缘起
Java 语言为了实现 “一次编写,处处运行”,编译器会将源码编译为一个中间语言 —— 字节码,之后通过 Java 虚拟机(JVM)将字节码翻译成对应的机器码执行。而这个翻译过程是解释执行的,相比静态编译的语言比如 C++ 会有一定的性能损失。
为了提高 Java 在运行时的执行效率,JVM 引入的即时编译技术,即 JIT(Just-In-Time):字节码依然是解释执行的,但通过对执行过程的分析,选择性的将热点代码编译成机器码并缓存起来,来整体提高 Java 的执行性能,同时在编译过程中也会有一些代码优化手段来让代码执行更有效率。
下文就来聊聊 JVM 中 JIT 相关的内容以及实践。
JVM 中的 JIT 编译器
大家最常用的 JVM 就是 HotSpot 了,默认情况下它的运行模式为混合模式(mixed mode),即运行阶段解释器和 JIT 编译器配合执行,也可以通过 JVM 参数设置其执行模式:
-Xint:完全采用解释器模式执行程序。-Xcomp:完全采用即时编译模式执行程序,如果即时编译出现问题,解释器会介入。-Xmixed:采用解释器 + 即时编译的混合模式共同执行程序,是 JVM 默认的执行模式。
通常来说我们没有必要修改它的执行模式。在介绍混合模式的执行方式之前,先介绍一下 JIT 编译器,HotSpot 为我们提供了两种 JIT 编译器,二者在代码优化策略上有所差异:
- C1 Compiler:又称 Client Compiler 或者 Client 模式,通常用于客户端程序这类本地资源较少且对启动时间敏感的程序,编译耗时通常较短,会有一定的优化效果。
- C2 Compiler:又称 Server Compiler 或者 Server 模式,对于运行环境的本地资源相对不受限制,会进行更多的深度优化,但通常编译耗时较长,而编译后的代码执行效率也会更优。
可以发现二者有各自的优势和适用场景,早期的时候可以通过 JVM 参数 -client 指定使用 C1 编译器,-server 指定使用 C2 编译器。那么是否有办法整合二者的优势呢?Java 7 开始引入了 分层编译 的概念对二者的优势进行整合。
分层编译
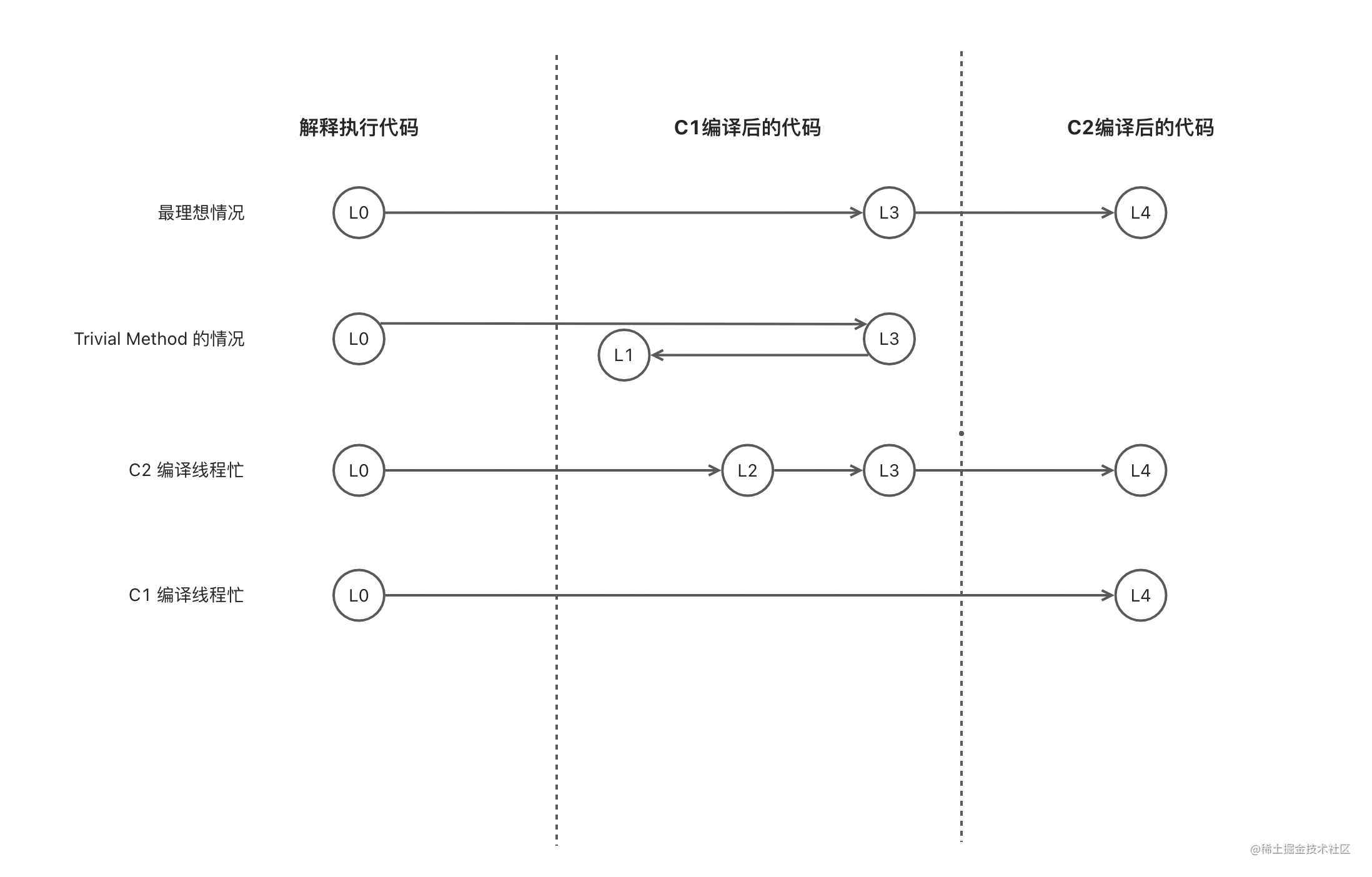
引入了分层编译的概念后,从解释器解释执行字节码到 JIT 编译器的介入,会有多个过渡过程,以及代码状态也被分为了 5 个级别:
| 编译级别 | 解释 |
|---|---|
| Level 0,解释执行代码 | 最初启动时,JVM 通过解释执行所有的代码。 |
| Level 1,C1 简单编译代码 | 这个级别,JVM 开始使用 C1 编译代码,但由于方法的复杂度,发现即便使用 C2 编译器也不会得到明显的性能收益,那么也就不会进一步去收集这类方法的 Profiling 信息,直接使用 C1 编译器编译。 |
| Level 2,C1 受限编译代码 | 这个级别,C1 编译器仅基于方法计数器和回边计数器提供 Profile 信息编译代码。 |
| Level 3,C1 完整编译代码 | 在 Level 2 的基础上,基于完成的 Profile 信息编译的代码。 |
| Level 4,C2 编译代码 | 这个级别,执行使用 C2 编译器编译后的代码。 |
在 JVM 解释执行字节码的过程中会收集代码执行过程中的信息,并且有专门的 JIT 编译线程在必要的时候介入优化。从上图几种过渡状态可以发现,最理想的情况是从 L0 直接到 L3 最后到 L4,但如果是你的方法复杂度很低,比如是简单的 get/set 方法,即便让 C2 去编译也不会再有更多收益,那么 L1 级别就已经足够。
由于编译线程是有限的并通过队列的方式编译你的方法,那么一定会有因繁忙而阻塞的情况,如果 C2 编译线程忙,那么就会先过渡到 L2 让代码尽早优化,再过渡到 L3,当 C2 编译线程闲时再交给它将过渡到 L4。C1 编译线程也有繁忙的时候,如果此时代码在解释执行的过程中已经收集到了足够的信息,那么会直接交给 C2 编译线程直接过渡到 L4。
