:地址
安装部分
git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
conda create -n gptac_venv python=3.11
conda activate gptac_venv
python -m pip install -r requirements.txt
python -m pip install -r request_llm/requirements_chatglm.txt
python main.py

2、chatGPT
-
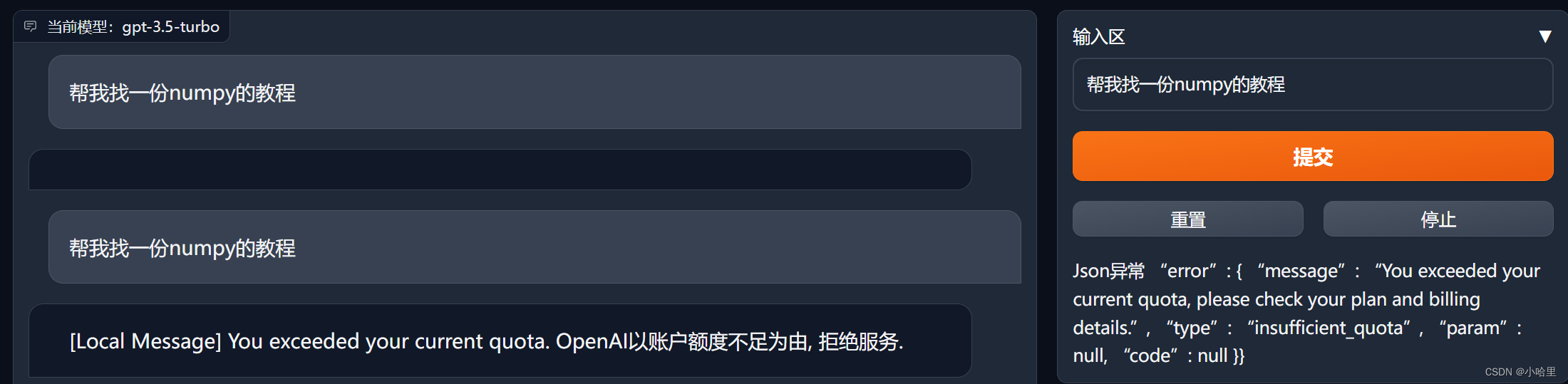
API_KEY的获取可以在openai账号里找到,注册也不必多说了
-
配置的话,改一下config中的几个地方就可以用了,注意http和https不要打错了。
具体报错可以参考官方的配置 -
看到额度没有了,其实就算是配置成功了(剩下的就只有氪金了)
3、chatGLM
-
我开始是拿cpu和内存跑的,配置跑不动,翻译一个helloworld需要五分钟(
-
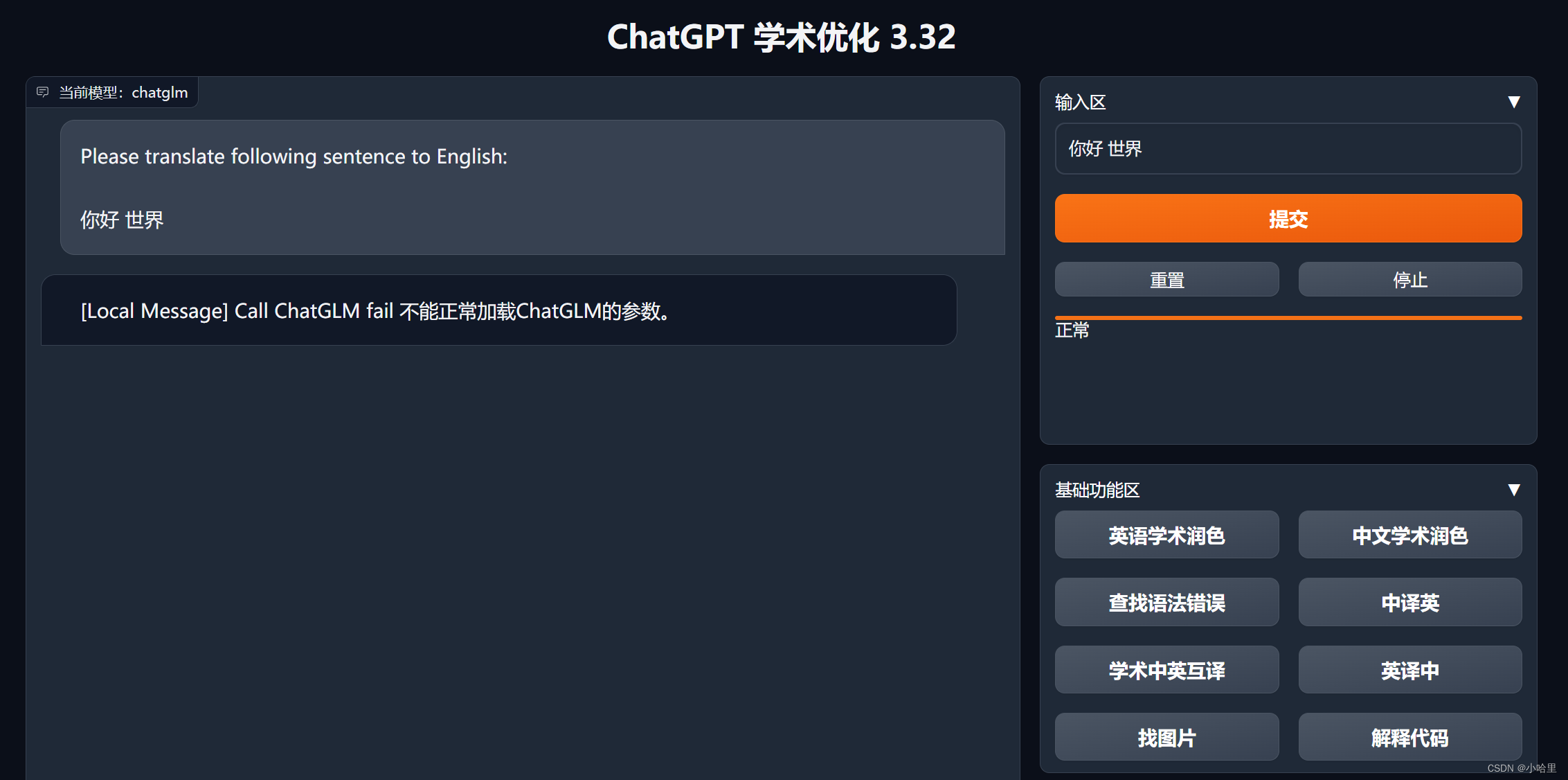
然后在config中改成使用cuda,出现了报错:
