Privacy-Aware Resource Sharing in Cross-Device Federated Model Training for Collaborative Predictive Maintenance
提出了一个基于拆分学习的框架 (SplitPred),该框架使 FL 客户能够在不损害 FL 方法的好处(即隐私和共享学习)的情况下最大化其本地网络中的可用资源。
在涉及异构边缘设备的 PdM 跨设备 FL 场景中,可能有一些 FL 客户端没有足够的计算资源来及时训练全局模型。这些客户端可能会导致模型聚合延迟,甚至在训练迭代期间断开连接。这反过来可能会阻碍其他客户从彼此的数据中有效地学习故障模式。
这种情况可能会在一段时间内停止协作预测过程,并在预测性维护等场景中证明成本高昂。
SplitPred
通过使物联网边缘设备(FL客户端)将其部分模型训练任务卸载到位于同一网络上的其他边缘资源来实现的(图1b)
确保边缘设备与本地边缘服务器交换模型更新(图 1b),然后将它们传递到全局服务器进行聚合。这有助于加快本地模型收敛时间,因为边缘设备有时无法实时访问全局服务器,从而导致模型更新交换延迟。
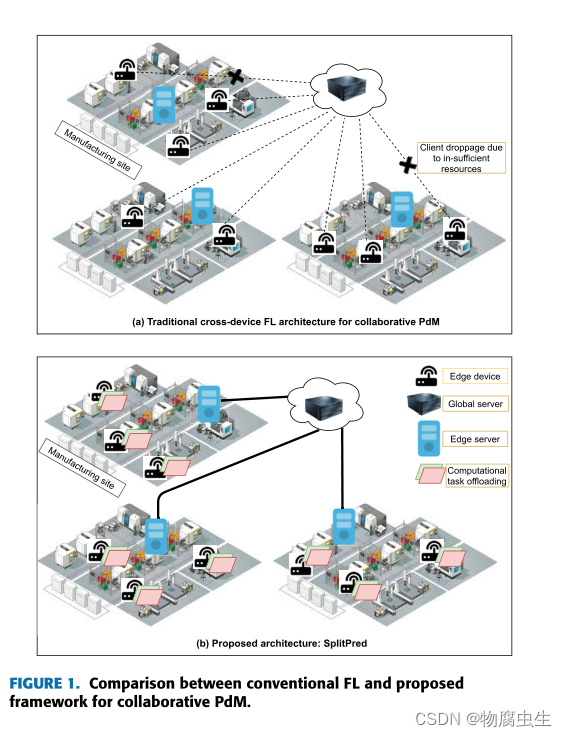
图 4 表示 SplitPred 的逻辑视图,其中部署在多个制造站点的边缘设备参与协作 PdM 过程。
SplitPred 的贡献在于它能够使本地网络中的边缘设备在训练全局模型的同时共享其计算和通信资源。
此外,SplitPred 使边缘设备能够利用已经分配给边缘服务器的带宽,以便与全局服务器进行交互,从而减少消息交换的数量和模型收敛时间。SplitPred 利用部署在本地网络边缘设备上的拆分神经网络 (SplitNN) 架构在训练全局模型的同时实现隐私保护资源共享。
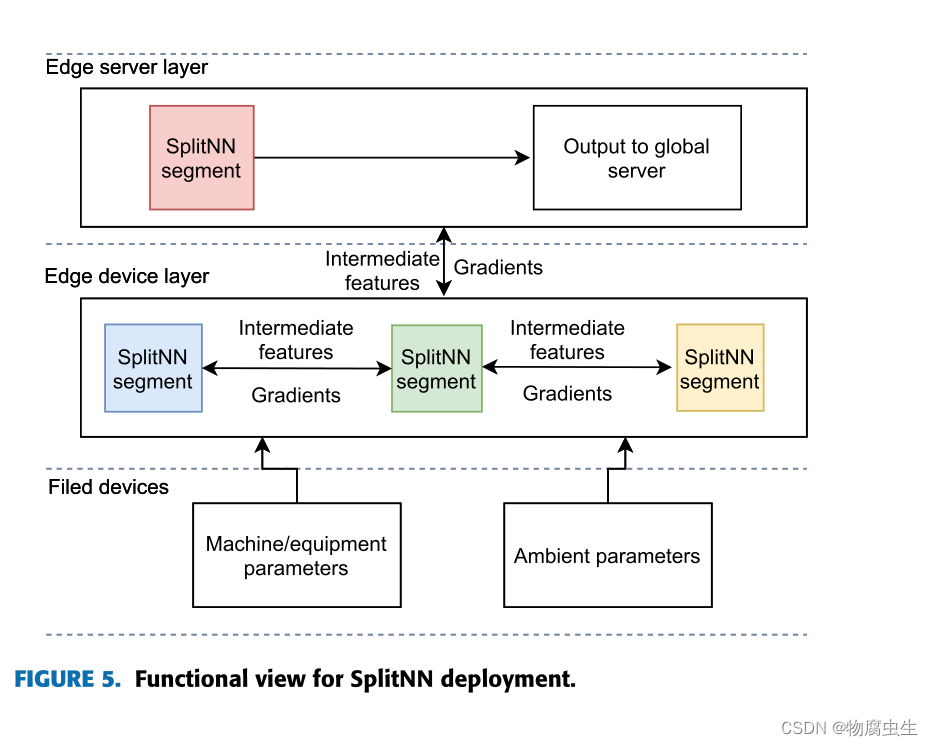
由于SplitPred 部署在制造现场的本地网络上,它采用如下三层本地网络架构:
• 现场设备:该层由传感器、执行器等组成,负责感知并可靠地从制造中提取参数现场并接收基于处理的制造数据的驱动指令。传感器将原始感知观察结果传输到首选边缘设备(可以通过有线或无线通信协议,例如 IEEE 802.15.4),以将输入提供给学习模型。
• 边缘设备:边缘设备层由物联网边缘设备组成,这些设备从现场设备接收原始数据并对其进行处理以进行推理。边缘设备是单板计算机(例如 Raspberry Pi),配备有限的计算和通信能力(例如 WiFi)。
• 边缘服务器:这一层由一个本地应用程序边缘服务器组成,负责将最终结果提供给全球服务器。 SplitPred 边缘服务器接收全局模型并分配合适的边缘设备进行训练。它是一种计算丰富的设备,边缘设备也可以将其神经网络段卸载到该设备上,但应该注意的是,边缘服务器也可以是具有与边缘设备类似功能的单板计算机。
为了完全启用边缘分析,每个边缘设备都可以按顺序参与训练不同的 NN 模型或不同 NN 模型的片段。
SplitPred1:所有顶层都保留在 ED 中,最底层以及标签保留在 ES 中。
