一、什么是EDA架构?
EDA 是一种基于发布/订阅模式的消息异步通信的架构,你可以把它理解为架构层面的观察者模式。它主要分为以下7个核心对象,具体的协同模式可以参考以下原理图。
事件 (Event):即要被处理的对象,它可以是离散的也可以是有序的;其格式既可以是JSON,也可以是XML或者银行专用的8583报文;
事件巴士(Event bus):负责接收从外部推送过来的event并作为同一个event在不同manager之间流转的载体;一般的选型可以使用MQ、Kafka或者Redis(当然Redis的pub/sub模式不能消息持久化);
Worker Manager:负责把订阅主题拿到的event分配给Worker;
Worker:作为执行者对event进行业务处理并做出响应;
MonitorManager:作为监控者负责监控event的处理,可以看作是event的守护线程。
Message Broker:作为一个消息中介,负责分配和协调多个worker(或者我们可以称之为工序)针对该event的处理顺序,且该broker负责维护该处理顺序所用到的路由规则。

大致流程为:
Event作为一个事件被发布到Event bus;
Message Broker和Rule是搭配干活的。所有的事件对自己的“我从哪里来”和“我要到哪里去”是完全不清楚的,由Message Broker根据Rule所定义的路由规则进行分派给对应的WorkManager;
当WorkManager在订阅的主题里面发现有对应的事件后,则会根据当时的worker的负载情况进行工作分配;接着,worker就会执行对应的业务处理流程;
贯穿整个过程,会由MonitorManager负责监听每个事件的状态。具体的实现是(以Kafka为例)可以约定所有的WorkManager针对处理异常的事件全部丢到一个死信主题,然后由MonitorManager负责订阅监听该主题并进行相应的告警处理。
二、适用场景
第一,因为它是异步的,因此特别适合以下:
1)整个交易处理链路较长的准实时或非实时场景,例如票据管理;
2)或者是基于fan-out的广播类型场景,例如移动商城抢购后需要跟进的一系列动作(短信通知、发货申请、更新订单状态等),这类场景一般是非实时,是time-tolerance(接受一定时间容差);
3)削峰填谷的场景。例如,上游应用系统推送了大量的系统日志至ELK,ELK更多是进行入库和统计分析,不需要对上游做实时响应的。
第二,如果业务模式的整个主流程不强调强一致性且流程变化很快的,则可以适当的考虑这种架构。
第三、因为它是通过管道进行异步通信,如果你的系统是那些对交易实时性要求较高的或者是跟2C端页面交互强关联的,则不太建议使用该异步架构;
三、优势
第一、在这种模式下,系统一般被分解成多个独立又互相有一定关联关系的服务或模块,这种模式真正体现高内聚低耦合,很好的体现Y轴扩展。笔者曾经负责过的一个票据处理系统就是这种EDA架构,每个worker只负责一个工序(满足高内聚),当需要新增额外工序的时候只需要继承基类新增新类型的worker,并配套新rule即可。眨眼看上去是不是责任链模式在系统架构中的体现?(题外话:扩展性理论可以参考《The Art of Scalability》里面的AKF scale cube模型);
第二,高内聚带来的好处就是,每当新增功能时大概率只需要改动某个节点的worker,改动的影响可以被限定在一定范围内(即某个worker内部);
第三,worker理论上可以无限水平扩展以便支持大规模的业务量;当manger变成瓶颈后,也可以适当把manager从单实例扩展成集群;
第四、基于事件(event)实际上持久化到Event bus ,因此便于做差错处理,提升了系统整体的可运维性。例如,event1在manager2处理失败后即不会继续往后处理,方便IT人员排查并修复后把该event重新路由至同一个manager下进行处理。
四、幂等性
既然使用到EDA这种事件触发型的架构模式,势必会面临一个以下常见的场景:
-
由于路由规则错误导致的同一个event被重复多次路由到同一个manager进行处理;
-