[Local Message] Call ChatGLM fail 不能正常加载ChatGLM的参数。
参考一下官方的帖子
 扫描二维码关注公众号,回复: 15053336 查看本文章
扫描二维码关注公众号,回复: 15053336 查看本文章
-
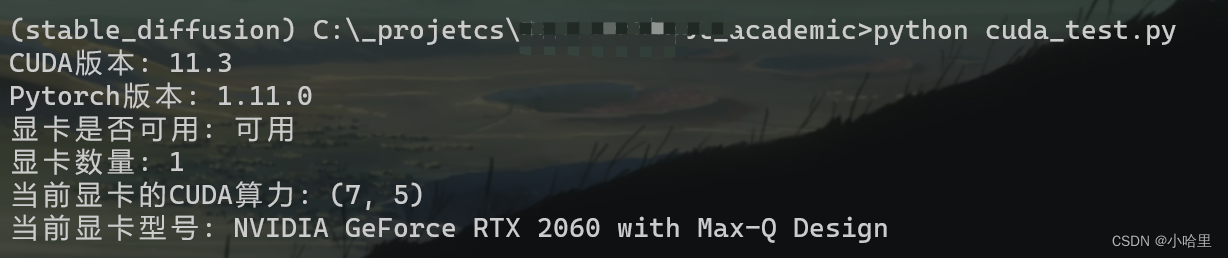
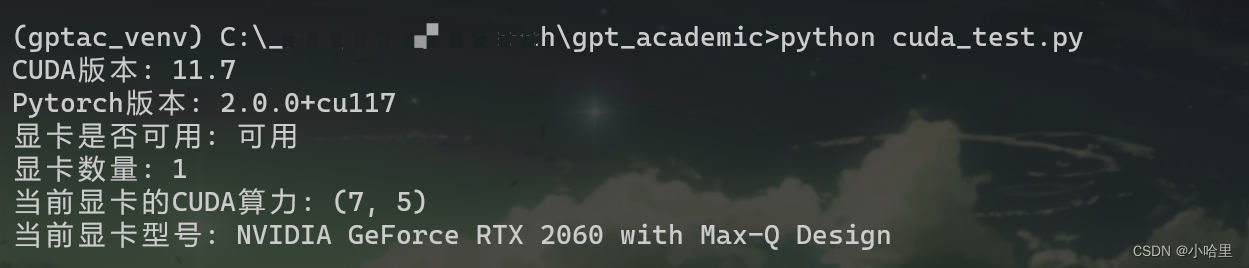
然后在终端中发现是cuda环境报错(找不到cuda设备),所以用以下代码进行修改
测试cuda环境能否使用。conda info --envs # 显示有哪些虚拟环境 conda activate gptac_venv python cuda_test.py# cuda_test.py import torch print('CUDA版本:',torch.version.cuda) print('Pytorch版本:',torch.__version__) print('显卡是否可用:','可用' if(torch.cuda.is_available()) else '不可用') print('显卡数量:',torch.cuda.device_count()) print('当前显卡的CUDA算力:',torch.cuda.get_device_capability(0)) print('当前显卡型号:',torch.cuda.get_device_name(0)) -