从 Java 8 开始,已经默认开启分层编译了,同时之前用于手动指定使用 C1 或 C2 编译器的参数
-client以及-server都不再有效。
编译线程
上面提到了 JVM 会起编译线程来进行 JIT 编译,编译线程的数量默认情况下是和当前机器的 CPU 核数有关的,默认情况下 CPU 核数与编译线程的关系如下:
| CPUs | C1 编译线程数 | C2 编译线程数 |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 1 | 1 |
| 4 | 1 | 2 |
| 8 | 1 | 2 |
| 16 | 2 | 6 |
| 32 | 3 | 7 |
| 64 | 4 | 8 |
| 128 | 4 | 10 |
也可以通过 JVM 参数 -XX:CICompilerCount 手动指定编译线程数,如果你手动指定了,那么 1/3 的线程数是 C1 的,剩下的就是 C2 的,比如你手动指定了 6 个编译线程数,那么最后就会起 2 个 C1 的编译线程和 4 个 C2 的编译线程。
即时编译触发时机
上文提到代码在解释执行过程中收集信息,JIT 编译器会在必要的时候介入,那么什么是必要的时候?或者怎么样的代码会被认为值得被优化?一定是被高频执行的热点代码,热点代码分为两种:被多次调用的方法、被多次执行的循环体。JVM 会为每个方法或者代码快建立计数器,如果执行次数达到一定的阈值,就认为它们是热点代码,JIT 编译器便会介入。
方法调用计数器
它统计的是一个方法调用的相对次数,即一段时间内方法被调用的次数,当超过一定的时间限度,如果该方法的计数仍然不足以让它提交给编译器编译,那么该计数会被减少一半,这个过程被称为方法调用的衰减(Counter Decay),这段时间被称为此方法统计的半衰周期(Counter Half Life Time)。
回边计数器
首先什么叫回边?回边(Back Edge)是指当字节码在执行时遇到控制流向后跳转的指令。回边计数器统计的是该方法循环执行的绝对次数,没有衰减的过程。
在有分层编译机制之前,可以通过 JVM 参数:-XX: CompileThreshold 设置方法调用计数器的阈值,默认 Client 模式下为 1500 次,Server 模式下为 10000 次。针对回边计数器也有固定的阈值计算公式。而有了分层编译机制后,上述参数不再有效,阈值是基于多个参数动态计算的:
方法调用次数 > Tier{X}InvocationThreshold * s ||
方法调用次数 > Tier{X}MinInvocationThreshold * s && 方法调用次数 + 循环回边次数 > Tier{X}CompileThreshold * s
其中 X 分别指上述讲过的编译级别,取 3 或 4。上面的参数默认值为:
Tier3InvocationThreshold = 200
Tier4InvocationThreshold = 5000
Tier3CompileThreshold = 2000
Tier4CompileThreshold = 15000
Tier3MinInvocationThreshold = 100
Tier4MinInvocationThreshold = 600
其中系数 s 的计算公式如下:
s = Level X 层待编译方法数 / (TierXLoadFeedback * 编译线程数) + 1
其中 X 也是指 3 或 4 的代码编译级别,TierXLoadFeedback 的默认值如下:
Tier3LoadFeedback = 5
Tier4LoadFeedback = 3
虽然计算公式变复杂了,分析公式从何而来也比较困难,但从计算公式上不难看出,如果是应用刚启动,待编译的方法数很小甚至为 0,那么头几个方法调用会很快被编译,随着应用的启动,调用的方法越来越多,待编译的方法数也会增多,那么后面调用的方法要被优化就需要更多的调用次数。