event被重复消费(例如可能来自于kafka的再平衡);
-
或者说人工从死信主题中被重新捞出来处理。
因此,幂等性设计在这种架构下就显得尤为必要。所有的所有的业务流程或操作在数据库视野上归根结底就是事物状态的变更和查询两大类。如果是查询类的操作,那幂不幂等这个无关重要。如果是变更类的操作,那就需要考虑幂等的设计。一般来说,幂等性可以通过token、状态码、乐观锁等方式实现。
其实这个幂等性在接口层面很是关键,笔者所负责的一些系统都出现了好些幂等性设计不足导致一些生产故障。这里我就按照之前的经验总结一些如何解决这个问题,有些是从同事的代码看到的,有些是自己之前的一些经验,虽然大体跟网上搜到的都是大致一样。
| 方式 | 实现原理 |
| 去重表 | 基本原理: 通过设计一张独立的表,该表拥有一个唯一索引(可以是独立索引或联合索引),然后当请求进来时,通过数据库的唯一性约束,如果插入正常的则继续执行,失败则返回失败。 具体做法: 在服务端定义一个接口,在接口中要求客户端上送客户端自己的UUID_1,然后服务端在处理的时候会生成服务端自己的UUID_2,并在该独立表中把UUID_1和UUID_2作为唯一索引进行insert操作。这样的话,就算是因为用户在前端重复提交,但在服务端都会因执行insert操作失败(DuplicateKeyException)而被成功拒绝掉。 这个方案不好的地方在于有数据库操作,因此在常规并发不高的情况下可以考虑,毕竟综合成本相对较低(复杂度和成本),这才符合KISS原则。 |
| token+redis机制 | token 机制其实就是服务端提供两个接口:1)提供token的接口;2)真正的业务接口。 首先,客户端先去服务端申请token,服务端返回token并缓存至redis用于后面的校验; 接着,客户端带着token去调用服务端的业务接口,服务端先尝试删除redis中的token: 如果删除成功,则往下处理业务逻辑; 如果删除失败,则代表相同接口被重复调用过,即这请求为重复请求,服务端直接拒绝。 当然网上会争论究竟是1)先删除token再处理业务;还是2)处理完业务后再删除token;只能说各有利弊吧,不过如果对于银行业这种以安全优先的行业的话肯定是优先第一个方案。 另外,这里也说一下这个方案的成本必要性。首先,这个机制要求客户端每次都需要调用两次接口,但是重复的情况肯定不是常态。那就是说为解决那1%的问题要99%的请求都要按照这种模式,而且这个方案还不完美解决问题,我自己觉得这个方案是不经济的做法。 |
| 状态码机制 | 状态码这个其实就是在交易表或主表中增加一个针对该交易的状态(前提是该表有个交易的全局唯一流水),针对提交进来的具有相同交易流水的交易通过该状态避免重复提交的情况。 这种做法一般在非2C的系统用得比较普遍,因为大部分情况下不太需要考虑流量、并发等因素。 |
| 乐观锁机制 | 具体做法就是在要更新的表中,通过增加一个字段(这里可以使用#version或者#timestamp)作为一个版本号字段。 |
| 分布式锁机制 | 基本原理: 这里以redis实现的方式为例。如果基于redis,主要使用SETNX+EXPIRE实现分布式锁(但是锁超时时间要取决于业务场景,或者说一般要大于调用方的超时时间)。这样的话,在锁超时时间内,同一个接口的重复提交(当然指的是接口参数是一样的情况下)会因为在调用SETNX失败而成功拒绝掉重复提交。 具体做法: 自定义一个幂等注解,然后配合AOP进行方法拦截,对拦截的请求信息(包括方法名+参数名+参数值)根据固定的规则去生成一个key,然后调用redis的setnx方法,如果返回ok,则正常调用方法,否则就是重复调用了。这样可以保证重复请求接口在一定时间内只会被成功处理一次。 具体的SETNX实现分布式锁还是有一些因key超时带来的锁释放的细节问题,具体可以参考我的另外一篇文章《 基于Redis的分布式锁》。 |