我当时就很奇怪,我其他虚拟conda环境下的cuda是可以用的,为什么gptac_venv这个环境就不行,也check了很多cuda版本相关的东西,环境变量,驱动支持,torch和torchvison和cuda版本对应之类的。
-
找了好久才发现原来是他默认安装的是cpu版的torch。 就是torch+cpu的形式。
所以卸载了torch重新安装就可以了
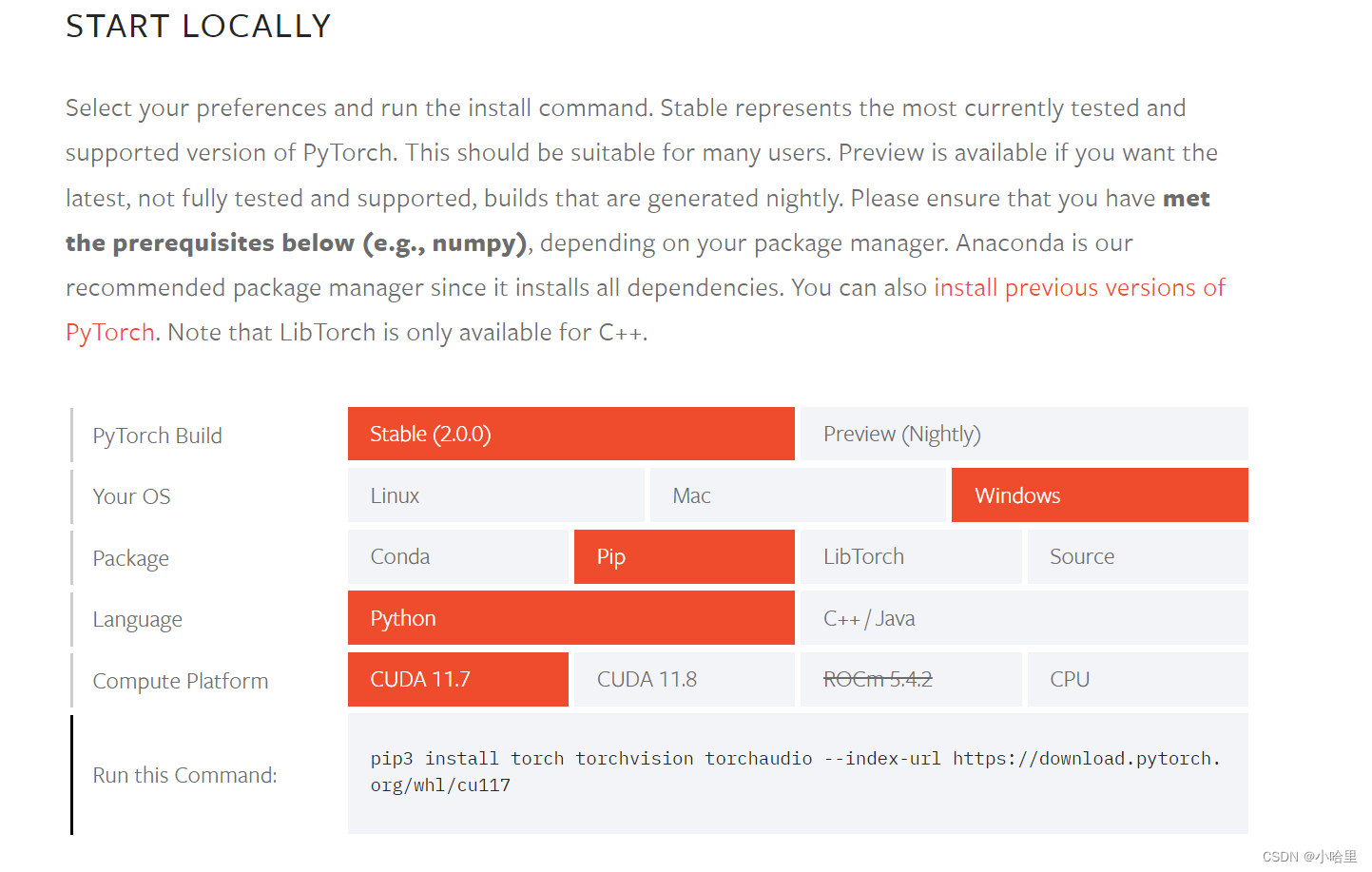
# https://pytorch.org/get-started/locally/ # 安装前记得先卸载 pip uninstall torch # 找对应自己的版本 pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 -
终于可以用上cuda了
-
结果又炸了, 来了个 “CUDA out of memory” in PyTorch
在加载内存的时候出现内存不够分配的情况,显然他采用的默认模型,6G显存是不够的

-
本来是只有该模型的操作了,可以参考
调小batch_size,设到4。
在报错处,也就是一个epoch跑完定时清内存.