相比过去固定阈值的模式,动态计算阈值更加弹性,尽可能平衡了 JIT 编译的及时性以及因为 JIT 编译对应用带来的性能影响。
OSR(On Stack Replacement)
这里额外提一下 OSR 的概念,首先 JIT 编译器的编译单元为一个方法,但通过回边计数器覆盖的热点代码是循环体内的代码,那么在编译单元依然为一个方法的情况下,其执行入口会有所不同,在方法执行过程中,循环体被替换为优化过后的代码,即方法的栈帧还在栈上的时候,这个方法被替换了,这就是 OSR “栈上替换” 的概念。
关于去优化
聊完编译器启动优化的时机后,咱们说说去优化。所谓去优化是指 JIT 编译器对代码的优化不再有效,此时这段代码会被回退会解析执行的模式重新经历一次从执行分析到优化的过程。去优化有两种状态:made not entrant 和 made zombie。
Not Entrant Code
made not entrant 可以翻译为 “不再进入”,顾名思义就是这段代码后续都会再用了。有两种情况代码会被标记上 made not entrant:
首先一种情况和激进优化有关,C2 编译器为了获得更好的优化效果,会进行一些比较激进的优化,随着代码的运行可能会导致之前的优化失效,这里以分支预测优化为例:
StockPriceHistory sph;
String log = request.getParameter("log");
if (log != null && log.equals("true")) {
sph = new StockPriceHistoryLogger(...);
}
else {
sph = new StockPriceHistoryImpl(...);
}
// Then the JSP makes calls to:
sph.getHighPrice();
sph.getStdDev();
比如你的服务器运行着如上的代码,之前大量的请求都没有 log 参数的情况下走的都是 else 条件,此时 sph 变量类型为 StockPriceHistoryImpl,编译器会进行一些方法内联处理等优化手段,但一旦开始有请求带上了 log 参数,那么逻辑会走到 if 条件为真的分支,此时 sph 变量类型为 StockPriceHistoryLogger,之前的优化边会被认为是无效的,去优化就发生了。
另一种情况和分层编译的机制有关,从上面讲的分层编译的过渡过程来看,代码的终态是 L4 或者 L1,那么过程中生成的 L2、L3 的代码编译结果在被编译的方法到达终态的时候也会发生去优化。
Zombie Code
这个状态可以理解为之前被标记为 made not entrant 的代码已经被标记为可被回收了,这些 zombie code 在 Code Cache 的清理机制触发时会被清理掉,下面会介绍 Code Cache 相关的内容。
编译缓存
JVM 中有一片被称为 Code Cache 的内存区域,用于缓存 JIT 编译器的编译结果,在之后的执行中,程序再次调用该方法时,就可以直接使用 Code Cache 中的本地代码,而无需再次进行编译。需要注意的是 Code Cache 的大小是固定的,启用分层编译的情况下默认是 240MB,如果 Code Cache 空间不足会导致 JIT 编译器无法继续编译新代码,进而导致应用程序的性能下降。
如果 Code Cache 满了,在 JVM 日志中会输出 CodeCache is full. Compiler has been disabled.。你可以通过 JVM 参数 -XX:ReservedCodeCacheSize 调整 Code Cache 的默认空间大小。
另外 Code Cache 有一个推断式的清理机制,通过 JVM 参数 -XX:+UseCodeCacheFlushing 控制,这个开关从 Java 7 开始就默认开启了,当 Code Cache 快满时,一半先前编译好的方法会被放入一个老方法队列中去,并以一个固定的频率开启检查(默认 30s),如果经过两次检查改方法依然没有被使用,则改方法被标记为 made not entrant,后续慢慢会被清理。
