Java集合总览
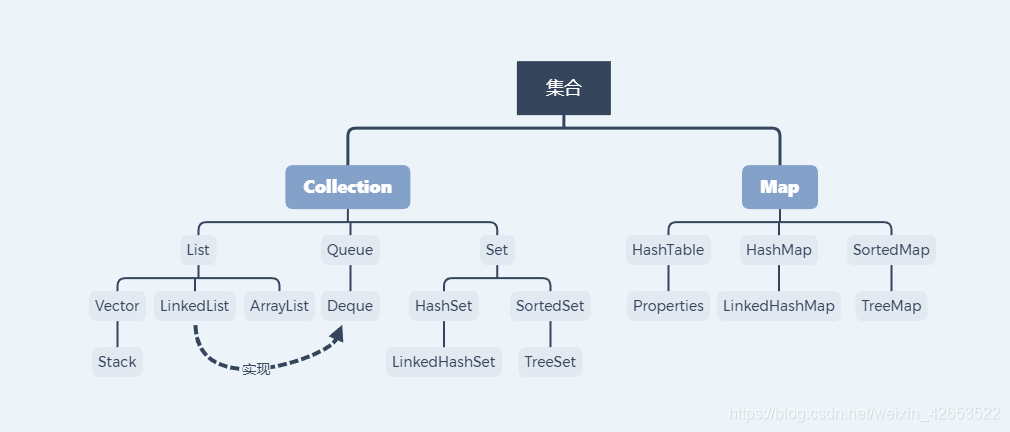
集合可以看作是一种容器,用来存储对象信息。所有集合类都在 java.util 包下,但支持多线程的集合类位于 java.util.concurrent 包下。
Java的集合类主要由两个根接口派生出来,分别是Collection 和 Map。
Java中的集合类可以分为两大类:一类是实现Collection接口;另一类是实现Map接口
Collection是一个基本的集合接口,Collection中可以容纳一组集合元素(Element)。
Map没有继承Collection接口,与Collection是并列关系。Map提供键(key)到值(value)的映射。一个Map中不能包含相同的键,每个键只能映射一个值。
一、Collection
1、Collection接口的子接口以及实现类
Collection接口的子接口包括:Set接口和List接口
Set接口的实现类主要有:HashSet、TreeSet、LinkedHashSet等
List接口的实现类主要有:ArrayList、LinkedList、Stack以及Vector等
List表达一个有序的集合,List中的每个元素都有索引,使用此接口能够准确的控制每个元素插入的位置。用户也能够使用索引来访问List中的元素,List类似于Java的数组。
Set接口的特点是不能包含重复的元素。对Set中任意的两个元素element1和element2都有elementl.equals(element2)= false。另外,Set最多有一个null元素。此接口模仿了数学上的集合概念。
ArrayList底层是数组
LinkedList底层是双向链表
LinkedHashSet底层是LinkedHashMap
HashSet底层是HashMap
TreeSet底层是TreeMap
| 存储元素是否有序 | 存储元素是否可重复 | |
|---|---|---|
| List(列表) | 有序 | 可重复 |
| Queue(队列) | 有序 | 可重复 |
| Set(集) | 无序 | 不可重复 |
Collection是单列集合:每个元素都是一个单独的个体
下图引用自动力节点-杜老师

1、List集合
(1)ArrayList
底层数据结构是数组;
查询快,增删慢
线程不安全,效率高。
(2)LinkedList
底层数据结构是链表
查询慢,增删快。
线程不安全,效率高。
(3)Vector
底层数据结构是数组,
查询快,增删慢。
线程安全,效率低。
(4)Stack
是Vector的实现类,实现一个后进先出的堆栈。
Stack提供5个额外的方法使 Vector得以被当做堆栈使用。push 和 pop 方法,还有 peek 方法得到堆栈的元素, empty方法测试堆栈是否为空,search 方法检测一个元素在堆栈中的位置。Stack 刚创建后是空栈。
2、Queue集合
队列是一种特殊的线性表,它只允许在表的前端进行删除操作,而在表的后端进行插入操作。
Deque类是Queue的实现类。而LinkedList 类既实现了 List 接口又实现了 Deque 接口(也就实现了 Queue接口)。Queue 接口窄化了对 LinkedList 的方法的访问权限,即在方法中的参数类型如果是 Queue 时,就完全只能访问 Queue 接口定义的方法了,而不能直接访问 LinkedList 的非 Queue 的方法。以使得只有恰当的方法才可以使用。
3、Set集合
(1)HashSet类
底层数据结构是哈希表。
存取和查找性能好。
集合元素值可以是 null
(2)LinkedHashSet
是 HashSet 的一个子类,具有 HashSet 的特性。
底层数据结构是链表和哈希表,由链表维护元素有序,元素的顺序与添加顺序一致。由哈希表保证元素唯一。
(3)TreeSet
底层数据结构是二叉树,是 SortedSet 接口的实现类,可以保证元素处于排序状态。
TreeSet 支持两种元素排序:自然排序、自定义对象定制排序。
二、Map
Map接口的实现类主要有:HashMap、TreeMap、Hashtable、ConcurrentHashMap以及Properties等
Map接口采用键值对 Map<k,v> 的存储方式,保存具有映射关系的数据。因此,Map 集合里保存两
组值,一组值用于保存 Map 里的 key,另外一组值用于保存 Map 里的 value,key 和 value 可以
是任意类型的数据,key 值不允许重复,可以为null。如果添加 key-value 对时 Map中已经有重复
的 key,则新添加的value 会覆盖原来对应的 value
HashMap底层与HashTable原理相同,Java 8版本以后如果同一位置哈希冲突大于8则链表变成红黑树
HashTable底层是链地址法组成的哈希表(即数组+单项链表组成)
LinkedHashMap底层修改自HashMap,包含一个维护插入顺序的双向链表
TreeMap底层是红黑树
Map是双列集合:每个元素都是一对数据,把这一对数据当做一个整体去操作
下图引用自动力节点-杜老师

1、HashTable与HashMap
HashMap 与 HashTable 是 Map 接口的两个典型实现,他们之间的关系完全类似于 ArrayList 和 Vertor。HashTable 是一个古老的Map实现类,它提供的方法比较繁琐,目前基本不用。
HashMap线程不安全,HashTable 线程安全。
HashMap 通常比 HashTable 要快
HashMap的key与value可以是null值。HashTable不允许使用Null值作为key和value,如果把null放入HashTable中,会发生空指针异常。
2、LinkedHashMap类
LinkedHashMap使用双向链表维护 key-value对的次序(其实只需要考虑key的次序即可),该链表负责维护Map的迭代顺序,与插入顺序一致,因此性能比HashMap低,但在迭代访问Map里的全部元素时有较好的性能。
3、Properties类
Properties类时Hashtable类的子类,它相当于一个key、value都是String类型的Map,主要用于读取配置文件。
4、TreeMap类
TreeMap是SortedMap的实现类,是一个二叉树的数据结构,每个key-value对作为二叉树的一个节点。TreeMap存储key-value对时,需要根据key对节点进行排序。TreeMap也有两种排序方式:
自然排序:TreeMap的所有key必须实现Comparable接口,而且所有的key应该是同一个类的对象,否则会抛出ClassCastException。
自定义对象定制排序:创建TreeMap时,传入一个Comparator对象,该对象负责对TreeMap中的所有key进行排序。