把pin_memory锁页内存改成flase。 -
后来发现,来到chatGLM的官网
可以看到,模型的精度是可以调整的
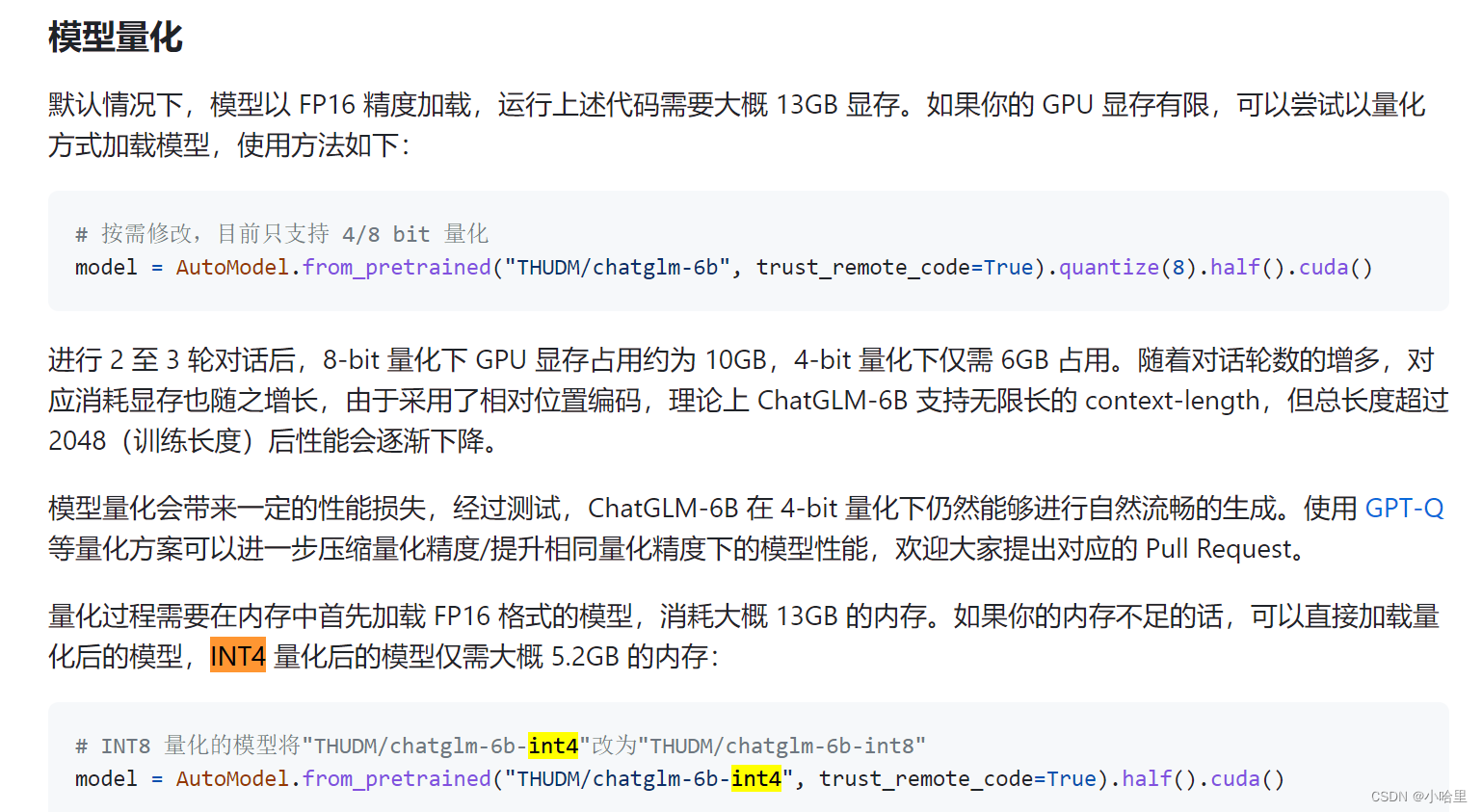
-
我们修改代码库中这段对应的代码
大概32行的位置,把几个模型的精度都修改一下
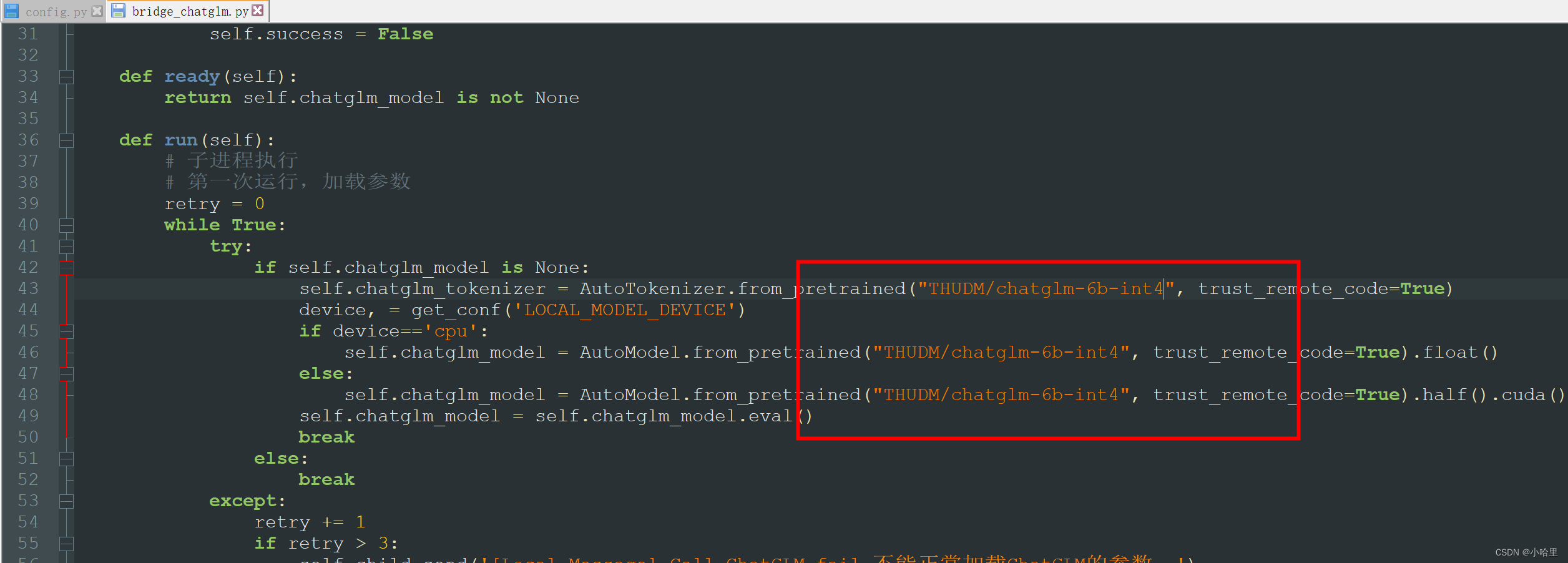
-
