【人工智能】— 不确定性
不确定性

不确定性与理性决策


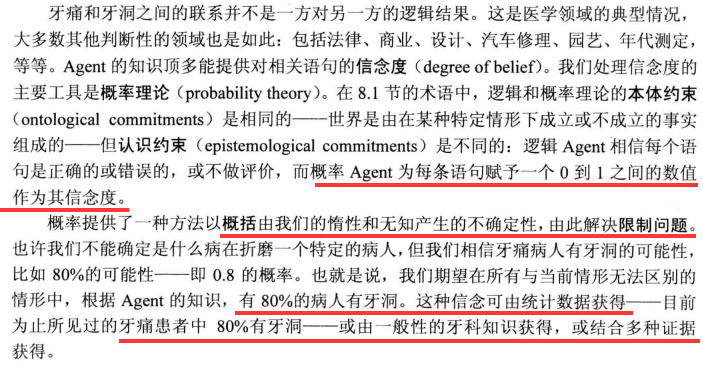
基本概率符号
先验概率(无条件概率)/后验概率(条件概率)



随机变量


概率密度

联合概率分布


公理

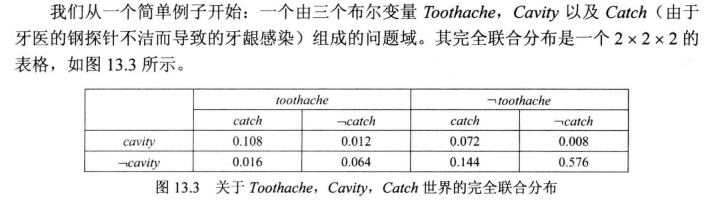
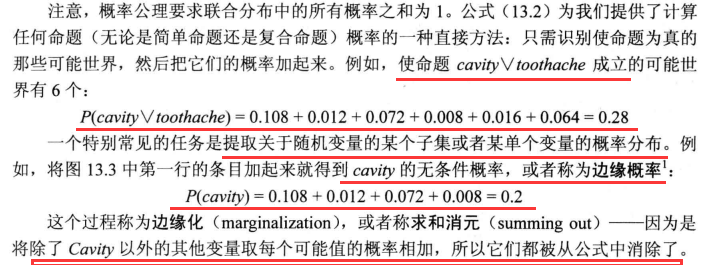
完全联合分布
概率演算

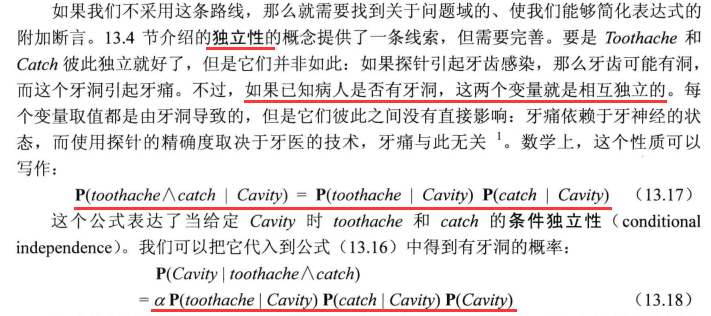
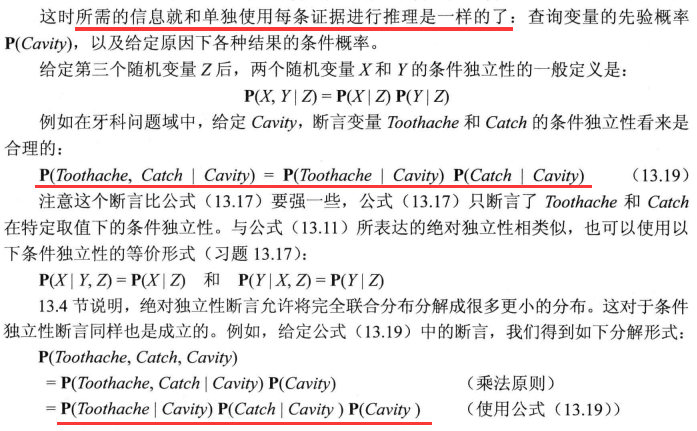
独立性
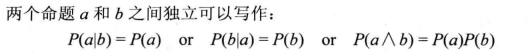