上面讲的这几种方式其实都是有个共通点,通过给某个业务请求生成或赋予一个唯一对应的令牌(如token,或乐观锁的#version),然后服务端针对业务接口的调用进行令牌校验,如果不能满足规则则拒绝处理。当然,上面的每种方法也有其局限性,因此在用于生产的设计方案中一般都是以上两种或多种方法的组合体。最关键的是,具体每个方案怎么组合或者组合到哪种程度是要与实际业务场景相结合的,总不能为了所谓的技术追求而犯了教条主义的错。
五、最终一致性
EDA架构是通过实现可靠事件模式来达成业务层的最终一致性的。什么是可靠事件模式?可靠事件其实就是保证事件(event)能够被成功投递、接收及处理,简直TCP链接的增强版。其中可靠性通过以下三个维度进行可靠性保证。Talk is cheap, show u the pic。

1、投递可靠性
首先,EDA架构下的消息巴士一般采用各种消息中间件作为消息传递的桥梁,而主流的开源消息中间件(例如RabbitMQ/RocketMQ/Kafka)使用的都是At least Once的投递机制(即每个消息必须投递至少一次),简单点说就是消息发送者(这里指“事件巴士”)发送消息至消息接受者(这里指“下游”)并且要监听响应,如果在规定指定时间内没有收到,则消息发送者会按某种频次重新发送该消息直到收到响应为止。
当然,如果是“上游”投递至“事件巴士”也需要从上游的应用层面做可靠性的容错处理。有兴趣的同学可以看一下Kafka的ACK机制。

2、传输可靠性
因为架构中使用消息中间件,目前大部分中间件都有对应的消息持久化机制,保证数据在没有被下游成功确认收到前不会丢失,哪怕是中间件本身宕机重启。当然,这个功能因中间件而异,部分中间件是放开给客户端控制的。
当然,中间件本身也有相应的数据容错策略。举个例子,Kafaka通过分区复制的策略保证数据不丢失。具体大致逻辑是由生产者(producer)首先找到领导者(leader)(这里的leader是Broker1上的Partition0)并把消息写到leader分区,然后leader分区会通过内部管道把消息复制到其它broker上的分区,这就是所谓的分区复制,这里附上原理图方便大家理解。

3、处理可靠性
我的理解,这里的处理可靠性更多指的是应用层的消息路由逻辑。就是说,当一个事件(event)被一个节点(worker)处理完后,会按照路由策略表严格指定该事件(event)的下一个节点(worker)是谁。我认为它的可靠性是相对平时的代码接口调用或者过程式代码的这种风格而言的,这也正是它的可靠性所在。
-
路由规则:这套路由规则被抽象出来作为核心资产进行统一管理,因为它是定义整个业务流转规则,明确-简单-严格;
-
异常处理规则:某个节点处理出现异常,处理过程会被终止。保证经过人工介入才能重新触发继续往后处理;
-
监控规则:某个事件或业务流程要整体成功跑完所有按路由规则要求的所有节点,否则监控会进行告警并触发人工介入。
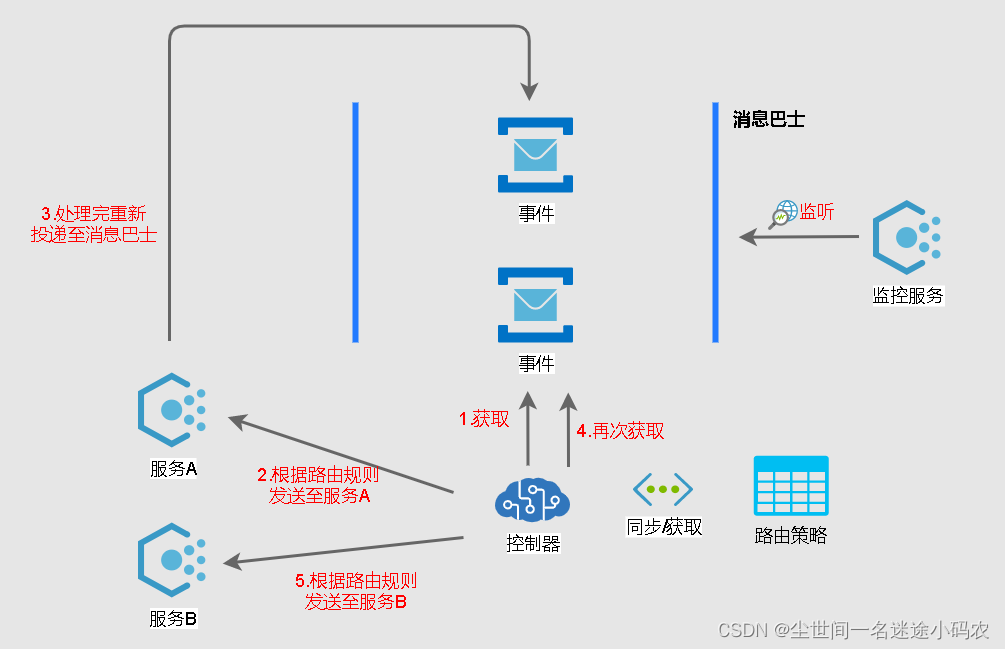
六、监控
EDA的这种架构还有一个突出的特点,就是因为每个节点都是解耦的,所以哪个节点都不清楚进来的每一个event当前的状态是怎样的,究竟是已经处理完毕呢还是被丢到死信主题呢。这就好像流水线上的工人,个人只会完成自己的工序并再放回到流水线上。
当然,我们可以通过定义每个节点的worker的异常处理逻辑(即发生异常时指定错误码并顺带进行告警),但是这种方法有两个弊端:
业务流程处理跟告警处理耦合在一起;如果这种告警是通过API接口调用的话就更麻烦,因为如果告警系统有任何问题且大面积的event出现异常时候分分钟拖死你这个worker,继而耗尽线程资源导致系统假死;
缺乏系统的整体错误情况看板;
因此,需要定义单独的monitor对这种异常进行监控并告警。如上图,MonitorManager和worker的协同方式一般可以有以下几种方式。
由worker指定错误码后,并同时生成一个告警event及推倒告警主题;
MonitorManager监听该告警主题,在发现有event后做响应告警处理;但因为MonitorManager一般只负责监控告警,且问题解决后MessageBroker后续还是得把它重新路由到之前的worker重试,所以一般使用fanout模式;
七、后话
今天差不多,后面可以讲一下另外一个跟事件驱动架构相关或者有关联的事件溯源架构。