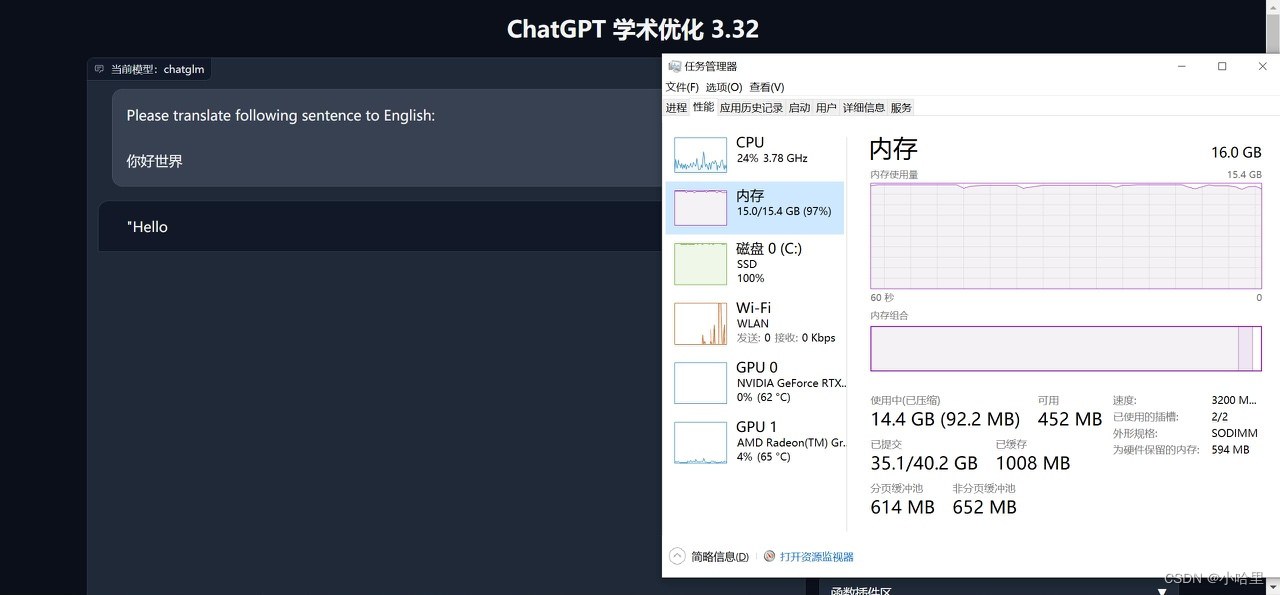
最后,可以看到此时的chatGLM已经成为了一个可用的状态,而且生成速度不比在线版的GPT要低(虽然效果可能比不上)。

-
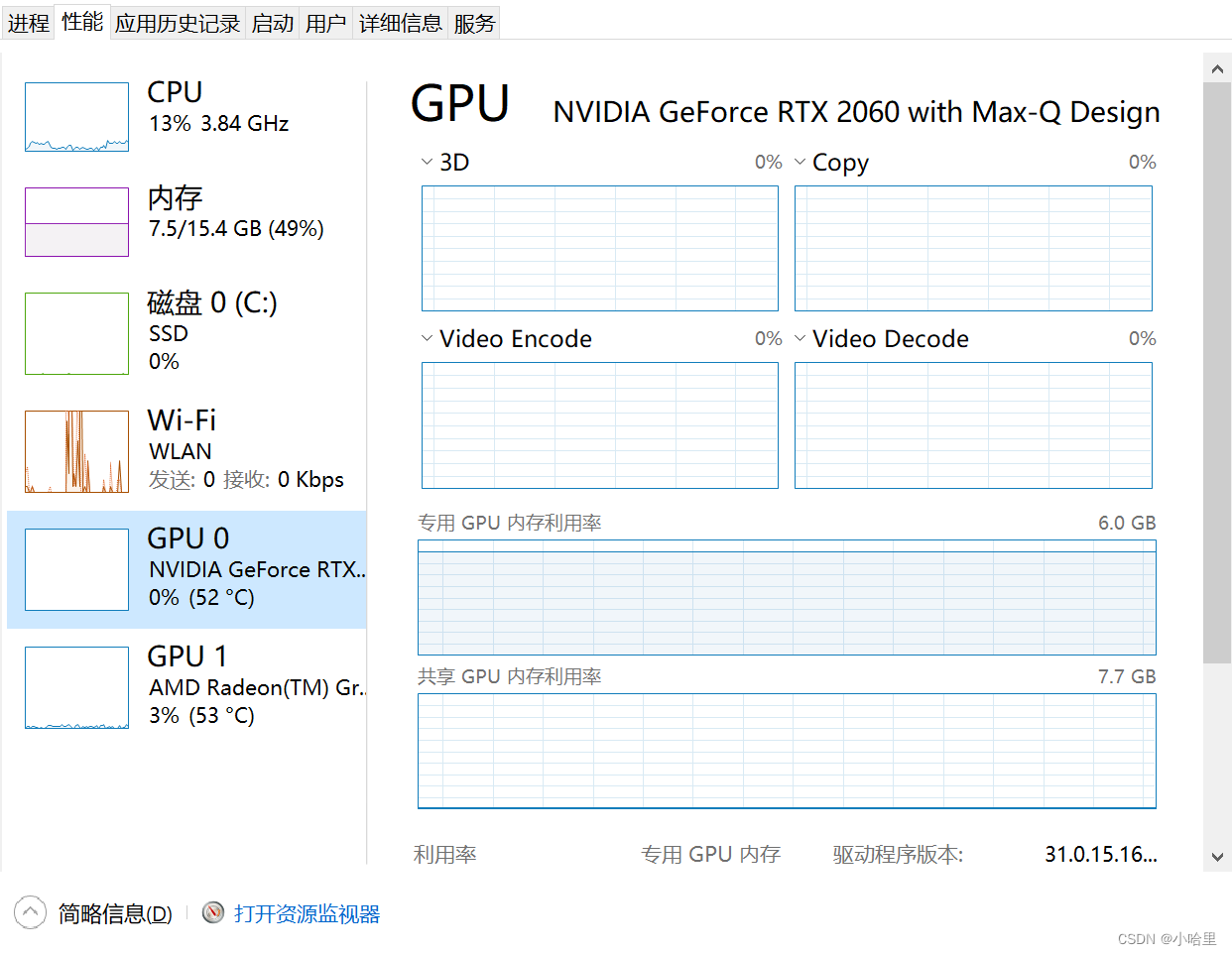
待机资源占用率,也就是刚刚好的6G显存+8G运存,一般不会跑满载。
4、newbing