贝叶斯法则



例1
你有两个信封可供选择。一个信封里有一个红球(价值100美元)和一个黑球,另一个信封里有两个黑球(价值为零)。

你随机选择一个信封,然后从该信封中随机取出一个球,结果是黑色的。
此时,你可以选择是否换另一个信封。问题是,你应该换还是不换?
E: envelope, 1表示有一个红球的信封,2表示都是黑球的信封 1 = ( R , B ) , 2 = ( B , B ) 1=(R,B), 2=(B,B) 1=(R,B),2=(B,B)
B: the event of drawing a black ball 拿到一个黑棋的事件
贝叶斯法则: P ( E ∣ B ) = P ( B ∣ E ) P ( E ) P ( B ) 贝叶斯法则:\\{}\\P(E|B) = \frac{P(B|E)P(E)}{P(B)} 贝叶斯法则:P(E∣B)=P(B)P(B∣E)P(E)
We want to compare 比较: P ( E = 1 ∣ B ) 比较:P(E=1|B) 比较:P(E=1∣B) vs. P ( E = 2 ∣ B ) P(E=2|B) P(E=2∣B)
在红球信封拿到黑球: P ( B ∣ E = 1 ) = 0.5 在黑球信封拿到黑球: P ( B ∣ E = 2 ) = 1 在红球信封拿到黑球:P(B|E=1) = 0.5 \\在黑球信封拿到黑球:P(B|E=2) = 1 在红球信封拿到黑球:P(B∣E=1)=0.5在黑球信封拿到黑球:P(B∣E=2)=1
拿到 1 、 2 信封的概率相同: P ( E = 1 ) = P ( E = 2 ) = 0.5 拿到1、2信封的概率相同:P(E=1) = P(E=2) = 0.5 拿到1、2信封的概率相同:P(E=1)=P(E=2)=0.5
抽到黑球的概率: B 在 E 取值上的边缘概率 P ( B ) = P ( B ∣ E = 1 ) P ( E = 1 ) + P ( B ∣ E = 2 ) P ( E = 2 ) = ( 0.5 ) ( 0.5 ) + ( 1 ) ( 0.5 ) = 0.75 \begin{aligned} &抽到黑球的概率:\\&{B在E取值上的边缘概率}\\ P(B) &= P(B|E=1)P(E=1) + P(B|E=2)P(E=2) \\ &= (0.5)(0.5) + (1)(0.5) \\ &= 0.75 \\ \end{aligned} P(B)抽到黑球的概率:B在E取值上的边缘概率=P(B∣E=1)P(E=1)+P(B∣E=2)P(E=2)=(0.5)(0.5)+(1)(0.5)=0.75
已经抽到一个黑球,此信封是红球信封的概率: P ( E = 1 ∣ B ) = P ( B ∣ E = 1 ) P ( E = 1 ) P ( B ) = ( 0.5 ) ( 0.5 ) ( 0.75 ) = 1 3 已经抽到一个黑球,此信封是红球信封的概率:\\{} \\P(E=1|B) = \frac{P(B|E=1)P(E=1)}{P(B)} = \frac{(0.5)(0.5)}{(0.75)} = \frac{1}{3} 已经抽到一个黑球,此信封是红球信封的概率:P(E=1∣B)=P(B)P(B∣E=1)P(E=1)=(0.75)(0.5)(0.5)=31
已经抽到一个黑球,此信封是黑球信封的概率: P ( E = 2 ∣ B ) = P ( B ∣ E = 2 ) P ( E = 2 ) P ( B ) = ( 1 ) ( 0.5 ) ( 0.75 ) = 2 3 已经抽到一个黑球,此信封是黑球信封的概率:\\{} \\P(E=2|B) = \frac{P(B|E=2)P(E=2)}{P(B)} = \frac{(1)(0.5)}{(0.75)} = \frac{2}{3} 已经抽到一个黑球,此信封是黑球信封的概率:P(E=2∣B)=P(B)P(B∣E=2)P(E=2)=(0.75)(1)(0.5)=32