SplitPred2:将 NN 的后端卸载到远程边缘服务器
SplitPred3 将 NN 的一部分卸载到相邻边缘设备 (ED2)。
SplitPred3 支持多个边缘设备之间的资源共享。根据图 8 所示的工作流程,SplitPred3 涉及多个 ED,它们共享 SplitNN 模型的不同部分,而标签则放置在 ES 中。前向传播和反向传播梯度的执行仍然类似于图 6 中所示的架构。第一个边缘设备 (ED1) 执行神经网络的第一段 (layer1, layer2, …, layerk) 并共享对应于 layerk 的激活和梯度与另一个执行第二段 (layerk+1, layerk+2, …, layerj) 的边缘设备 (ED2)。对应于 layerj 的激活和梯度与 ES 共享,其中执行最后一个段 (layerj+1, layerj+2, …, layern) 并执行 C(outputn, labels)。这里,layerk 和 layerj 是两个拆分层。对于反向传播,ES 计算以下偏导数(方程 16)并与 ED2 共享 ∂C ∂aj。
概述的每个部署策略都限制了本地设备(边缘设备和边缘服务器)之间原始制造数据的共享。参与式边缘设备仅彼此共享其最后一层神经网络的输出。这不仅可以确保数据隐私,还可以减少本地网络中的消息交换次数。部署策略由 ED 特定的局部参数(如剩余能量、工作负载等)确定。文献中提出了各种卸载决策机制,如 [29],但是,此讨论超出了本文介绍的工作范围.
SplitPred 的使用可以提高收敛时间、准确性,同时减少训练过程中的消息交换次数。
然而,FL 在训练全局模型的内存需求方面优于 SplitPred。
最后,我们为未来的研究提出了以下未解决的问题:
全局模型准确性和计算开销之间的权衡:这项工作采用一个简单的具有两个隐藏层的 NN 模型作为协作 PdM 的全局学习模型。 NN 的简单性试图在资源受限的边缘设备上保持准确性和计算开销之间的权衡。然而,其他集中式模型(如 LSTM 和 CNN)会产生更好的准确性,但计算量很大。这使得这些模型不适用于资源受限的边缘设备,并且在试图最小化网络和边缘资源消耗的场景中可能会适得其反。
因此,准确性和计算开销之间的权衡仍然是一个悬而未决的问题。虽然拆分学习不能与 LSTM 一起使用,但可以探索轻量级 CNN 模型(1D 和 2D)以进一步提高准确性。
本地网络和模型交换的隐私泄露:拆分层可能的隐私泄露 [通常通过
(1)增加卸载设备的隐藏层数量和(2)使用差分隐私来处理。然而,这两种技术,尤其是差分隐私,都会受到全局模型准确性降低的影响。因此,需要解决在保持全局模型准确性的同时降低隐私泄露风险的问题。
区块链等技术可用于实现安全可靠的模型交换,因为所涉及的共识机制可以帮助识别潜在的恶意 FL 客户端。
本地边缘设备的内存开销:使用拆分学习的全局模型训练涉及训练过程中涉及的每个设备存储梯度,这反过来导致本地网络上边缘设备的内存开销增加。可以探索数据压缩技术以减少内存需求,同时确保压缩/解压缩过程不会影响模型收敛时间。