-
如何使用newbing
早两个月是要申请list的,现在好像不用申请了,直接打开就能用?(我反正是这样的) -
1、安装最新的EdgeDEV

-
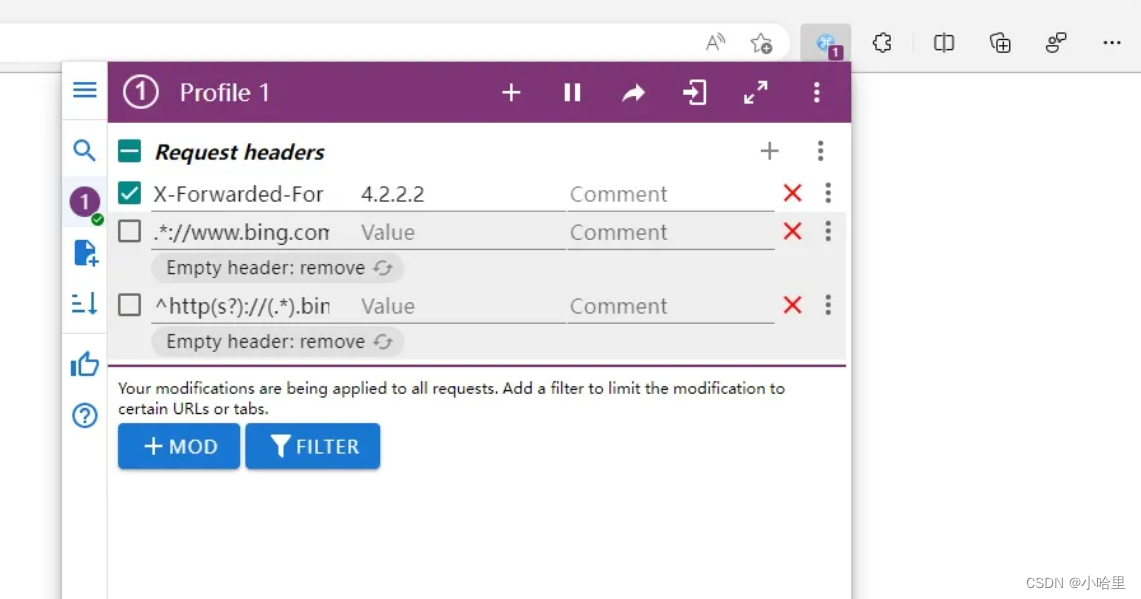
2、装插件Mod Header(不是必须的)
name:X-Forwarded-For,在value:4.2.2.2