通过计算可得,抽到黑球后信封为 1 的概率为 1 / 3 , 信封为 2 的概率为 2 / 3 。因此,更换信封可以提高获得红球的概率。 通过计算可得,抽到黑球后信封为 1 的概率为 1/3,\\信封为 2 的概率为 2/3。因此,更换信封可以提高获得红球的概率。 通过计算可得,抽到黑球后信封为1的概率为1/3,信封为2的概率为2/3。因此,更换信封可以提高获得红球的概率。
例2
一位医生进行一项测试,该测试有99%的可靠性,即99%的生病者测试结果为阳性,99%的健康者测试结果为阴性。这位医生估计整个人口中有1%的人是生病的。
因此,对于测试结果为阳性的患者,他是生病的概率是多少呢?
我们可以使用贝叶斯定理来计算患者生病的条件概率。设事件 S 表示患者生病,事件 T 表示测试结果为阳性。则所求的条件概率为:
P ( S ∣ T ) = P ( T ∣ S ) P ( S ) P ( T ) P(S|T) = \frac{P(T|S)P(S)}{P(T)} P(S∣T)=P(T)P(T∣S)P(S)
其中, P ( T ∣ S ) P(T|S) P(T∣S) 表示患者生病的条件下,测试结果为阳性的概率, P ( S ) P(S) P(S) 表示患者生病的先验概率, P ( T ) P(T) P(T) 表示测试结果为阳性的概率。
根据题目中给出的数据,我们有: P ( T ∣ S ) = 0.99 根据题目中给出的数据,我们有:\\P(T|S) = 0.99 根据题目中给出的数据,我们有:P(T∣S)=0.99
P ( S ) = 0.01 P(S) = 0.01 P(S)=0.01
P ( T ) = P ( T ∣ S ) P ( S ) + P ( T ∣ S ‾ ) P ( S ‾ ) P(T) = P(T|S)P(S) + P(T|\overline{S})P(\overline{S}) P(T)=P(T∣S)P(S)+P(T∣S)P(S)
其中, S ‾ 表示患者不生病。 其中,\overline{S}表示患者不生病。 其中,S表示患者不生病。
根据测试的可靠性,我们可以得到 P ( T ∣ S ‾ ) = 1 − P ( T ∣ S ) = 0.01 因此 P ( T ) = P ( T ∣ S ) P ( S ) + P ( T ∣ S ‾ ) P ( S ‾ ) = ( 0.99 ) ( 0.01 ) + ( 0.01 ) ( 0.99 ) = 0.0198 根据测试的可靠性,我们可以得到 \\P(T|\overline{S}) = 1-P(T|S)= 0.01 \\{}\\因此\\{}\\ \begin{aligned} P(T) &= P(T|S)P(S) + P(T|\overline{S})P(\overline{S}) \\ &= (0.99)(0.01) + (0.01)(0.99) \\ &= 0.0198 \\ \end{aligned} 根据测试的可靠性,我们可以得到P(T∣S)=1−P(T∣S)=0.01因此P(T)=P(T∣S)P(S)+P(T∣S)P(S)=(0.99)(0.01)+(0.01)(0.99)=0.0198
代入贝叶斯公式,我们可以计算出患者生病的条件概率: P ( S ∣ T ) = ( 0.99 ) ( 0.01 ) 0.0198 ≈ 0.50 因此,测试结果为阳性的患者生病的概率约为 50 代入贝叶斯公式,我们可以计算出患者生病的条件概率:\\{}\\P(S|T) = \frac{(0.99)(0.01)}{0.0198} \approx 0.50\\{}\\ 因此,测试结果为阳性的患者生病的概率约为50%。 代入贝叶斯公式,我们可以计算出患者生病的条件概率:P(S∣T)=0.0198(0.99)(0.01)≈0.50因此,测试结果为阳性的患者生病的概率约为50
使用贝叶斯规则:合并证据