JIT 编译日志分析与实践
观察 JIT 编译日志
我们可以通过 JVM 参数 -XX:+PrintCompilation 来观察 JIT 的执行过程,以一段测试代码为例:
public class SomeComputation {
public String doSomething(String str) {
if (str == null || str.isEmpty()) {
return "Hello World!";
}
return str.toUpperCase() + str.toLowerCase();
}
}
public class TrivialObject {
private int a;
private String b;
public int getA() {
return a;
}
public void setA(int a) {
this.a = a;
}
public String getB() {
return b;
}
public void setB(String b) {
this.b = b;
}
}
public class JITCompilationPlaygroundMain {
public static void main(String[] args) {
SomeComputation sth = new SomeComputation();
for (int i = 0; i < 100000; i++) {
TrivialObject obj = new TrivialObject();
obj.setA(i);
obj.setB(String.valueOf(i));
sth.doSomething(obj.getB());
}
}
}
带上参数执行代码后会得到如下输出(由于比较长,仅贴出关键部分):
149 61 3 me.leozdgao.playground.TrivialObject::setB (6 bytes)
149 62 3 me.leozdgao.playground.SomeComputation::doSomething (39 bytes)
150 72 1 me.leozdgao.playground.TrivialObject::setB (6 bytes)
150 61 3 me.leozdgao.playground.TrivialObject::setB (6 bytes) made not entrant
150 42 1 me.leozdgao.playground.TrivialObject::getB (5 bytes)
150 56 3 me.leozdgao.playground.TrivialObject::<init> (5 bytes)
150 57 3 me.leozdgao.playground.TrivialObject::setA (6 bytes)
150 58 3 java.lang.String::valueOf (5 bytes)
150 60 3 java.lang.Integer::toString (48 bytes)
150 32 3 java.lang.String::getChars (62 bytes) made not entrant
150 71 4 java.lang.StringBuilder::append (8 bytes)
151 73 1 me.leozdgao.playground.TrivialObject::setA (6 bytes)
151 57 3 me.leozdgao.playground.TrivialObject::setA (6 bytes) made not entrant
151 30 ! 3 sun.misc.URLClassPath$JarLoader::ensureOpen (36 bytes)
152 33 1 java.net.URL::getProtocol (5 bytes)