添加request headers,name栏目填入:.*://http://www.bing.com/.*
添加equest headers,name栏目填入:^http(s?)://(.*).bing\.com/(.*)
-
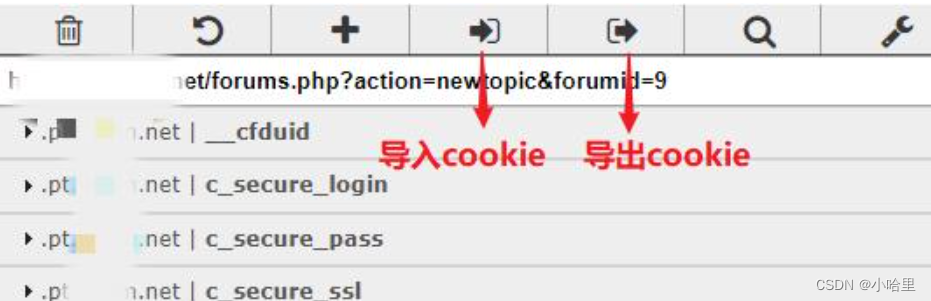
3、装Cookie Editor插件(必须的)
bing插件安装,直接应用商店就可以
成功进入newbing后导出cookie为json格式,放到config里面

-
config.py配置,仅供参考
-
最后效果
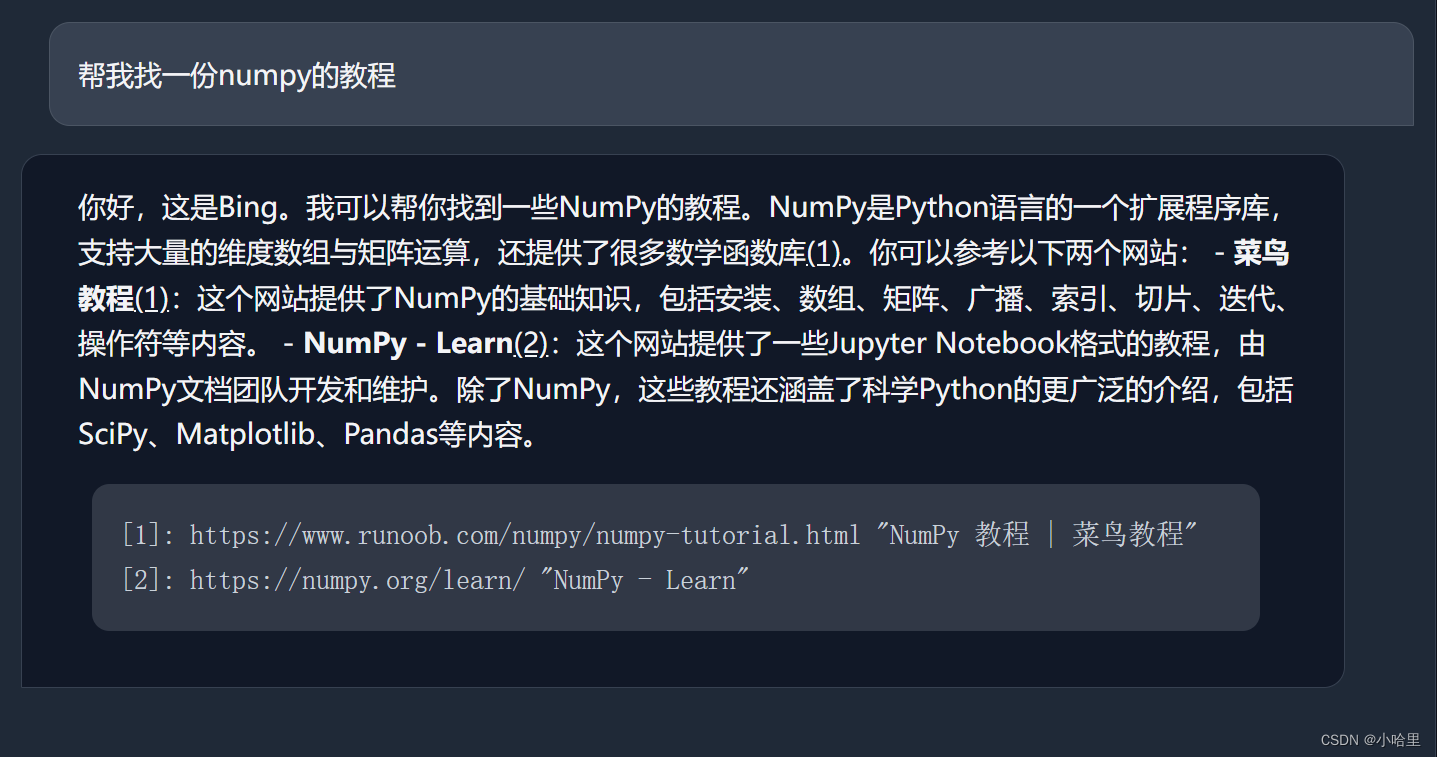
-
可以看到,终端里的响应还是比较慢的(问一个问题要等挺久,好像是拆分出来问了好多次),但是勉强还能用(主要是newbing自己本身的效果有点玄学)