朴素贝叶斯

最大似然估计
最大似然估计(Maximum Likelihood Estimation,简称MLE)是一种常用的参数估计方法,用于根据已知的样本数据来估计模型的参数。它的核心思想是选择能够使观测到的数据出现的概率最大的参数作为估计值。
具体来说,在最大似然估计中,我们假设样本数据来自于某个概率分布,但是该分布的参数是未知的。我们的目标是通过样本数据来估计这些参数,使得该分布能够最好地解释观测到的数据。
假设我们有一个样本集合 X = x 1 , x 2 , . . . , x n X={x_1, x_2, ..., x_n} X=x1,x2,...,xn,每个样本都是来自于某个分布 f ( x ∣ θ ) f(x|\theta) f(x∣θ) 的观测值,其中 θ \theta θ 是分布的参数。我们要找到能够最大化样本集合 X X X 的联合概率密度函数 L ( X ∣ θ ) L(X|\theta) L(X∣θ) 的参数值 θ \theta θ。这个联合概率密度函数可以表示为:
L ( X ∣ θ ) = ∏ i = 1 n f ( x i ∣ θ ) L(X|\theta) = \prod_{i=1}^n f(x_i|\theta) L(X∣θ)=i=1∏nf(xi∣θ)
我们的目标是找到能够最大化 L ( X ∣ θ ) L(X|\theta) L(X∣θ) 的 θ \theta θ 值。因此,最大似然估计的计算可以表示为:
θ ^ M L E = arg max θ L ( X ∣ θ ) \hat{\theta}_{MLE} = \arg\max_{\theta} L(X|\theta) θ^MLE=argθmaxL(X∣θ)
有时候我们需要对上式取对数来避免计算机计算下溢,得到的式子为:
θ ^ M L E = arg max θ log L ( X ∣ θ ) = arg max θ ∑ i = 1 n log f ( x i ∣ θ ) \hat{\theta}_{MLE} = \arg\max_{\theta} \log L(X|\theta) = \arg\max_{\theta} \sum_{i=1}^n \log f(x_i|\theta) θ^MLE=argθmaxlogL(X∣θ)=argθmaxi=1∑nlogf(xi∣θ)
最大似然估计方法是一种常用的参数估计方法,具有计算简单、理论基础好等优点。它在统计学、机器学习、信号处理等领域都得到了广泛应用。
小结
以下是对概率论中重要的公式的整理:
- 条件概率公式:
对于事件 A 和事件 B,其条件概率表示为 P ( A ∣ B ) P(A|B) P(A∣B),表示在事件 B 发生的条件下,事件 A 发生的概率。条件概率公式为:
P ( A ∣ B ) = P ( A , B ) P ( B ) P(A|B) = \frac{P(A,B)}{P(B)} P(A∣B)=P(B)P(A,B)
- 乘法规则公式:
对于事件 A 和事件 B,其联合概率表示为 P ( A , B ) P(A,B) P(A,B),表示事件 A 和事件 B 同时发生的概率。乘法规则公式为:
P ( A , B ) = P ( A ∣ B ) P ( B ) P(A,B) = P(A|B)P(B) P(A,B)=P(A∣B)P(B)
- 链式规则公式:
对于多个事件 A , B , C , D A,B,C,D A,B,C,D,其联合概率表示为 P ( A , B , C , D ) P(A,B,C,D) P(A,B,C,D),链式规则公式可以表示为:
P ( A , B , C , D ) = P ( A ∣ B , C , D ) P ( B ∣ C , D ) P ( C ∣ D ) P ( D ) P(A,B,C,D) = P(A|B,C,D)P(B|C,D)P(C|D)P(D) P(A,B,C,D)=P(A∣B,C,D)P(B∣C,D)P(C∣D)P(D)
- 条件化的链式规则公式:
对于事件 A 和事件 B,其联合概率表示为 P ( A , B ) P(A,B) P(A,B),条件化的链式规则公式可以表示为:
P ( A , B ∣ C ) = P ( A ∣ B , C ) P ( B ∣ C ) P(A,B|C) = P(A|B,C)P(B|C) P(A,B∣C)=P(A∣B,C)P(B∣C)
- 贝叶斯定理公式:
贝叶斯定理是根据先验概率和条件概率来计算后验概率的一种方法,可以用于分类、预测等任务。贝叶斯定理公式为:
P ( A ∣ B ) = P ( B ∣ A ) P ( A ) P ( B ) P(A|B) = \frac{P(B|A)P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)P(A)
- 条件化的贝叶斯定理公式:
对于事件 A 和事件 B,条件化的贝叶斯定理公式可以表示为:
P ( A ∣ B , C ) = P ( B ∣ A , C ) P ( A ∣ C ) P ( B ∣ C ) P(A|B,C) = \frac{P(B|A,C)P(A|C)}{P(B|C)} P(A∣B,C)=P(B∣C)P(B∣A,C)P(A∣C)
- 加法/条件概率公式:
对于事件 A 和事件 B,加法/条件概率公式可以表示为:
P ( A ) = P ( A , B ) + P ( A , ¬ B ) = P ( A ∣ B ) P ( B ) + P ( A ∣ ¬ B ) P ( ¬ B ) P(A) = P(A,B) + P(A,\neg B) = P(A|B)P(B) + P(A|\neg B)P(\neg B) P(A)=P(A,B)+P(A,¬B)=P(A∣B)P(B)+P(A∣¬B)P(¬B)
这些公式在概率论中非常重要,可以应用于统计学、机器学习、信号处理、金融领域、医学领域等各个领域的问题中。熟练掌握这些公式可以帮助我们更好地理解和解决实际问题。