152 55 s 1 java.util.Vector::size (5 bytes)
156 82 4 me.leozdgao.playground.SomeComputation::doSomething (39 bytes)
163 80 4 java.lang.String::valueOf (5 bytes)
163 34 3 java.lang.String::<init> (82 bytes) made not entrant
163 81 4 java.lang.Integer::toString (48 bytes)
171 58 3 java.lang.String::valueOf (5 bytes) made not entrant
172 60 3 java.lang.Integer::toString (48 bytes) made not entrant
172 62 3 me.leozdgao.playground.SomeComputation::doSomething (39 bytes) made not entrant
176 84 % 3 me.leozdgao.playground.JITCompilationPlaygroundMain::main @ 10 (53 bytes)
177 85 3 me.leozdgao.playground.JITCompilationPlaygroundMain::main (53 bytes)
先解释一下日志格式:
时间 JVM编译ID 标识符 编译层次 编译的方法名 去优化标记
对着我们输出的日志解释,其中时间指的是应用启动到编译触发的时间,关于标识符的含义上面日志中出现的 3 个代表:
%:表示是否是 OSR 编译s:是否为 synchronized 方法!:是否包含异常处理器
还有两个没有在上面的例子中出现的标识符:
n:是否是 native 方法b:是否阻塞应用线程
通过观察编译层次列的值可以比较好的验证前文说过的过渡过程,以方法 TrivialObject::setB 为例,由于它是一个简单的 setter 方法,属于 Trivial Method,时间 149ms 时是 L3,在 150ms 时过渡到了 L1,再看方法 SomeComputation::doSomething,它的方法体里定义了一些逻辑,在 149ms 时是 L3,156ms 时过渡到 L4,是最常见的过渡过程。
仔细观察发现过渡到 L1 或者 L4 的方法,后续都有一个额外的 L3 记录,且最后有一列值为 made not entrant,这个就是上面说的去优化标记,因为分层编译机制的关系 L3 作为中间状态的代码被标记为 ”不再进入“。
应用预热
在实际开发的过程中,由于 JIT 机制的存在,应用在重新部署刚启动的阶段,JIT 编译器尚未及时优化热点代码,可能会造成服务发生短时间内的响应时间增加,以及刚启动阶段大量的 JIT 编译导致 CPU 利用率飙高,这些都潜在影响着服务的可用性,特别对于面向 C 端的服务接口尤其需要关注。
要解决这个问题,可以考虑进行 ”应用预热“,这个需要根据每个应用的实际情况来自行判断,以 Spring Boot 应用为例,可以基于事件 ApplicationReadyEvent,在应用实际对外提供服务之前提前调用你认为的热点代码,提前触发 JIT 编译,从而让应用真正提供服务的时候,热点代码已经是被优化过了的。
总结
笔者也是遇到了需要做应用预热的场景,就顺便将 JIT 的机制从分层编译到 Code Cache 还有日志分析进行了一番整理,当然应用预热根据不同应用的情况,其实涉及到的东西不止 JIT 编译这一个因素,这篇文章中就不再展开了。
在 Java9 开始 Graal 编译器的引入,基于 AOT 编译的代码由于在编译期就已经被编译成了目标环境的机器码,根本不存在 JIT 的机制,那么也就不用担心应用需要预热的问题,这个部分的介绍和实践就在后续的文章中再做介绍啦。
参考资料: