目录
引言
什么是BPF
历史
是 Berkeley Packet Filter 的缩写,诞生于1992, 目的是提高网络包的过滤工具的性能。
2014年进入了Linux 内核的主线。
从使用的方式上来说,比较像是JavaScript。
组成
指令集、存储对象、辅助函数等几部分组成。
执行机制
一般有两种执行机制:
- 解释器
- 一个讲BPF指令动态转化成本地化指令的即时JIT 编译器
执行之前要通过验证器的安全性检查,可以保证BPF程序本身不会奔溃
BPF 和ebpf 的关系
现在的ebpf 为了和之前保持一致还是继续称呼为BPF。
BCC、bpftrace、IO Visor
直接通过BPF 指令编写BPF程序是比较繁琐的,因此有了高级语言去支持。
BCC(BPF编译器集合,BPF),最早用于开发BPF trace 程序,提供了一个C语言的环境,也提供了lua、python环境来实现用户端接口,是libbcc和libbpf库的前身,这两个库提供了使用BPF 程序对事件进行观测的库函数。
BCC 函数库提供了70多个tool。
bpftrace 是新出现的前端,提供了专门用于创建BPF工具的高级语言支持。bpftrace 也是基于libbcc和libpbf库进行构建的。
bpftrace 在编写功能强大的单行程序,短小的脚本比较在行,BCC 主要开发比较复杂的大型后端进程。
BCC 和bpftrace 不属于linux 内核,属于GITHUB上的一个 IO ViSor 的linux 基金会。
BCC 项目的quick start
execsnoop
来自bcc 项目,通过跟踪execve 系统调用来工作。
sudo execsnoop-bpfcc

作用
可以使用这个工具来检查业务负载,就是说可以看到进程是不是按照自己的想法,在一定的周期下被创建出来。
biolatency
概念
绘制块设备的延迟直方图(disk IO latency)
sudo biolatency-bpfcc
在虚拟机环境下,这个命令会在内核版本:5.19.0-35-generic 下执行失败。
动态插桩:kprobes和uprobes
概念
在生产环境中正在运行的程序的任意指令位置插入观测点
缺点
随着版本的更换,被插桩的函数可能会重新命名,或者直接被去掉,这样会有稳定性的问题,BPF工具可能会直接无法工作。
静态插桩:tracepoint 和USDT
概念
本质上就是为了解决上面动态插桩中接口稳定性的问题,直接把稳定的事件名硬编码到代码中,直接由开发者进行维护。
USDT(user level statically defined tracing),就是描述这个技术的。
缺点
硬编码会带来额外的维护成本
推荐的方案
首先使用静态的跟踪技术(tracpoint 或者USDT)如果不够用再使用动态插桩技术。
初识bpftrace : 跟踪openat
sudo bpftrace -e 'tracepoint:syscalls:sys_enter_openat {printf("%s %s \n",comm,str(args->filename));}'
这里有一些小的tips:
- openat 在linux 中被调用的次数远远超过open
- bpftrace 必须要使用root 权限
- bpftrace 一般比较simple,支持一些比较小的命令工具,但是BCC tool功能比较强大
技术背景
图解BPF

BPF辅助函数
- Map操作函数:BPF_MAP_LOOKUP_ELEM、BPF_MAP_UPDATE_ELEM、BPF_MAP_DELETE_ELEM等
- 内存操作函数:BPF_MEMCPY、BPF_MEMCPY_STR、BPF_MEMSET等
- 网络操作函数:BPF_SOCK_OPS_TCP_SOCK等
- 时间操作函数:BPF_KTIME_GET_NS等
- 系统调用操作函数:BPF_TRACE_PRINTK、BPF_GET_CURRENT_PID_TID等
- 数学计算函数:BPF_ADD、BPF_SUB、BPF_MUL、BPF_DIV等
- 其他函数:BPF_DEBUG、BPF_EXIT等
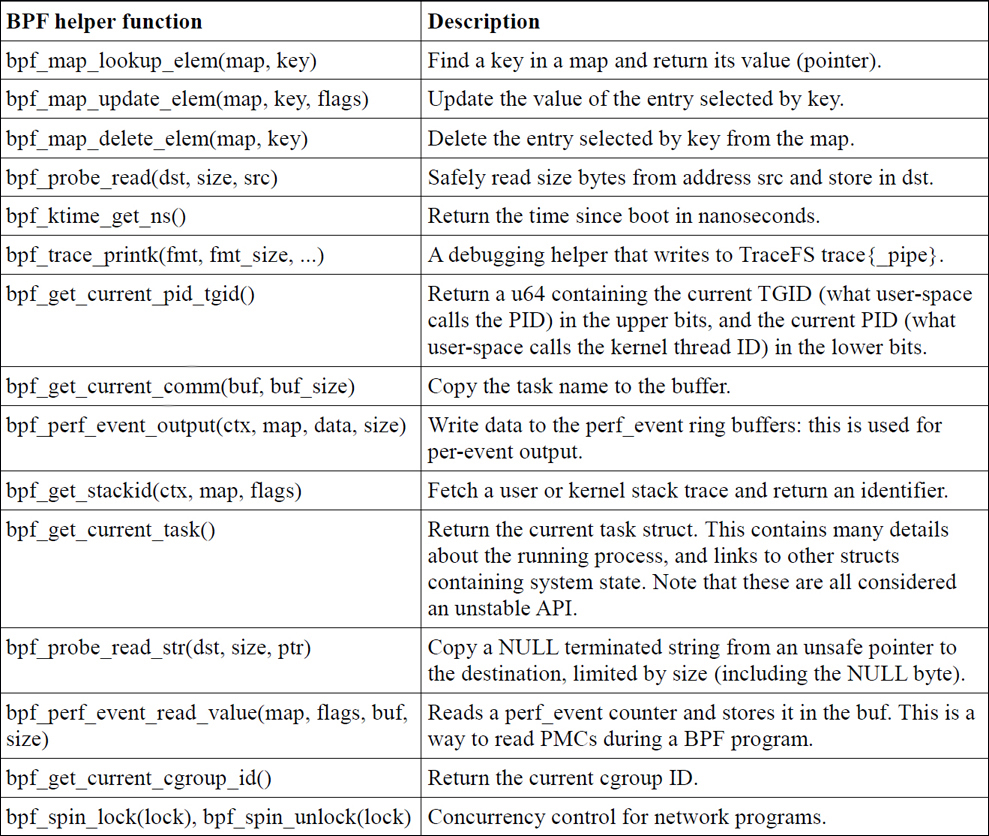
bpf_probe_read()
BPF中的内存访问仅仅限于 BPF寄存器和栈空间(以及通过辅助函数访问BPF映射表),如果访问其他内存(比如说除了BPF之外的内存),就需要使用bpf_probe_read()。
这个函数会进程安全性的检查禁止出现缺页中断,以保证在probe 上下文中不会发生缺页中断(否则可能会引发内核问题)。
还有其他的辅助函数: bpf_probe_read_kernel、bpf_probe_read_user()
为什么bpf_probe_read 要禁止缺页中断
在Linux内核中,BPF程序可以在内核空间中访问用户空间内存。当BPF程序访问的用户空间地址空间中的页面不在物理内存中时,会触发缺页中断,然后内核会将对应页从磁盘中读入内存,完成物理内存的分配操作,这个过程是比较耗时的。
但是,在某些情况下,我们可能并不需要立即读入缺页中断所对应的页面,比如在处理高速网络数据包时,不能承受太大的时延。因此我们可以通过禁止缺页中断来避免耗时的物理内存分配,提高处理性能。
bpf_probe_read是如何禁止缺页中断的
需要设置当前线程的脱离缺页中断标志位
/* 禁用缺页中断 */
void disable_page_fault(void)
{
preempt_disable();
current->flags |= PF_NOFREEZE;
current->mm->def_flags |= VM_FAULT_NOPAGE;
}
样例
使用bpf_probe_read 函数读取skb 中UDP 数据包
读取UDP数据包的过程需要先读取IP头部,然后再根据IP协议类型字段确定上层协议为UDP,接着读取UDP头部,然后再读取数据载荷。以下是一个使用bpf_probe_read()函数读取UDP数据包的示例代码
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/udp.h>
int mybpf_prog(struct __sk_buff *skb)
{
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
struct ethhdr *eth = data;
if (eth + 1 > data_end)
return 0;
// 读取IP头
struct iphdr iph;
if (bpf_probe_read(&iph, sizeof(iph), (void *)(eth + 1)) != 0)
return 0;
if (iph.protocol == IPPROTO_UDP) {
// 读取UDP头
struct udphdr uh;
if (bpf_probe_read(&uh, sizeof(uh), (void *)((unsigned char *)iph + (iph.ihl * 4))) != 0)
return 0;
// 计算数据包总长度
unsigned int len = ntohs(iph.tot_len) - (iph.ihl * 4) - sizeof(uh);
if (len <= 0) // 数据包长度错误
return 0;
// 读取数据载荷
unsigned char payload[len];
if (bpf_probe_read(&payload, len, (void *)((unsigned char *)uh + sizeof(uh))) != 0)
return 0;
// 对读取的数据载荷进行处理
...
return 1;
}
return 0;
}
BPF 系统调用命令

使用strace 分析execsnoop
sudo strace -ebpf execsnoop-bpfcc
bpf(BPF_BTF_LOAD, {btf="\237\353\1\0\30\0\0\0\0\0\0\0\274\4\0\0\274\4\0\0H\17\0\0\0\0\0\0\0\0\0\2"..., btf_log_buf=NULL, btf_size=5148, btf_log_size=0, btf_log_level=0}, 28) = 3
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY, key_size=4, value_size=4, max_entries=128, map_flags=0, inner_map_fd=0, map_name="events", map_ifindex=0, btf_fd=0, btf_key_type_id=0, btf_value_type_id=0, btf_vmlinux_value_type_id=0, map_extra=0}, 72) = 4
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=510, insns=0x7ff36007d000, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(5, 19, 17), prog_flags=0, prog_name="syscall__execve", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=3, func_info_rec_size=8, func_info=0x5645a446e430, func_info_cnt=1, line_info_rec_size=16, line_info=0x5645a4a88f20, line_info_cnt=252, attach_btf_id=0, attach_prog_fd=0, fd_array=NULL}, 144) = 5
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=82, insns=0x7ff36021b7d0, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(5, 19, 17), prog_flags=0, prog_name="do_ret_sys_exec", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=3, func_info_rec_size=8, func_info=0x5645a446e430, func_info_cnt=1, line_info_rec_size=16, line_info=0x5645a348d760, line_info_cnt=28, attach_btf_id=0, attach_prog_fd=0, fd_array=NULL}, 144) = 7
PCOMM PID PPID RET ARGS
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0x7ff35babc690, value=0x7ff35babc590, flags=BPF_ANY}, 144) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0x7ff35babc590, value=0x7ff35babc690, flags=BPF_ANY}, 144) = 0
^Cstrace: Process 4540 detached
PS: 最好是可以避免直接使用strace 因为使用strace 本质上使用ptrace,会严重的降低目标进程的执行速度,性能可能会直接下降到原来的1%,但是他的好处是可以支持bpf 系统调用的翻译,比如说可以打印出BPF_PROG_LOAD
BPF程序类型
不同的bpf程序类型定义了BPF 程序可以挂载的事件类型,以及事件的参数,主要用于trace 用途的BPF程序的类型如下:

BPF 映射表类型

其中BPF_MAP_TYPE_PERF_EVENT_ARRAY 可以将内核中的捕捉到的信息传递到user ,execsnoop就使用了这个类型。
BPF的并发控制
BPF一直缺乏并发控制,直到Linux 5.1添加了自旋锁 spin lock帮助程序,尽管这些还不能用于跟踪程序。
通过跟踪,并行线程可以并行地查找和更新BPF映射字段,当一个线程从另一个线程覆盖更新时,就会导致破坏。这也称为丢失更新问题(lost update),即并发读写重叠导致丢失更新。跟踪前端BCC和bpftrace在可能的情况下使用每cpu哈希和数组映射类型来避免这种损坏。这将为每个逻辑CPU创建实例(比如说使用BPF_MAP_TYPE_PERCPU_HASH这种带有PERCPU 的type)
这是使用了BPF_MAP_TYPE_PERCPU_HASH type 的方式
strace -febpf bpftrace -e 'k:vfs_read { @ = count(); }'
这是没有使用并发控制的方式
strace -febpf bpftrace -e 'k:vfs_read { @++; }'
Comparing the counts shows that the normal hash undercounted events by 0.01%.
对比下来会有0.01% 的误差。
BPF sysfs 接口
在Linux 4.4中,BPF引入了通过虚拟文件系统公开BPF程序和映射的命令,通常挂载在/sys/fs/ BPF上。这被称为“钉住”,这可以有很多用途。它允许创建持久的BPF程序,类似于守护进程,并在加载它们的进程退出后继续运行。它还为用户级程序与正在运行的BPF程序进行交互提供了另一种方式:它们可以读写BPF映射。
BPF 类型格式
如果说我们缺少目标程序的源代码,导致写一些BPF tool 比较困难,那么这里有一种BTF 的技术可以解决这个问题。
但是BTF 技术还在开发过程中。
BPF CO-RE
BPF 的“一次编译,到处运行的”Compile Once - Run Everywhere 项目,旨在允许BPF程序一次性编译为BPF字节码,保存,然后在其他系统上分发和执行。这将避免在所有地方安装BPF编译器(LLVM和Clang),这对于空间受限的嵌入式Linux来说是一个挑战。它还可以避免在执行BPF可观察性工具时运行编译器所带来的运行时CPU和内存成本。
CO-RE 目前也在开发阶段。
BPF 的局限性
- 不可以随意的使用内核函数
- BPF 的栈的大小不可以超过512 (MAX_BPF_STACK),这个有解决方案:使用映射存储空间。
调用栈回溯
BPF 提供了存储调用栈信息的而专用映射表结构,可以保存基于帧指针或基于ORC的调用栈回溯信息。
基于帧指针的调用栈回溯
这个技术主要基于一个前提:函数调用栈帧链表的头部,始终保存在某一个寄存器中(RBP on x86_64),并且这个函数调用的返回地址永远位于RBP 的值指向的位置加上一个固定的偏移量(+8)。
这标志任何调试器都可以在中断程序执行之后,通过读取RBP后遍历以RBP的值为头部的链表,同时在固定偏移位置获取返回地址,从而轻松的进行栈回溯。

PS: 在gcc 编译器中默认是没有函数帧指针的,将RBP作为普通的寄存器来使用的,但是这个性能的提升其实没有很高,所以建议开启这个默认行为。
-fno-omit-frame-pointer
基于调试信息来做debug
也就是在gcc 的后面加 -g -wall 的意思。
这其中包含了DWARF的ELF 的调试信息
在ELF文件中调试相关的文件段是 .eh_frame 和.debug_frame
缺点就是这样会让这个可执行文件非常大
libjvm.so = 17M
libjvmd.so = 222M
最后分支记录
也就是LBR,是inter 的一个特别的技术,被记录在硬件缓冲区中,这个技术没有额外的开销。
但是支持记录的深度会存在限制。
BPF不支持LBR
ORC
针对栈回溯需求专门设计了一种新的调试信息格式——Oops 回滚能力(Oops rewind capability,ORC)。相比于DWARF格式,使用这种格式对于处理器的要求比较低,ORC使用的也是ELF的文件段,目前linux 内核以及给了一部分支持。
目前还没有开发用户态对ORC调用栈的支持。
在内核中基于ORC的调用栈回溯可以通过 perf_callchain_kernel 函数支持。
符号
调用栈信息目前在内核中以地址数据形式记录的,这些地址可以通过用户态的程序翻译成符号(比如函数的名字)。
但是这部分工作目前还没有完成。
火焰图
火焰图是一种用于显示程序 CPU 使用状况的可视化工具。下面给出一些火焰图的基本用法和解读方法:
- 坐标轴:火焰图的 y 轴标识调用栈,从上到下表示函数调用的深度。x 轴表示 CPU 时间(可以是毫秒、秒或其他单位),从左到右表示程序的运行时间。
- 颜色:火焰图的颜色表示函数调用在 CPU 时间或计数器空间上所占的相对值。
- 宽度:火焰图中的每个矩形宽度表示相关代码的 CPU 时间或者计数器测得值。
- 工具:例如Flamegraph,perf等火焰图生成工具都支持启用各种设定,如矩形排列顺序,颜色方案等等。
根据以上信息,接下来了解如何解读火焰图:
- 开头与结尾:火焰图的开始和结尾通常是程序的入口和退出点,在火焰图中通常具有相当宽的板块和颜色较浅。
- 宽度:火焰图中宽度较大的矩形表示在程序执行过程中的资源消耗比较高,其代码运行时间也相应较长。
- 颜色:火焰图中的颜色从浅绿色到深绿色选区,浅绿颜色区域是程序当中相对花费时间的低开销地方,深绿区域则追求更大的时间花费。
- 重复调用:在火焰图中,相同函数的重复调用会显示相同的框,框内的宽度指示它被调用的次数和执行时间的相对大小。
- 堆栈信息:火焰图中的每个函数调用的名称和调用堆栈信息也可用于鉴别和调整程序的性能问题。
事件源
Kprobes
kprobes 和kretprobes 的概念
kprobes 提供了针对内核的动态插桩支持,不需要重启内核。
kretprobes可以用来对内核函数返回时进行插桩以获取返回值,也可以用kprobes 和kretprobes 同时对一个函数进行插桩,来获取一个内核函数调用的时间。
原理
- 注册断点:Kprobes利用内核的动态内存分配技术,在内核 web 服务器代码的关键位置注册断点。
- 断点触发:当内核执行到已注册断点的位置时,则立即暂停执行,并在此时开始执行 Kprobes 注册的处理程序。
- 处理程序:Kprobes 的处理程序可以是一个用户自定义的函数,它可以在断点处挂钩处理内核函数调用,并记录性能数据或更改内核状态,以进行调试或分析。
- 处理完成:处理程序完成后,Kprobes 将继续执行中断位置的剩余代码,完成对内核代码的跟踪或处理。
Kprobes接口
之前必须使用c语言写入口处理函数和返回处理函数,然后调用register_kprobe()来注册。
现在主要使用BCC 或者bpftrace。
BCC提供了:
attach_kprobe() attach_kretprobe()
bpftrace 的一个demo 如下:
bpftrace -e 'kprobe:vfs_* {@[probe] = count()}'
uprobes
概念
提供了用户态程序的动态插桩。
和kprobes类似,原理和kprobes 也类似。
原理
通过在指定的地址处插入一条跳转指令来截获进入或离开该地址的CPU执行流程,并在其前后执行指定的处理程序。这种方法可以在不破坏二进制代码的情况下,实现对程序的运行状态进行监控和修改
接口
基于Ftrace ,向/sys/kernel/debug/tracing/uprobe_events: 通过对这个文件写入特定字符串的打开或者关闭uprobes
perf_event_open()
BCC 中提供了两个接口:
attach_uprobe attach_uretprobe
跟踪点 tracepoint
概念
静态插桩
原理
在编写内核代码时,开发者可以使用tracepoint宏定义来预定义跟踪点。这些跟踪点及其参数在编译时就已经被固定在内核二进制代码中了。
在程序运行时,如果开启了跟踪功能,当程序执行到相应的跟踪点时,会触发与之对应的tracepoint回调函数。这个回调函数可以在代码中定义,用来实现所需要的操作。由于跟踪点已经事先定义好了,因此可以避免插入额外的汇编指令,从而减少了对程序运行性能的影响。
接口
BCC提供了
tracepoint_probe()
USDT
概念
用户态预定义静态跟踪, 提供了一种用户空间的跟踪点机制
BPF 与USDT
USDT().enable_probe()
性能监控计数器
性能监控计数器是用于测量程序运行过程中各种系统硬件状态的计数器。它们通常由处理器底层硬件提供,在系统中大量运行的计数器可以用于监控系统的性能和瓶颈。性能监控计数器可以衡量诸如指令执行、CPU缓存性能、内存汇总等方面的各项指标,进而评估整个系统的性能和优化方案的效果。
在软件开发过程中,使用性能监控计数器可以比较精确地分析程序的性能瓶颈。开发人员可以结合不同的计数器指标,确定系统瓶颈所在,并通过优化代码和算法等方式提高程序的性能。
常见的性能监控计数器包括CPU运行周期(Clocks)、指令执行数(Instructions)、缓存命中率(Cache Hits)、内存访问延迟(Memory Latency)等。这些计数器通常可以通过专用工具或系统命令行接口获取,例如Linux系统提供的perf工具、Intel VTune、AMD CodeXL等性能监控工具。